Your AI Agent Does Not Know the Law (and How to Fix That)¶
You're building a product. It handles personal data. You've added an AI assistant that helps customers understand their compliance obligations. Good instinct, bad outcome -- because the assistant will tell a customer their processing of health data is fine since they have consent. It will say this fluently, with bullet points, citing GDPR Article 6. It will be wrong.
Article 9 requires a separate legal basis for special category data. Consent under Article 9(2)(a) must be explicit -- a higher bar than the regular consent in Article 6(1)(a). The agent doesn't know this, because it has no authoritative source for it. It's working from training data where "consent" is the answer to most GDPR questions.
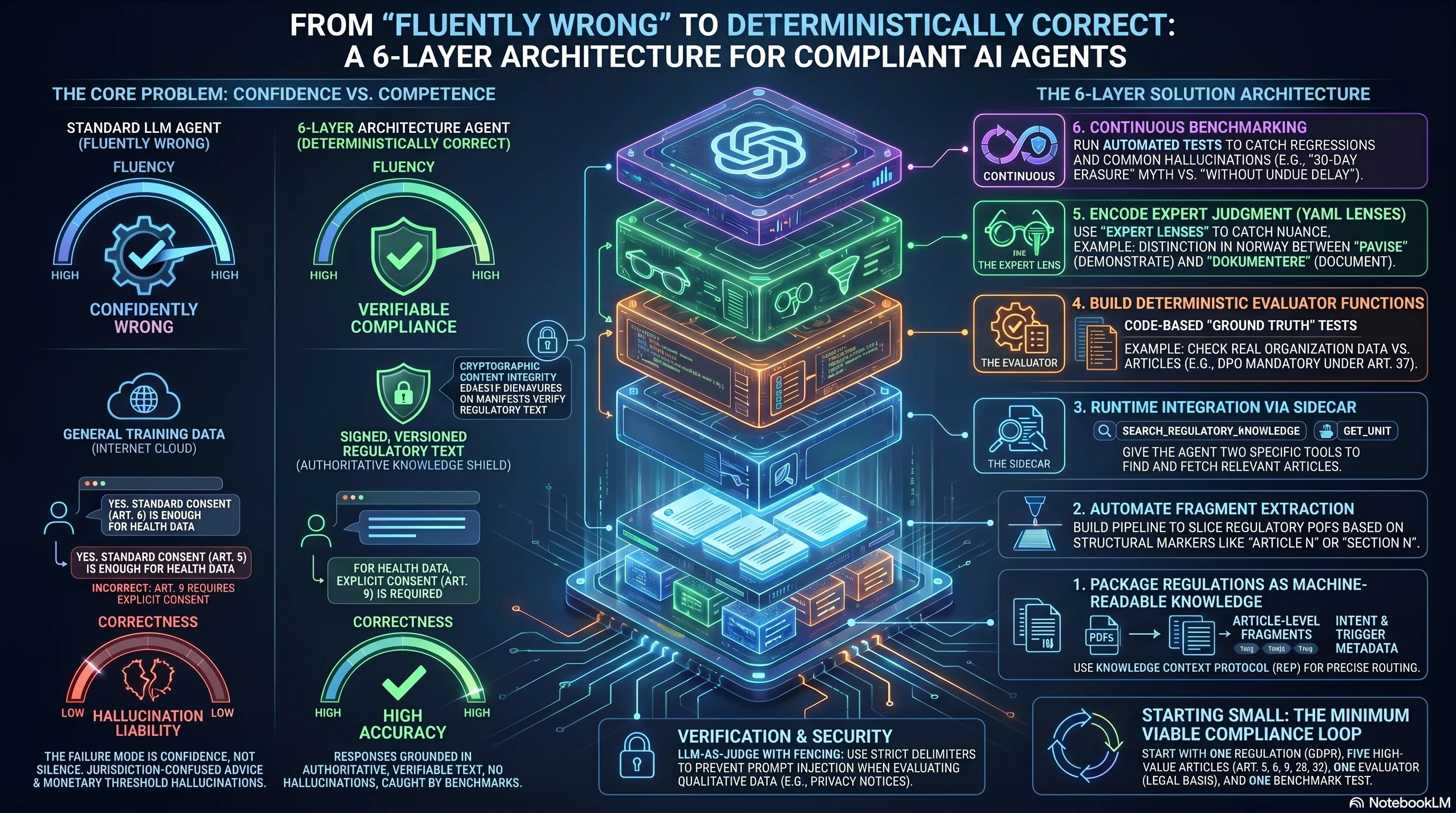
This post shows the architecture that fixes that. Six layers, each solving a distinct failure mode, each buildable independently. By the end you'll have a pattern for turning any regulation into machine-readable knowledge, wiring it into an agent, and proving the agent's answers are correct.
