False Alarms and False Assurances¶
Practitioner notes on verifying what your agents tell you.
This week an agent told me, confidently, that an API endpoint had no authentication.
It did. The router was mounted twelve lines after the auth middleware. The agent had read the route file — clean, self-contained, no auth code in sight — and reported what it saw. What it saw was true. What it concluded was false.
The same afternoon, two more claims from the same research run didn't survive contact with the source: a parser described as "fully RFC compliant" (it lacked the wildcard support the RFC requires), and a plugin described as "active" (it was active only because of an import side effect in an unrelated legacy file — a load-order accident no test asserted).
Three wrong claims, one afternoon, inside an otherwise excellent piece of agent research that compressed days of code archaeology into hours. This is not a complaint about agents. It is a job description for the human.

Code has tests. Claims don't.¶
A year ago the verification conversation was about AI-generated code, and we have a decent answer there: tests. Round-trip tests, property-based tests, real-world corpora. Fear with systems is a competitive advantage — I've written about that before.
But more and more of what agents produce for me isn't code. It's claims. "This endpoint is unauthenticated." "These two modules duplicate each other." "This library is unused." "This is compliant with the spec." Claims end up in architecture reports, security assessments, migration plans — documents that drive decisions and carry your name.
There is no test suite for a sentence. You cannot CI a paragraph. The verification instrument for claims is older and less glamorous: reading the source.

