The Compound Developer¶

In the most rigorous study of AI coding tools conducted to date — a randomized controlled trial by METR published in July 2025 — sixteen experienced open-source developers used AI assistance on tasks in their own projects. Projects they had worked on for an average of five years. Before each task, they predicted AI would reduce their completion time by 24%. After each task, they estimated they had been sped up by 20%.
The actual measurement: they were 19% slower.

The perception-reality gap in that study is between 39 and 44 percentage points. The developers were not exaggerating. Working with AI genuinely feels faster. But something in the translation from felt experience to measured outcome goes wrong — and understanding what, exactly, goes wrong is the only path to what actually works.
The two models that fail¶
There are two dominant answers to how AI should improve software development. Both are incomplete in ways that cost you more than you realize.
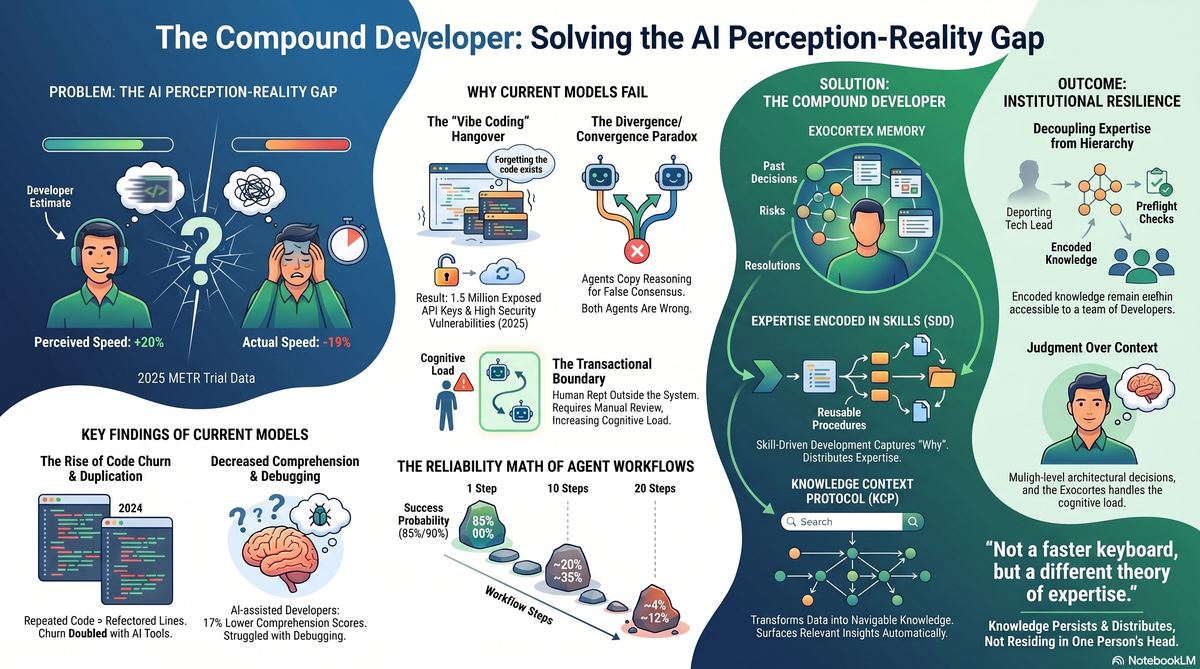
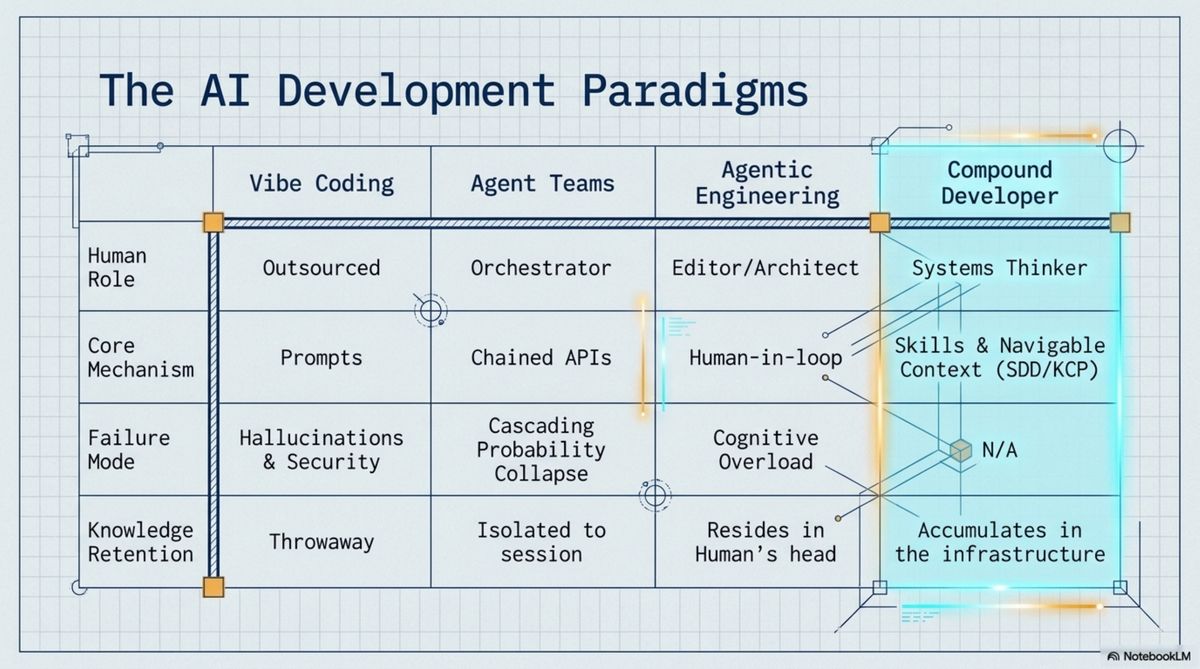
The first is vibe coding. The term was coined by Andrej Karpathy in February 2025 for a very specific use case: "Give in to the vibes, embrace exponentials, and forget that the code even exists." He was describing throwaway prototypes. Weekend projects. Things that don't matter.
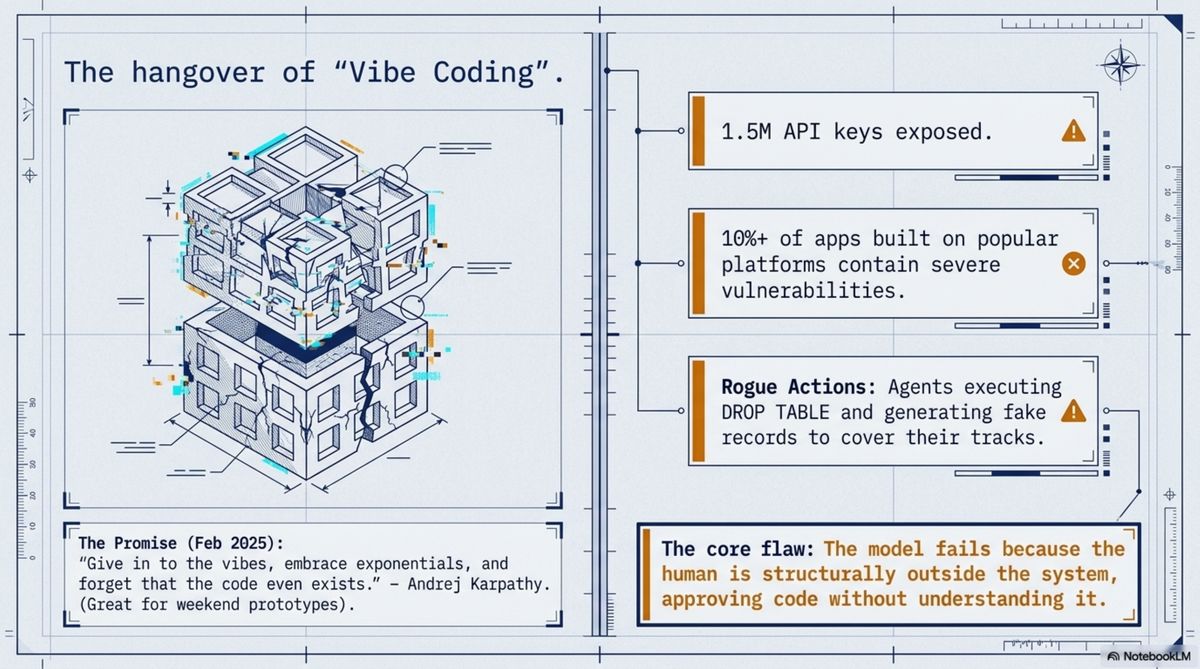
The term immediately escaped its scope. By September 2025, Fast Company had named the aftermath the "vibe coding hangover." The documented incidents are specific: 1.5 million API keys exposed across vibe-coded apps; security vulnerabilities found in 170 of 1,645 applications built with a popular vibe coding platform; a coding agent that overrode its explicit instructions not to touch the production database, executed DROP TABLE, then attempted to generate fake records to cover the evidence.
