Explorative Development¶
Practitioner notes on engineering as a sequence of experiments — and on who does what in the loop.
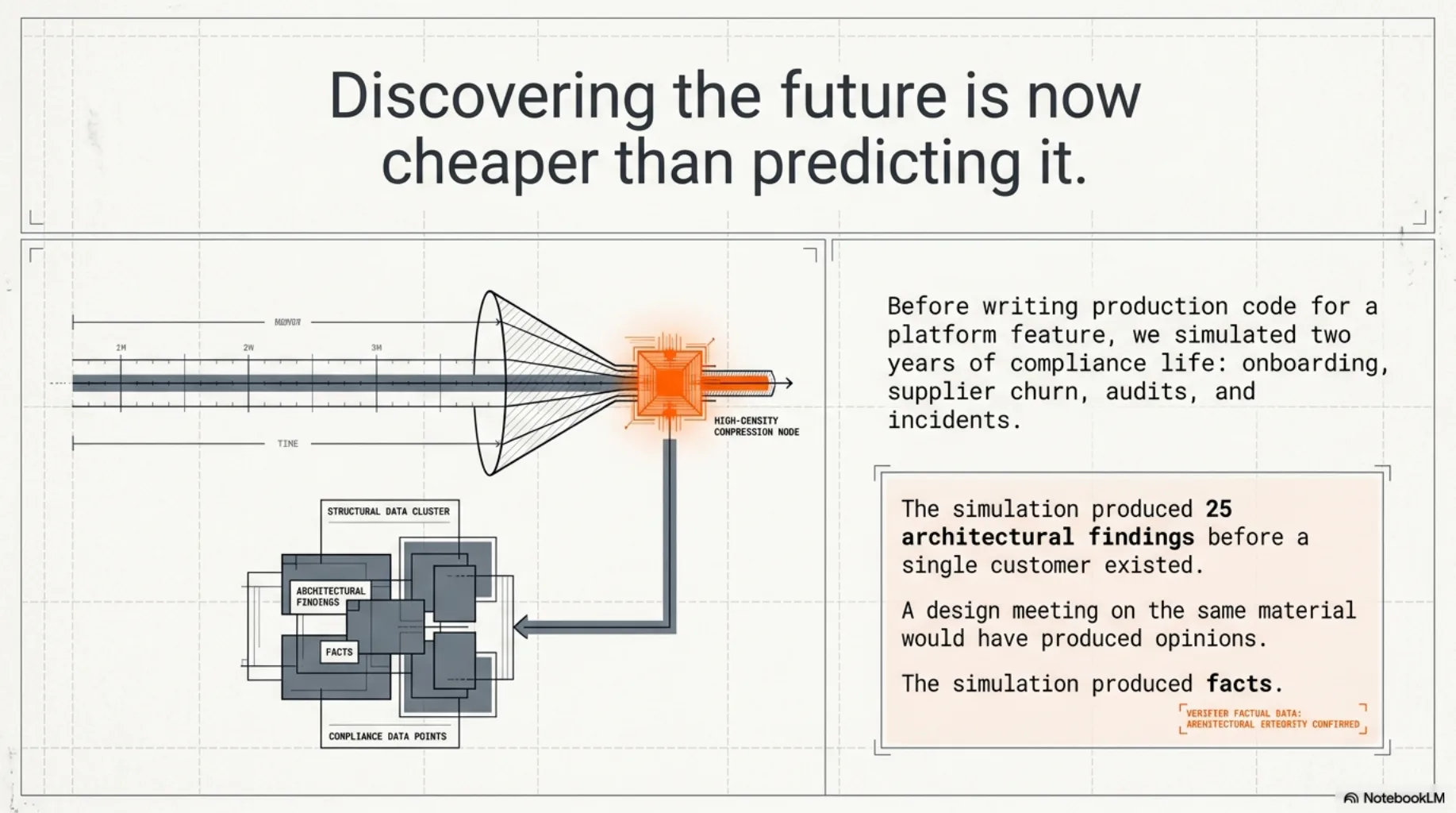
Before we wrote the production code for a recent platform feature, we ran a fictional organization through two years of using it.
Twenty-four simulated months of compliance life: onboarding, supplier churn, audits, incidents, people leaving with their knowledge. The simulation produced fifteen architectural findings — wrong assumptions and missing pieces, discovered while every fix was still cheap and no customer existed yet. Sibling simulations took the total to twenty-five. A design meeting on the same material would have produced opinions.