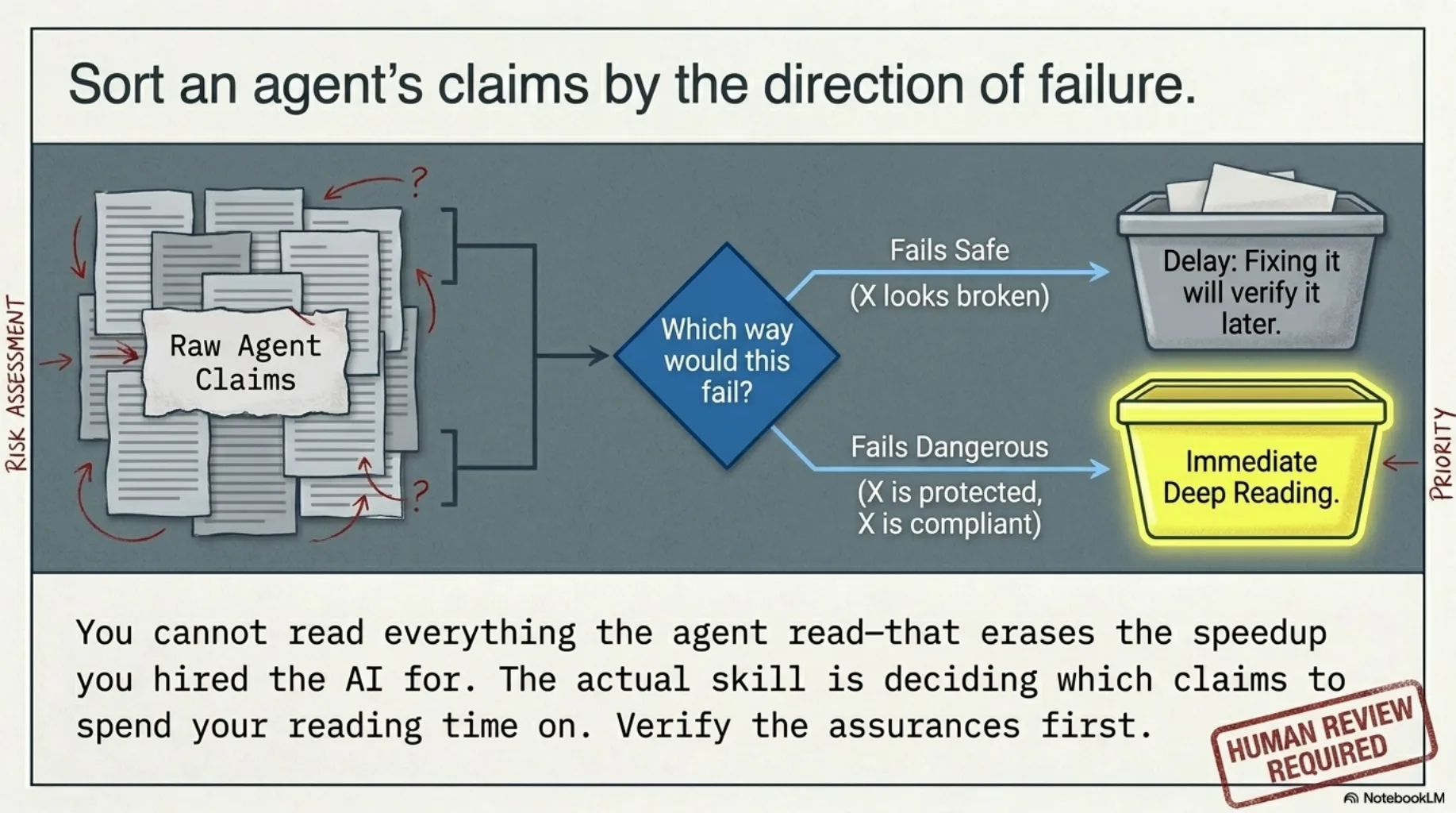
And since you cannot read everything the agent read — that would erase the speedup you hired the agent for — the actual skill is deciding which claims to spend reading on. That's a judgment problem, and it has structure.
The asymmetry that does the sorting¶
Look again at my three wrong claims:
- "No authentication" — a false alarm. The system was safer than reported.
- "Fully RFC compliant" — a false assurance. The system was worse than reported.
- "The plugin is active" — a false assurance. The protection was an accident, not a guarantee.
These failure modes are not symmetric.
A false alarm costs you an hour. You investigate, find the middleware, strike the finding, move on. Mildly embarrassing if it ships; cheap if it doesn't.