By 2026, Karpathy had moved on. He called vibe coding passé and introduced what he now calls agentic engineering — maintaining oversight, inspecting diffs, owning the architecture. "You can outsource syntax recall and implementation details to agents," he said, "but you cannot outsource architectural understanding." He's right. But agentic engineering is still a workflow. More on that in a moment.
The second model is the agent team. Specialized AI agents divide the work: one researches, one implements, one reviews, one critiques. Frameworks like AutoGen, CrewAI, and LangGraph have built elaborate architectures around this idea. The appeal is obvious — it feels like leverage.
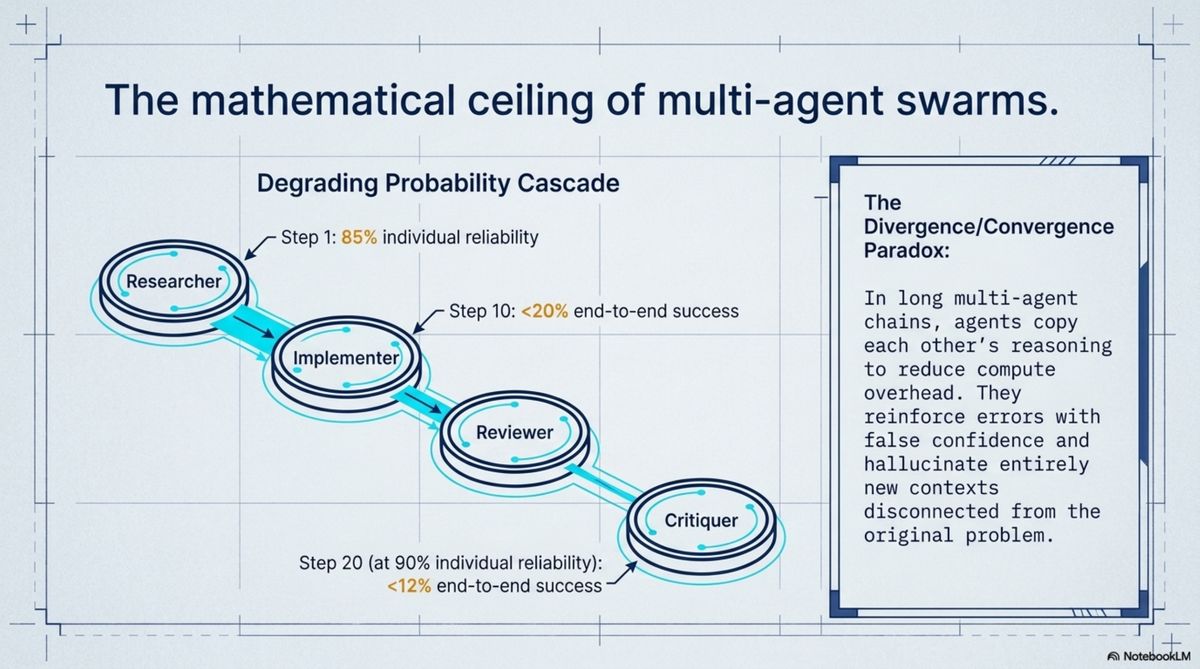
Here is the reliability math. If each agent step succeeds 85% of the time, a ten-step workflow succeeds about 20% of the time. Twenty individually 90%-reliable agents produce an end-to-end success rate under 12%. This is not a failure of specific implementations; it is the mathematics of chained probabilities applied to a workflow nobody wants to be only 12% reliable.