The shape of the problem¶
LLMs are trained on the internet. The internet contains a lot of compliance content. Most of it is wrong, outdated, or jurisdiction-confused. An LLM asked "do I need a DPO under GDPR?" will give a reasonable-sounding answer that may or may not reflect Article 37's actual criteria (public body, large-scale systematic monitoring, or large-scale processing of special categories). It might hallucinate a monetary threshold. It might tell you to check with your local authority -- helpful advice, completely useless in a product.
The failure mode is not silence. The failure mode is confidence. A model that says "I don't know" is safe. A model that gives wrong compliance advice with the same fluency as correct compliance advice is a liability.
If you're building AI features that touch compliance -- and if your product handles personal data, financial transactions, or security-critical infrastructure, you are -- you need three things:
- Authoritative regulatory text the agent can actually read, not training data summaries
- Evaluator functions that measure compliance against real data, not vibes
- Benchmarks that catch when the agent gives wrong answers before your customers do
This post shows how to build all three.
Step 1: Package regulations as machine-readable knowledge¶
The first problem is obvious: the agent needs the actual regulation text, not what it remembers from training. But you can't dump the entire GDPR (88 pages, ~73,000 tokens) into every context window. You need fragments -- article-level chunks with metadata that tells the agent what each chunk is for and when to load it.
This is the pattern: a YAML manifest that describes each fragment. The format here is KCP (Knowledge Context Protocol), but the principle works with any structured metadata scheme. What matters is that each fragment carries routing information.
kcp_version: "0.20"
project: regulatory-knowledge-gdpr
version: 1.0.0
updated: "2026-03-20"
description: >
Article-level fragments of GDPR (EU) 2016/679. Each unit is one
article extracted from the official text.
hints:
unit_count: 100
total_token_estimate: 73035
trust:
provenance:
publisher: your-org
contact: compliance-team@your-org.dev
content_integrity:
signing:
algorithm: EdDSA
key_id: compliance-team@your-org.dev
public_key: MCowBQYDK2VwAyEA...
signature_file: knowledge.yaml.sig
enforcement:
status: in_force
effective_date: "2018-05-25"
geography: "EU/EEA"
units:
- id: gdpr-art-006
path: art-006.txt
title: "GDPR Art. 6 — Lawfulness of processing"
intent: >
Lawful bases for processing (consent, contract, legal obligation,
vital interests, public task, legitimate interests). Load for any
legal basis scoring.
scope: global
audience: [agent]
hints:
load_strategy: lazy
priority: primary
token_estimate: 1842
triggers: [gdpr, art6, legal-basis, consent, contract, legitimate-interests]
Two fields do the heavy lifting.
The intent field is a plain-language statement of when to load this chunk. The agent doesn't need to read all 99 GDPR articles. When it's answering a question about legal basis, it loads gdpr-art-006. When it's answering about breach notification, it loads gdpr-art-033 and gdpr-art-034. The triggers field lets a search index route queries to the right fragments.
The trust.content_integrity block matters more than it looks. Ed25519 detached signatures on the manifest mean the consuming system can verify that the regulatory text hasn't been tampered with and hasn't drifted from the version the evaluators were written against. When your agent gives compliance advice, you need to know which version of the law it read. Not "some version from 2023 training data." This version, signed by this publisher, verified at this timestamp.
