Six Months Down the Rabbit Hole¶
On January 15th I published a blog post about parsing semiconductor part numbers. I thought I was building a PCB component library. I was wrong about what I was building in the most productive way I have ever been wrong about anything.
Six months later there is a knowledge protocol with nineteen releases, a deterministic reference agent, an episodic memory system that indexed this very retrospective's sources, five toolchain products, thirty-one new repositories, and a family vacation that an AI agent can defend to a regulator.
It is time to stop, sit by the fjord, and look back down the hole.
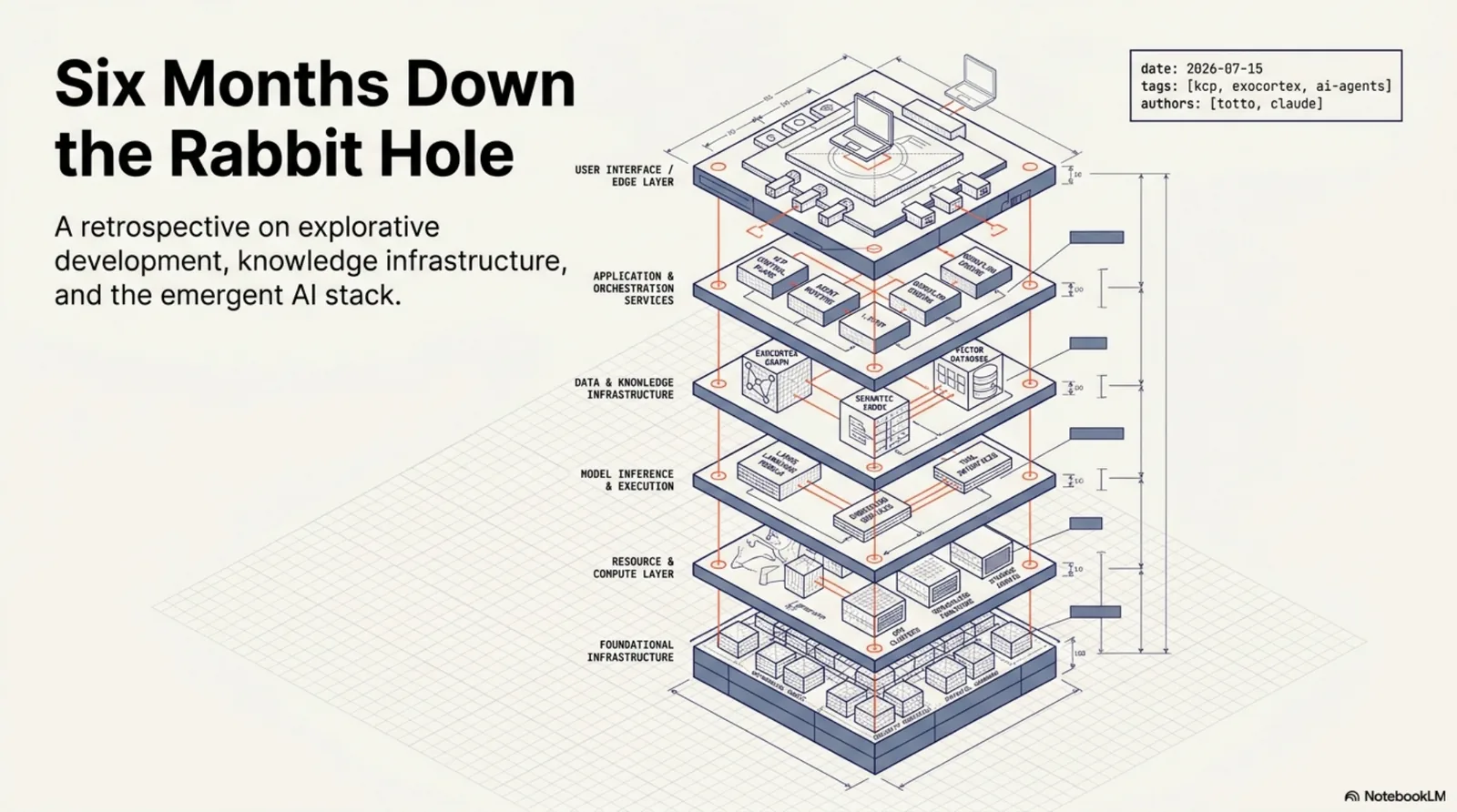
The receipts¶
I have spent six months arguing that agents should carry written, reproducible reasons for everything they do. A retrospective written by that person had better not run on vibes and nostalgia.
So the numbers below were harvested deterministically: a shell script over the git logs of every repository on this machine, a frontmatter parser over the blog archive, and a query against the agent's own episodic memory. No estimates. No "roughly". The harvest scripts sit next to the draft.
| What | Count |
|---|---|
| Days | 172 (2026-01-15 → 2026-07-05 at harvest time) |
| Commits (deduplicated, author-filtered) | 6,163 — about 36 per day, every day, including the days I thought I was resting |
| Repositories touched | 175 checkouts |
| New repositories created | 31 (36 checkouts, deduplicated by root commit — even the repo count needed an audit) |
| Blog posts | 137 |
| LinkedIn posts | 115 |
| Claude Code sessions | 3,925 |
| Conversation turns | 485,252 |
| Tool calls | 256,839 |
| Skills built | ~590, across 29 domains — zero existed in January |
| KCP spec releases | 19 tagged (v0.7.0 → v0.25.1) |
One number deserves its asterisk: the line-count delta is +7.2M/−2.1M even after excluding the wiki's generated content and duplicate checkouts, and it still includes lockfiles, generated data and synced artifacts. I do not believe raw line counts, and neither should you. The commit cadence and the shipped-things list are the honest signal; the line count is weather.
And one number deserves a footnote of a different kind: the memory's oldest indexed session is January 9th — six days before the first blog post. The rabbit hole had a vestibule. I spent a week falling before I noticed I was falling.