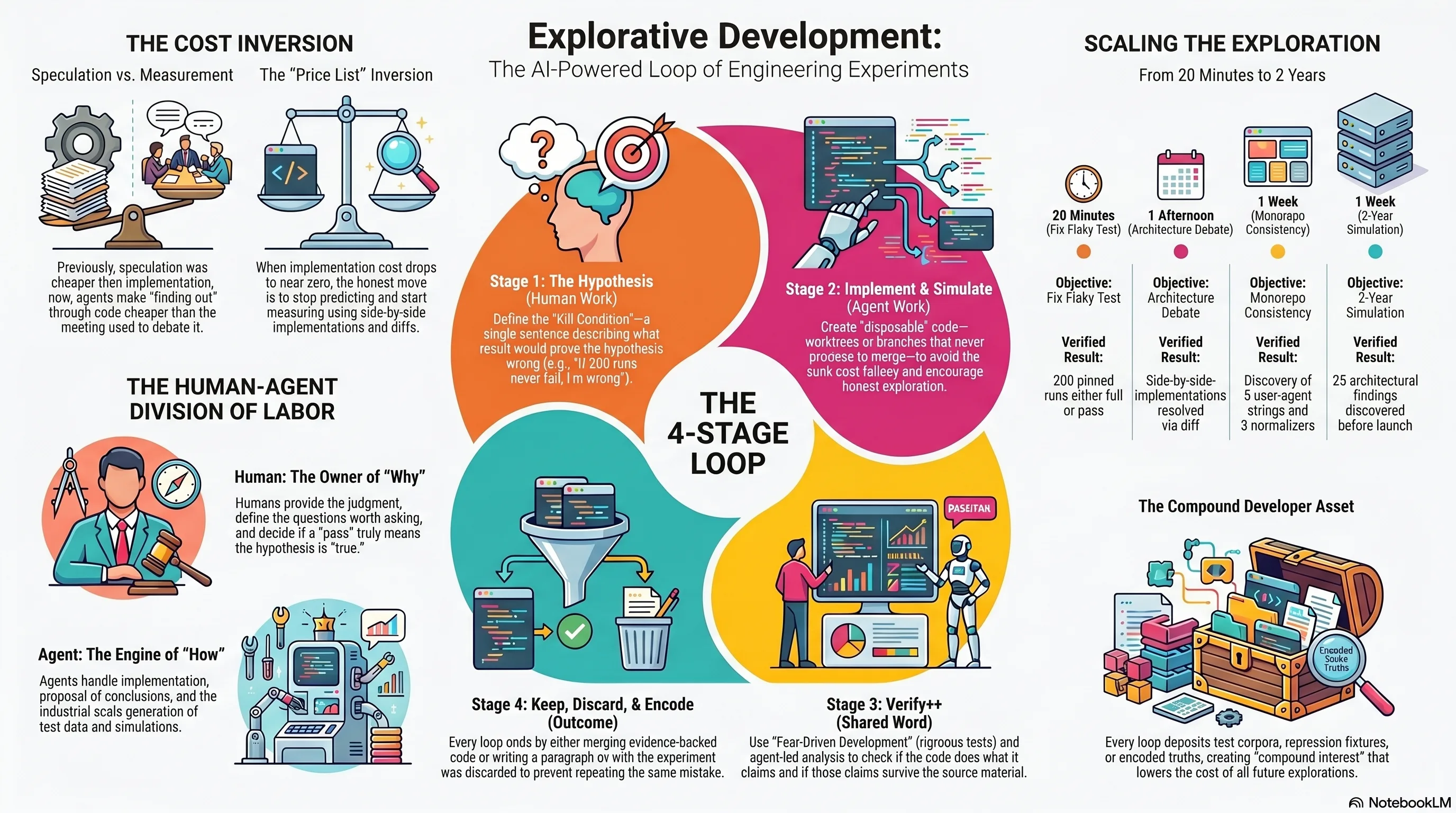
That run is the clearest recent example of how I've worked for years, and of what I've started calling the approach out loud: explorative development. An idea becomes a hypothesis. The hypothesis becomes the cheapest implementation or simulation that could prove it wrong. The result gets verified. What survives is kept — and what was learned gets encoded, either way.
It is not a new method. It's the scientific method wearing a hoodie. Two things are new: the price list, and the fact that I no longer run the loop alone.
The price of finding out¶
For most of my career, testing a hypothesis about a system cost days. So we didn't test hypotheses — we argued them. Design documents, architecture meetings, whiteboard debates: all elaborate machinery for avoiding implementation, because implementation was the expensive part. Speculation was cheaper than finding out, so organizations institutionalized speculation.
Agents inverted the price list. Implementation is now frequently cheaper than the meeting that would have debated it. "Would a side-by-side implementation be safer than refactoring in place?" used to be a discussion. Now it's an afternoon — you build it side-by-side, run both, and the discussion dissolves into a diff.