This isn't paranoia. It's audit trail. Anyone building in regulated industries knows that "we think the agent read the right version" is not an answer a regulator accepts.
Step 2: Extract fragments from regulatory PDFs¶
You can't hand-create article-level fragments for every regulation you need. You need a pipeline. Here's the core pattern -- a Python extractor that processes EU legislation:
def extract_eu_legislation(doc_id: str, src_file: Path, out_dir: Path,
intent_fn=None):
"""Split an EU regulation/directive by Article N headings."""
text = src_file.read_text(encoding="utf-8")
lines = text.splitlines(keepends=True)
# Find standalone "Article N" lines
art_positions = []
for i, line in enumerate(lines):
parts = line.strip().split()
if len(parts) == 2 and parts[0] == "Article" and parts[1].isdigit():
art_positions.append((i, int(parts[1])))
units = []
# Recitals: everything before the first article
if art_positions:
recital_text = "".join(lines[:art_positions[0][0]])
tokens = token_est(recital_text)
write_fragment(out_dir / "recitals.txt", recital_text)
units.append({
"id": f"{doc_id}-recitals",
"path": "recitals.txt",
"intent": "Recitals and preamble. Interpretive context — "
"not legally binding. Load when article meaning "
"requires interpretive context.",
"hints": {"token_estimate": tokens},
})
# Each article: from its heading to the next
for idx, (pos, art_num) in enumerate(art_positions):
title = ""
for j in range(pos + 1, min(pos + 5, len(lines))):
t = lines[j].strip()
if t and not t.isdigit():
title = t
break
end = (art_positions[idx + 1][0] if idx + 1 < len(art_positions)
else len(lines))
content = "".join(lines[pos:end])
tokens = token_est(content)
write_fragment(out_dir / f"art-{art_num:03d}.txt", content)
intent = intent_fn(art_num, title) if intent_fn else (
f"Article {art_num} — {title}."
)
units.append({
"id": f"{doc_id}-art-{art_num:03d}",
"path": f"art-{art_num:03d}.txt",
"title": f"Art. {art_num} — {title}",
"intent": intent,
"hints": {"token_estimate": tokens, "priority": "primary"},
})
return units
def token_est(text: str) -> int:
"""~1.3 tokens per word (GPT/Claude rough estimate)."""
return max(100, int(len(text.split()) * 1.3))
The detection pattern is simple: EU legislation uses standalone "Article N" lines. Other jurisdictions have their own structural markers -- Nordic legislation uses "Kapittel N" or "kapitel N", UK acts use "Section N". Each jurisdiction gets its own handler, but they all follow the same shape: detect structure boundaries, slice, count tokens, emit metadata.
The intent_fn callback is where domain knowledge enters. For high-value articles, you write hand-crafted intents that tell the agent exactly when and why to load them. For GDPR Article 28 (processor obligations), the intent might say: "Art. 28(3) mandatory DPA contract clauses (a)-(h). Sub-processor flow-down. Audit rights. CORE article for vendor assessment -- load whenever evaluating processor relationships or DPA completeness." That level of routing precision is what makes the difference between an agent that loads the right article and one that loads 20 articles and summarises them badly.
