Organized Truths¶
Practitioner notes on the verification you only do once.
In the previous post I described catching an agent claiming a parser was "fully RFC compliant." I caught it by opening the RFC — four minutes of reading against a parser that handled none of the wildcard support the spec requires.
The tips in that post were about catching such claims. This post is about a better question that took me longer to ask:
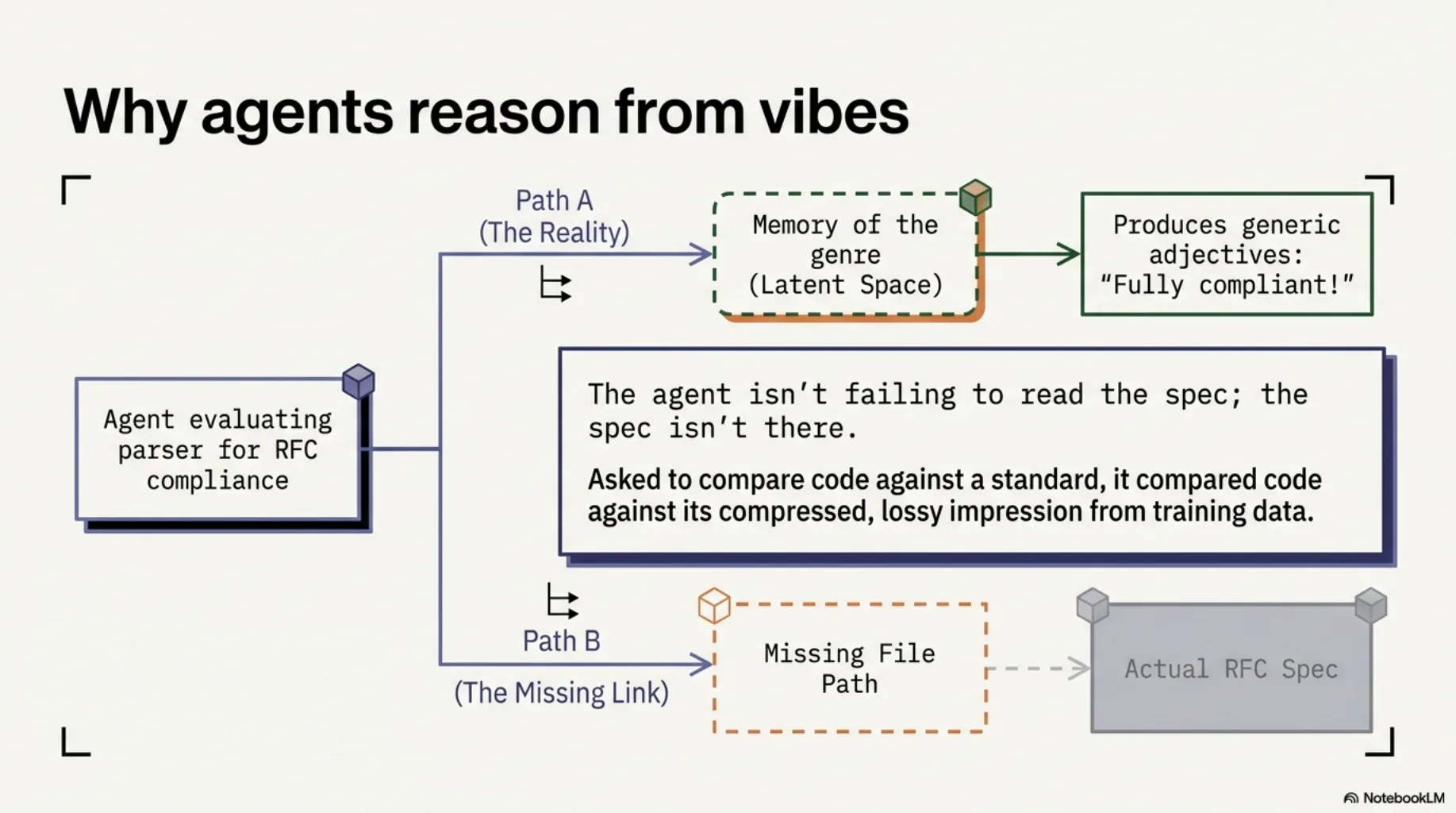
Why did the agent never open the RFC?
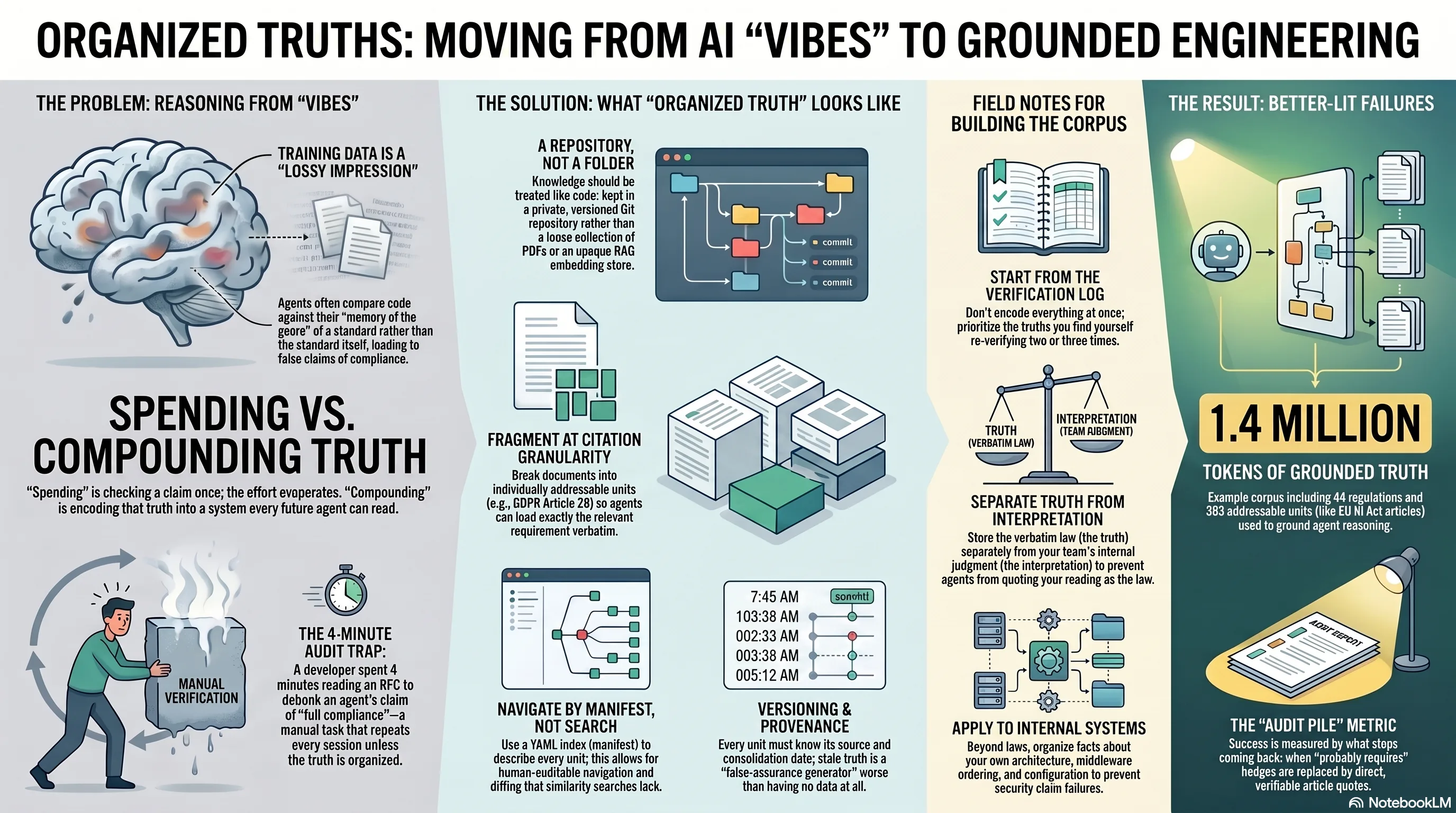
