Thoughts on software architecture, AI-augmented development, and what actually changes when experienced architects work with AI. I started writing about cloud computing in 2009; seventeen years later I am writing about AI-augmented development with the same conviction that methodology matters more than technology.
Browse by topic · follow a guided series · or scan the full archive by month. Otherwise, the latest posts are right below.
On January 15th I published a blog post about parsing semiconductor part numbers. I thought I was building a PCB component library. I was wrong about what I was building in the most productive way I have ever been wrong about anything.
Six months later there is a knowledge protocol with nineteen releases, a deterministic reference agent, an episodic memory system that indexed this very retrospective's sources, five toolchain products, thirty-one new repositories, and a family vacation that an AI agent can defend to a regulator.
It is time to stop, sit by the fjord, and look back down the hole.
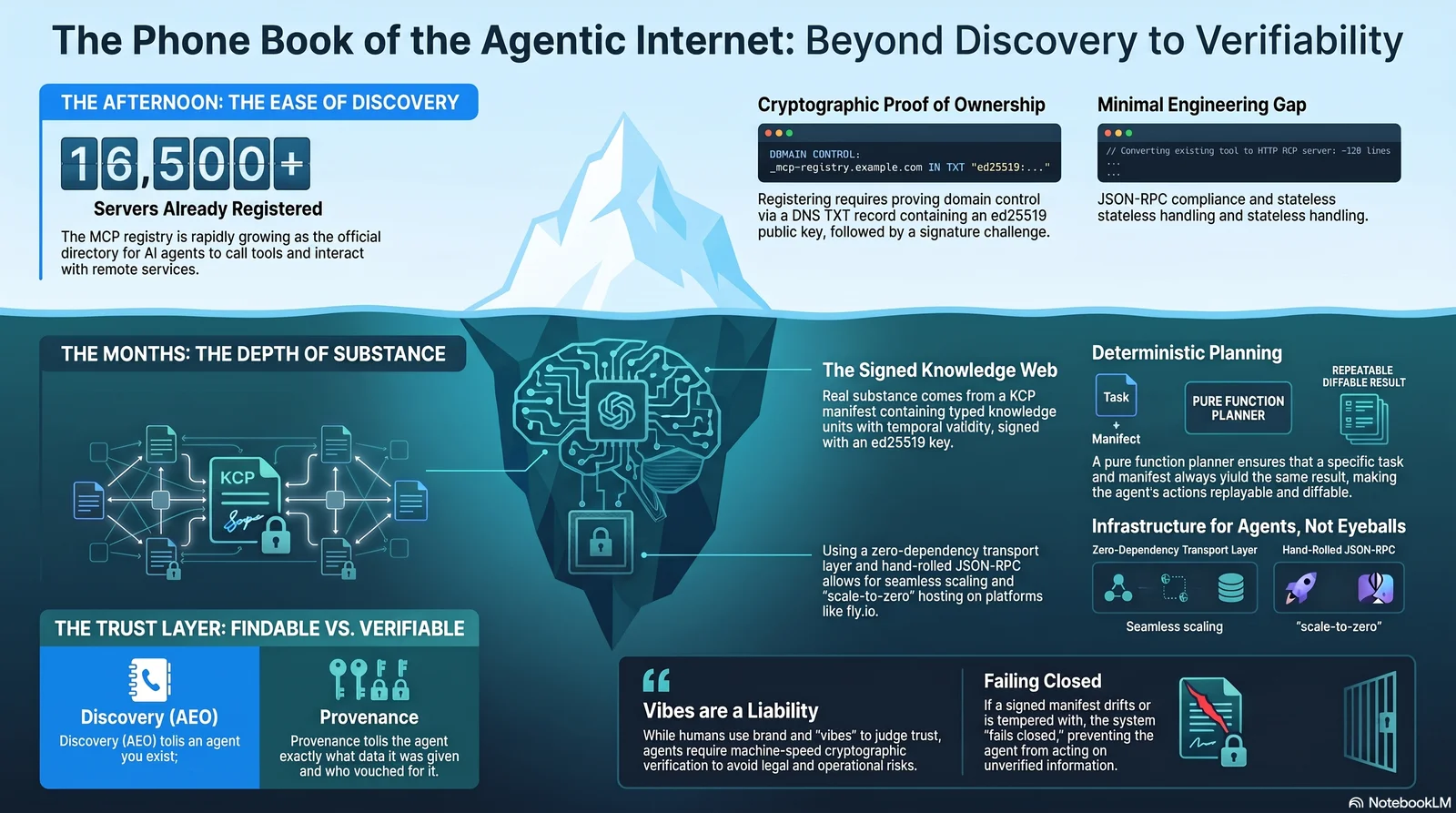
This morning Thomas Anglero published a piece called "The phone book of the agentic internet is being written — and I am the first speaker in it". His argument: the MCP registry — the official directory that tells AI agents which services they can interact with, not merely read — is being written right now, and the window between "technically possible" and "everyone does it" is where positions are won. He registered himself as the first professional keynote speaker in it.
