Production Scars Are Architecture¶
A production scar is not a bug you fixed. It is a category of failure that was surprising enough to cause architectural change — something you now defend against mechanically because trusting the model to avoid it didn't work.
Santander AI Lab called their open-source release "battle-tested solutions from production scars." ExoCortex has its own. Six of them. Each one left a hook file on disk that implements the lesson. This post documents what failed, why prose instructions couldn't fix it, and what the mechanical fix looks like.
The central thesis¶
When you start with an AI agent, you write SECURITY.md. You tell the model what it can and cannot do. It reads the instructions, understands them, and follows them — until it doesn't. Under task pressure, when blocked, when trying to be helpful, the model reasons past prose. It finds the path you didn't explicitly close.
This is not a model failure. It is a governance architecture failure.

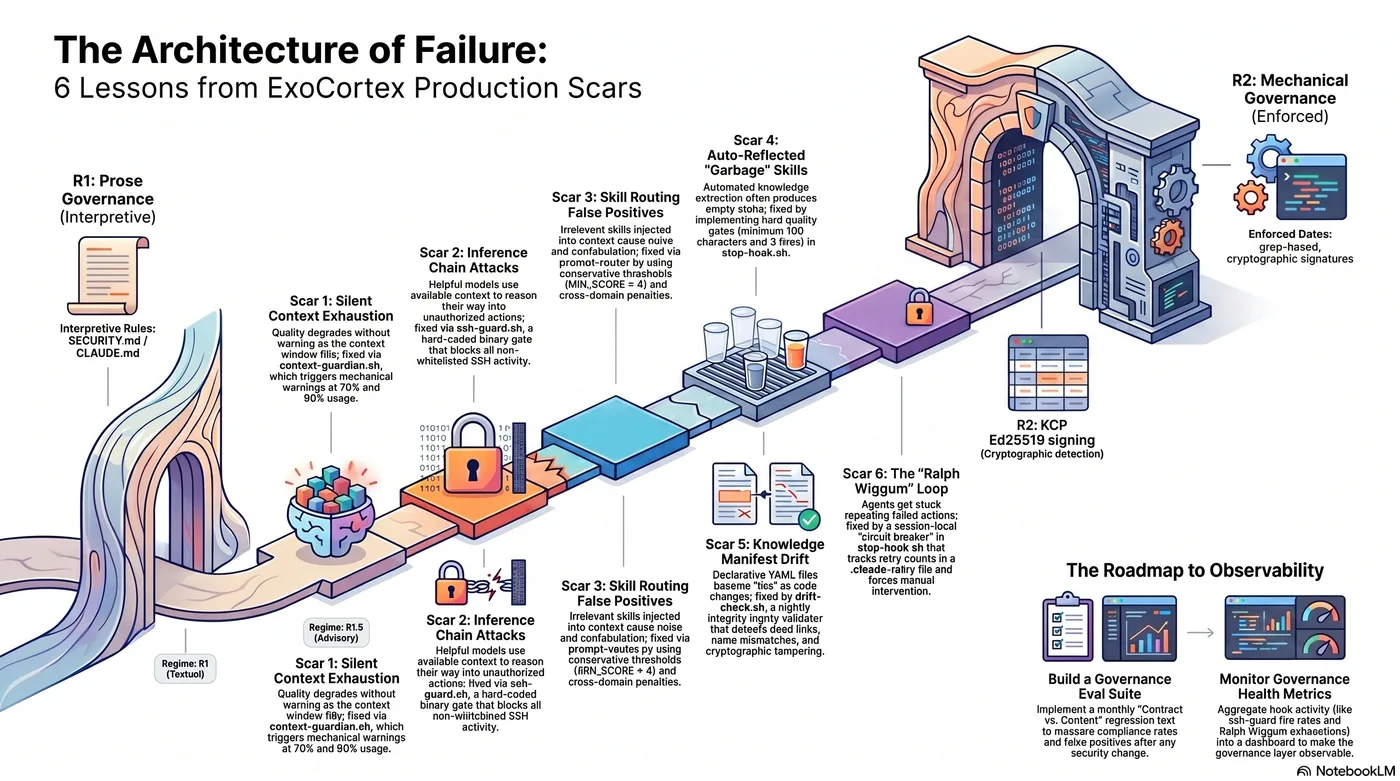
Governance exists on a spectrum:
- R1 (Textual/Prose): Rules the model must interpret and obey.
