Hiring by the Book: A Defendable HR Agent on a Regulatory Knowledge Web
The question lands in every organization sooner or later, usually from HR, usually on a Friday: "Can we use an AI tool to screen and rank job applicants?"
It looks like a yes/no question. It is actually a stack of them. Is candidate ranking a high-risk AI system under the EU AI Act's Annex III? What does GDPR Article 22 say about automated decisions on people? Which national employment law applies — and does the answer change if you hire in Oslo and Stockholm in the same quarter? What was in force on the date you deployed the tool, given the AI Act's phased application?
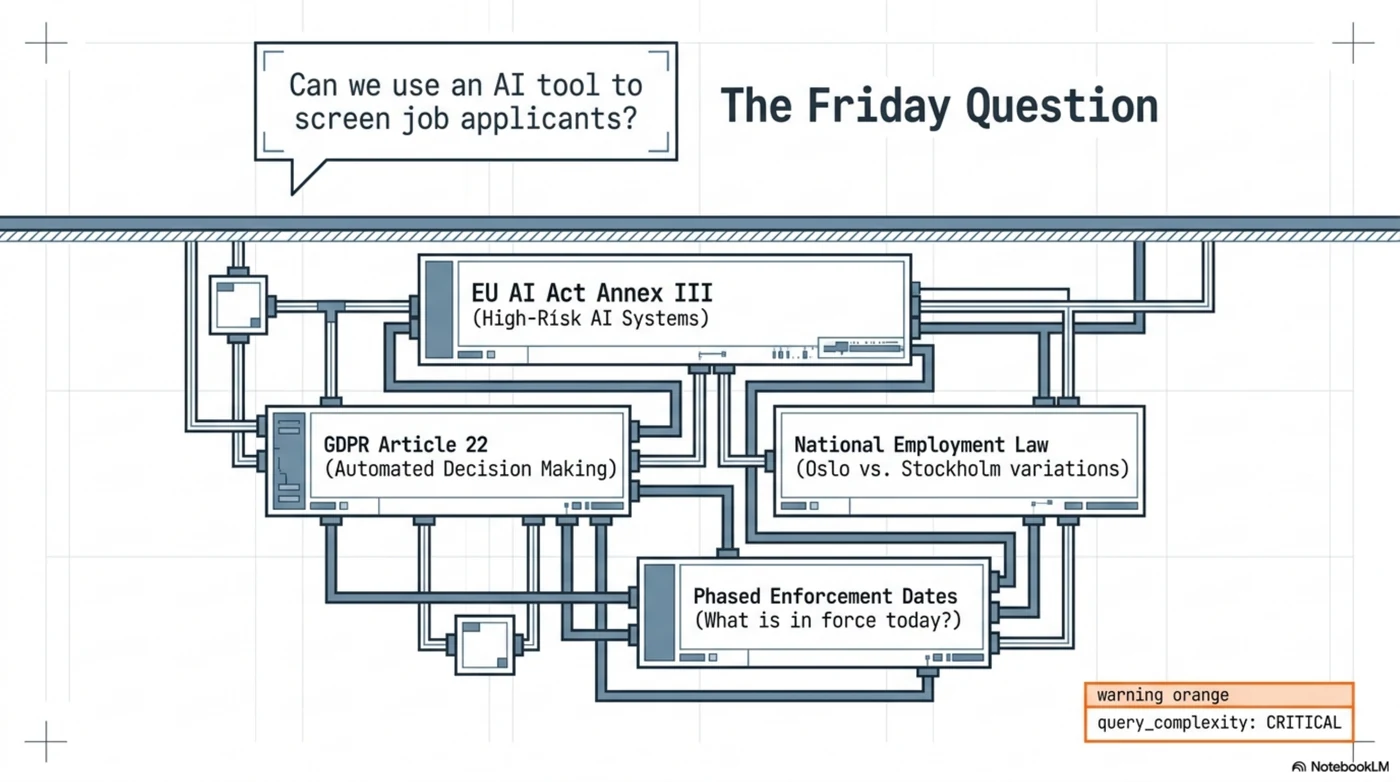
Most organizations answer this with a meeting, a memo, and a hope. Some paste the question into a chatbot and get back something confident, uncited, and unreproducible. Neither version survives the follow-up question that matters: "Show me how you decided that."

Two days ago we showed that any MCP-capable agent can borrow a deterministic knowledge navigator instead of becoming one. This post takes that bridge somewhere concrete: a regulated knowledge-worker scenario, built on infrastructure that actually exists — and an honest account of where it broke when we tried it.