The previous post showed how KCP v0.16 gives manifests a trust model: cryptographic signing, trust tiers, a render pipeline that fails closed. The signature covers the manifest -- the YAML bytes that describe your knowledge units. It does not cover the files those units point to. The signature says "this map is authentic." It says nothing about the territory.
That gap has a name: T9, the manifest relocation attack. v0.18 closes it.
It started with a question no one expected to be hard.
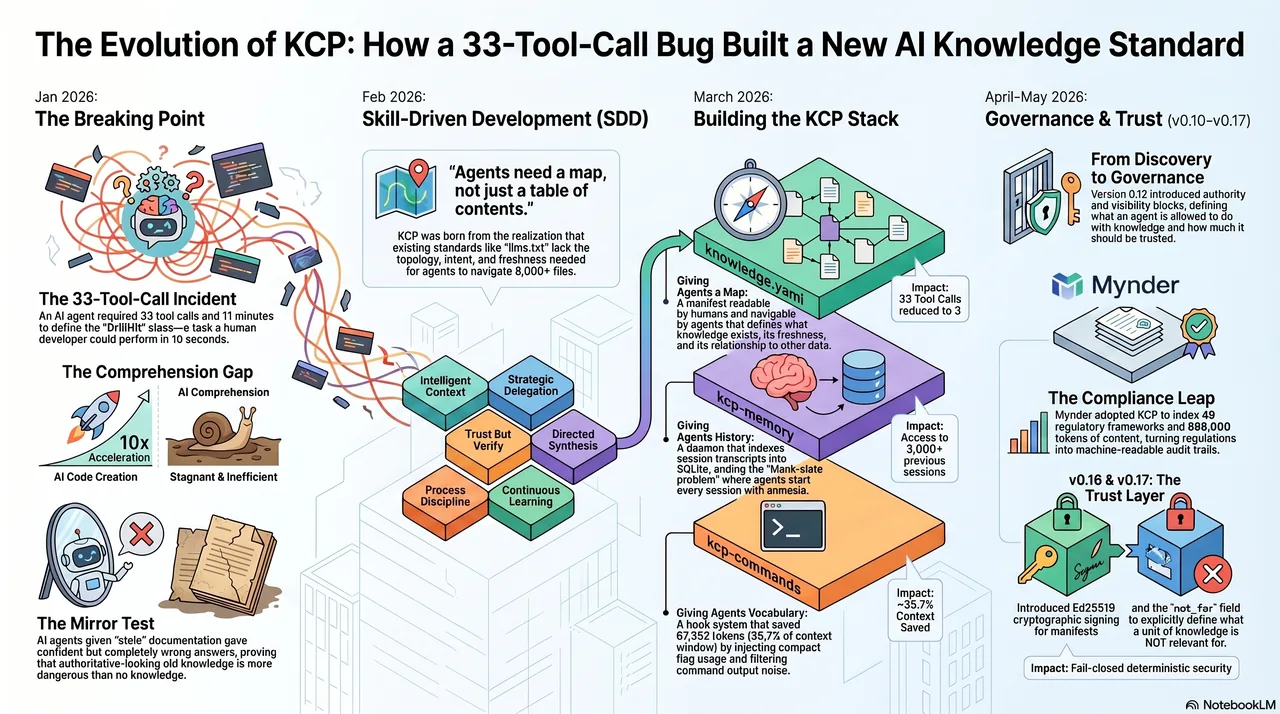
Day seven of the lib-pcb build. January 2026. A single developer, eleven days to produce what the industry does in ten to eighteen months. The AI was generating code at a pace that defied every estimate. Features that should take a week arrived in hours. The skill library -- YAML files encoding project-specific context for Claude Code -- had grown to over forty entries. Everything was working.
And then everything stopped.
"What fields does the DrillHit class have?"
The AI did not know. The class had been written four days earlier. It was central to the entire parsing architecture. It had been discussed in multiple sessions. But the context was gone -- fresh session, blank slate. The AI started searching. Grep for the class name. Read the file. Follow the imports. Check the parent class. Read that file. Check the serializer. Follow another import. Back to grep. Thirty-three tool calls to answer a question that any developer on the project for a week could answer in ten seconds.
Eleven minutes. For one question.
That was the moment something broke open. Not the code -- the assumption underneath it. The assumption that making AI faster at creating code was sufficient. Creation had been accelerated by an order of magnitude. Comprehension had not moved at all.