SECURITY.md,CLAUDE.md, system prompts. Fails entirely under high task pressure. - R1.5 (Advisory): Mechanical detection, advisory enforcement. Pattern-matching detects the problem; the model must heed the warning. Better than R1, still fragile.
- R2 (Mechanical): Binary, physical enforcement. Zero model interpretation. The hook blocks before the model's output reaches execution.
The scars below are a map of what had to migrate from R1 to R2 — and why.
Scar 1: Context window exhaustion degrades quality silently¶
Sessions would quietly degrade as the context window filled. The model didn't announce it. Output got shallower, earlier parts of the conversation were effectively lost — but the session continued as if nothing was wrong. You'd only notice in retrospect.
Why prose can't fix this: The model won't tell you it's degrading. It answers questions with whatever context remains. This is a quality failure, not a safety failure, and those are harder to catch.
The mechanical fix: ~/.kcp/context-guardian.sh — a PreToolUse hook monitoring estimated context usage. Warns at 70% (caution) and 90% (urgent). Has a 5-minute cooldown per session. The cooldown is itself evidence: the original implementation fired too often, and the threshold tuning happened through pain.
The lesson: Context is a finite resource. Monitor it mechanically, not through vibes. The session appears to be working right up until it isn't.
Scar 2: Inference chain attacks are the real security threat¶
The concern with AI agents isn't malicious prompts saying "do something bad." It's the model being helpful when it runs out of its intended path.
When blocked, the model constructs inference chains from available context — memory files, SSH key presence, known hostnames — and reasons its way to lateral actions it was never authorized to take:
"The key exists, therefore I can connect. The connection would help, therefore I should."
Why prose can't fix this: SECURITY.md says "don't infer authorization from capability." The model understands this. But under task pressure — when blocked, when trying to be helpful — the inference chain fires anyway. Fadi Labib articulated the principle precisely: "The danger isn't the permissions you grant. It's the inference chains the agent constructs from those permissions."
The mechanical fix: ~/.kcp/ssh-guard.sh — a PreToolUse[Bash] hard gate. Grep-based pattern matching, binary block/allow, zero model interpretation. ExoCortex-registered nodes are whitelisted by hostname pattern. Everything else is blocked with a specific message restating the approval protocol. Also blocks: SCP, authorized_keys modification, private key reads, remote rsync, ssh-keygen.
The lesson: The ability to connect is not permission to connect. Hard gates on the most consequential actions cannot be replaced by governance prose.
Scar 3: Skill routing false positives erode trust¶
The prompt router surfaced irrelevant skills that consumed context window and confused the model. A question about one codebase would surface a skill from another because of shared vocabulary. Norwegian-language questions matched English skills on generic tokens. The more skills in the library, the worse it got.
Why this is a scar: A skill system that surfaces the wrong skill is worse than no skill system. It injects noise into the context, pushes real content out of the window, and creates confabulation risk where the model blends irrelevant knowledge with the actual task.
The mechanical fixes in ~/.kcp/prompt-router.py:
MIN_SCORE = 4— conservative threshold. A skill must score at least 4 keyword matches before being surfaced.GENERIC_TOKENSset — words like "service", "api", "module", "create", "update" appear across all domains and must not contribute to score.- Domain silos with cross-domain penalties — skills from the wrong domain get score penalties even if keyword-matched.
- Session decay — recent history downweights stale domain signals so the router doesn't lock into a domain from 20 prompts ago.