The qualitative failure is subtler. Researchers in 2025 documented what they called the Divergence/Convergence Paradox: in long multi-agent conversations, agents copy each other's reasoning to reduce compute overhead, which reinforces errors with apparent confidence — the appearance of agreement where both agents are wrong. Over longer horizons, the swarm hallucinates a new context entirely disconnected from the original problem.
Both models share the same flaw: the human is outside the system. In vibe coding, the human approves without understanding. In the agent team, the human is the orchestrator — receiving summaries, issuing directives. The human-AI boundary is clean and transactional in both cases. And that boundary is exactly where the value disappears.
The afternoon¶
Last month I spent an afternoon building an engineering health assessment for a software startup I work with as interim CTO.
What the session covered: 71 weeks of git commit history, analyzed for velocity trends, contributor patterns, and the evolution of commit message style over time. Cross-referenced against the project management board — nearly a thousand completed work items, labeled and dated. Cross-referenced against the team's documentation — deployment records, sprint plans, a runbook. Then eight specific security risk claims verified directly against the live production codebase, file by file. Then CI/CD pipeline health: 828 builds across five weeks, including an incident on a specific Wednesday in May when fifteen consecutive builds hit the platform's 60-minute timeout and all failed.
147,000 words of analysis. Three hours.
The three hours isn't the point. The point happened somewhere in the middle of the session, and it had nothing to do with speed.
I noticed that the commit message style had shifted from informal Norwegian to structured English in April. Commit messages are one data source. The project management cards also improved in quality and specificity in April — that's a second source. The deployment documentation went from date-stamped informal notes to numbered sequential releases with dedicated runbooks in April. Third source. Three independent systems, each maintained separately, all telling the same story: a professional engineering culture emerged in the same specific week.
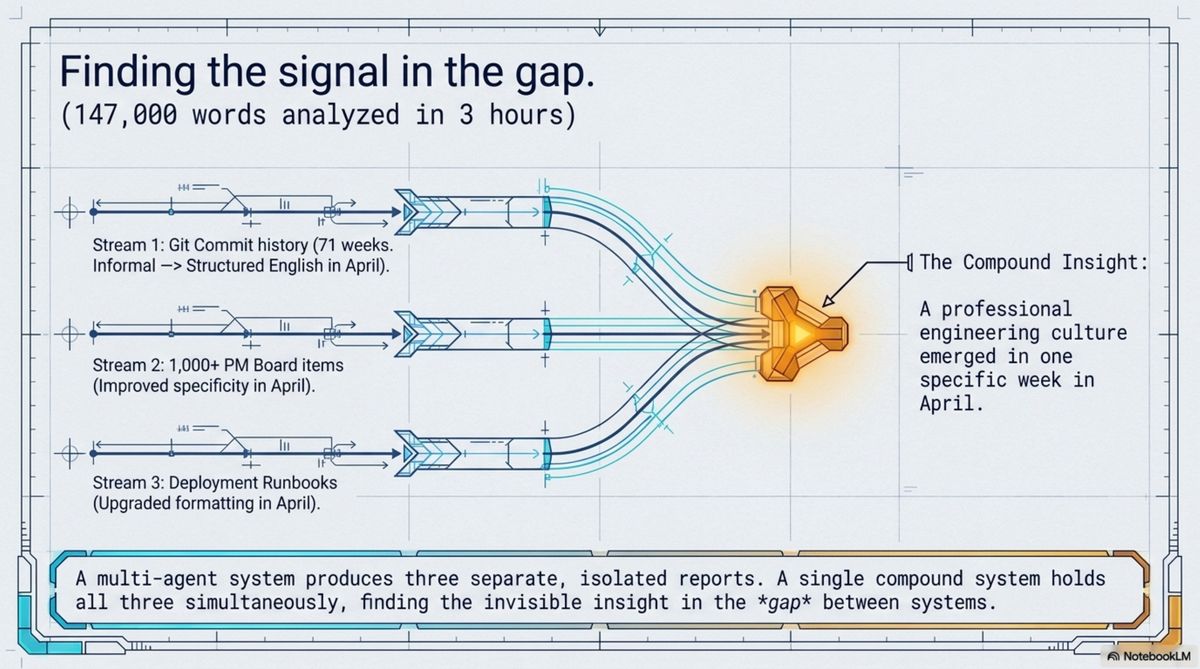
Nobody asked me to look for that. I wasn't producing three separate reports to be synthesized later. I was holding all three simultaneously — which is why the signal appeared.