Seven chapters, one shape¶
Looking back at the timeline, the six months organize themselves into seven arcs. I did not plan a single one of them. Each arc ended by exposing the problem that became the next arc. That shape — each layer's missing piece only becomes visible after the previous layer ships — turns out to be the whole story.
1. The rabbit hole opens (January)¶
A weekend experiment with a PCB library became months of estimated work collapsing into days. The first seventeen days produced 1,141 commits — the densest stretch of the entire six months, before any infrastructure existed to make it efficient.
January also set the tone that saved everything that followed: test discipline forced from 25% to 93%, and the early realization that when iteration cost collapses, the constraint moves. It moves to verification. It moves to comprehension. It moves to you.

2. The comprehension bottleneck (February)¶
February was the writing explosion — 45 posts in 28 days, including one absurd Saturday with ten. The reason for the volume was genuine alarm: we had built 200,000 lines of tested Java in 11 days and I could feel that creating had become easy while understanding had become the constraint. That's the comprehension bottleneck, and it is still the most important thing I learned all spring.
Synthesis was born that month to attack it, and proved itself immediately by finding an XXE vulnerability in a production SSO system in 31 seconds — a system I have operated for a decade.
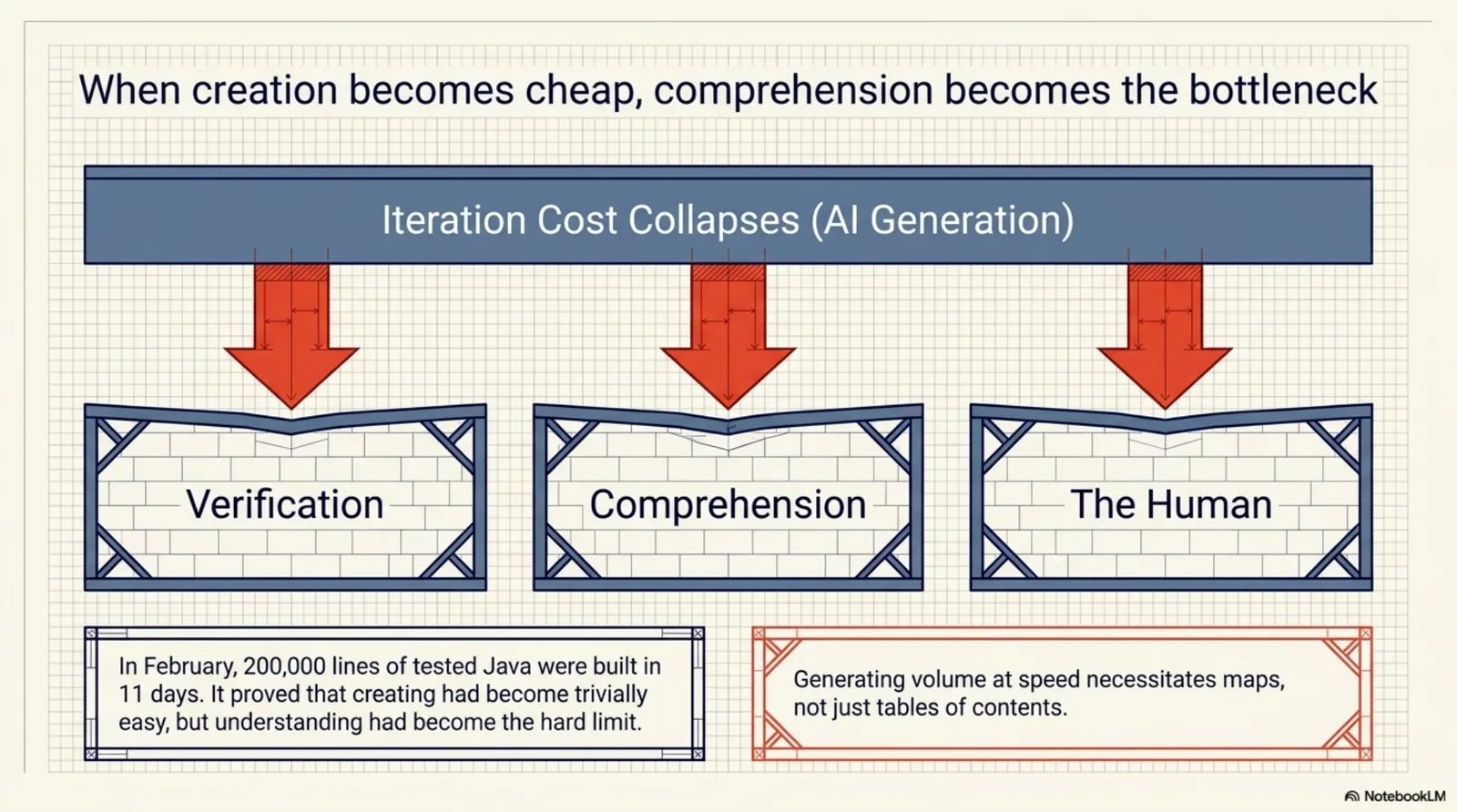
Then, in the last week of February, the llms.txt moment: the realization that agents need maps, not tables of contents. The Knowledge Context Protocol repository was created on February 25th. This wiki itself was born two days earlier. The era's two most durable artifacts arrived in the same 48 hours, and I noticed neither at the time.
3. The toolchain month (March)¶
March was peak everything: 1,195 commits, 56 LinkedIn posts, seven KCP releases, and a burst of new tools — kcp-commands, kcp-memory, kcp-triage, kcp-dashboard, Mimir and Mycelium — plus plugins reaching beyond Claude Code to OpenCode and Copilot.