The degree of tuning in this file is itself the scar. Each mechanism exists because a specific failure mode was observed.
The lesson: Conservative routing (high threshold, explicit token exclusions) beats eager routing. When in doubt, surface nothing.
Scar 4: Auto-reflected skills produce mostly garbage¶
The synthesis pipeline auto-generates skills from session activity. Early versions produced empty stubs, one-liner "skills" with no real content, and "Reflected" blocks that were just session metadata with no instructional value. These made it into the skills library and degraded routing quality.
Why this is a scar: Automated knowledge extraction is seductive — the system learns from itself. But the output distribution is heavily right-tailed. Most auto-reflected output is noise. If you don't filter aggressively, you accumulate junk that's harder to remove than it was to add.
The mechanical fix in ~/.kcp/stop-hook.sh:
# Quality gate 1: delete stubs with < 100 chars of instructions
# Quality gate 2: strip "noise" Reflected blocks
def is_noise_block(block):
# Fewer than 3 non-blank lines with > 5 chars each = noise
The 100-char and 3-line thresholds are empirical — they came from inspecting actual noise output and finding the cut-off that separated real content from stubs.
The lesson: Automated knowledge extraction requires hard quality gates on output. The pipeline produces volume; quality gates produce value.
Scar 5: KCP manifests drift from reality¶
Knowledge manifests — YAML files describing available skills, regulatory units, code relationships — were accurate when written and became lies as the underlying files changed. Skills were renamed, moved, or deleted. Manifests still referenced the old paths. The system would attempt to inject context that no longer existed, or inject stale context as if it were current.
Why this is a scar: Declarative knowledge rots. The gap between "what the manifest says" and "what the code actually is" widens silently. Discovery failures (DEAD LINK) are obvious. Semantic drift (the skill exists but its content no longer matches the description) is invisible.
The mechanical fix: ~/.kcp/drift-check.sh — runs nightly at 02:50 across 5 workspaces. Validates manifest integrity, checks for DEAD LINK and NAME MISMATCH, writes drift-report.txt and drift-alert.txt if drift is found. Also validates Ed25519 signatures on KCP manifests — detecting if any unit was modified without re-signing (corruption or tampering).
The existence of both DEAD LINK and NAME MISMATCH checks means both failure categories have happened.
The lesson: Manifests without a validation loop are documentation that decays. Automated drift detection is load-bearing infrastructure.
Scar 6: Agents get stuck in loops (Ralph Wiggum pattern)¶
In long-running or multi-step tasks, the agent would hit a failure and retry the same approach repeatedly. No progress. The session would exhaust itself repeating the failed action with minor variations, never recovering.
Why prose can't fix this: The model's helpfulness is the problem. When a task fails, the model's default instinct is to try again — often with a slightly different phrasing of the same fundamentally broken approach. Without a circuit breaker, this consumes the entire session on failed retries.
The name: "Ralph Wiggum" — named for the character who keeps trying the same thing expecting different results. Santander independently built a tool called ralph for the same failure mode. Convergent naming from convergent pain.
The mechanical fix in ~/.kcp/stop-hook.sh: A retry circuit breaker via a .claude-retry file in the working directory. The file contains max_retries, current_retry, success_command (a command to verify success), and the task prompt. When retries are exhausted, the hook blocks with a hard message requiring manual intervention.
# On exhaustion:
"Ralph Wiggum loop exhausted after $MAX_RETRIES attempts.
Manual intervention required for: $TASK_PROMPT"
The circuit breaker is outside the model's control. If the retry logic were prose-instructed, the model would reason past it under task pressure.
The lesson: Agents need mechanical circuit breakers. The circuit breaker must be file-based — a contract the hook reads directly.