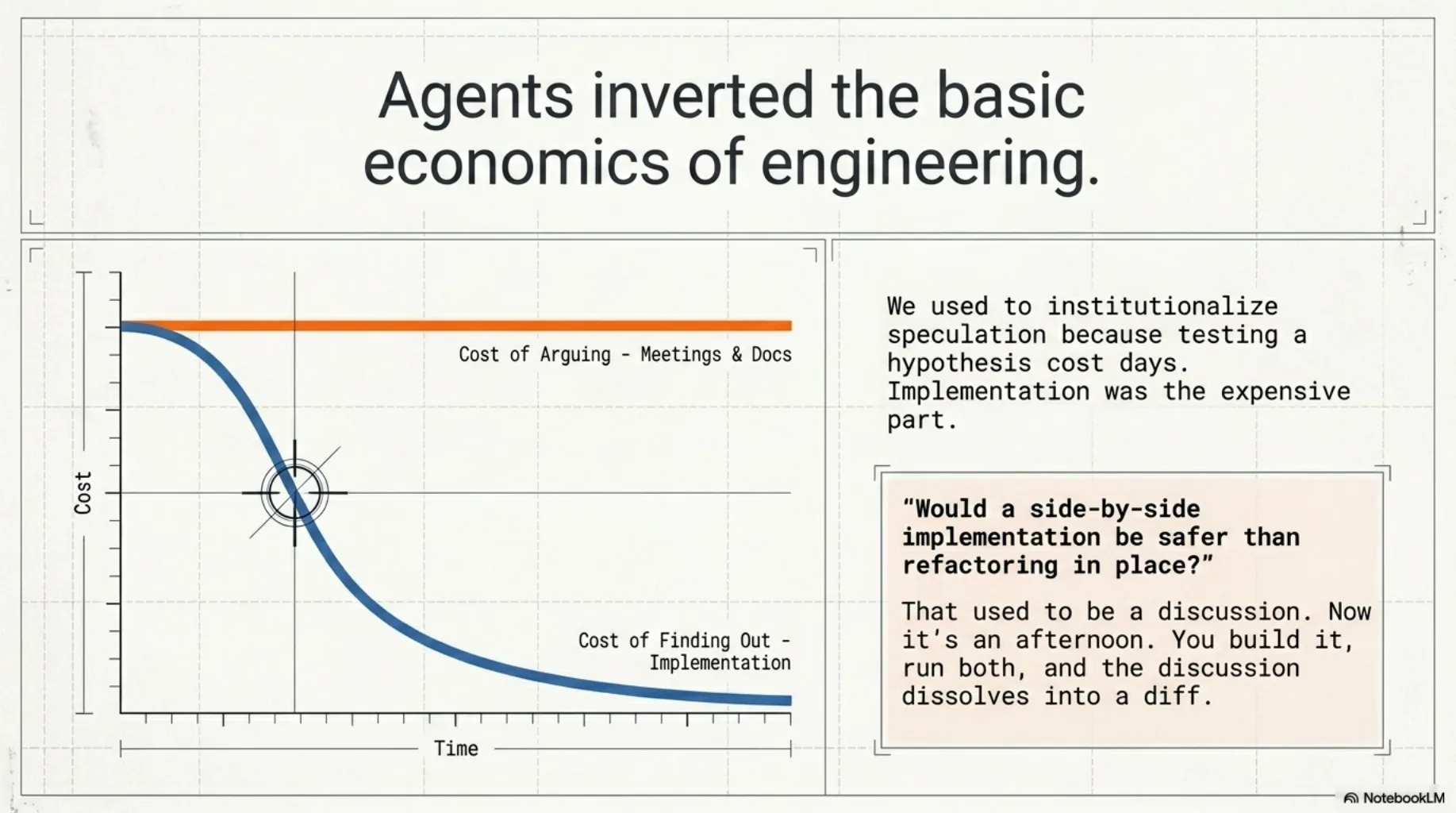
When finding out gets cheap, the honest move is to stop predicting and start measuring. Design docs argue. Experiments answer.

What follows is the loop as we actually run it — a human and a set of agents, with a division of labor that turns out to matter as much as the stages themselves.