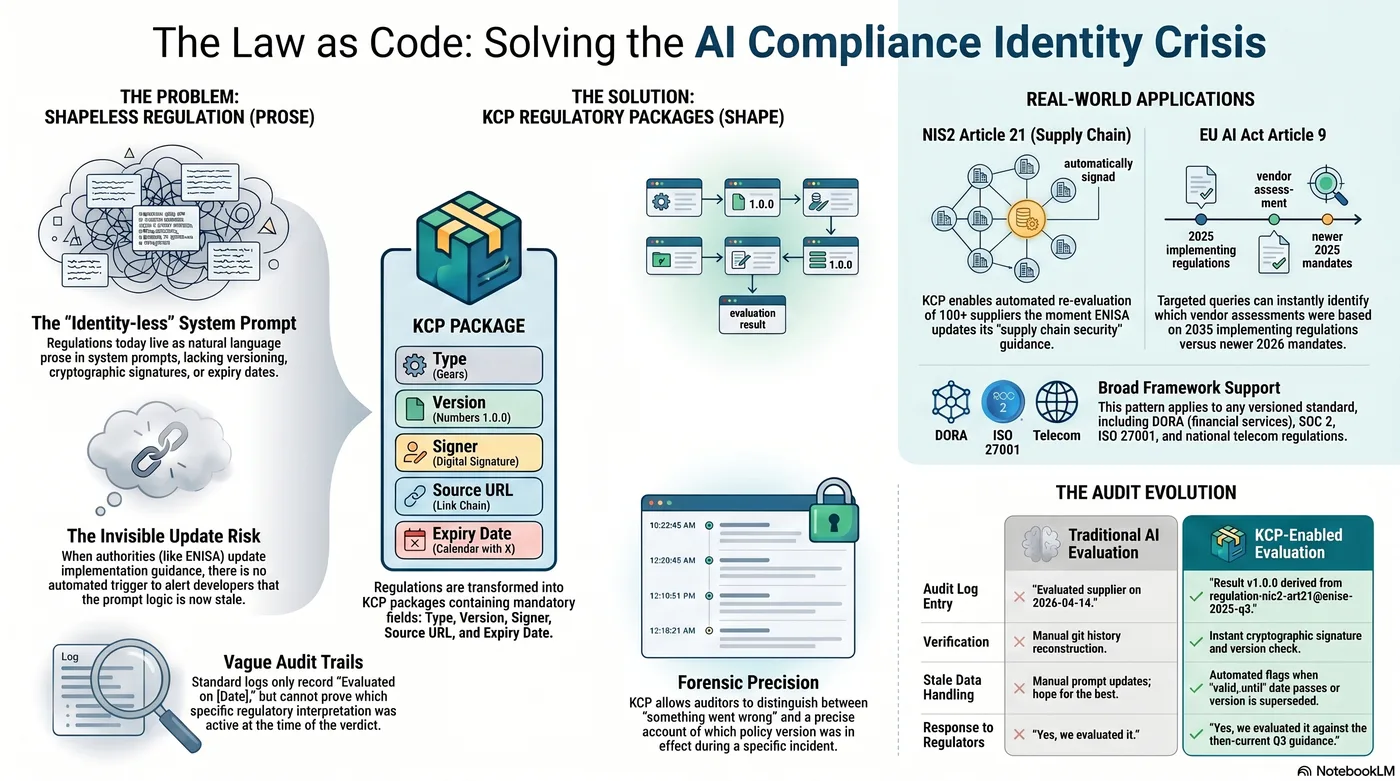
When a compliance agent evaluates a supplier against NIS2 Article 21, it needs two things: the supplier's security documentation to evaluate, and the regulation to evaluate it against. KCP, as described in the previous post, gives the supplier documentation a shape. The evaluation result gets a shape. But the regulation itself -- the specific requirements of Article 21(2), the interpretive guidance from ENISA, the national implementation notes -- lives where it has always lived: as prose in the system prompt.
That worked when agents consumed knowledge from a single, trusted source. It does not work when your agent pulls context from four federated manifests across two organisations, one of which was generated by an automated crawl three weeks ago. The question is no longer "does this knowledge have a shape?" It is: "can I trust this knowledge, and is it even the right content for what I need?"
