We Cancelled a 45-Minute Architecture Review. A KCP Query Answered It in 1.2 Seconds.¶
Last week someone asked the question that usually triggers a meeting: "If we change the payment service API contract, what else breaks?" In any enterprise system older than a few years, nobody has the full picture. The payment service team knows their side. The downstream consumers know theirs. The platform team knows the deployment topology. But the blast radius of a contract change lives in the intersection of what three or four people carry in their heads, and the only way to assemble that intersection has always been to put those people in a room.
We didn't put them in a room. We ran a query.
1.2 seconds. Fourteen repos checked. The result: three downstream services with explicit API contract dependencies declared in their KCP manifests, one internal SDK that wraps the payment client, and a batch job that nobody on the current team had worked on but that calls the v2 endpoint every night at 03:00. The dependency graph, the downstream consumers, the API contract versions they depend on, and the risk surface. All of it queryable. All of it current.
The 45-minute architecture review got cancelled. Not because the question was unimportant. Because the answer already existed.
Why That Meeting Existed in the First Place¶

Architecture reviews like this one follow a pattern that anyone who has worked in enterprise systems for more than a few years will recognise. A change is proposed. Someone asks "what does this affect?" Nobody knows the full answer. The people who know parts of it are identified, calendars are consulted, a 30- or 45-minute slot is found three days from now, and everyone shows up to reconstruct a picture that the organisation already possesses but has never made queryable.
The meeting is not the problem. The meeting is a reasonable response to a structural deficit: organisational knowledge trapped in people's heads. When the only way to assemble a dependency graph is to ask the people who built the dependencies, then meetings are the correct tool. They are expensive, slow, and synchronisation-dependent, but they work.
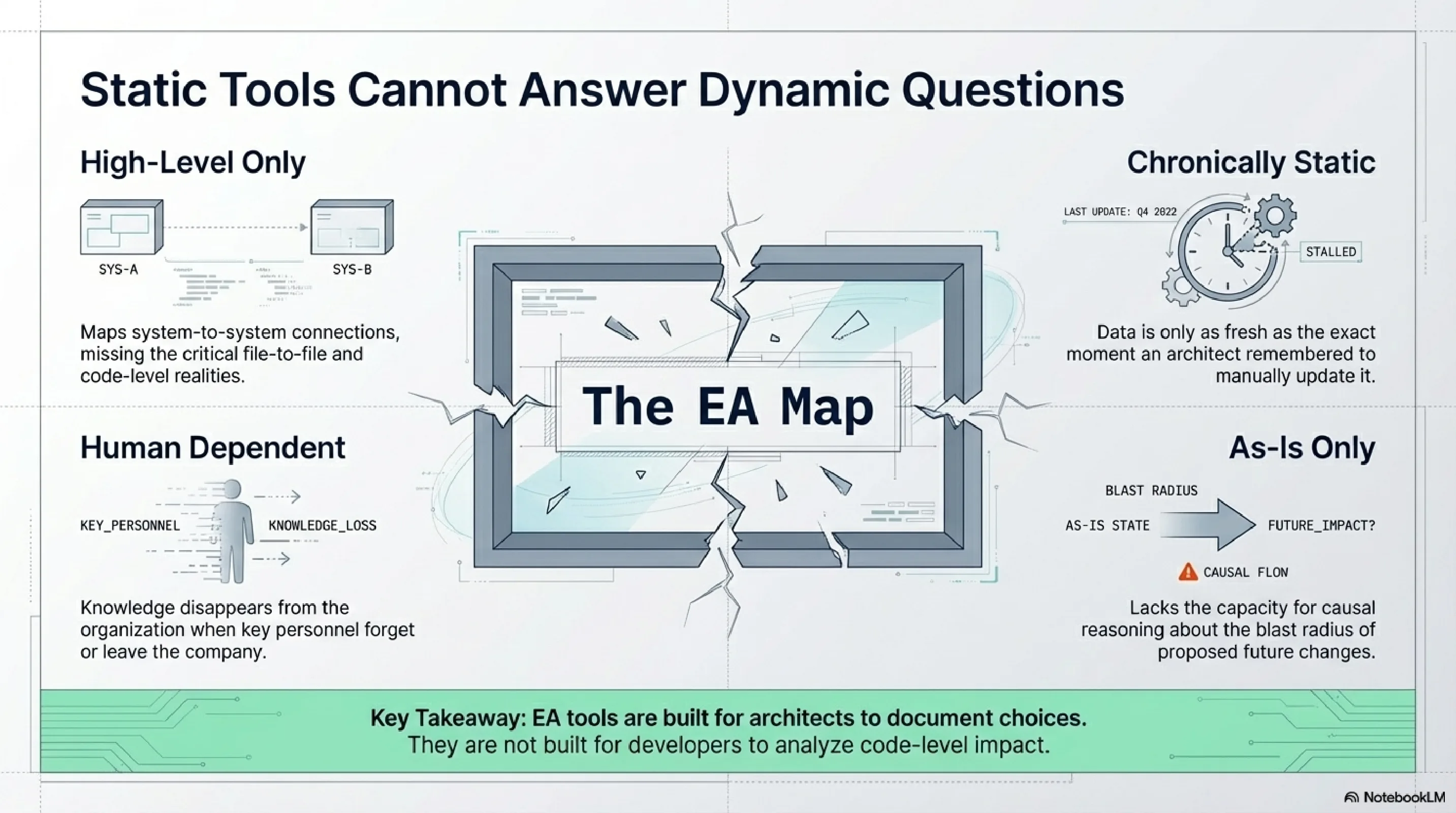
The questions that produce these meetings are remarkably consistent. What is the blast radius of this change? Who owns this service? What does the API contract guarantee? Can we safely deprecate this endpoint? What changed in this subsystem and when? Each question has a deterministic answer. The data exists. It is scattered across repositories, wikis, Slack threads, and the memories of engineers who may or may not still be on the team. The meeting exists to gather the shards.
What Changed¶
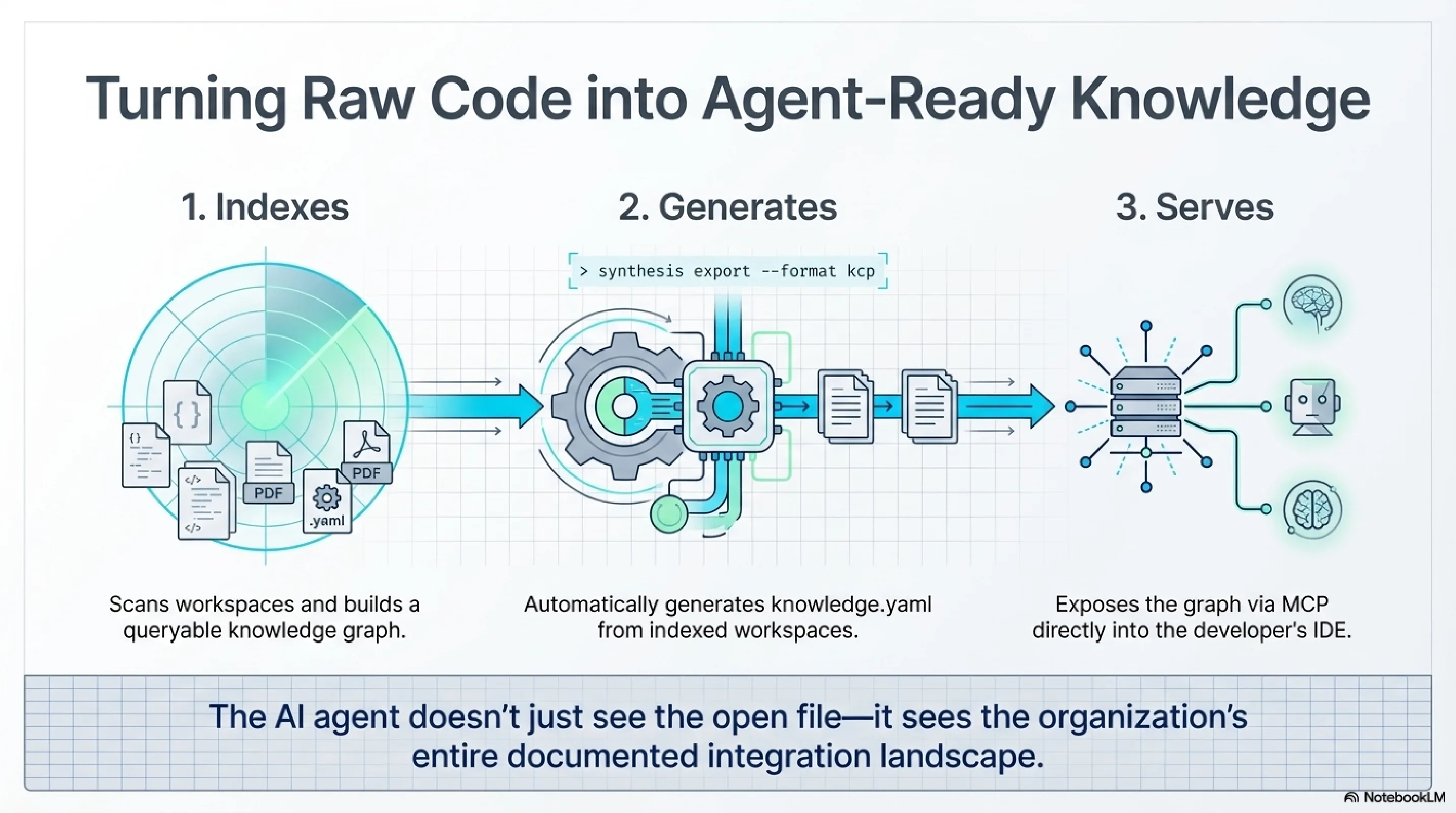