Not because it couldn't read it. Because the RFC wasn't there. The agent had the parser in its context and the spec in its vibes — a compressed, lossy impression from training data. Asked to compare code against a standard, it compared code against its memory of the genre of that standard. Of course it produced an adjective.
You can audit that failure forever. Or you can change what the agent reasons from.
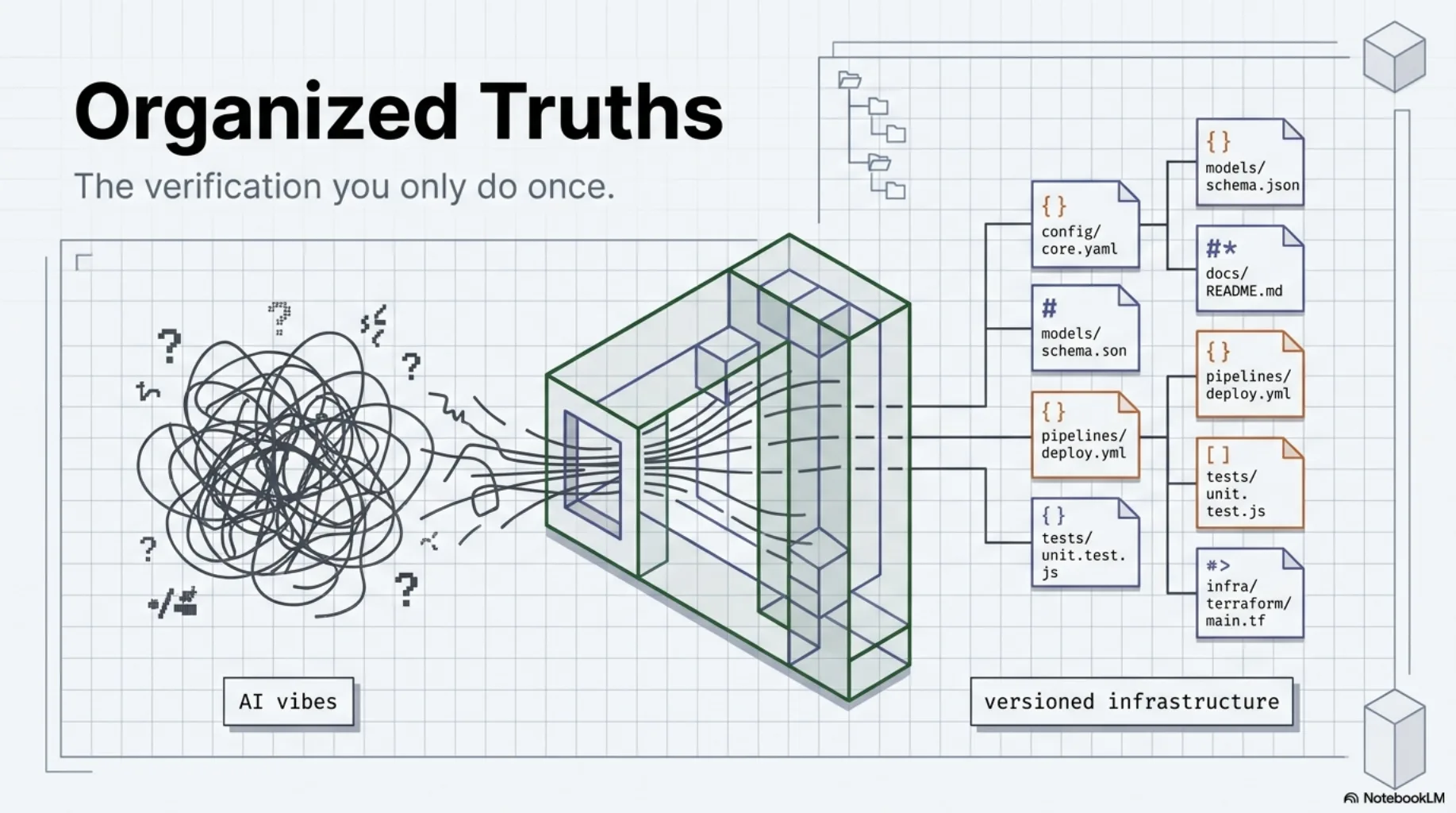
Verification doesn't compound. Truth does.¶
Every verification ends with you holding a small, hard-won truth: the RFC requires wildcard support. Article 28(3) demands specific contract terms of processors. The auth lives in the middleware chain, twelve lines up.