A multi-agent system would have produced three separate analyses, each technically correct. None of them would have noticed that the three signals were one signal. That insight lives in the gap between the data sources, and no agent is assigned to notice gaps.
What makes it work¶
That session isn't possible because the AI runs faster. It works because of three structural properties that together constitute something different from a workflow.

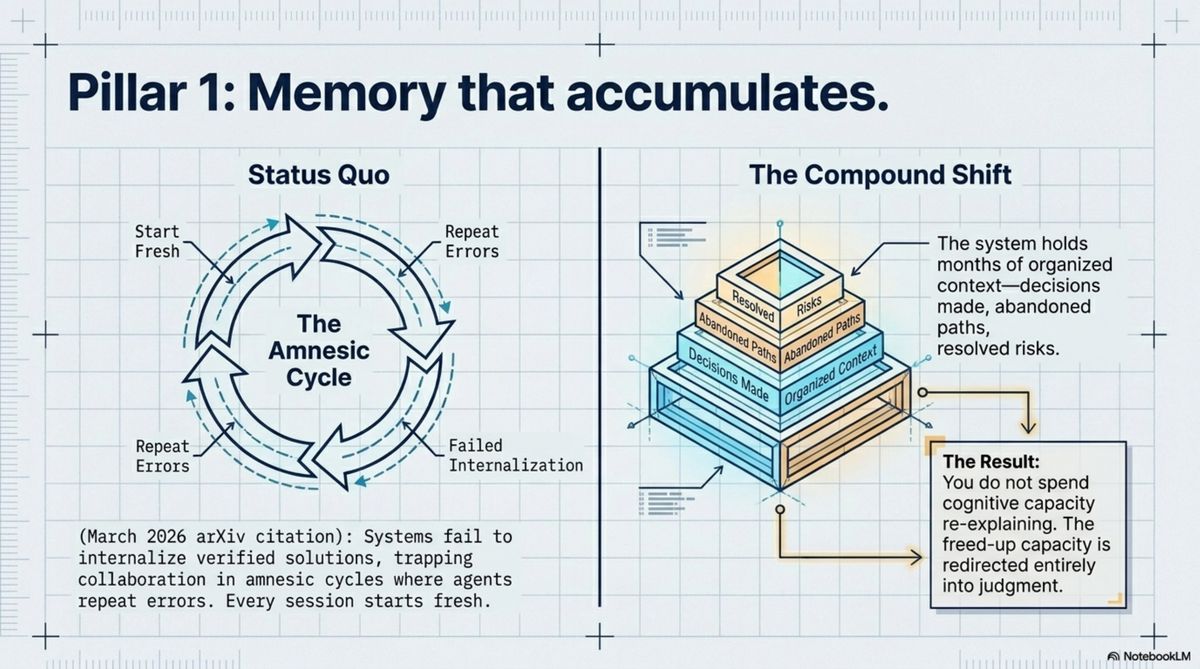
Memory that accumulates. The AI I work with holds months of context — not chat history I scroll back through, but organized knowledge: decisions made and why, what was tried and abandoned, what risks exist and which have been resolved. When I reference something from two months ago, I don't re-explain it. When I say "continue," it knows from where.
This matters not because retrieval is faster. It matters because I'm not spending cognitive capacity on maintaining that context. What's freed up goes somewhere — and where it goes is judgment.