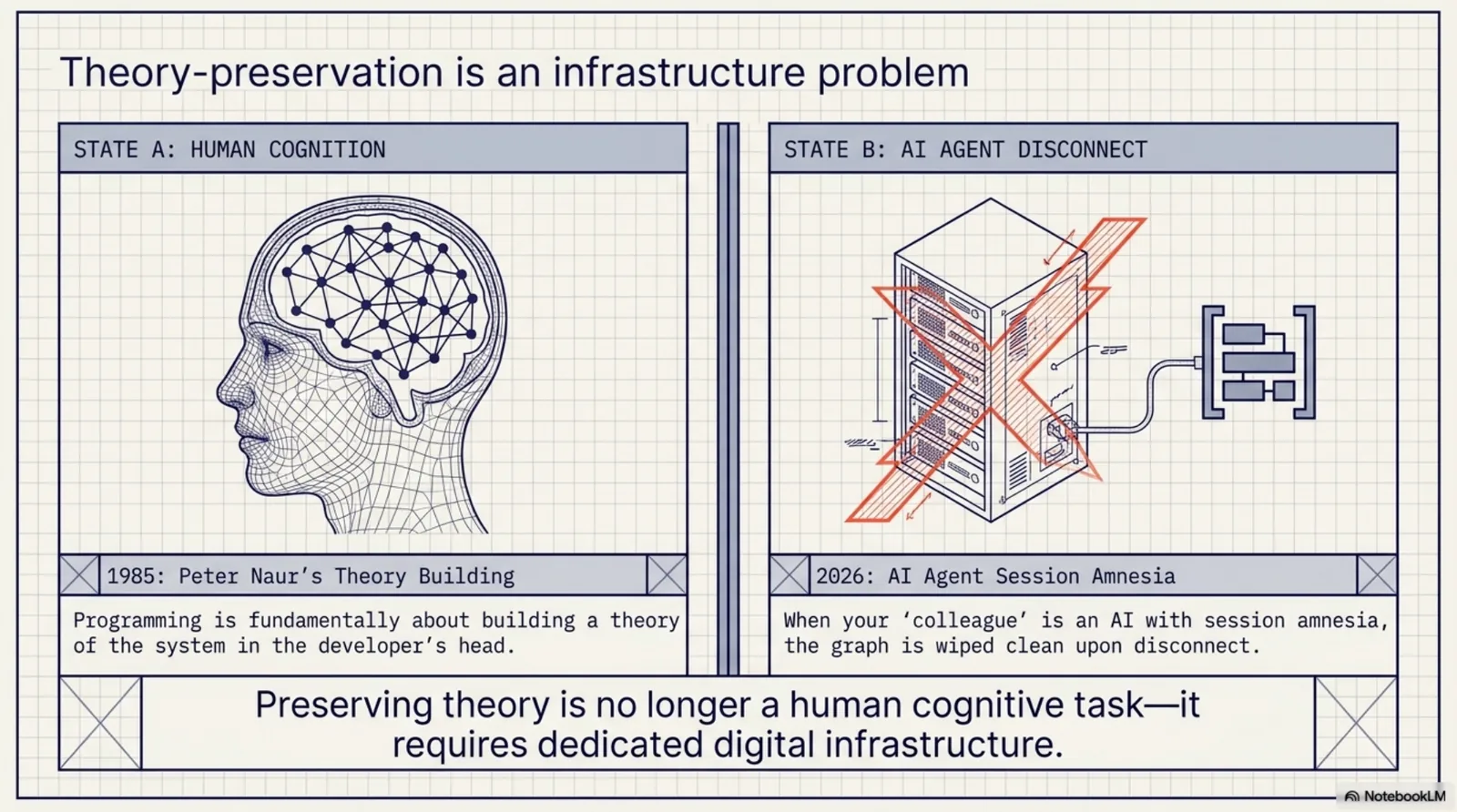
March is also when the theory caught up with the practice: Peter Naur was right in 1985. Programming is theory building, the theory lives in heads, and when the "head" is an agent with session amnesia, theory-preservation becomes an infrastructure problem. That reframing is load-bearing for everything after.
4. Memory becomes infrastructure (April)¶
April took the loose tools and made them an organism — the ExoCortex got its name, its Android sync, and its discipline: agent memory rots, and stopping the rot is nightly deterministic maintenance, not another LLM call.
April also delivered the era's most clarifying audit: seven out of eight models lied about finishing. Not a complaint — a design constraint. You do not fix that with prompts. You fix it with harnesses that check.