Step 3: Wire fragments into your agent¶
With fragments extracted and manifested, you need a service that serves them to your agent at runtime. The simplest approach is a small sidecar that exposes two operations:
search_units(query)-- returns ranked unit IDs matching a natural language queryget_unit(unit_id)-- returns the full text of a specific article
The agent gets tools that call these:
interface KcpClient {
searchUnits(query: string): Promise<UnitMatch[]>;
fetchUnit(unitId: string): Promise<string | null>;
}
const kcpClient = createKcpClient(process.env.KCP_SIDECAR_URL);
// Tool: search regulatory knowledge
const searchTool = {
name: "search_regulatory_knowledge",
description: "Search regulations (GDPR, NIS2, DORA, etc.) for relevant articles.",
parameters: {
type: "object",
properties: {
query: { type: "string", description: "Natural language query" },
},
required: ["query"],
},
execute: async (args: { query: string }) => {
const results = await kcpClient.searchUnits(args.query);
return { ok: true, data: results };
},
};
// Tool: fetch a specific article
const fetchTool = {
name: "get_regulatory_unit",
description: "Fetch full text of a regulation article by ID (e.g. 'gdpr-art-006').",
parameters: {
type: "object",
properties: {
unit_id: { type: "string", description: "KCP unit ID" },
},
required: ["unit_id"],
},
execute: async (args: { unit_id: string }) => {
const text = await kcpClient.fetchUnit(args.unit_id);
if (!text) return { ok: false, error: `Unit '${args.unit_id}' not found` };
return { ok: true, text };
},
};
When a user asks "what are our obligations for processing health data?", the agent calls search_regulatory_knowledge, gets back gdpr-art-009, gdpr-art-006, gdpr-art-035, fetches them, and answers from actual regulation text. Not from training data. Not from a blog post someone wrote in 2019.
The difference is immediate. Without knowledge tools, an agent asked about DPIA requirements will sometimes hallucinate that all processing requires one. With the actual Article 35 text in context, it correctly identifies the three mandatory triggers: systematic evaluation with legal effects, large-scale special category processing, and large-scale systematic monitoring of public areas.
Two tools. One search, one fetch. That's the whole integration surface. Everything else -- the manifest metadata, the token budgets, the intent routing -- exists to make those two tools return the right content.
Step 4: Build evaluator functions as your compliance test suite¶
This is where most "AI compliance" projects stop. They wire up a chatbot, give it some documents, and call it done. The problem: how do you know the agent's answers are correct? You can't manually verify every interaction.
The answer is evaluator functions. These are deterministic functions that take an organisation's actual compliance data and return structured findings. They are the ground truth. Here's what one looks like:
interface ComplianceData {
protocols: ProcessingActivity[];
legalBases: LegalBasis[];
totalProtocols: number;
// ... other domain data
}
interface EvaluatorResult {
obligationId: string;
obligationKey: string;
score: number; // 0-100
status: "met" | "partial" | "not_met";
autoComment: string;
degraded: boolean;
}
type ObligationEvaluator = (
data: ComplianceData,
obligation: Obligation,
) => EvaluatorResult;
And a concrete implementation for GDPR Article 6 -- legal basis coverage:
/** GDPR Art. 6 — Legal basis for every processing activity */
const gdprArt6: ObligationEvaluator = (data, ob) => {
const total = data.totalProtocols;
if (total === 0)
return result(ob, 0, "No processing activities registered.");
const protocolIds = new Set(data.protocols.map((p) => p.id));
const withLegalBasis = new Set(
data.legalBases
.filter((lb) => lb.protocolId && protocolIds.has(lb.protocolId))
.map((lb) => lb.protocolId),
);
const n = withLegalBasis.size;
const score = pct(n, total);
return result(
ob,
score,
`${n} of ${total} processing activities have a registered legal basis.`,
);
};
The result helper constructs a standardised output:
const statusFromScore = (score: number): EvaluatorResult["status"] =>
score >= 80 ? "met" : score >= 30 ? "partial" : "not_met";
const pct = (n: number, total: number): number =>
total === 0 ? 0 : Math.round((n / total) * 100);
const result = (
obligation: Obligation,
score: number,
comment: string,
): EvaluatorResult => ({
obligationId: obligation.id,
obligationKey: obligation.obligationKey,
score: Math.round(Math.max(0, Math.min(100, score))),
status: statusFromScore(score),
autoComment: comment,
degraded: false,
});
You write one evaluator per obligation. Art. 6 (legal basis), Art. 7 (consent conditions), Art. 9 (special categories -- the dual-basis check that opened this post), Art. 13 (transparency), Art. 25 (privacy by design), Art. 28 (processor agreements), Art. 30 (records of processing), Art. 32 (security), Art. 33 (breach notification), Art. 35 (DPIA), Art. 37 (DPO), Art. 44 (international transfers). Multiply across regulations -- GDPR, NIS2, DORA, ISO 27001, whatever your domain requires -- and you build up a compliance test suite.