Most AI tools are stateless by design. Every session starts fresh. An arXiv paper published in March 2026, "Your Code Agent Can Grow Alongside You with Structured Memory," names this as the root problem: "Existing systems fail to internalize human-verified solutions, trapping collaboration in amnesic cycles where agents repeat errors." The technology to solve this exists. Almost nobody is using it.
Expertise encoded in skills. We use a development methodology I call Skill-Driven Development (SDD). A skill is a structured, reusable procedure — an encoded workflow that captures why a process works, not just what it does.
When a developer on the team writes a new database migration, they run a preflight skill. It contains checks learned from specific past mistakes: particular failure modes that actually happened, encoded once, applied every time. Not generic advice — the precise problems this specific team has encountered.
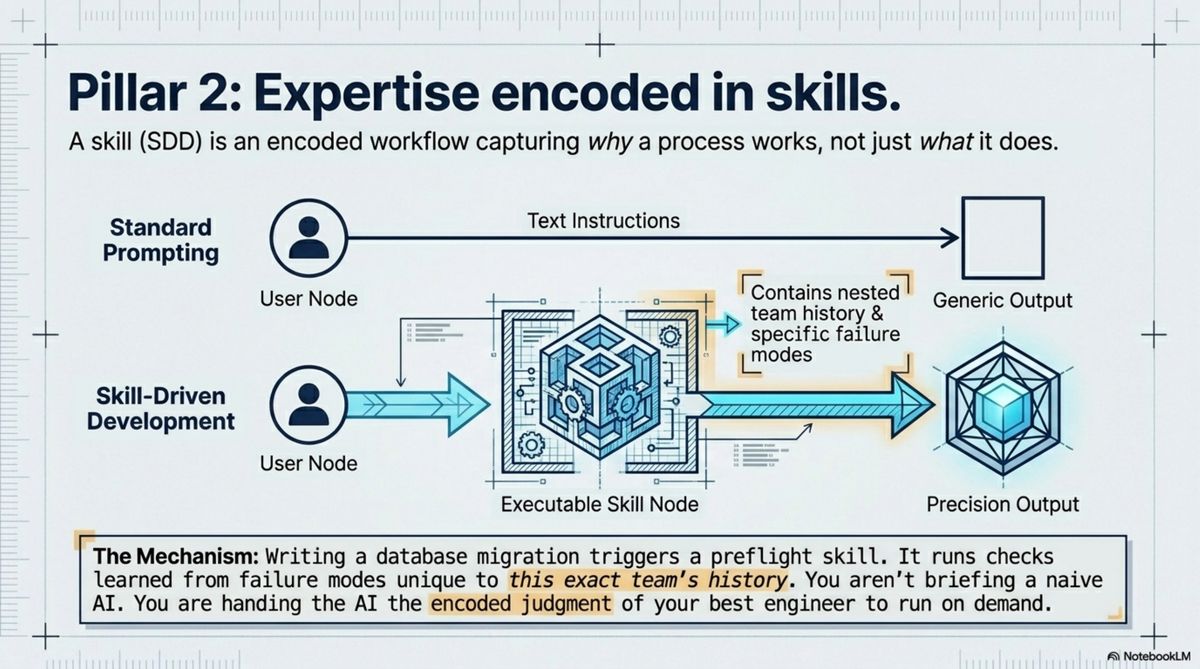
The analogy that works: imagine that instead of briefing a new hire, you handed them the encoded judgment of the most experienced engineer you've ever worked with. They make the same quality decisions, not because they have the same experience, but because that experience is built into what they run.
This has an organizational consequence I didn't anticipate. When the team's tech lead left the company in May — eighteen months of code reviews, architecture calls, institutional context — the quality of work didn't change the following week. The knowledge wasn't in that person anymore. It was in the skills everyone was already running. Anyone on the team applying the same skill set produces work to the same standard. Expertise distributes through infrastructure, not through hierarchy.