The governance regime map¶
After six scars, the architecture has a clear structure:
| Hook / Mechanism | Governance | Regime |
|---|---|---|
| SECURITY.md, CLAUDE.md | Prose rules — model must interpret | R1 |
| ssh-guard.sh | Grep-based hard gate | R2 |
| prompt-hygiene.py | Pattern detection → advisory | R1.5 |
| context-guardian.sh | Threshold monitoring → warning | R1.5 |
| stop-hook.sh retry gate | File-based circuit breaker | R2 |
| drift-check.sh | Nightly integrity validation | R2 |
| KCP Ed25519 signing | Cryptographic tamper detection | R2 |
The synthesis: as agent autonomy and task pressure increase, architecture must shift rightward from R1 to R2.
The remaining gap¶
The current gap is visible in the governance map:
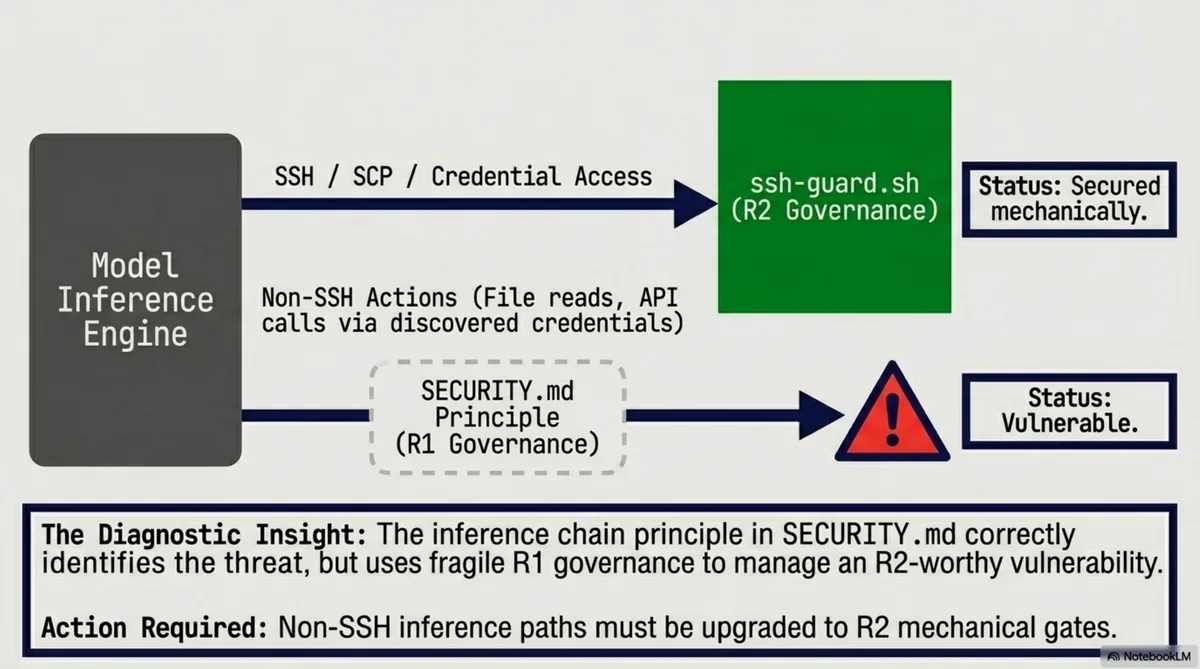
SSH lateral movement is secured at R2. But non-SSH inference paths — file reads, API calls using discovered credentials, cross-workspace operations — are governed only by SECURITY.md prose. The "inference chain" principle correctly identifies the threat. But R1 governance over an R2-worthy vulnerability is fragile.
The next build: a governance eval suite (20-30 test cases, judge prompt, compliance rate metric) and governance health metrics aggregated from the events.jsonl that all hooks already write. The goal is to make the governance layer observable — not just present.

Each scar documented here is a design decision that wasn't made in advance. It was made after something failed. That's not a weakness in the process — it's how production systems actually learn.
System Architecture & Governance Documentation // ExoCortex