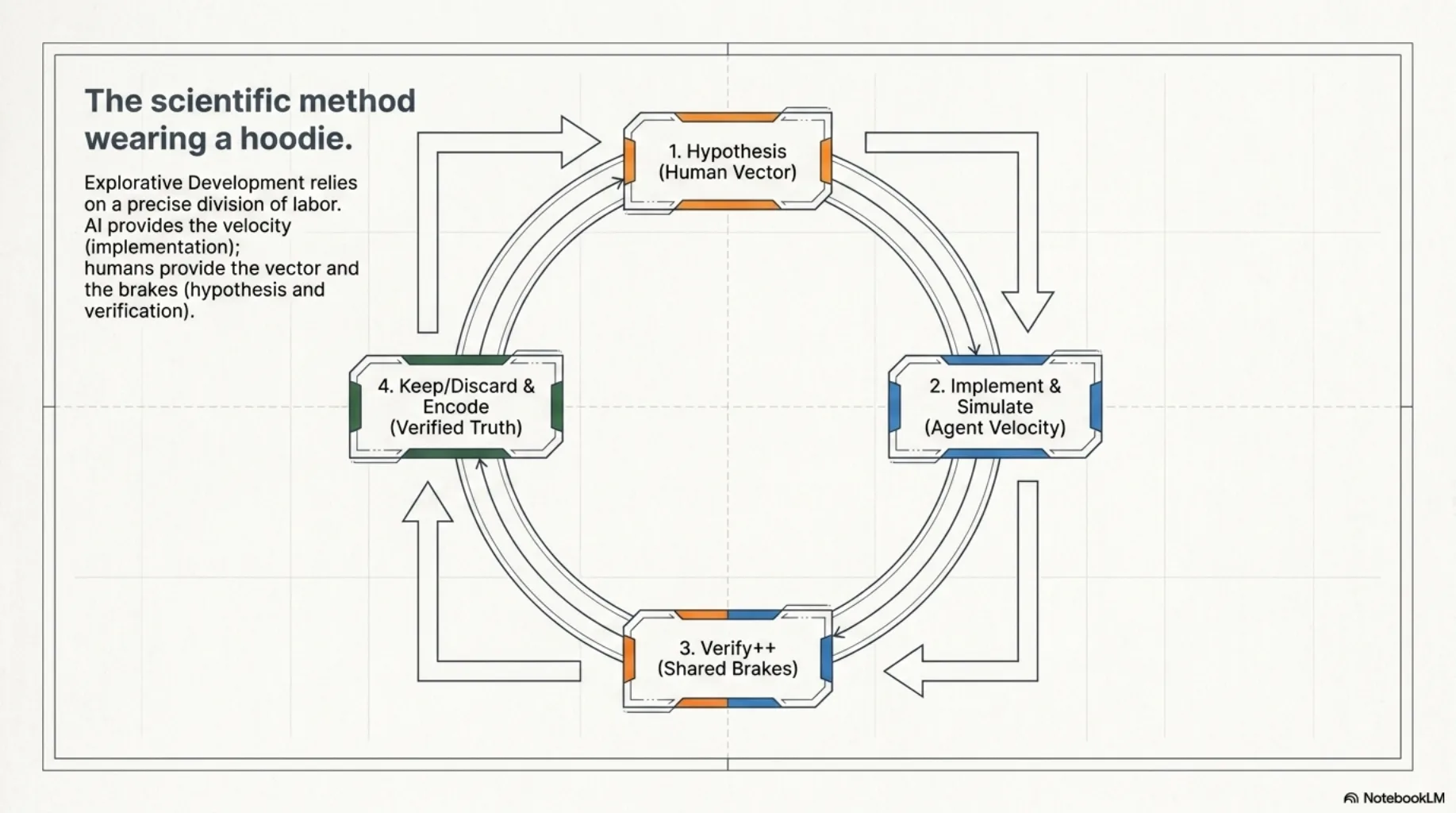
Stage 1: The hypothesis — human work¶
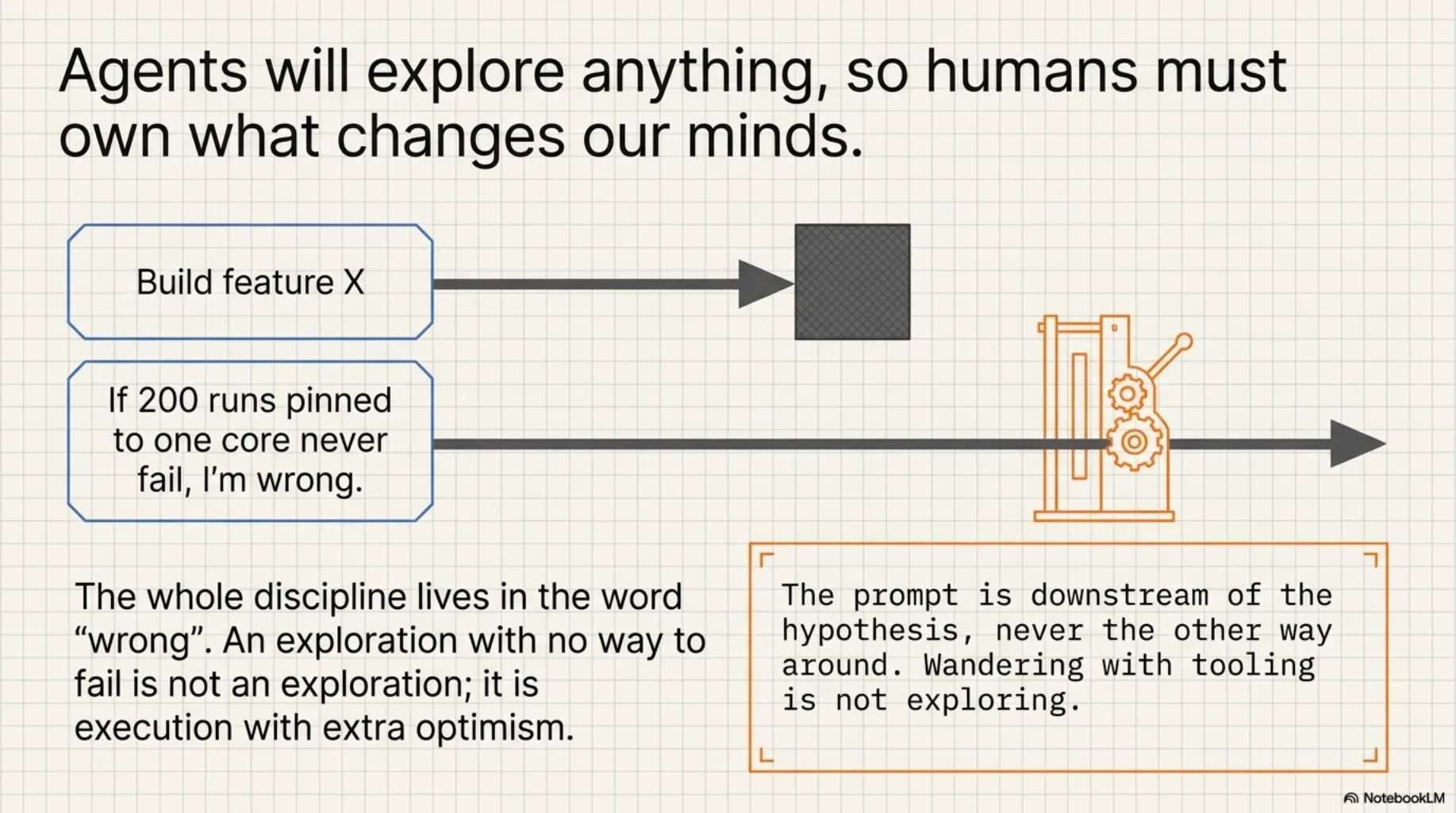
A task is "build feature X." A hypothesis is "I believe X will work, and here is the cheapest implementation that could prove me wrong."