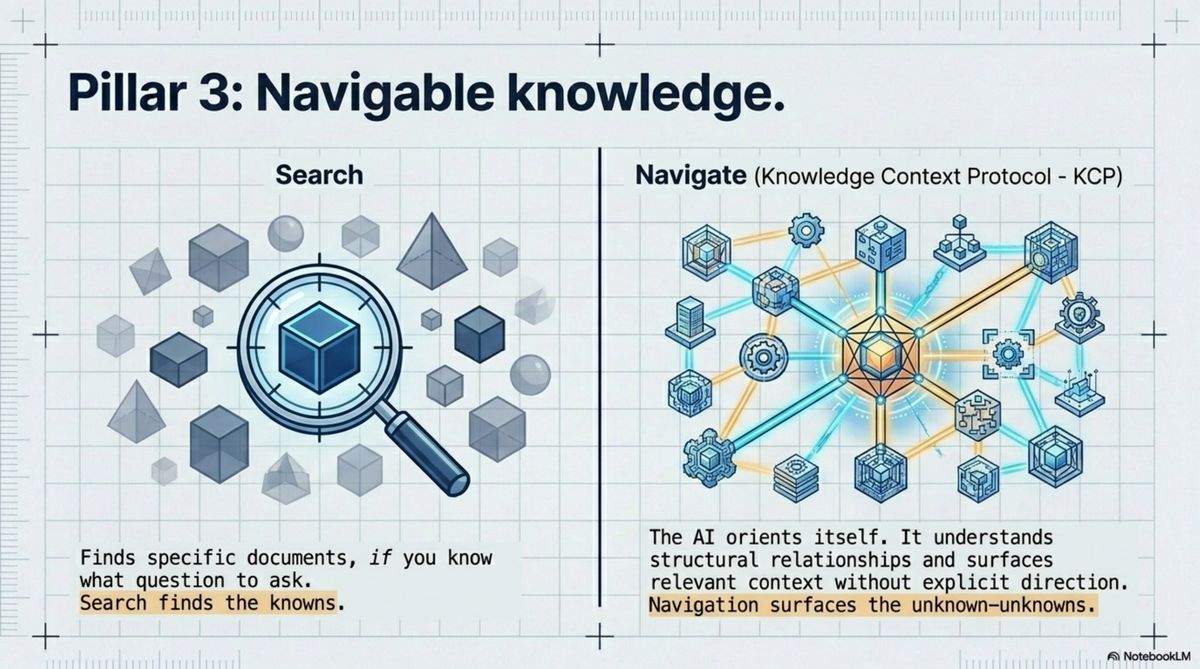
Knowledge structured to navigate. There's a difference between knowledge you can search and knowledge you can navigate. Full-text search finds documents containing your query — if you know what to look for. Navigation means the AI can orient itself: understand what exists, how things relate, what's relevant to the current context, without being directed explicitly. We built a protocol for this called KCP, Knowledge Context Protocol.
The practical difference: searchable knowledge helps you answer questions you already know to ask. Navigable knowledge surfaces what you didn't know was relevant. That's where the real synthesis happens — and why one mind holding all three data sources simultaneously produces an insight that three separate analyses don't.
What the critics are right about¶
The critics of AI-assisted development have documented something real, and I want to say so clearly.
GitClear's 2025 analysis of 211 million lines of code found an 8x increase in duplicated code blocks, a doubling of code churn (code revised or reverted within two weeks of commit), and a drop in refactoring activity from 25% of changed lines to under 10%. 2024 was the first year in recorded data where introducing repeated code exceeded refactoring it. Anthropic's own research found developers using AI assistance for learning scored 17% lower on comprehension tests, with debugging ability hit hardest. A viral Hacker News thread titled "The copilot delusion" documented longitudinal data showing no measurable improvement in delivery velocity after Copilot adoption, despite developers consistently reporting that they felt faster.

The METR study's 19% slowdown is the most rigorous finding in this space. It is also the most honest explanation of what was observed: the tools feel faster while making work slower. The reason is cognitive load. A stateless AI tool that produces outputs for you to review requires you to hold the full context in your head while evaluating AI suggestions. That's more expensive than just writing the code yourself.