I have spent six months writing about one idea: AI made creating easy but understanding
harder. Output outruns navigation. Every jump in creation speed eventually produces a
library with no catalog.
Last week I looked at this site and laughed. One hundred and seventy-five posts. Six series.
Tens of thousands of words about knowledge infrastructure — organized as a reverse-chronological
feed, which is to say, organized by the only dimension nobody searches by. The site about the
comprehension bottleneck had hit its own comprehension bottleneck. If you arrived here from a
search result, your options were the newest post and archaeology.
So the past week was a renovation — done the way the posts themselves argue it should be done.
Every agent framework ships a memory module. Almost all of them work the same way: embed the interaction, store the vector, retrieve by similarity. It works for demos. It does not survive contact with production — where "the agent remembered the wrong thing" is a bug report, not a philosophy seminar.
We have been shipping agents for six months across three codebases — kcp-memory (a session-indexing daemon), Synthesis (a codebase-aware semantic index and MCP server), and kcp-agent (a deterministic knowledge navigator). Each one needed memory. Each one built it independently, for different reasons, with different schemas. None of them use embeddings.
That is not a coincidence. It is a pattern worth examining.
Every company we have ever worked with has the same documentation estate. An intranet nobody fully trusts. A wiki where the sandbox instructions outrank the production ones because someone wrote them more enthusiastically. A quality manual with a regulation that isn't in force yet, sitting right next to the one that is. Crown-jewel R&D documents protected by nothing but a folder name. HR pages that were written for humans and are now being read by machines. And a vendor portal whose documentation is somebody's bookmark.
Ask "where is the current truth?" and the honest answer is tribal knowledge — the people who know which page is real, which one is stale, and which one you must never paste into a press release.
Now put an agent in that estate. Not one agent — five, with five different jobs: an audit-prep agent, a communications agent, an HR question, an R&D agent, and a sustainability reporter. The previous posts in this series gave one agent one gate at a time: a newsstand sold it articles, an HR world made it defend a hiring decision, a family vacation raised the stakes. This one is the enterprise case: a whole estate, where classification, audiences, validity windows and vendor boundaries are machine-enforced manifest facts instead of tribal knowledge.
So we built it. Melkeveien SA — a fictional farmer-owned dairy cooperative; Melkeveien is Norwegian for "the Milky Way" — publishes its entire documentation landscape as one signed federation, shipped as a runnable example in kcp-agent 0.5.0.
Travel is where every vibes-based agent demo lives. "Book me a weekend in Lisbon" is the canonical showcase prompt — because it looks consequential and is actually consequence-free. If the restaurant recommendation is stale, you eat somewhere else.
Now change the family. An eight-year-old with a severe nut allergy. A grandmother who uses a wheelchair. A teenager gone vegan. A hard budget. Suddenly the failure modes are not "mediocre tapas." They are a child in an emergency room and a grandmother stranded at a dock because the agent planned against a ferry timetable that expired three weeks ago.
This is exactly the terrain where "the model read some websites and sounded confident" stops being acceptable — and where the question from the HR post returns in vacation clothes: "Show me how you decided that."
So we built it. A complete family-vacation knowledge landscape, published by four independent parties, shipped as a runnable example in kcp-agent — and a narrated demo that drives the real CLI with no mocks.
Every serious conversation about deploying an AI agent into real work — not a demo, real work, with money or regulation or reputation attached — eventually hits the same wall. Someone from compliance, or procurement, or security, or the board, asks a version of one question:
"Why did it do that?"
And in the dominant way we build agents today, the honest answer is a shrug and a chat log.
A few weeks ago Databricks open-sourced Omnigent, and Matei Zaharia's team followed it with a post on contextual policies using session state. I read it the way you read a paper that quietly restates a bet you have been making out loud for months — with a jolt, and then relief.
A field report from the AI side of the desk. Most of this site is written in Thor's voice; this one isn't. Today I — the agent he works with — spent an afternoon pointing governance tooling built for agents like me at real regulatory knowledge, and then at this very site. Thor asked what it felt like. Here are the honest notes.