The defensive practitioner spends that truth once — strikes a finding, fixes a report — and the truth evaporates when the session ends. Next month a different agent, in a different session, makes the same class of claim, and you do the same four minutes of reading. The seven tips from the previous post make that audit fast. They don't make it stop.
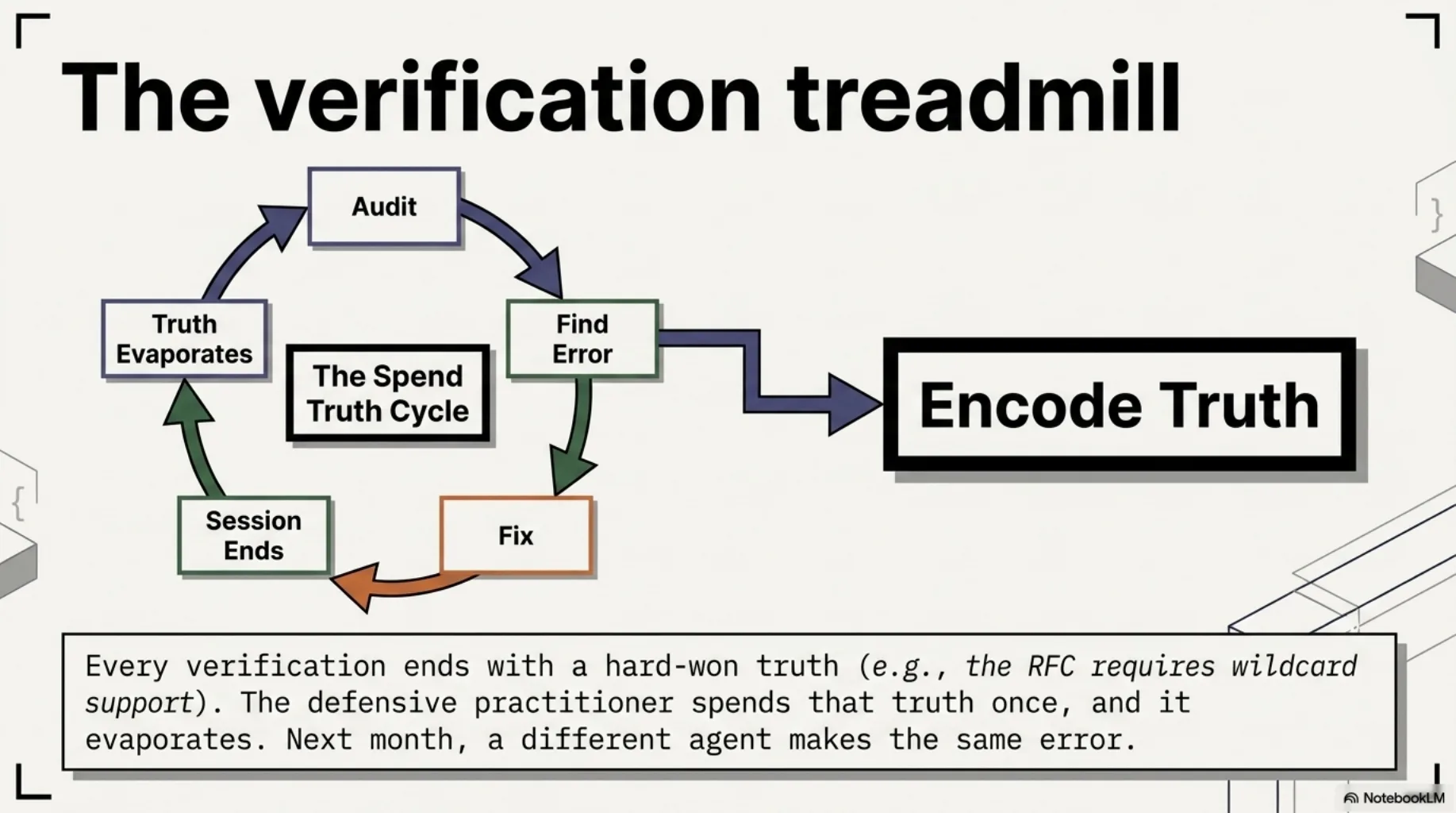
The compounding move is to encode the truth instead of spending it: into an organized, versioned corpus that every future agent reads before it makes claims. The actual spec text. The actual law. Structured at the granularity you cite it at, with provenance.