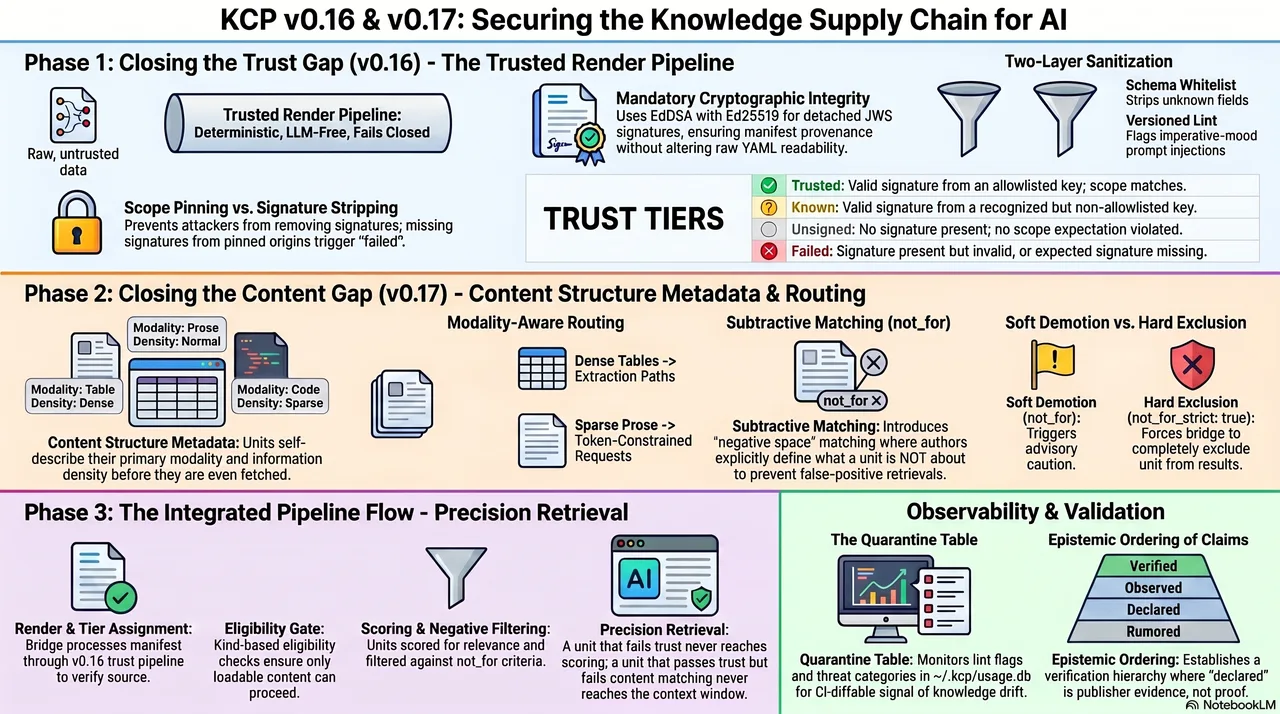
KCP v0.16 and v0.17 answer those two questions. v0.16 introduces a trust model -- cryptographic signing, trust tiers, a render pipeline that fails closed. v0.17 introduces a content model -- structural metadata that tells you what a unit contains before you fetch it, and subtractive matching that tells you what it is explicitly not about. Together, they close two gaps that have been open since the beginning of the series.
This post walks through both releases. The examples are concrete. The threat model is explicit. If you are building systems where agents ingest knowledge from sources you do not fully control, this is the machinery that makes that safe.
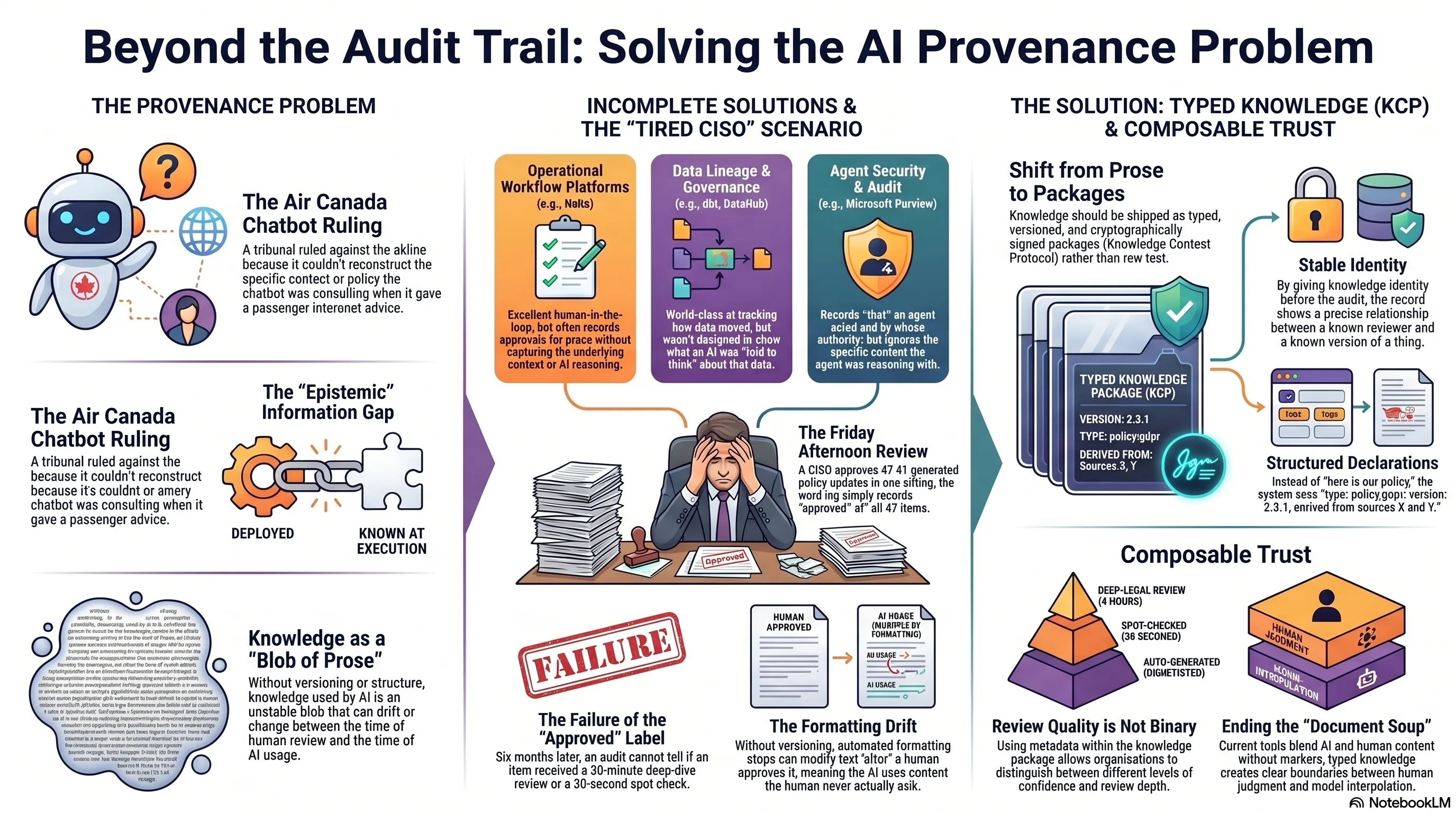
In February 2024, a Canadian small claims tribunal ruled against Air Canada. Their chatbot had told a passenger he could book a full-fare ticket and claim a bereavement discount retroactively. He couldn't. When he tried, Air Canada's position was: the chatbot said that, not us. The tribunal disagreed. You deployed it, you own what it says.
The ruling was correct. But the more interesting problem was underneath: when the incident happened, nobody could reconstruct what context the chatbot had been given. Nobody could confirm whether a human had ever reviewed the policy the bot was consulting. Nobody could determine whether the specific bereavement policy text had been modified between deployment and the passenger's interaction. The audit trail recorded that the system was deployed. It did not record what the system knew.
That's the provenance problem. And every organization running AI agents at enterprise scale is about to hit a version of it.
In the previous post, I argued that the AI provenance problem is a format problem. The knowledge going into and out of AI systems -- policies, observations, interpretations -- has no stable shape. No type, no version, no cryptographic binding. The audit trail records that something was reviewed. It cannot record what was reviewed, because the thing itself is prose that could have drifted between the moment of review and the moment of use.