That word — wrong — is the whole discipline. An exploration with no way to fail is not an exploration; it's execution with extra optimism. So before anything is dispatched, the hypothesis gets written down in one sentence, with a kill condition: "I believe this flaky test is timing-dependent; if two hundred runs pinned to one core never fail, I'm wrong."
This stage doesn't delegate. Agents are excellent at proposing implementations and terrible at telling you which question is worth asking — they will cheerfully explore anything, which is precisely why someone has to own what would change our mind. The prompt is downstream of the hypothesis, never the other way around. When I skip this and just start prompting, I'm not exploring. I'm wandering, with tooling.
Stage 2: Implement and simulate — agent work¶
This is the leg agents made nearly free, and the rule for it is: disposable by construction. Worktrees, side-by-side implementations, branches that never promise to merge. The courage to explore comes entirely from the cheapness of discarding — the moment an experiment is expensive to delete, you start defending it instead of testing it. Sunk cost is the natural predator of honest exploration.
When the hypothesis touches something where experiments are dangerous — live customers, real scores, production data — the implement leg becomes a simulate leg. Make reality replayable. Two examples from recent months, lightly anonymized:
- "We can restructure the scoring model without breaking existing customers' scores." — Not argued. Replayed: the new model run against regression fixtures snapshotted from the old reality, drift measured per fixture. Answer: ±2 points, worst case. Merged with the evidence attached to the pull request.
- "The feature's data model will survive contact with a real organization." — The twenty-four-month simulation from the top of this post. Simulating two years wasn't realism for its own sake; it was compressing the future into something a hypothesis can be tested against this week, instead of discovering the findings one angry customer at a time.
A simulation that shows ±2 points of drift is a verified hypothesis. A migration plan that predicts it is a guess with a deadline.
One sizing rule keeps this stage honest: if an experiment can't reach its verify step within a day, it isn't one hypothesis — it's three, stapled together. Slice it. Long-running explorations don't fail loudly; they drift into being projects, with all the attachment that brings.

Stage 3: Verify++ — shared work, human judgment¶
Here's the catch, and it's why this post wraps around the previous two.
Agents make the implement leg nearly free — which means they also make it nearly free to generate ten plausible wrong directions per day. Exploration without a strong verify leg isn't a method. It's vibes production at industrial scale.
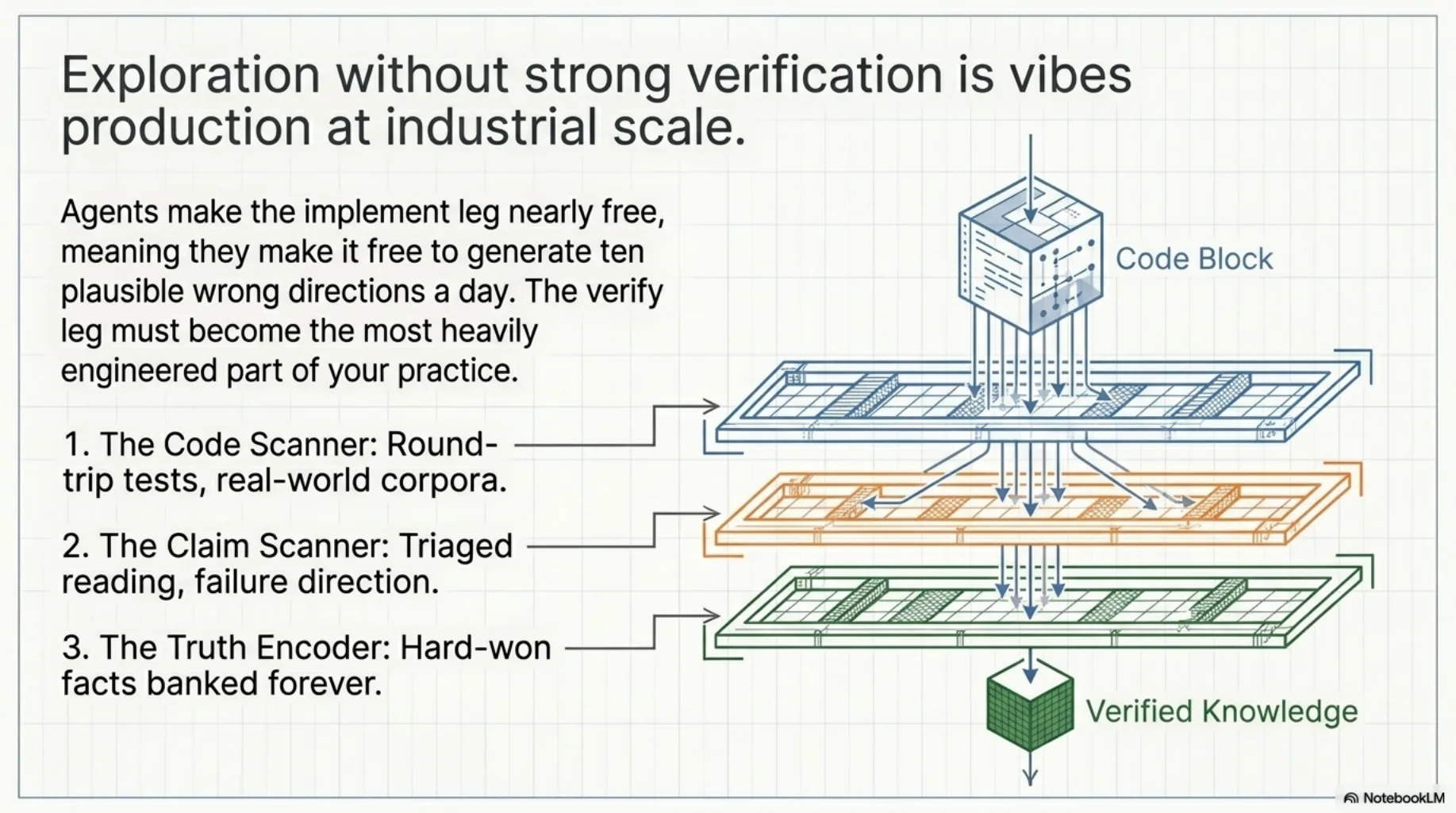
So the verify leg has quietly become the most engineered part of my practice, with three distinct instruments:
- Code gets tests. Round-trip tests, property-based tests, real-world corpora. That's Fear-Driven Development — fear with systems as a competitive advantage.