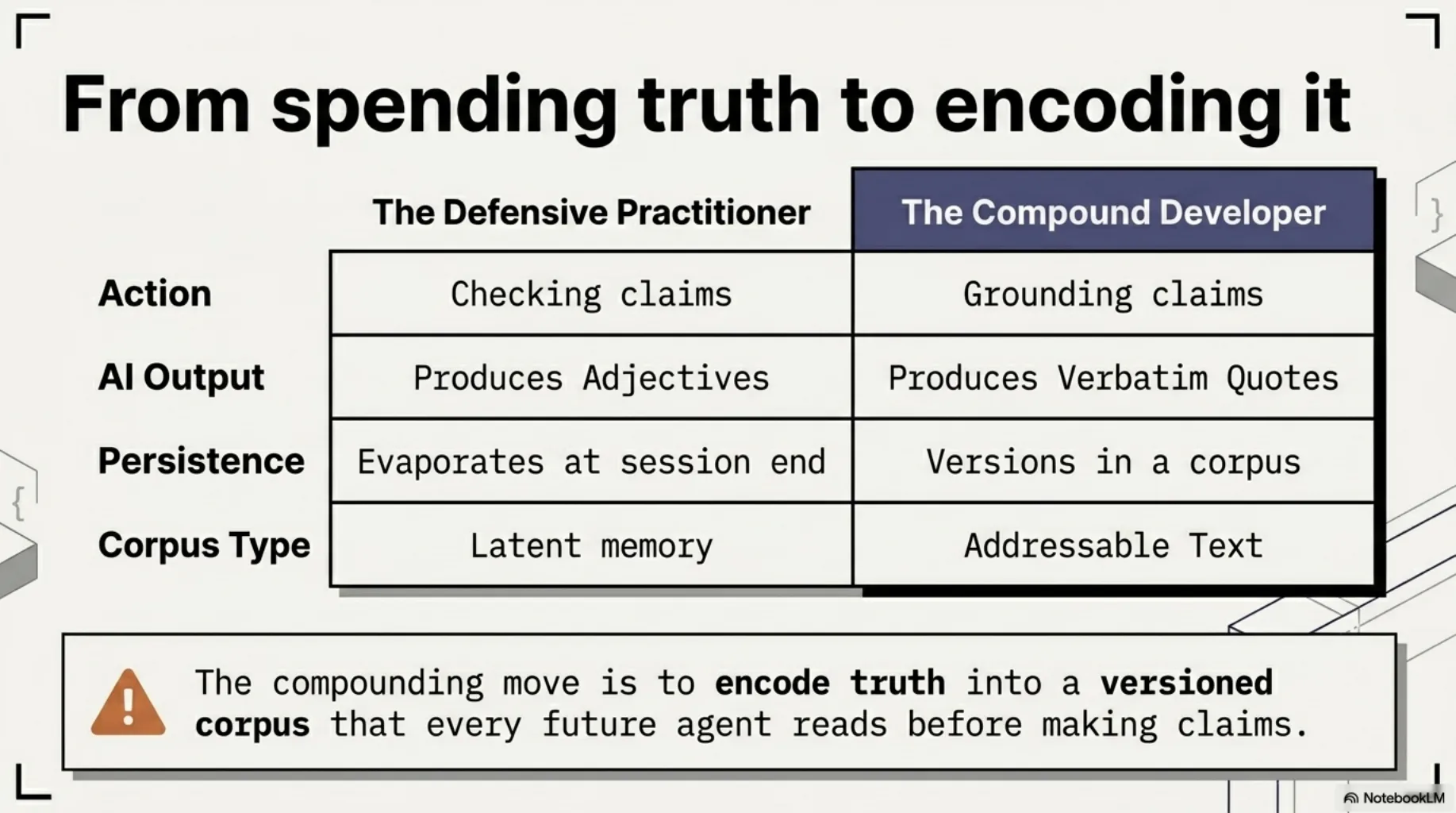
This is the difference between checking claims and grounding them. An agent reasoning about "GDPR compliance" from training data produces adjectives. An agent handed the organized text of the regulation produces references — and its claims arrive pre-attached to the very instrument you would have verified them against anyway.
What organized truth actually looks like¶
Not a folder of PDFs. Not "we have RAG." Dumping documents into an embedding store gives you vibes with extra steps — opaque recall you can't audit, retrieving fragments you can't address.
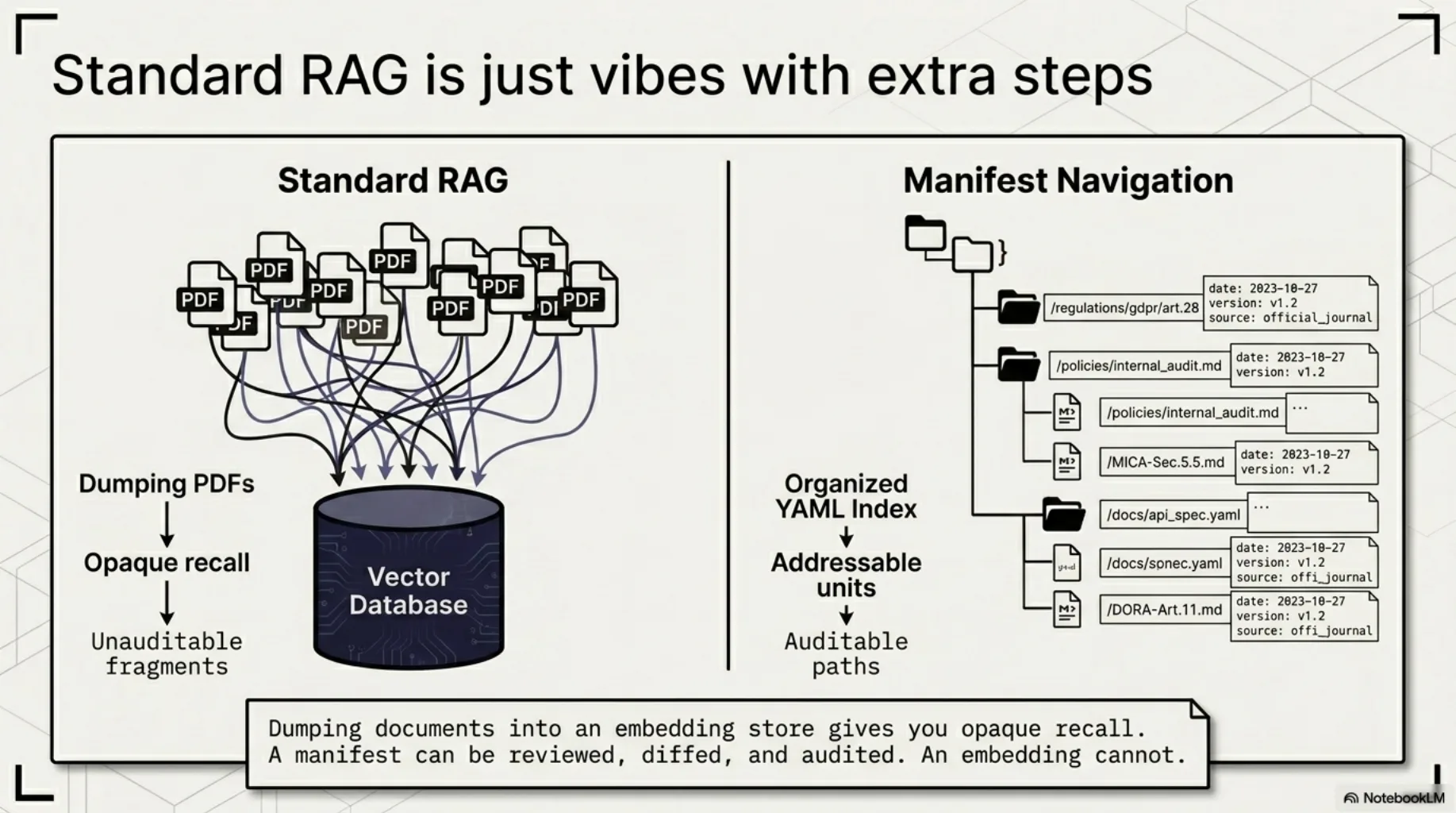
The version that works, in my experience, looks like a codebase:
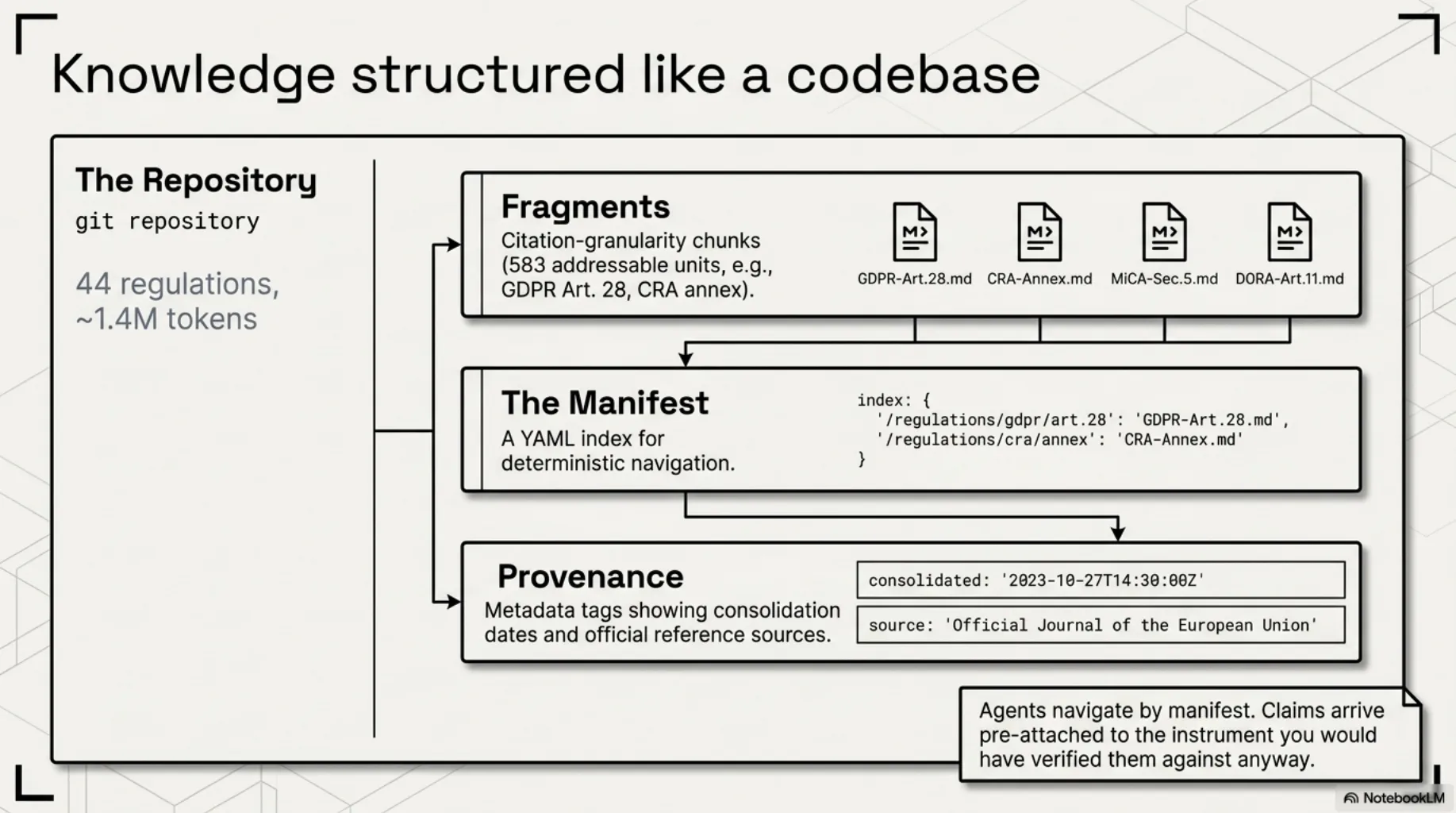
- A repository. Ours is a private knowledge base for compliance work: 44 regulations and frameworks, ~1.4 million tokens of source text, under git like everything else we maintain.
- Fragments at citation granularity. All 99 GDPR articles as individually addressable units. All 113 EU AI Act articles. Every CRA annex. 583 addressable units in total — because compliance claims cite articles, not documents, and the agent should load exactly the article in question, verbatim.
- A manifest. A YAML index describing every unit: what it is, where it came from, what it covers. Agents navigate by manifest, not by similarity search. A manifest can be reviewed, diffed, and audited. An embedding can't.
- Provenance and versions. Laws change. Each unit knows its source, its consolidation date, its official reference. A stale truth presented as current is a false-assurance generator — strictly worse than no corpus at all.
The result: when an agent assesses a supplier's data-processing agreement, it doesn't reason about what GDPR Article 28 "probably says." It loads Article 28. The claim it produces quotes the requirement it's checking against. My audit collapses from open the law and compare to check the quote — and usually to nothing, because a claim with the instrument attached fails in much more visible ways than a claim made from vibes.