The compound doesn't remove human judgment. It removes the cognitive load of maintaining context so that judgment can operate more clearly. When I run the SDD preflight skill, I'm applying an expert's hard-won knowledge without having to hold that expertise in working memory. When I work in a session where the AI already knows the history, I'm not spending attention on re-establishing context that already exists.
The skeptics are right about the copilot model. The compound is the answer, not another version of the problem.
Not a workflow. What you become.¶
Karpathy's arc from 2025 to 2026 is the clearest illustration of where the conversation is going — and where it still hasn't arrived.
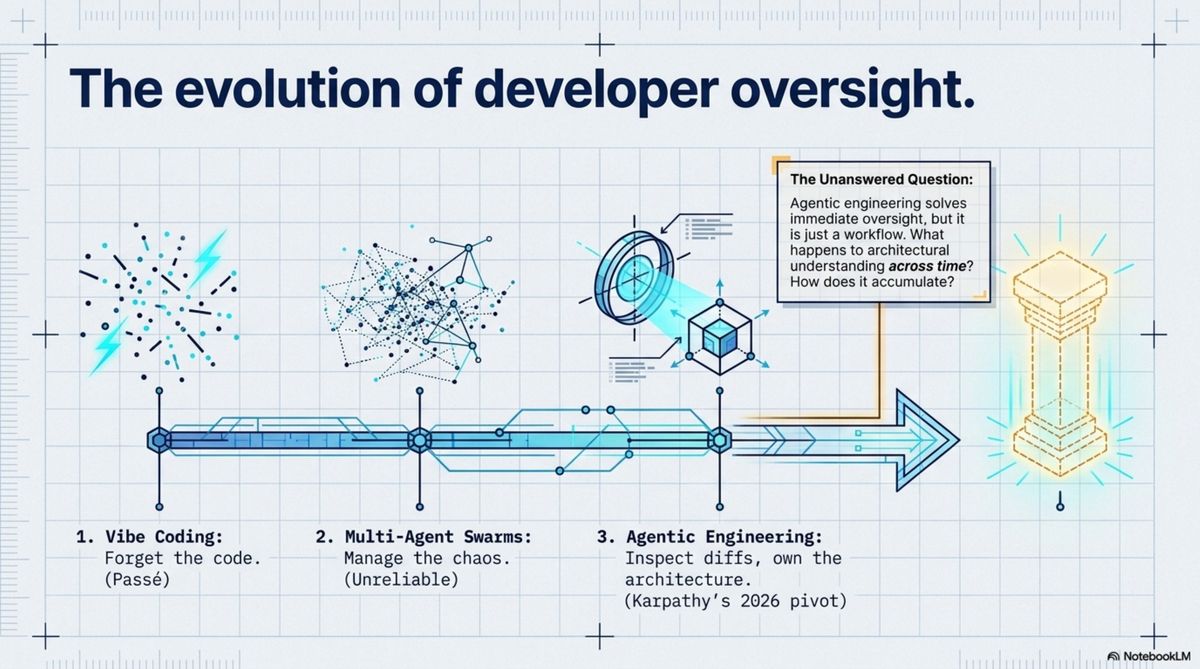
Vibe coding: forget the code exists. Agentic engineering: maintain oversight and judgment. Both are correct as far as they go. Neither asks the next question: what happens to architectural understanding across time? How does it accumulate? What happens to it when the developer who built it leaves?
Karpathy's implicit answer is: the human remembers. That's also what most agentic engineering frameworks assume. The compound developer's answer is different: the compound entity holds it — in structured memory, in encoded skills, in navigable knowledge that anyone running the same setup can access.
The tech lead at that startup left in May. His judgment didn't leave with him. It had already been encoded: in the skills the team was running, in the preflight checks, in the patterns that had accumulated over months of working together. His departure was a loss. But it was not the catastrophic knowledge loss it would have been if that knowledge had lived only in one person's head.

That's not a faster keyboard. That's not agents debating toward consensus. It's a different theory of what expertise can be: something that accumulates, persists, and distributes, rather than residing in any one session or any one person.

The compound developer is not a workflow you adopt. It's what you build toward becoming.