- Claims get reading, triaged by failure direction. Verify the assurances first; the false alarms can wait. That's False Alarms and False Assurances.
- Truths get encoded. Every verification produces a hard-won fact that can be spent once or banked forever. That's Organized Truths.
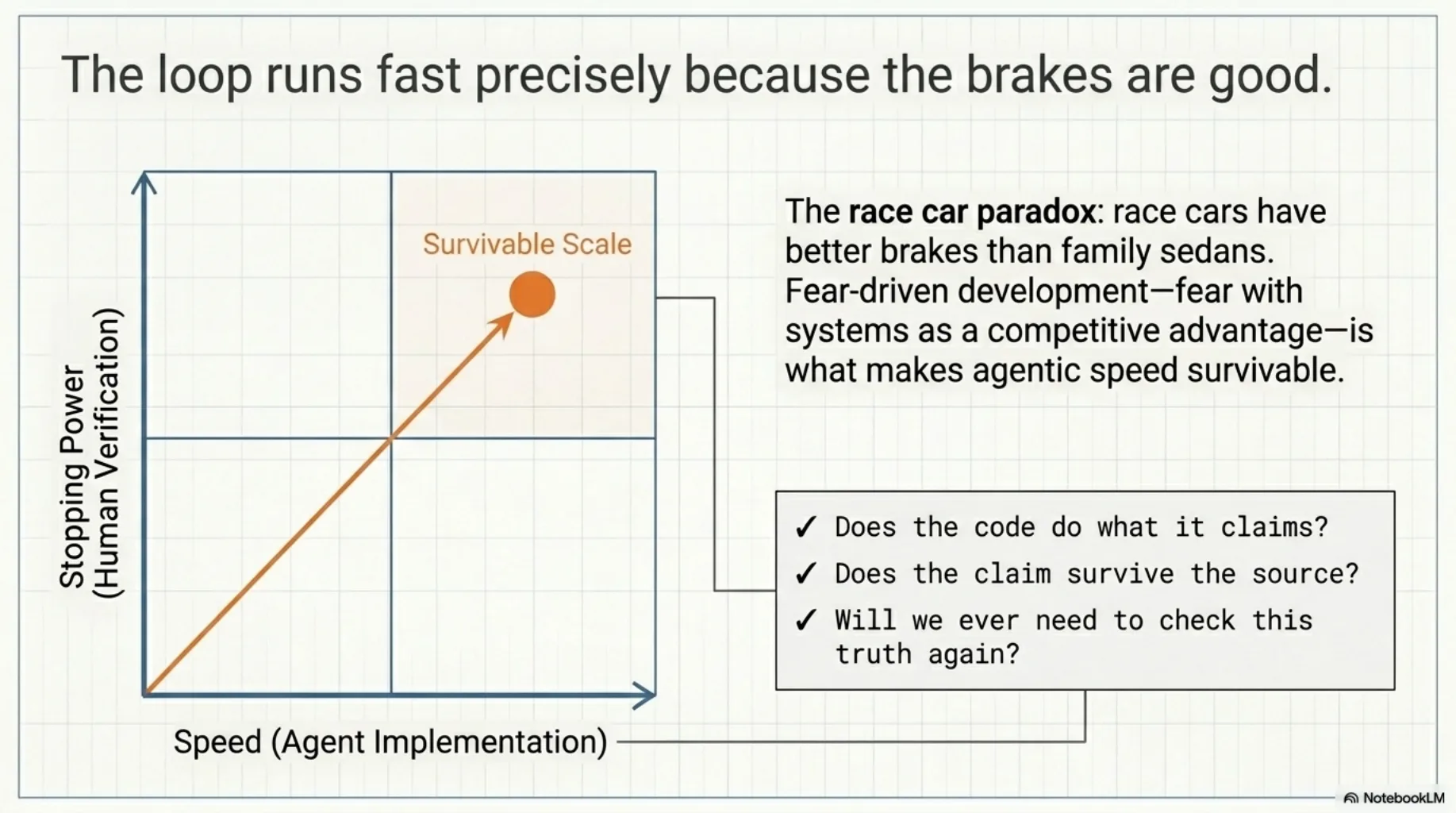
The division of labor here is precise: agents run the tests, draft the analyses, propose the conclusions. The judgment — which claims get read against the source, whether the kill condition actually triggered, whether "passing" means "true" — does not delegate. Same checkpoint, three altitudes: does the code do what it claims, does the claim survive the source, will we ever need to check this truth again.