Each of the 58 repositories in the workspace now carries a knowledge.yaml file at its root. This is a KCP manifest, a structured YAML declaration of what the repository contains, what it depends on, what it exposes, and what an agent or human should know before making changes. Dependencies are typed. API contracts are versioned. Domain boundaries are explicit. Authority is declared.

Here is what a dependency declaration looks like in practice:
dependencies:
- name: payment-service
type: api
contract_version: "v2.3"
endpoints_consumed:
- POST /api/v2/transactions
- GET /api/v2/status/{id}
owner: platform-team
notes: "Batch job calls status endpoint nightly at 03:00 Oslo time"
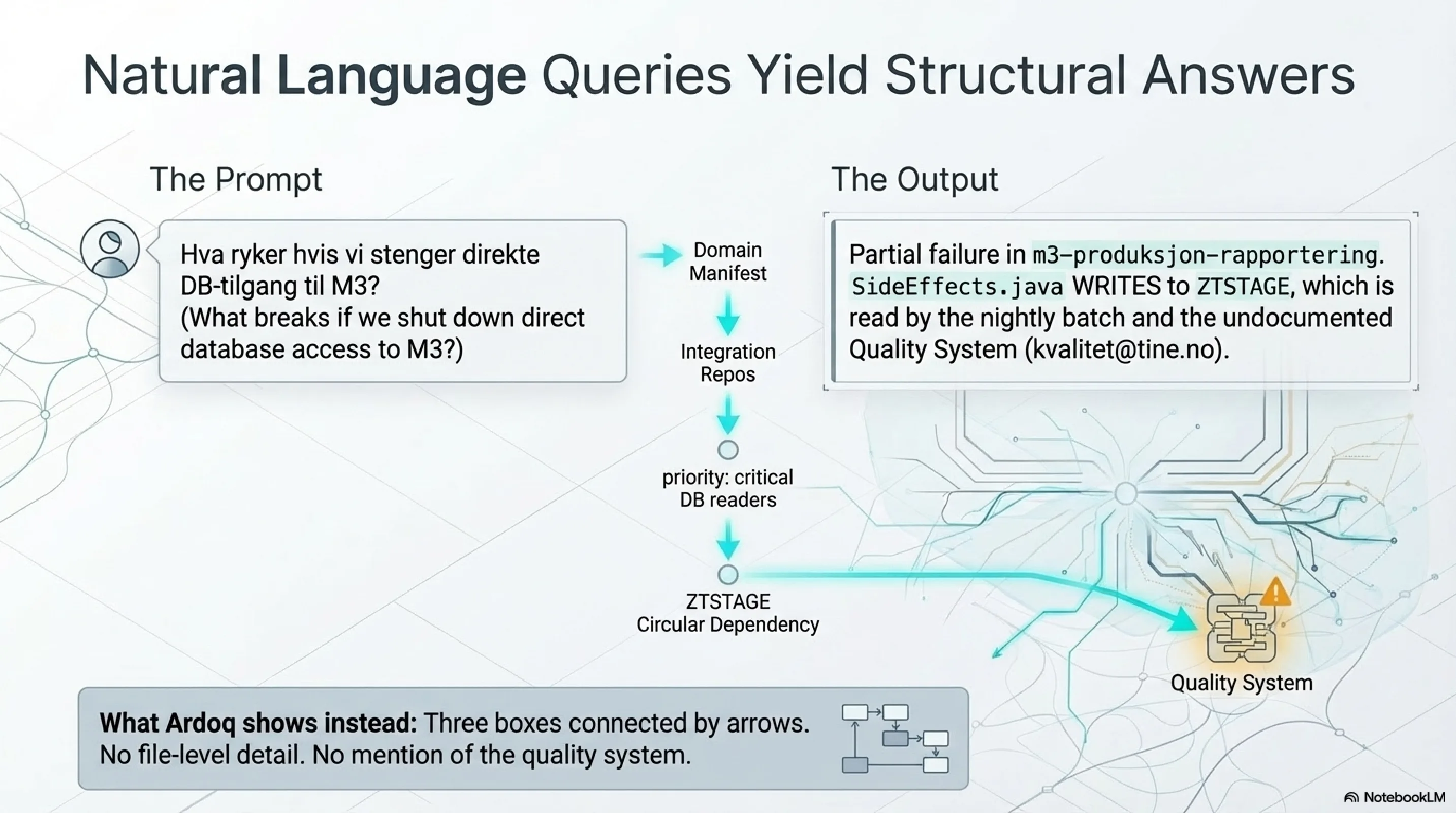
Synthesis indexes these manifests alongside the code. When someone queries "payment service API consumers," the FTS5 index returns every repository whose KCP manifest declares a dependency on the payment service, with the contract version, the specific endpoints consumed, and the ownership metadata. The query does not require anyone to remember that the batch job exists. The batch job's repository declares its own dependency. The knowledge is structural, not social.
This is the shift. Not from meetings to queries. From knowledge that requires human assembly to knowledge that is pre-assembled, version-controlled, and searchable. The manifests evolve with the code because they live alongside it, reviewed in the same pull requests, subject to the same CI checks.
What It Does Not Replace¶

The query tells you the blast radius. It does not tell you what to do about it.
After the search returned 3 downstream services, 1 SDK, and 1 batch job, there was still a decision to make. Do we version the new contract as v3 and maintain v2 in parallel? Do we coordinate a migration sprint? Is the batch job critical enough that its maintainer needs to be involved in the migration timeline, or can it be updated independently?
These are judgment calls. They require context that no manifest captures: the political dynamics between teams, the current sprint priorities, the risk appetite of the product owner, the fact that the batch job's original developer left six months ago and nobody has touched it since.
The meeting still happened. But it was 15 minutes instead of 45, and it started with the answer to the discovery question already on screen. Three engineers joined instead of the usual five, because the two people who would have been there solely to provide information were replaced by a query result. The conversation was about the decision, not the discovery.
This distinction matters because the temptation is to frame this as "meetings are waste." They are not. Discovery meetings are a symptom of missing infrastructure. Decision meetings are where human judgment happens. The goal is not fewer meetings. The goal is fewer meetings that exist solely because the organisation cannot answer its own questions.