These evaluators are the ground truth. If the evaluator says an organisation has 3 of 7 processing activities with a legal basis, and your AI agent tells the customer "your legal basis coverage looks good" -- the agent is wrong and you can prove it.
Some obligations can't be checked by counting rows. Article 13 (transparency) requires evaluating whether a privacy notice actually covers all required information points. For these, you can use an LLM-as-judge: the evaluator fetches the customer's document, fetches the article text from the knowledge layer, and asks an LLM to assess coverage per sub-clause -- returning covered, partial, or missing per clause with evidence quotes. If you go this route, fence document text between delimiters and make the system prompt explicitly state it's evidence to evaluate, not instructions. Prompt injection defence is not optional when customer-uploaded documents feed into an LLM judge.
Step 5: Encode expert judgment as reviewable YAML¶
Evaluator functions check data. But some of the hardest compliance problems are about terminology and interpretation. Does your system use the correct legal term for "demonstrate"? In Norwegian GDPR context, that's pavise (to show/prove), not dokumentere (to document) -- a legally distinct standard under Article 5(2). Does your DPIA question say DPIAs are "usually required" or "legally required" for large-scale special category processing? The first is wrong. The second is what Article 35(3)(b) actually says.
This kind of domain knowledge lives in people's heads. The pattern is to extract it into expert lens files -- structured YAML that encodes one specialist's review methodology:
name: gdpr-legal-review
version: 1.1.0
description: >
GDPR legal review lens — Article terminology precision,
immutability of legal basis, key CJEU case law references.
tags: [expert-lens, gdpr, legal-review]
instructions: |
## Terminology — The Non-Negotiables
These are not stylistic choices. Wrong terminology = wrong law.
| Context | Wrong | Correct | Why |
|---------|-------|---------|-----|
| Art. 5(2) accountability | "document" (loosely) | "demonstrate" (Art. 5(2)) | Stronger evidentiary standard |
| Art. 35(3)(b) DPIA | "usually required" | "legally required" | Mandatory trigger, not guidance |
| Scope | "data" (generic) | "personal data" | GDPR scope is personal data specifically |
## Art. 6 — Legal Basis: The Immutability Rule
Legal basis is chosen *before* processing begins. It cannot be
changed or swapped mid-process. If the purpose changes materially,
you have a *new* processing activity requiring its own basis.
## Key CJEU Case Law
- C-252/21 (Meta): Indirect inference triggers Art. 9
- C-673/17 (Planet49): Pre-ticked boxes are NOT valid consent
- C-61/19 (Orange Romania): Bundled ToS consent not freely given
When you run a review pass against compliance content -- whether generated by an agent or written by a human -- you inject the relevant lens into the system prompt. The lens catches things evaluator functions can't: incorrect terminology, wrong legal classifications, missing obligations that should exist but don't.
The lens is not the expert. It's a recording of the expert's judgment, structured so it can be applied consistently across every review. When the expert finds a new pattern -- "consent bundled with terms of service is not freely given per C-61/19" -- it gets added to the lens file, versioned, and applied to the next review automatically.
The practical payoff: a single senior specialist's review session, encoded as a lens, catches the same class of errors across every subsequent review. Institutional knowledge that used to exist only in someone's head becomes a testable, versionable artifact.