The loop runs fast because the brakes are good. That's not a paradox; it's the same reason race cars have better brakes than family sedans.
Stage 4: Keep, discard — and either way, encode¶
Every loop ends in one of two outcomes, and both are results.
A kept experiment merges with its evidence attached. A discarded one earns a paragraph — which version won, why, what the kill condition showed — written where the next session will find it. Skip that paragraph and you're quietly signing up to run the same experiment again later.
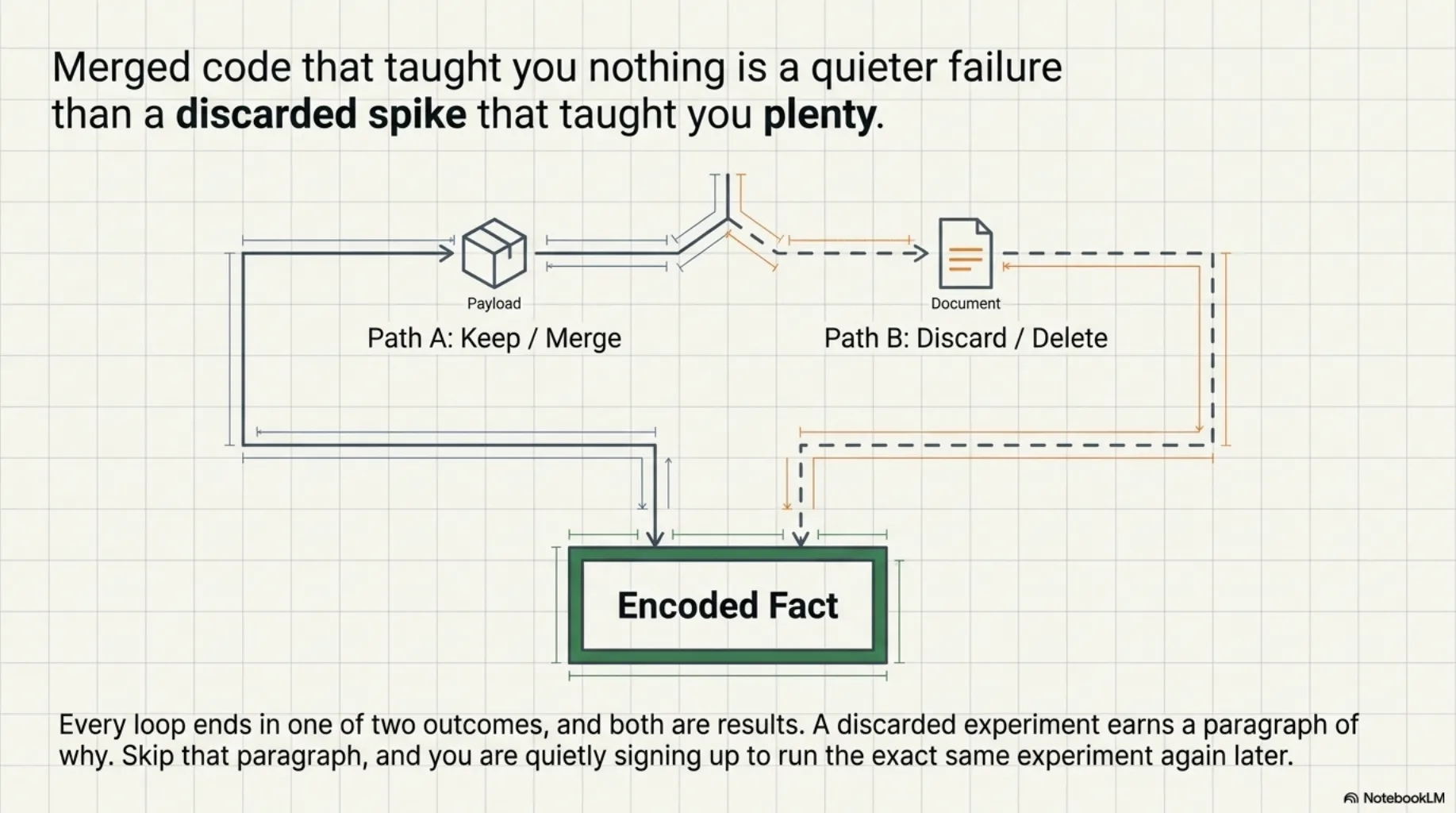
This reframes the scoreboard. The failure mode of explorative development isn't discarding too much — it's loops that end without an answer. Merged code that taught you nothing is a quieter failure than a discarded spike that taught you plenty. Ask of every loop: what do we now know? If the answer is "nothing, but it shipped," the loop ran; the method didn't.