The Structural Point¶
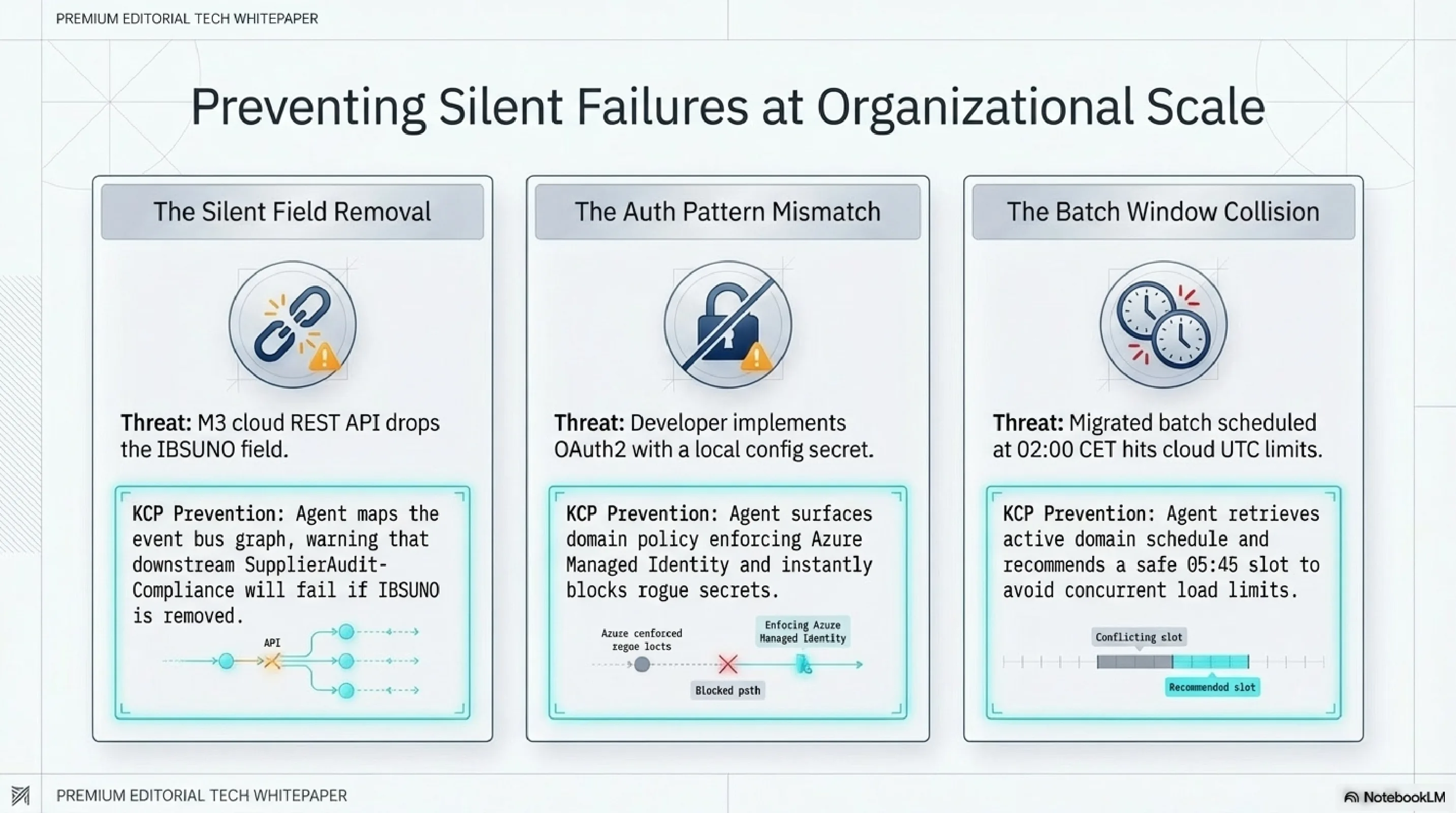
Every organisation I have worked with in 30 years of enterprise consulting has the same pattern. Knowledge accumulates in people. People leave, change roles, go on holiday, forget. The knowledge degrades. When a question arises that depends on that knowledge, the organisation's only recourse is to reassemble it from whoever is still around and hope the picture is complete.
This is not a process failure. It is an infrastructure failure. The organisation never built the system that would make its own knowledge queryable. Instead, it built processes around the absence of that system: architecture review boards, change advisory boards, impact assessment meetings, cross-team syncs. Each one a workaround for the same root cause.
KCP manifests are one answer. There are others. The specific technology matters less than the principle: organisational knowledge that cannot be queried will be assembled in meetings. Organisational knowledge that can be queried will be queried. The meeting was never the problem. The missing knowledge infrastructure was.