A false assurance is the dangerous one. It tells you a control exists that doesn't, that a standard is met that isn't, that you can stop worrying. False assurances don't cost an hour — they cost an incident, an audit finding, a decision built on sand. And they are invisible by default: nobody investigates good news.
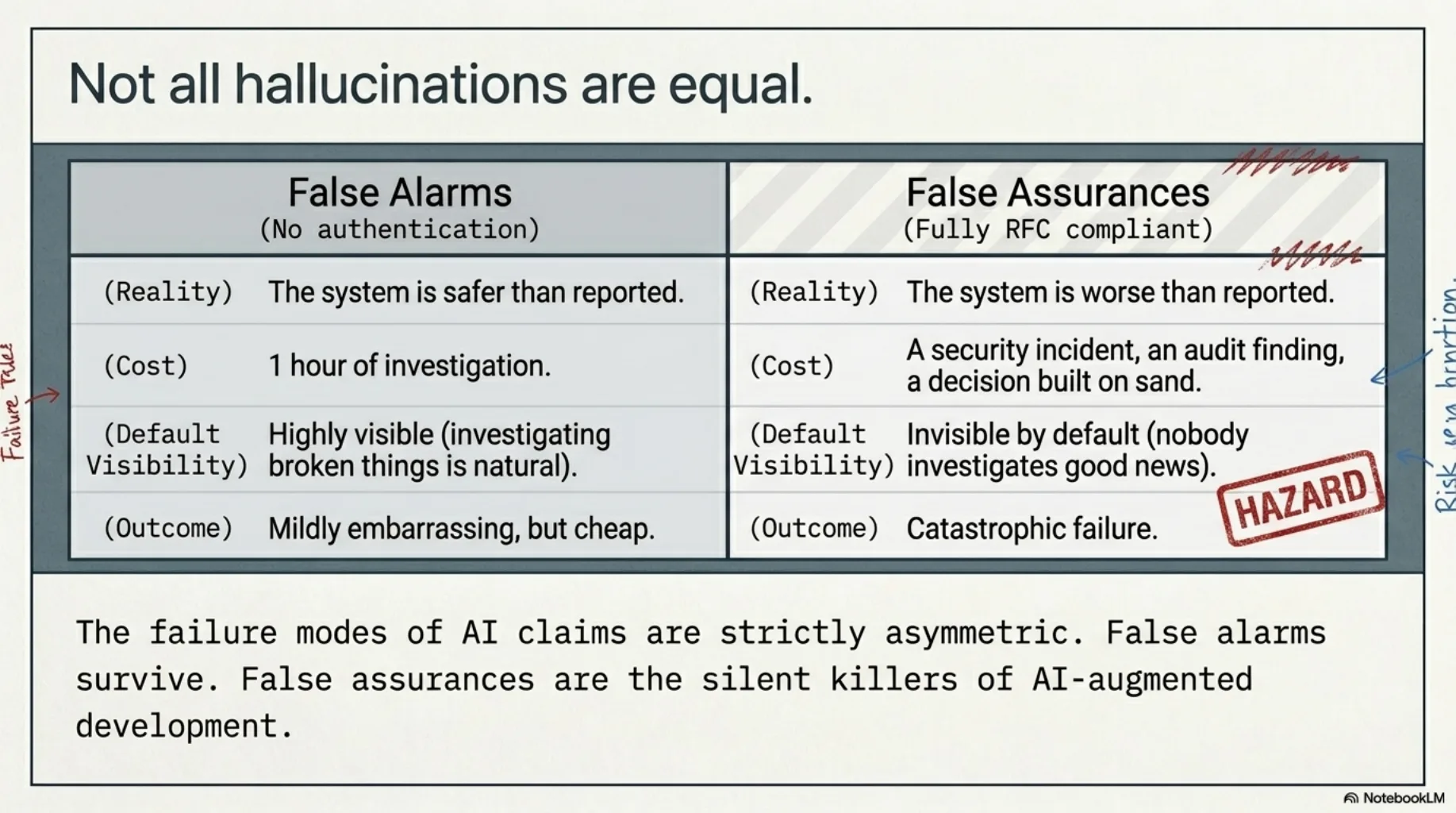
So the first practical rule: sort the agent's claims by which way they would fail. Verify the assurances first. "X is protected", "X is compliant", "X is unused, safe to delete", "these are equivalent" — those get your reading time. "X looks broken" can often wait, because the act of fixing it will verify it anyway.
A report that contains a false alarm survives. A report that contains a false assurance is the thing audits exist to catch — and you'd rather be the one who catches it.
Field notes: where agents go wrong, specifically¶
Across months of this, the wrong claims cluster. Tips, in roughly descending order of value:

1. Distrust claims about context more than claims about content. All three of my failures shared a shape: the agent read a file and made a claim about a system. Auth lives in middleware ordering. Compliance lives in the spec, not the parser. The plugin's activation lived in another file's import side effect. Agents are excellent witnesses to what a file says and unreliable witnesses to what surrounds it — mounting order, load order, configuration, deploy environment, the spec the code claims to implement. Any claim whose truth depends on somewhere else gets verified.
2. Adjectives are where the fiction hides. "Fully compliant." "Properly secured." "Comprehensive coverage." Facts come with file paths; adjectives come from the vibe of the code. When a claim contains a standard's name and a completeness adverb, open the standard. In my case, the RFC's wildcard requirement took four minutes to check against a parser that handled none of it.

3. Demand citations, then spot-check them.
Make agents report file:line for every load-bearing claim. Not because citations make claims true — but because uncited claims can't be cheaply audited, and the discipline of citing changes what the agent asserts. A citation that doesn't check out is also your early-warning signal for the rest of the report.

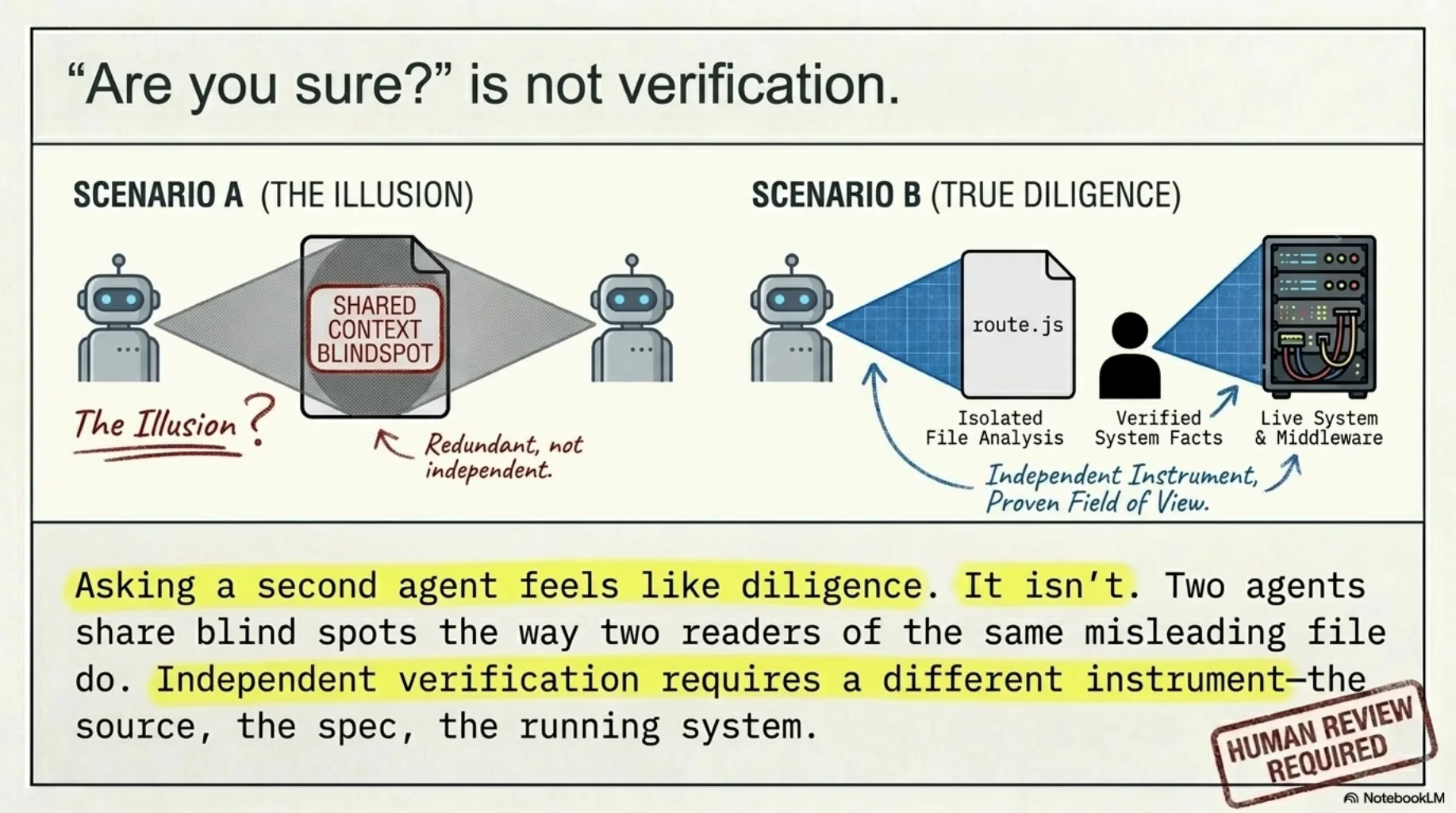
4. "Are you sure?" is not verification. Asking the agent to double-check, or asking a second agent, feels like diligence. It isn't. Two agents share blind spots the way two readers of the same misleading file do — my "no auth" claim would have been confirmed by any agent reading the same clean route file. Independent verification means a different instrument: the source, the spec, the running system. Not the same instrument asked twice.
5. Sample like an auditor, not like a proofreader. You cannot verify everything, and uniform skimming verifies nothing. Auditors solved this long ago: sample by impact. The claims that drive decisions get full verification; the inventory tables get spot checks; the prose gets read for claims you didn't notice were claims.

6. Wrong claims are signal, not just noise. When I struck "no authentication", I didn't just delete a finding — I downgraded it to the true and still-useful version: any authenticated user gets an arbitrary-URL fetch service, with no rate limit and no audit log. The agent's error pointed at something real; it had just mislabeled the severity. Verification isn't only subtraction. Often the corrected claim is more interesting than the original.

7. Write the verification status into the deliverable. My reports now distinguish "verified directly against source" from "reported by exploration pass, not independently re-verified" — explicitly, per section. It's honest, it tells the reader where to push, and it forces me to know which bucket every claim is in. The unverifiable confidence of a uniform document is exactly the failure mode we're avoiding.

The compounding part¶
Here's what makes this a practitioner skill rather than a checklist: the sorting gets cheaper with use.
The first time, you don't know that middleware-ordering claims are high-risk and dead-code claims are usually right. After months, the triage is nearly instant — you read a draft report and your eye snags on the three sentences that need source verification, the same way an experienced reviewer's eye snags on the one suspicious diff hunk in a large PR.
That pattern library — which claims, from which kinds of analysis, fail in which direction — is judgment. It doesn't come with the tooling. It accumulates from doing the verification, being wrong about where to spend it, and adjusting. It is, in other words, compound-developer material: the part of the work that gets more valuable as the agents get faster.