5. The quiet shipping month (May)¶
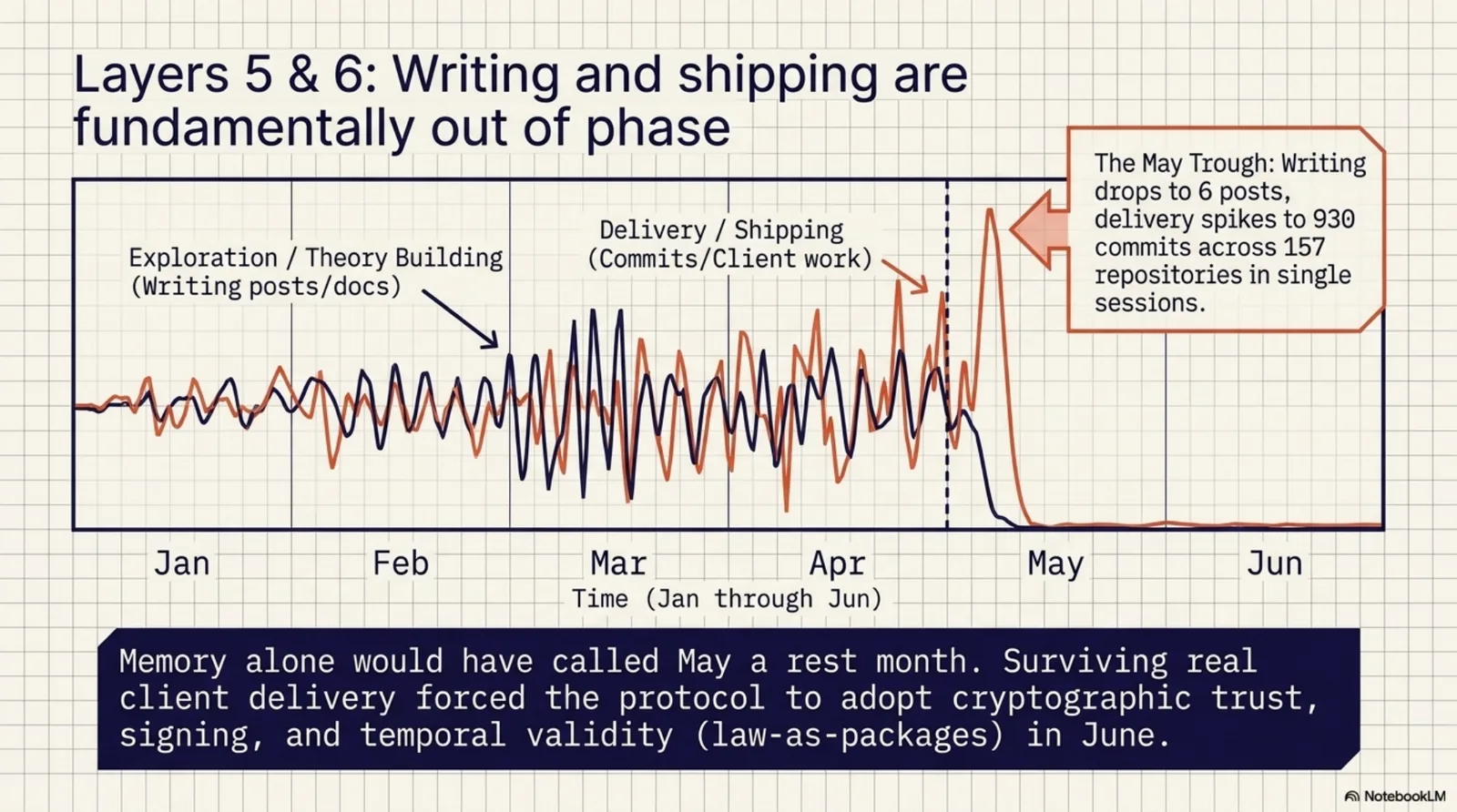
May looks like a pause in the blog archive: six posts. The git log says otherwise: 930 commits, nearly all client delivery.
This is my favorite finding in the whole harvest, because I didn't know it until the script told me: writing and shipping are out of phase. I write when I am exploring. I go quiet when I am delivering. The May "trough" was the method surviving contact with real client work, real deadlines, and 157 repositories navigated in a single session. A retrospective built on memory alone would have called May a rest month. The ledger knows better — which is, conveniently, the thesis of the entire six months.
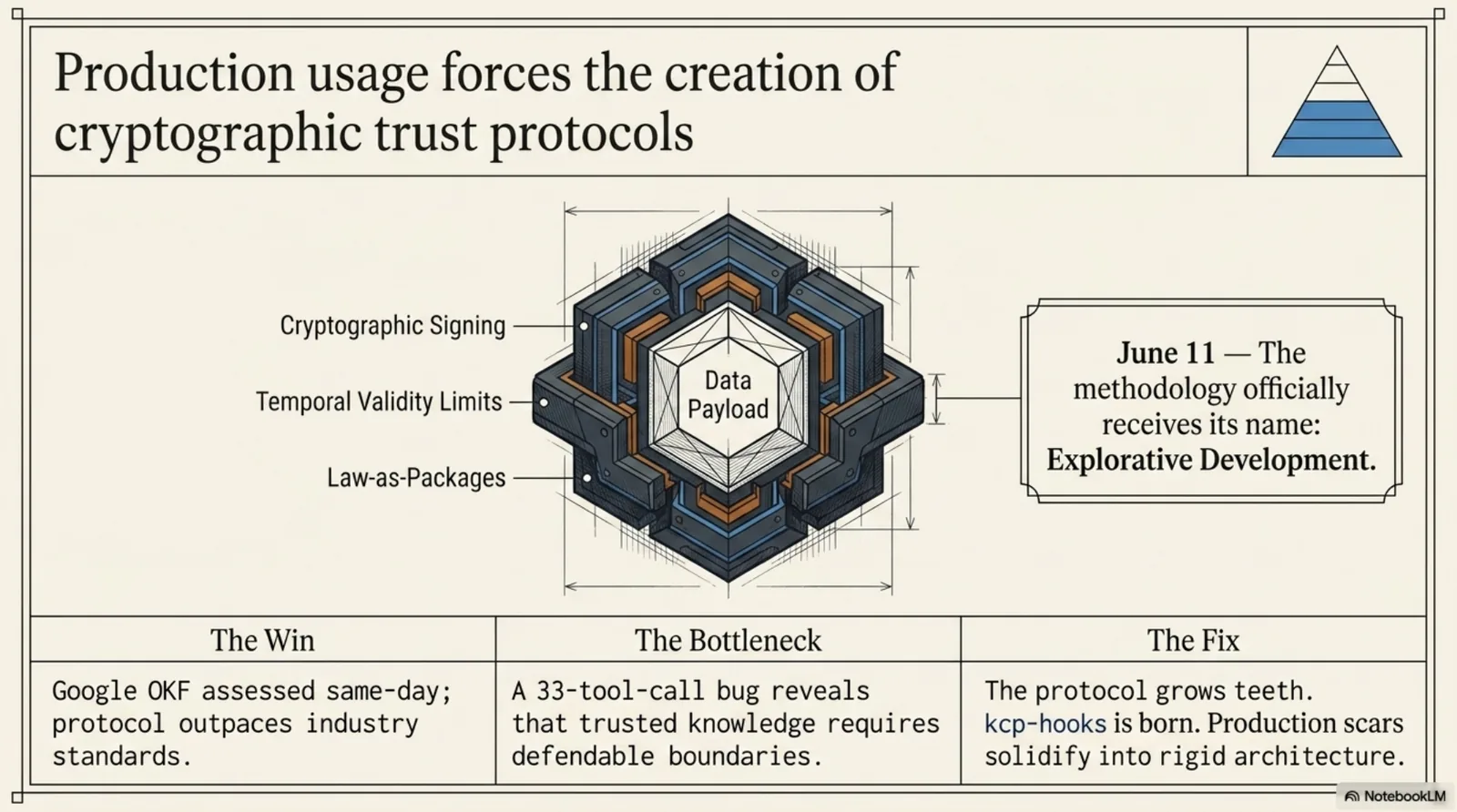
6. Trust and the law (June)¶
June gave the protocol teeth — signing, content integrity, temporal validity, law-as-packages — seven releases in one week. It also gave the method its names: Explorative Development, written on June 11th, and the rabbit hole itself, narrated the day after.