Field notes: building the corpus¶
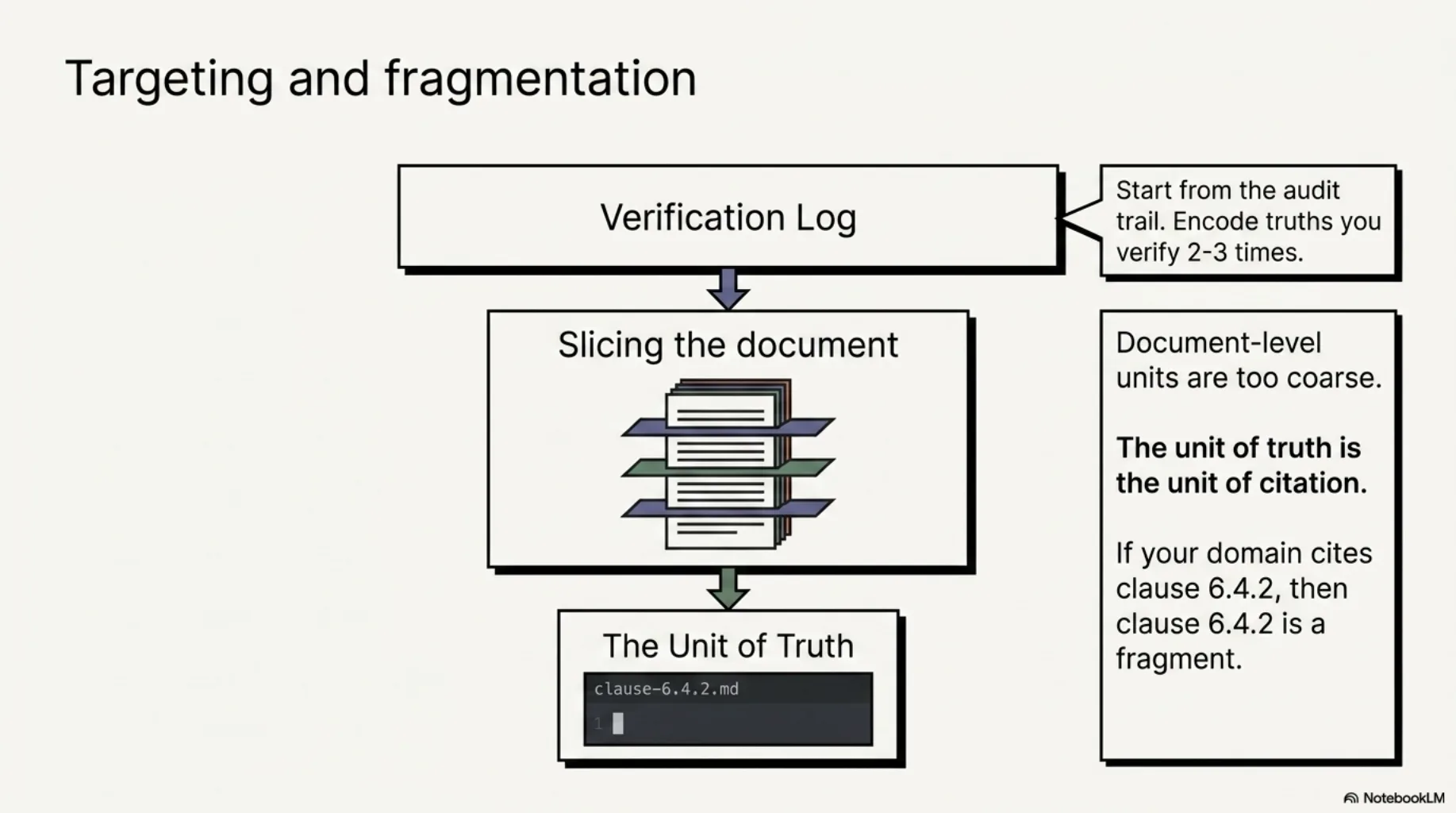
1. Start from your verification log, not from ambition. Don't set out to encode "all relevant standards." Encode the truths you keep re-verifying. Every claim you've personally checked twice is a candidate; three times is a backlog item. The corpus grows out of the audit trail — which guarantees it covers the claims that actually occur, in the order they actually cost you time.
2. Fragment where citations point. Document-level units are too coarse — an agent given the whole regulation will skim it the way it skims everything, and you're back to vibes with better sourcing. The unit of truth is the unit of citation: the article, the requirement, the annex section. If your domain cites clause 6.4.2, then clause 6.4.2 is a fragment.
3. Separate truths from interpretations. The text of Article 28 is a truth. "This means our DPA template needs a sub-processor approval clause" is an interpretation — yours, dated, revisable. Store both; label them differently. Interpretations are valuable precisely because they encode judgment, but an agent must never be able to quote your reading of the law as if it were the law.
4. Versioning is part of the truth. Regulations get amended, consolidated, replaced. A corpus without dates rots silently — and unlike code rot, truth rot produces confident, well-cited, wrong claims. Pin every unit to its consolidation date, and treat "is this still current?" as a maintenance task with an owner, the same as dependency updates.