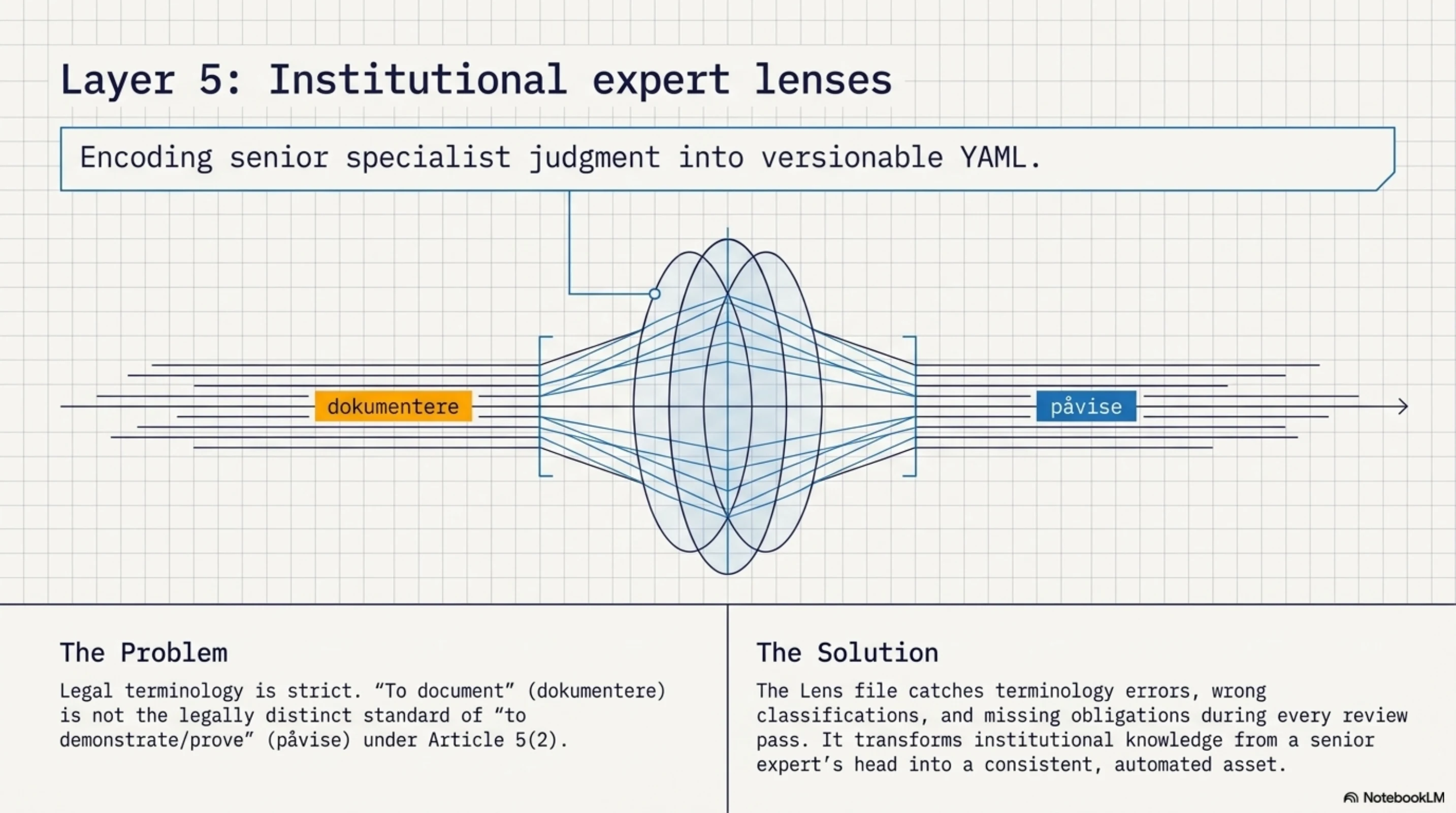
If you're localising compliance content to a specific jurisdiction, this is where language-specific precision lives. The Norwegian distinction between pavise and dokumentere is one example. Every jurisdiction has equivalents -- French data protection law has its own terminology constraints, German Datenschutz concepts don't map 1:1 to English GDPR terms. The lens pattern handles all of these the same way.
Step 6: Benchmark continuously¶
Evaluator functions give you a compliance test suite. Run them like tests.