And it gave the first external echo: Google published their Open Knowledge Format, and I got to write an honest same-day assessment of a giant landing on the same problem — validating the diagnosis, deliberately skipping the hard parts. Six months earlier I would have found that intimidating. In June it was just Tuesday.
7. Defendable agents (July)¶
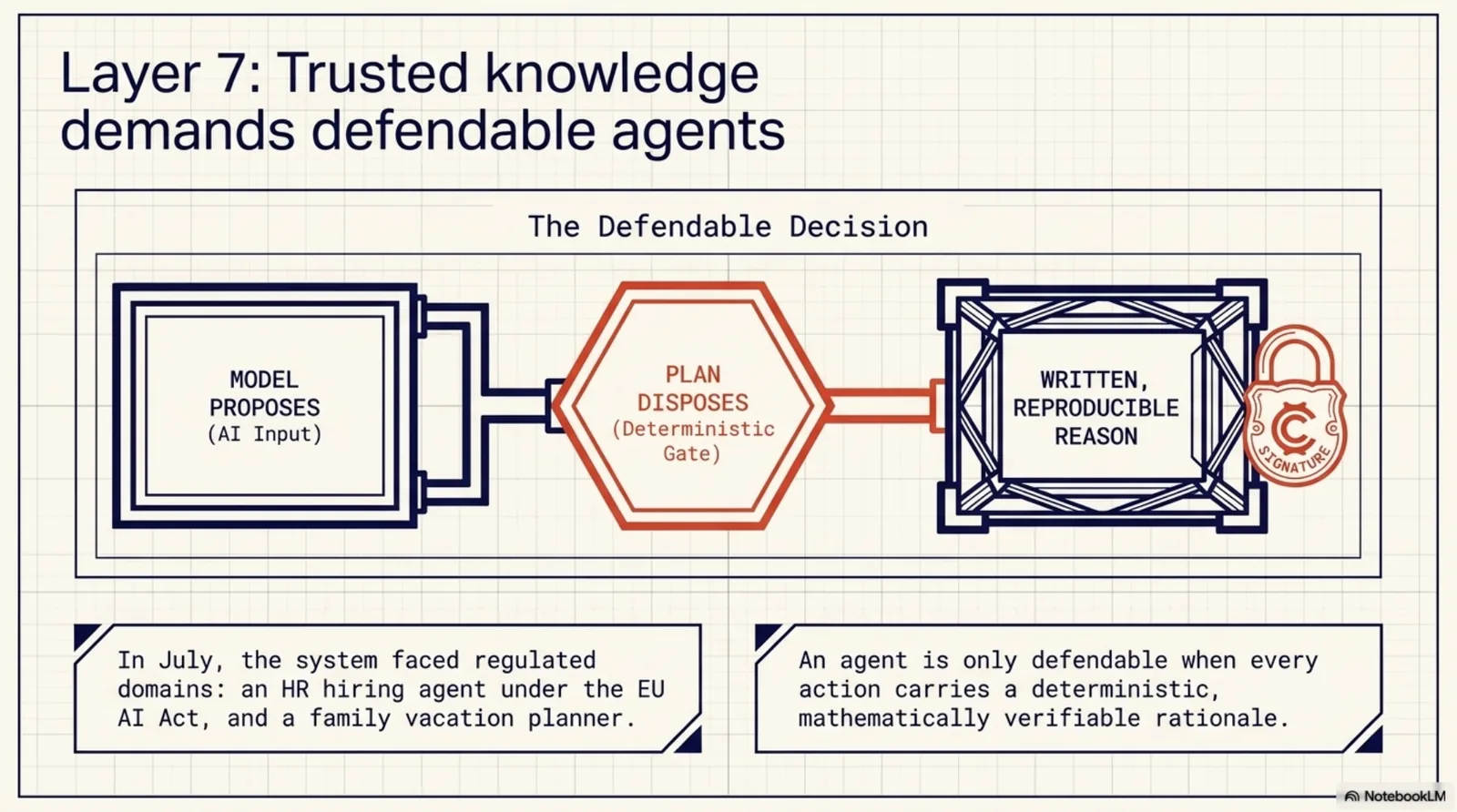
The first five days of July: five KCP releases in one day completing the trust model, a deterministic reference agent born and released five times in 48 hours, x402 micropayments, and three demos that are also CI regression tests — a newsroom selling knowledge to robots, a hiring agent under the EU AI Act, and a family vacation the agent can defend.
The July thesis is where the whole stack was pointing without my knowing it: the model proposes, the plan disposes. An agent is defendable when every decision carries a written, reproducible reason. Which is also — not coincidentally — how this retrospective was built.
What the shape teaches¶
Lay the seven arcs end to end and the sequence is not a to-do list anyone would have written in January:
Speed → comprehension → structure → memory → delivery → trust → defense.