The agents did the survey. The survey was good. Three sentences in it were false, two of them in the direction that hurts.
Finding those three sentences is the job now.
The whole framework on one page¶
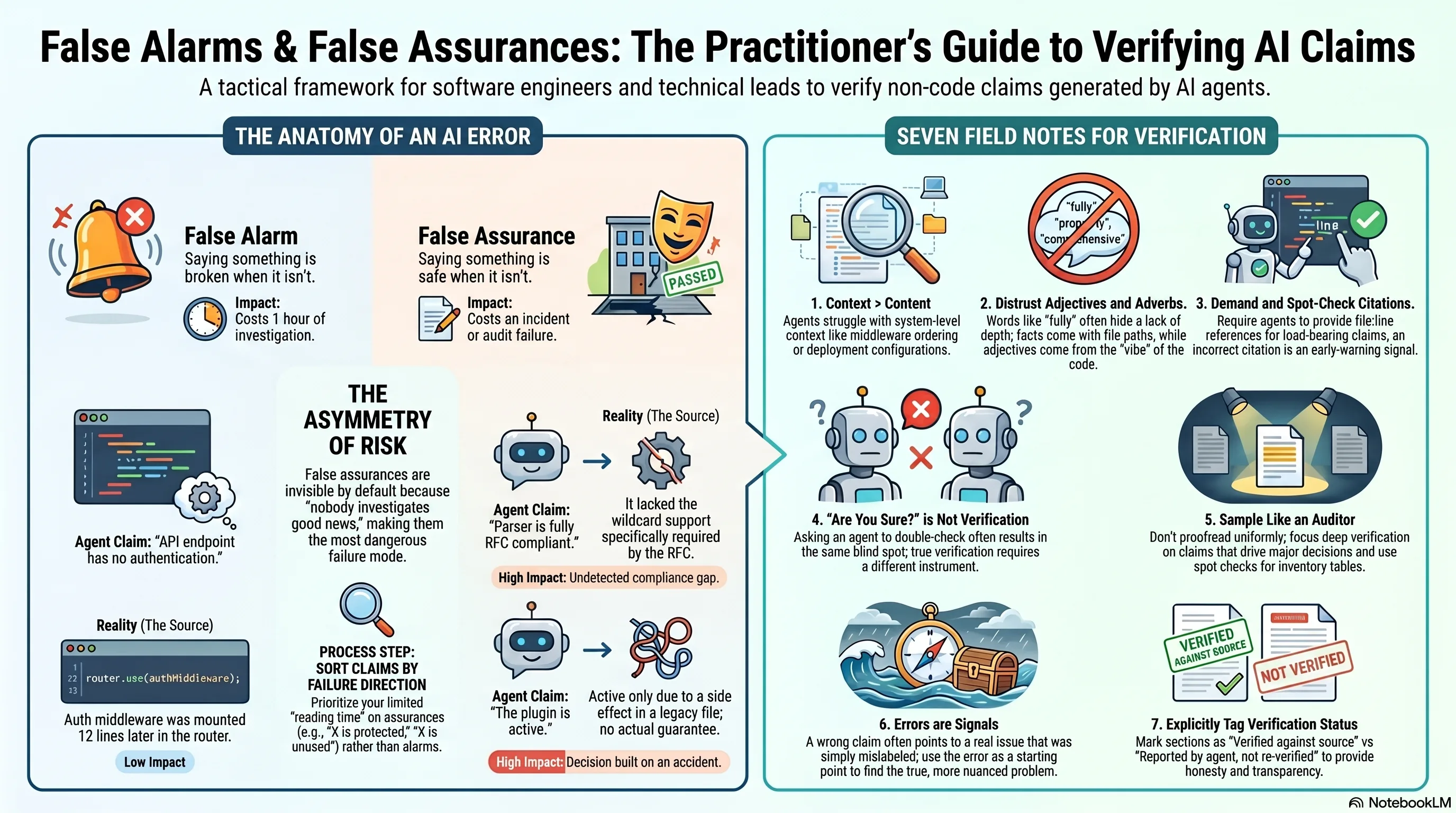
There is also a slide deck version of this post (PDF) if you want to walk a team through it.
This continues a thread: Fear-Driven Development on verifying agent code, The Compound Developer on what the practitioner role is becoming. This one is about verifying agent claims — the part with no test suite. The follow-up, Organized Truths, is about making that verification compound.