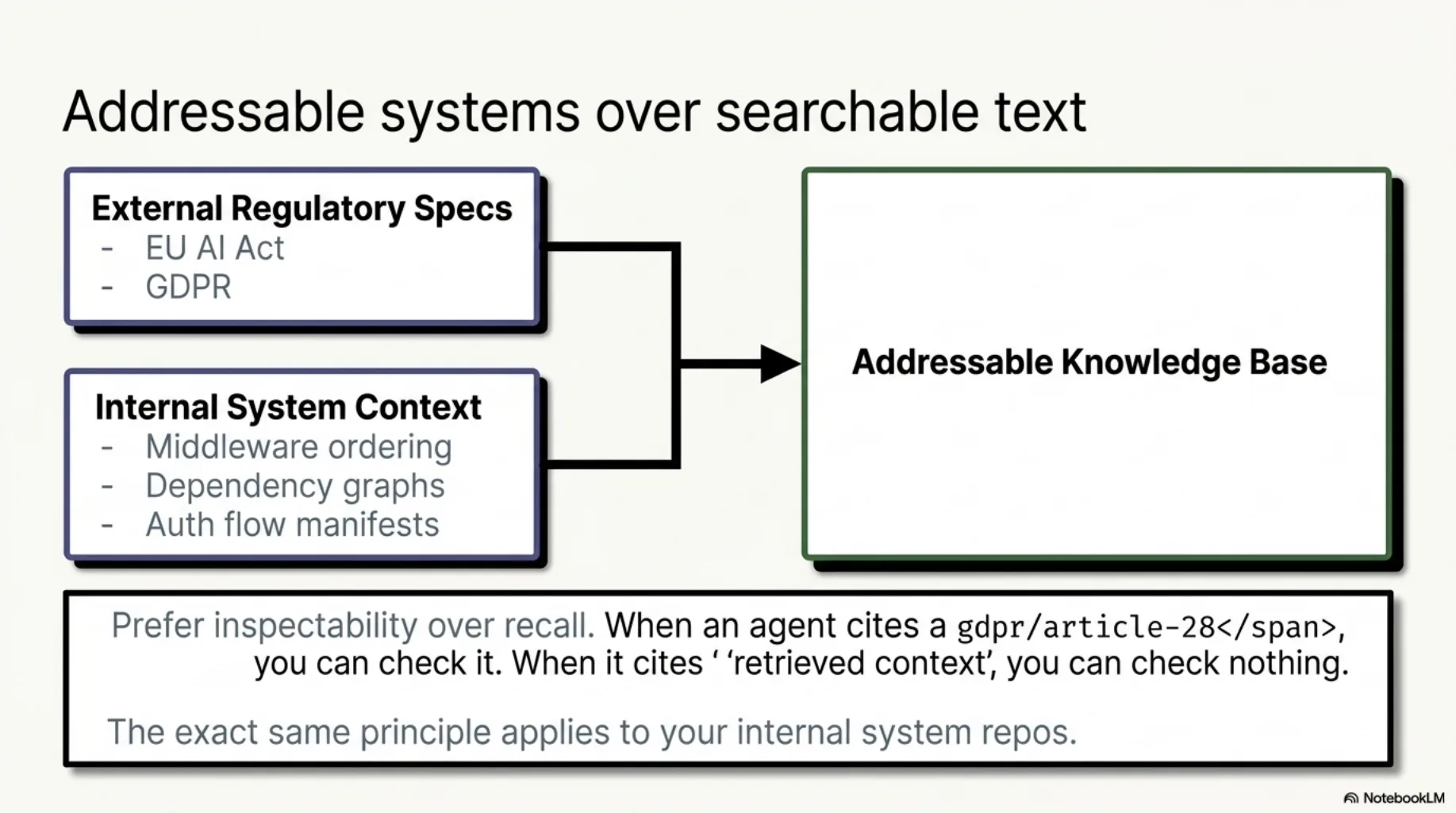
5. Prefer addressable over searchable.
Inspectability beats recall. When an agent's claim cites gdpr/article-28 you can open that exact unit and check; when it cites "retrieved context" you can check nothing. If you do add similarity search later, add it as navigation over the manifest — never as a replacement for it.
6. The same move works on your own systems. Laws and specs are the obvious corpus, but the previous post's worst failures were context claims — middleware ordering, load order, configuration. Those truths live in your repos, and they can be organized too: architecture manifests, dependency graphs, "how auth actually works here" documents that agents load before making security claims. The principle is identical — replace the agent's impression of your system with addressable facts about it.
7. Measure by what stops coming back. The corpus is working when categories of claims disappear from your audit pile. We stopped seeing "probably requires" hedges on GDPR claims — they became article quotes, right or visibly wrong. That's the metric: not coverage, not token counts, but the verification you no longer perform.
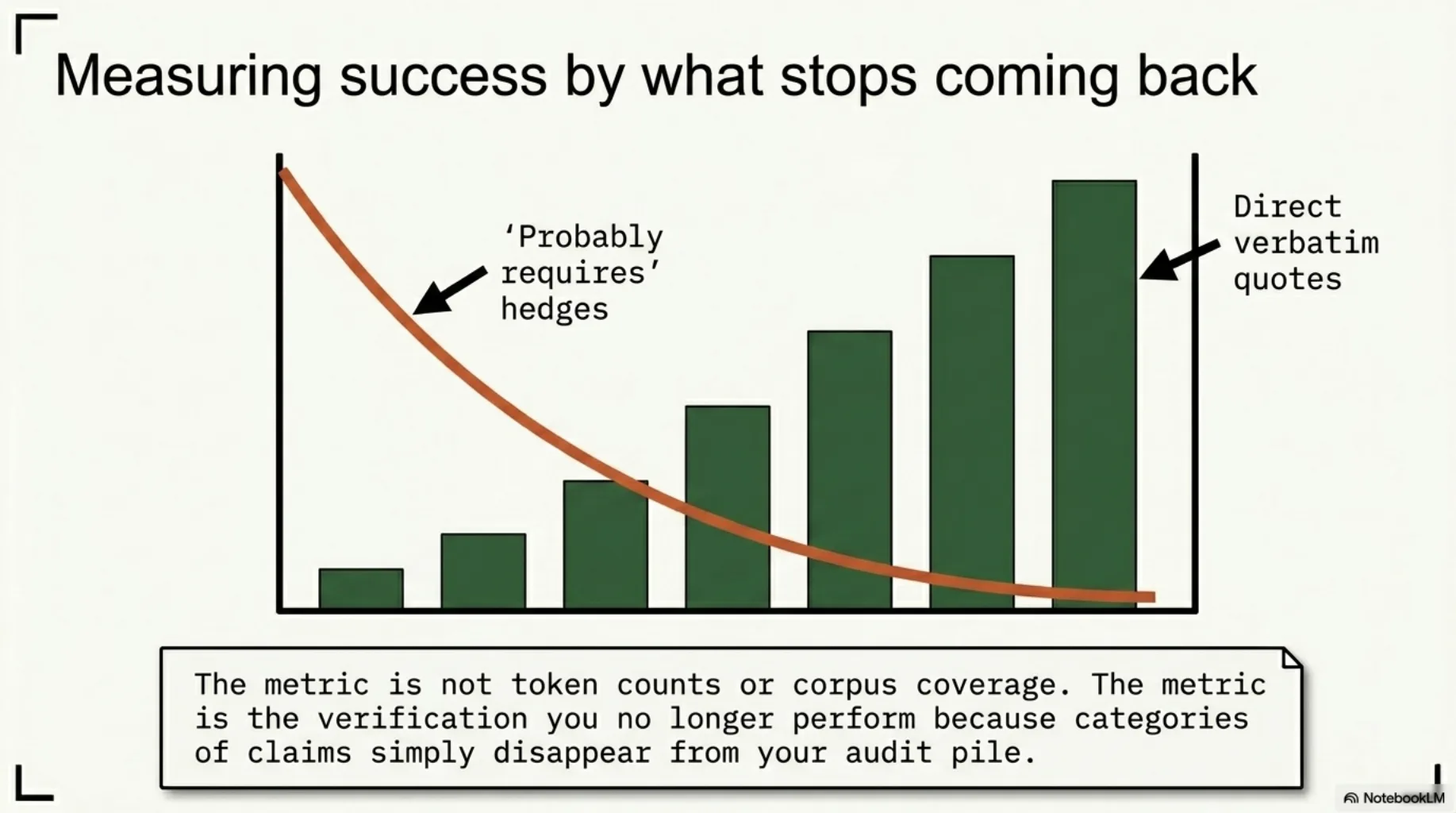
The honest limits¶
Organized truths don't make the previous post's discipline obsolete. An agent can quote Article 28 perfectly and still misjudge whether a clause satisfies it — grounding fixes the premises, not the reasoning. Claims still fail; they just fail in better-lit places.