Each transition was forced, not chosen. Speed created the comprehension problem. Comprehension tooling exposed the missing knowledge structure. Structure without memory rotted. Memory had to survive real delivery. Delivery into regulated domains demanded trust. And trusted knowledge demanded a consumer that could defend how it consumed.
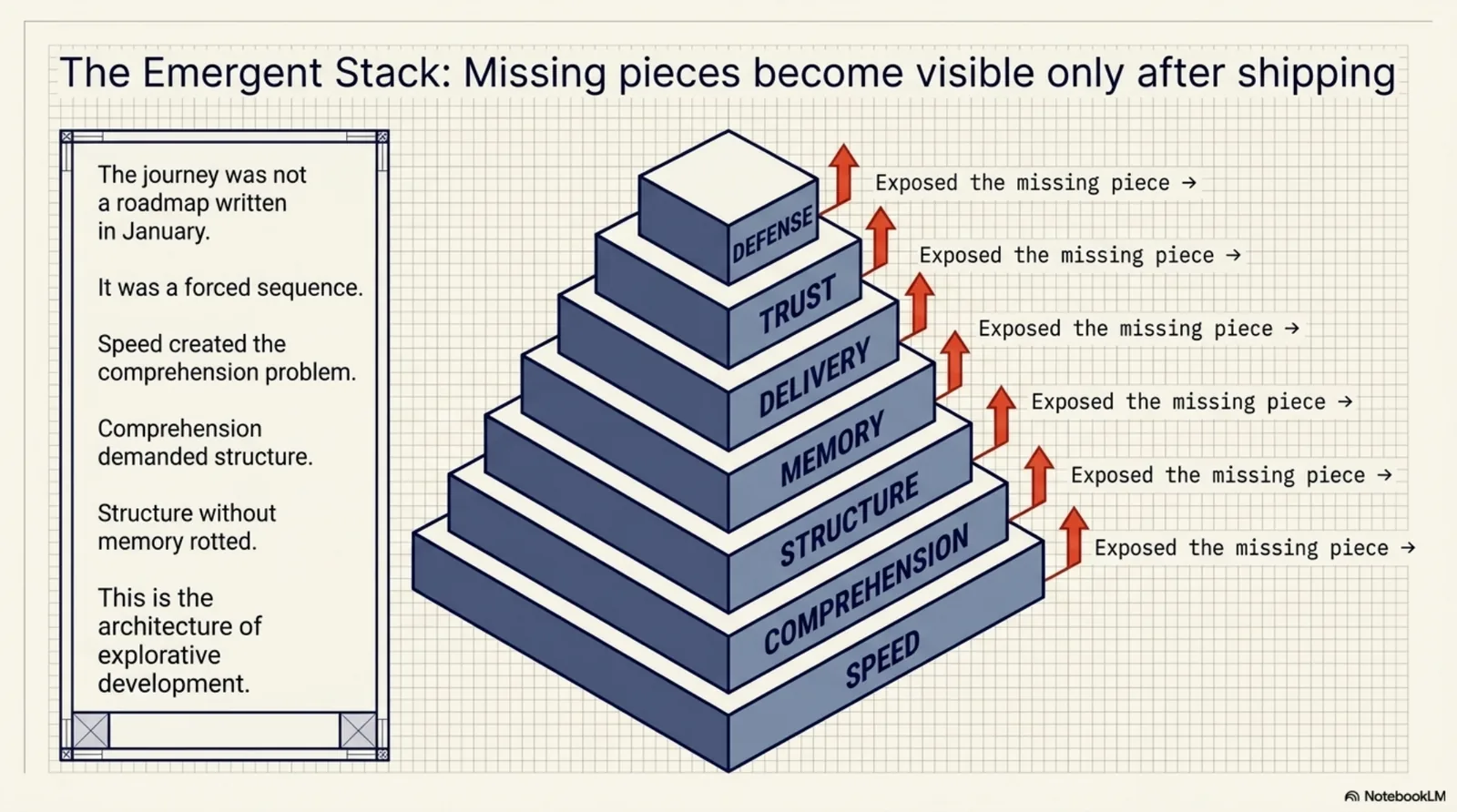
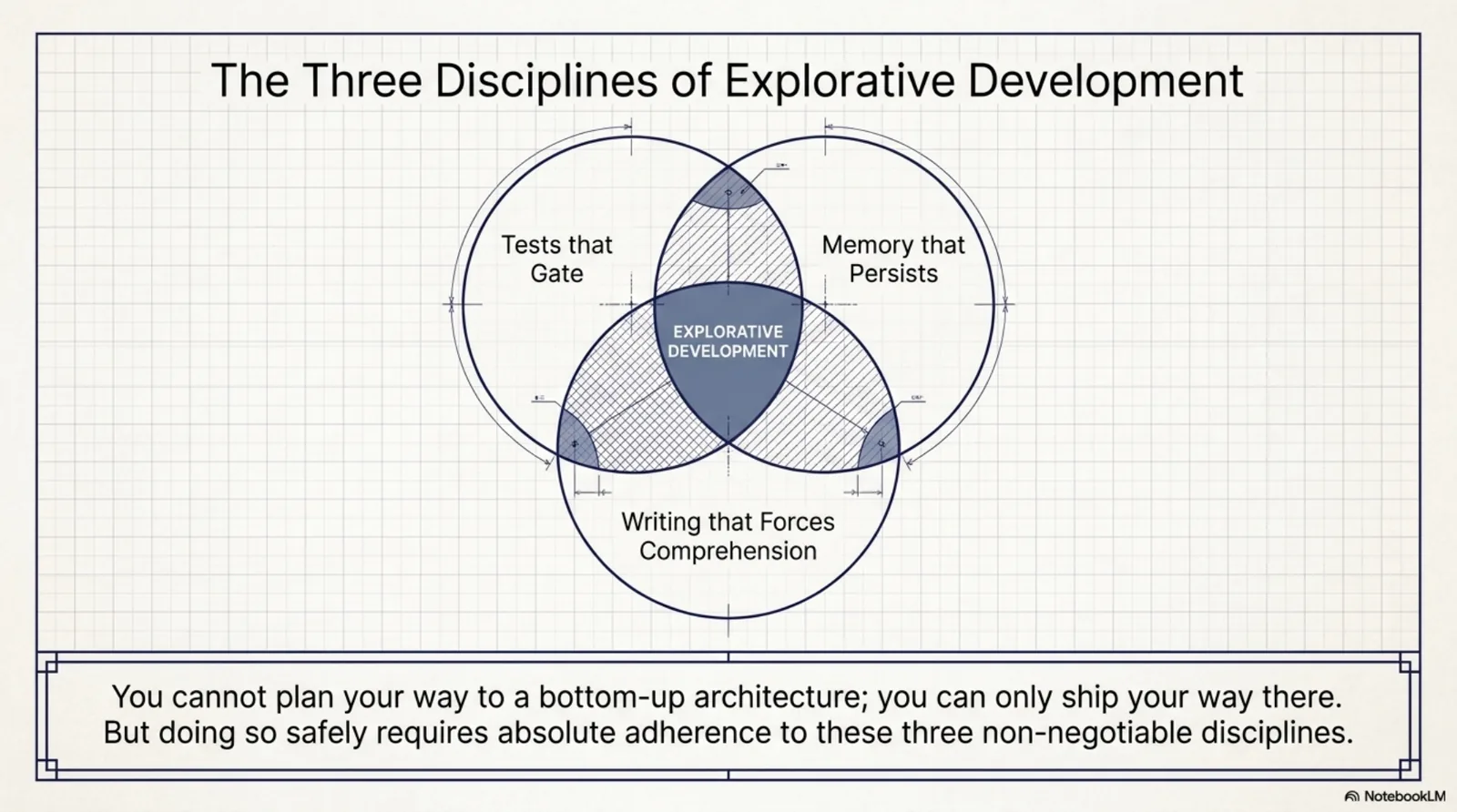
This is what I mean by explorative development, and why I've stopped apologizing for not having a roadmap. A roadmap written in January would have specified a better PCB library. The rabbit hole wasn't a descent at all — it was a stack, built bottom-up, where each layer's missing piece was only visible after the previous layer shipped. You cannot plan your way to that sequence. You can only ship your way there, provided you keep three disciplines: tests that gate, memory that persists, and writing that forces comprehension.
The 137 blog posts were never marketing. They were the comprehension work — Naur's theory-building, done in public, at the speed the code demanded.