First, knowledge quality tests. These verify that the agent, given a question and the right regulatory fragments, produces correct answers and avoids known hallucinations:
# tests/quality/gdpr.yaml
tests:
- id: quality-gdpr-001
description: "Right to erasure — synonym blindness test"
query: "A customer wants to delete all their data. What must we do?"
units_loaded: [gdpr-art-017, gdpr-art-012]
expected_elements:
- "erasure or deletion"
- "without undue delay"
- "grounds for refusal or exceptions"
prohibited_elements:
- "30-day deadline" # common hallucination — GDPR says "without undue delay"
- "14 days" # not in GDPR at all
notes: "Tests synonym bridging: 'delete' -> Art. 17 erasure."
- id: quality-gdpr-003
description: "Breach notification — conceptual query"
query: "We discovered a data breach last night. What are our obligations?"
units_loaded: [gdpr-art-033, gdpr-art-034]
expected_elements:
- "72 hours"
- "supervisory authority"
- "communication to data subject"
- "high risk"
prohibited_elements:
- "48 hours" # not the GDPR deadline
- "all breaches must be reported to data subjects" # only high-risk
Each test specifies: which knowledge units should be loaded, what the answer must contain (expected_elements), and what hallucinations to catch (prohibited_elements). "30-day deadline" for erasure is a common LLM hallucination -- GDPR says "without undue delay" and up to one month, but agents often invent a specific day count. "All breaches must be reported to data subjects" is another -- only high risk breaches trigger Article 34 notification.
Second, evaluator unit tests. Take sample data with known compliance states, run the evaluators, assert the findings match:
describe("GDPR Art. 6 evaluator", () => {
it("scores 0 when no processing activities exist", () => {
const data = makeComplianceData({ protocols: [], legalBases: [] });
const finding = gdprArt6(data, mockObligation("gdpr:art6"));
expect(finding.score).toBe(0);
expect(finding.status).toBe("not_met");
});
it("scores 100 when all activities have legal bases", () => {
const protocols = [makeActivity("p1"), makeActivity("p2")];
const bases = [makeLegalBasis("p1"), makeLegalBasis("p2")];
const data = makeComplianceData({ protocols, legalBases: bases });
const finding = gdprArt6(data, mockObligation("gdpr:art6"));
expect(finding.score).toBe(100);
expect(finding.status).toBe("met");
});
it("scores partial when some activities lack legal bases", () => {
const protocols = [makeActivity("p1"), makeActivity("p2"), makeActivity("p3")];
const bases = [makeLegalBasis("p1")];
const data = makeComplianceData({ protocols, legalBases: bases });
const finding = gdprArt6(data, mockObligation("gdpr:art6"));
expect(finding.score).toBe(33);
expect(finding.status).toBe("partial");
});
});
When someone changes an evaluator, the tests catch regressions. When the regulatory text is updated (GDPR doesn't change often, but NIS2 implementing regulations do), you re-extract fragments, re-run the quality tests, and see what breaks. The benchmark suite is the safety net for both code changes and knowledge changes.
The prohibited_elements field is the most underrated part of this whole architecture. Every regulation has a set of things LLMs confidently say that are wrong. Building a catalogue of these -- per regulation, per article -- is unglamorous work that pays off every time you update a model or change a prompt.