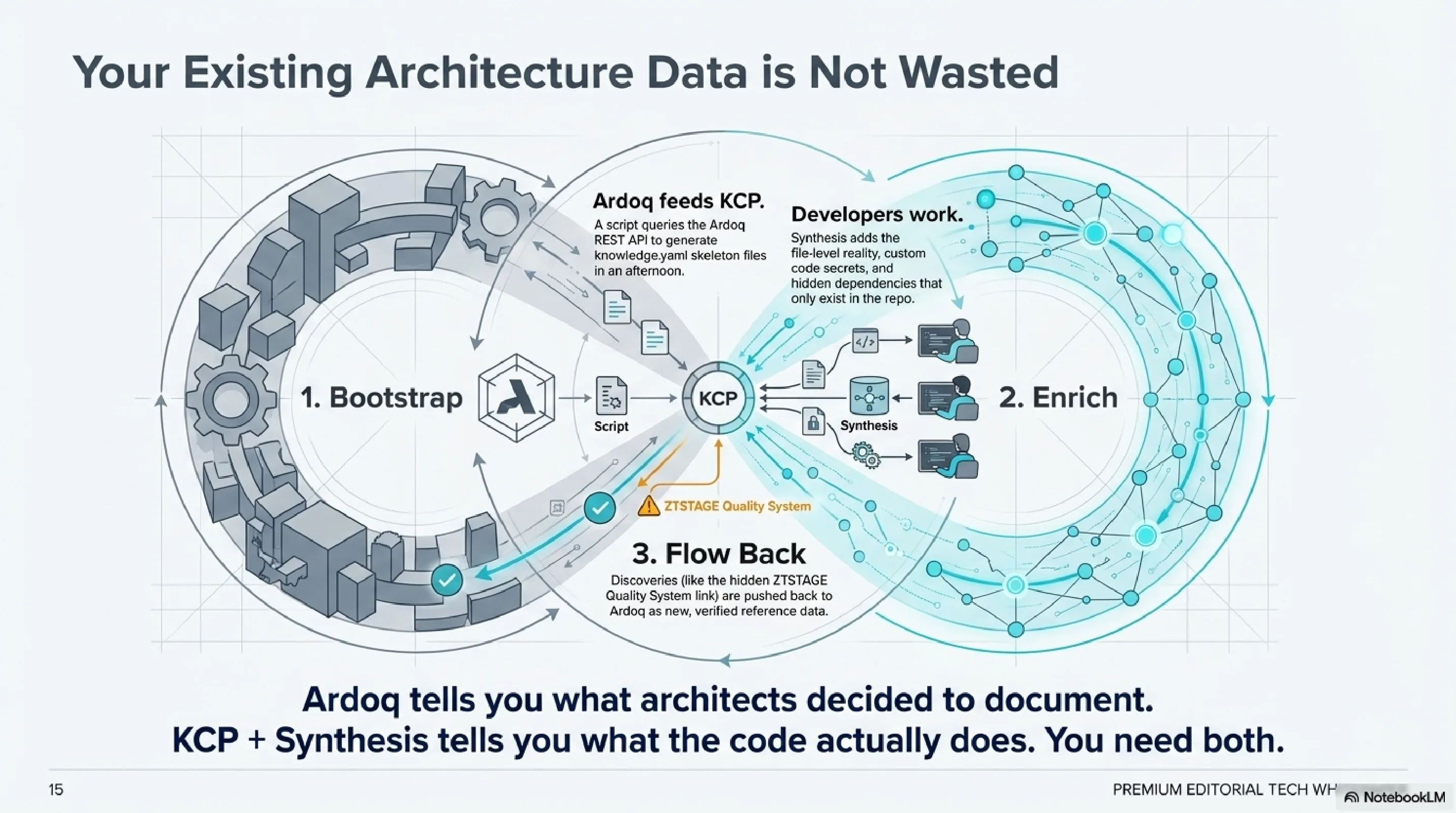
When the batch job showed up in the query results, the team lead said something that stuck with me: "I didn't even know that job still ran." In the old model, that would have been discovered in the architecture review, or worse, discovered in production after the contract change broke the nightly run. In the new model, the batch job's own manifest declared its dependency, and the query surfaced it without anyone needing to remember it existed.
That is what knowledge infrastructure does. It remembers what people forget. Not through AI magic or complex reasoning. Through structured declarations, version-controlled alongside the code, indexed and searchable in milliseconds. The most useful query result last week was not the three services everyone expected to find. It was the one batch job that nobody remembered.
Totto is the founder of eXOReaction, an enterprise architecture consultancy in Oslo. He builds Synthesis, the ExoCortex, and the KCP specification. Java Champion since 2005, thirty-plus years of enterprise systems, currently making organisational knowledge queryable so the right meetings can be shorter and the wrong ones can stop happening.