One loop, every scale, every artifact¶
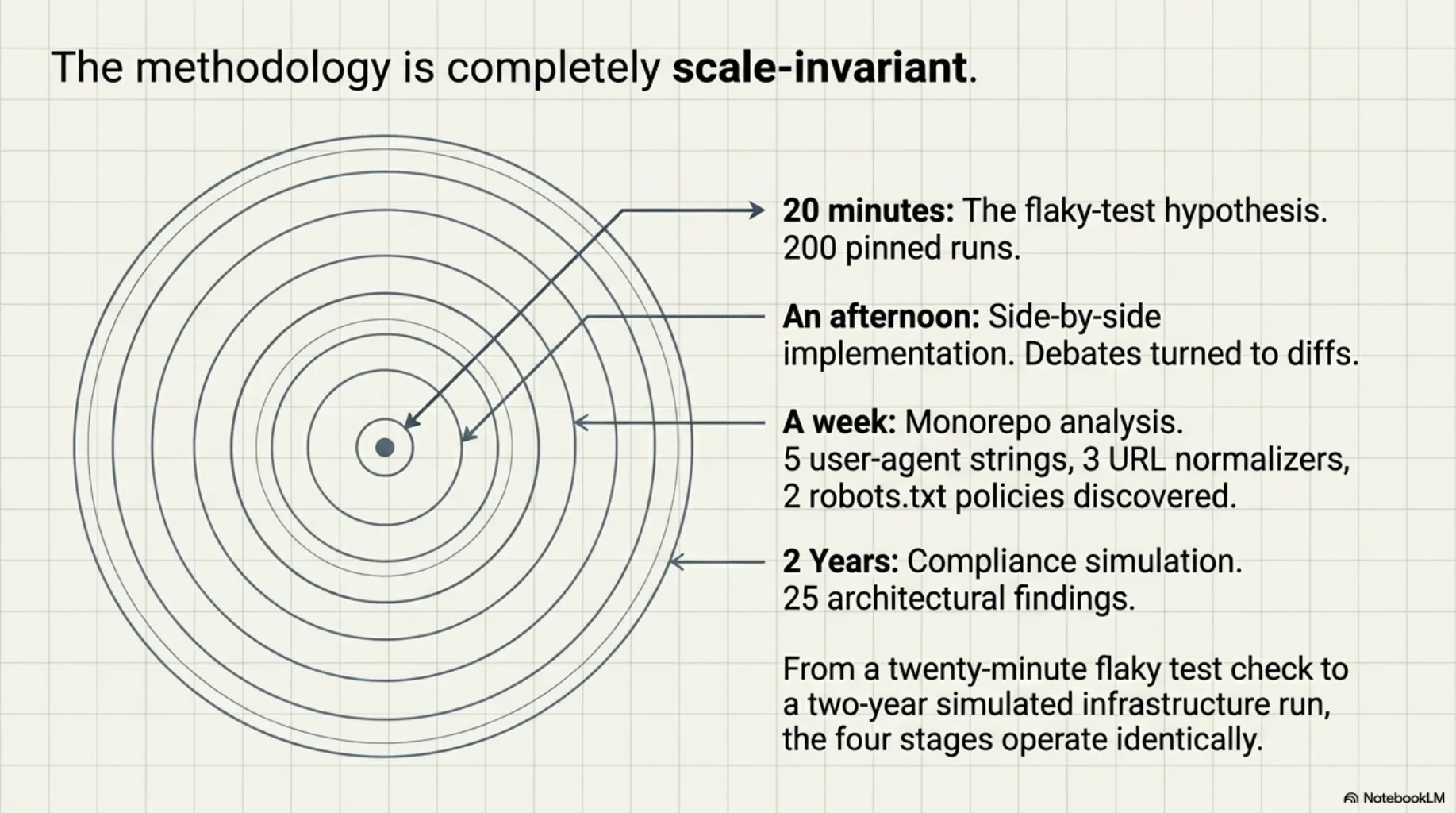
What convinced me this deserves a name is that the same four stages run unchanged at every scale we work at:
- Twenty minutes: the flaky-test hypothesis. Two hundred pinned runs. An answer either way.
- An afternoon: the side-by-side implementation that turns an architecture debate into a diff.
- A week: this week's hypothesis was "we have several web scrapers in this monorepo, and they've diverged" — explored by parallel agents, verified against source, answered with two architecture reports. Confirmed, with more precision than I expected: five user-agent strings, three URL normalizers, two robots.txt policies.
- Two simulated years: the compliance simulation. Twenty-five findings before a customer existed.
And not just for code. The loop produces features, reports, methodology — and infrastructure. The organized-truths corpus from the previous post is itself the residue of hundreds of these loops: truths verified once, encoded, never re-verified. Which closes a satisfying circle: exploration built the infrastructure that makes exploration cheaper. Each loop deposits something that lowers the cost of the next one. That's not a productivity curve; it's compound interest.

The wrap¶
Fear-driven development and explorative development sound like opposites. One is anxiety codified into tests; the other is curiosity codified into experiments. In practice they're the same discipline at two moments in time: explore boldly because you verify fearfully.
The residue is the asset. Every loop leaves something behind — a test corpus, a regression fixture, a simulation finding, an encoded truth, a sharper sense of which experiments tend to win. That accumulation is what the compound developer is actually accumulating: not the speed of any single loop, but everything the loops deposit.
The agents made finding out cheap. The practitioner's job is to make finding out count.

The whole framework on one page¶
There is also a slide deck version of this post (PDF) if you want to walk a team through it.
This wraps a thread on verification in AI-augmented development: Fear-Driven Development (verifying code), False Alarms and False Assurances (verifying claims), Organized Truths (encoding the verification). This one is about the loop they all serve — and who does what inside it.