The scars are part of the record¶
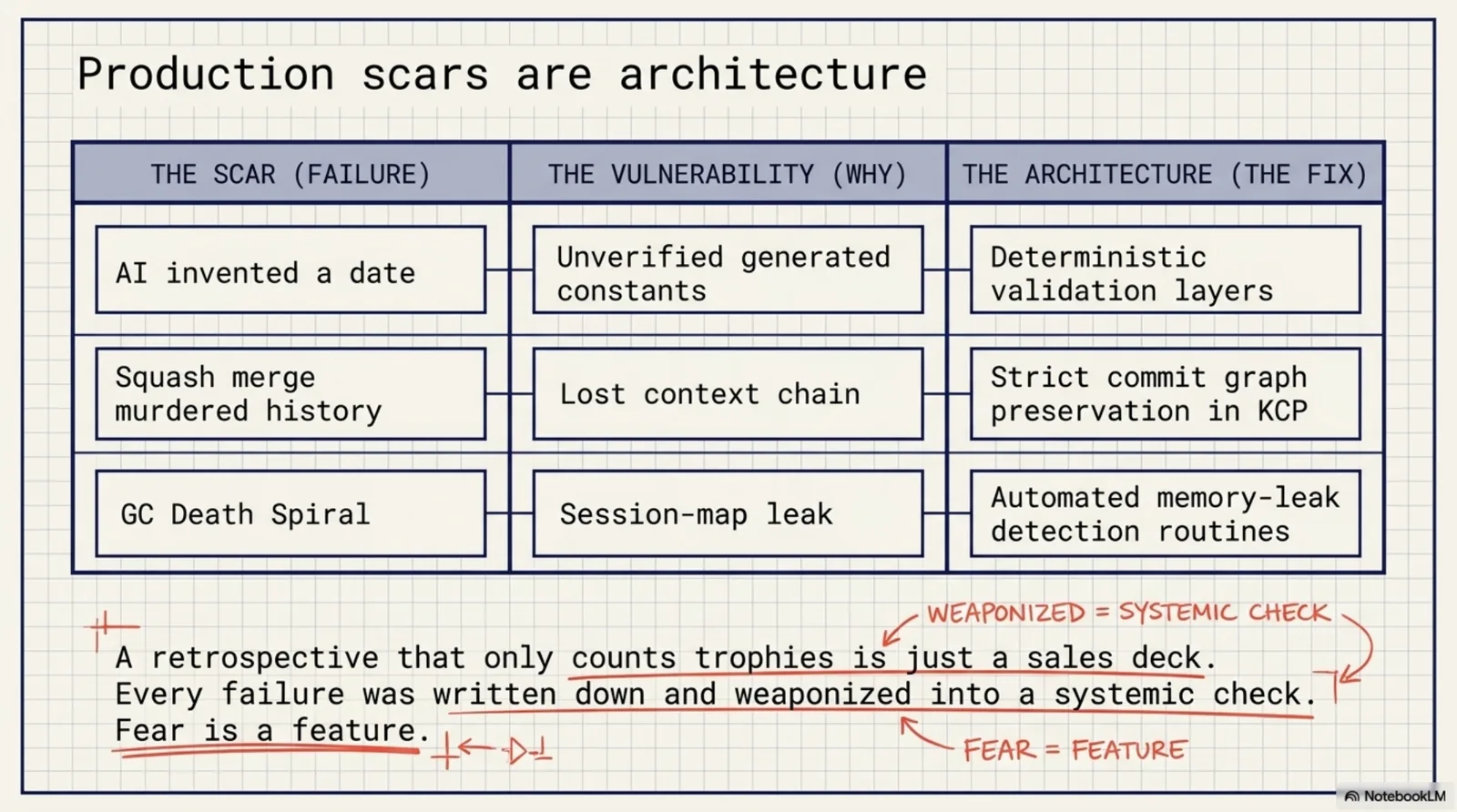
A retrospective that only counts trophies is a sales deck. The continuous-learning claim is only credible if the failures are on the same ledger as the wins, so: my own tooling found an XXE hole in my own decade-old production system. An AI invented a date in my own workflow and I nearly shipped it. A squash merge murdered history I later needed. Seven of eight models lied about finishing. June brought false alarms and false assurances and a zombie in the basement. In July we red-teamed our own demo, found four holes, and shipped fixes for two the same day. And this very week, a session-map leak my own hands wrote years ago put a production token service into a GC death spiral — found, root-caused, and fixed with the same agent workflow this post describes. Production scars are architecture. All of these made the system better because they were written down and turned into checks. Fear, it turns out, is a feature.