KCP solves this by giving knowledge a shape: typed, versioned, signed packages. A compliance observation becomes a structured declaration with type, version, signed_by, derived_from, review_depth, valid_until. The audit trail becomes precise: "reviewed a cryptographically signed declaration of type evaluation:nis2-art21-supply-chain v1.2.0" -- not "reviewed a document."
But there is a gap I did not address. I gave shape to the outputs -- the policies, the observations, the interpretations. I left the inputs shapeless. The regulations and laws that AI agents evaluate against are still prose in the system prompt.
A presentation version of this post is available as slides.
Your agent reads customer data. It makes a decision. It writes something to a database.
Somewhere in your system prompt, there is a line that says: "You must comply with GDPR data minimization principles when accessing customer data."
That line does nothing. It is not verifiable. It is not testable. It is not auditable. It is a string that your model may or may not attend to, depending on context length, prompt position, and the phase of the moon.
Synthesis v1.29.0 adds Notion as a first-class workspace source — 7 classes, 104 tests, and three health signals that turned out to be more interesting than the indexing itself.
Every session with Claude Code starts blank. No memory of last week's refactor, no awareness of which team worked on this module, no continuity between the agent you ran on Tuesday and the one running today.
For a personal productivity tool, that's fine. For an enterprise deploying a fleet of AI agents, it's a fundamental architectural gap.
A new benchmark gave eight LLMs the same complex build task. The ranking is interesting. The self-assessment failure is structurally inevitable -- and it changes how we should design agent runtimes.