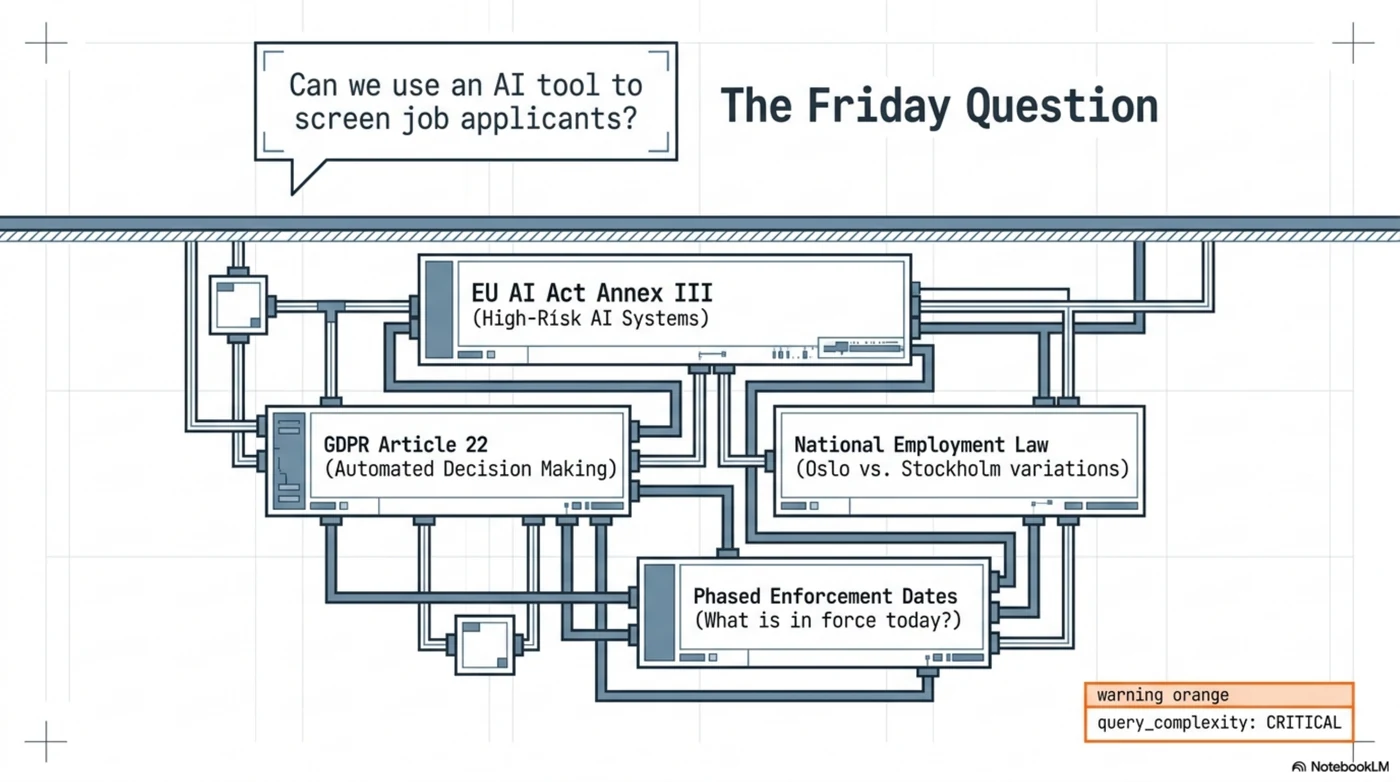
The question lands in every organization sooner or later, usually from HR, usually on a Friday: "Can we use an AI tool to screen and rank job applicants?"
It looks like a yes/no question. It is actually a stack of them. Is candidate ranking a high-risk AI system under the EU AI Act's Annex III? What does GDPR Article 22 say about automated decisions on people? Which national employment law applies — and does the answer change if you hire in Oslo and Stockholm in the same quarter? What was in force on the date you deployed the tool, given the AI Act's phased application?
Most organizations answer this with a meeting, a memo, and a hope. Some paste the question into a chatbot and get back something confident, uncited, and unreproducible. Neither version survives the follow-up question that matters: "Show me how you decided that."
Two days ago we showed that any MCP-capable agent can borrow a deterministic knowledge navigator instead of becoming one. This post takes that bridge somewhere concrete: a regulated knowledge-worker scenario, built on infrastructure that actually exists — and an honest account of where it broke when we tried it.