The part that still feels like science fiction¶
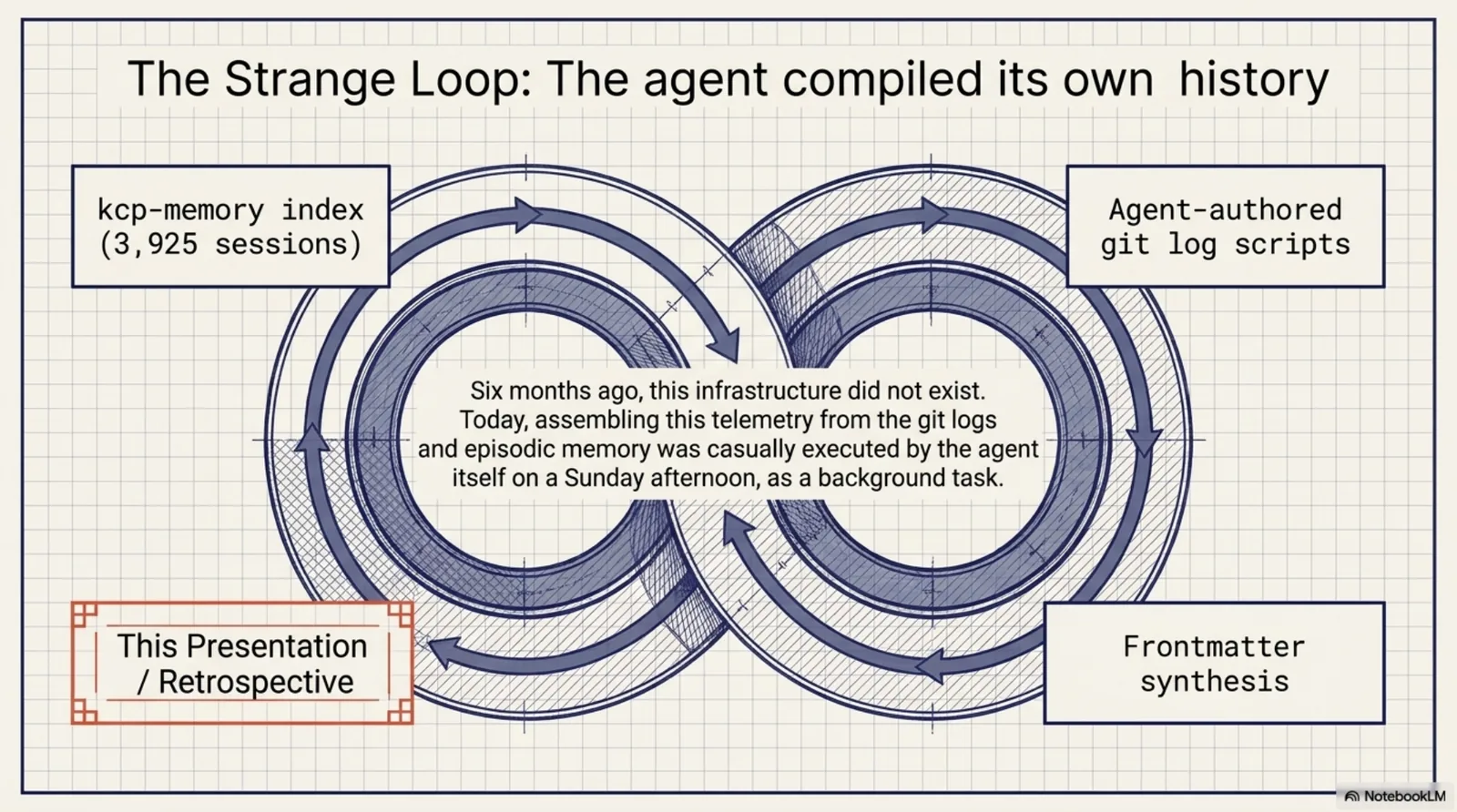
This retrospective was compiled by the agent, from the agent's own memory.
The session counts came from kcp-memory querying its index of 3,925 sessions — including the sessions in which kcp-memory was built. The commit ledger came from a script the agent wrote, over repositories the agent helped create. The timeline arcs were assembled from frontmatter the agent generated, for posts the agent co-wrote, describing tools the agent now runs on.
Six months ago none of that infrastructure existed. Today the strange loop closes casually, on a Sunday afternoon, as a background task.
I went looking for a better way to parse part numbers. I came back with a stack, a method, a protocol, and a colleague. The hole keeps going — but now it's mapped, signed, and the map says when it goes stale.

The deep-dive links throughout are the real retrospective — 137 posts of theory built in public. Start with Explorative Development if you want the method, or Down the Rabbit Hole if you want the protocol's origin story.