And the maintenance is real work. Someone has to notice the amendment, re-fragment the consolidated text, review the diff. But notice what kind of work it is: applying legal and architectural judgment, once, where it permanently changes what every future agent can know. That's not overhead on the real work. For the compound developer, it increasingly is the real work.

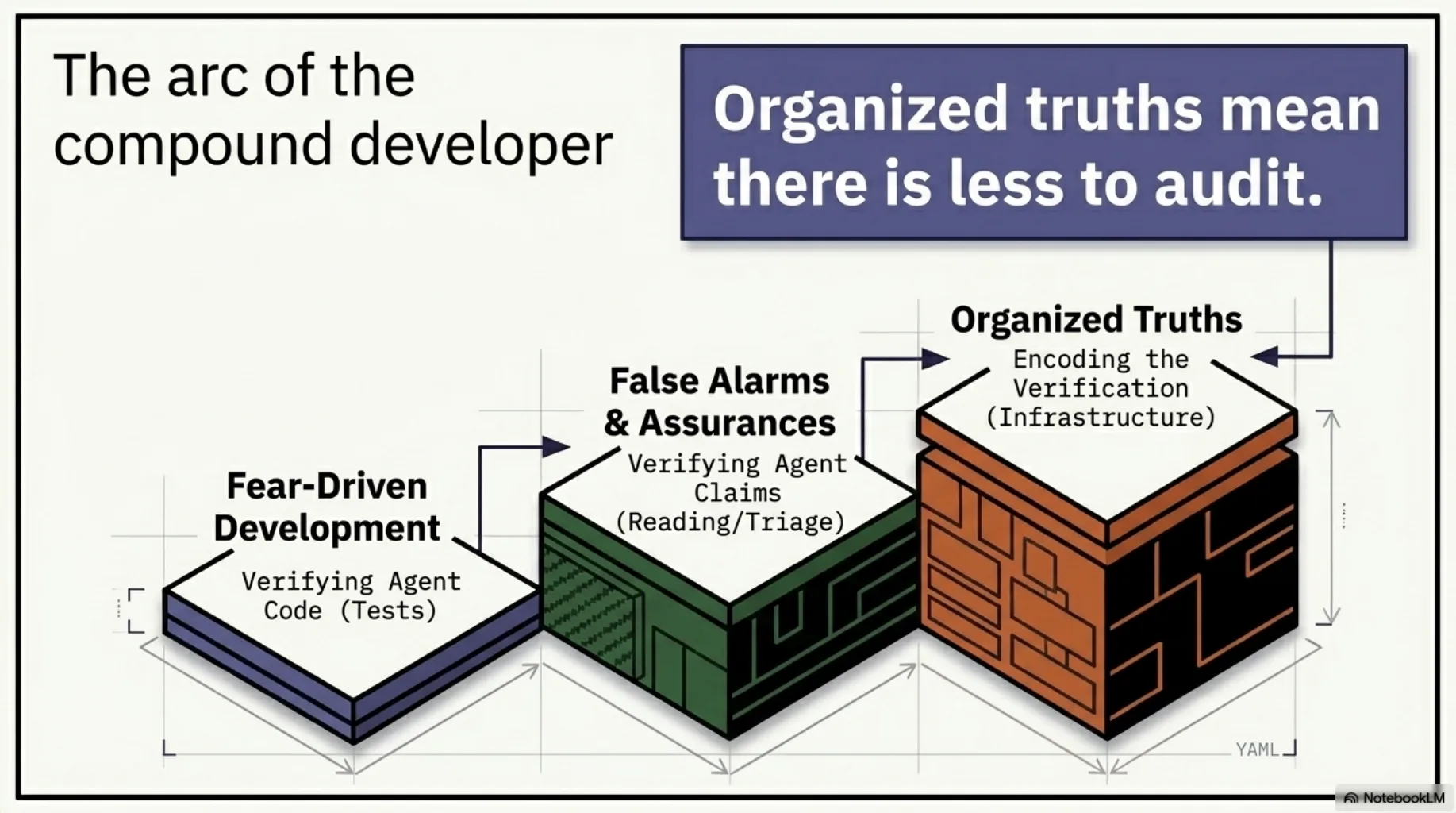
The arc, completed¶
Fear-Driven Development was about verifying agent code — tests do that. False Alarms and False Assurances was about verifying agent claims — reading does that, triaged by which way the claim would fail.
This post is about the part that compounds: every verification you perform is a truth you can either spend or encode. The seven tips make you a better auditor.
Organized truths mean there is less to audit.
The whole framework on one page¶
There is also a slide deck version of this post (PDF) if you want to walk a team through it.
Third in a thread on verification in AI-augmented development: Fear-Driven Development → False Alarms and False Assurances → this. The corpus described here is built on KCP (Knowledge Context Protocol) — see KCP Tools: from instrumentation to infrastructure for that lineage.