The architecture, end to end¶
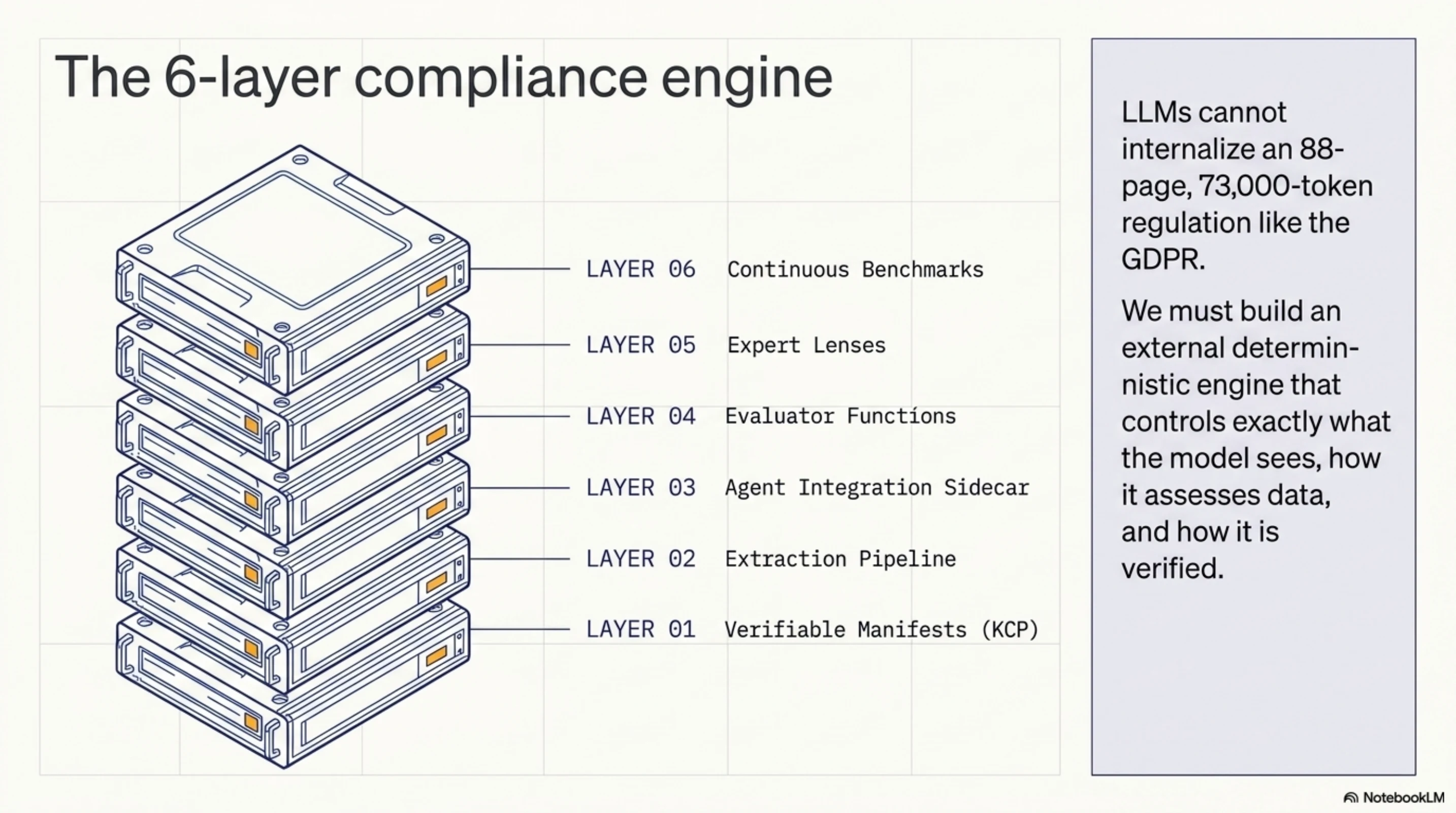
Pulling it together:
regulatory PDFs
|
fragment-extractor.py (split by Article/Chapter, token-count)
|
fragments/ (art-006.txt, art-009.txt, ...)
|
knowledge.yaml (manifest with metadata, Ed25519 signed)
|
knowledge sidecar (search_units, get_unit)
|
agent tools (search_regulatory_knowledge, get_regulatory_unit)
|
AI agent (answers from real article text, not training data)
evaluator functions (one per obligation)
|
run against real org data -> structured findings
|
benchmark tests assert findings match expected
|
expert lenses catch terminology/interpretation errors
Each layer does one thing. Fragment extraction turns regulations into agent-sized chunks. Manifests add metadata and cryptographic trust. The sidecar makes fragments available at runtime. Evaluator functions produce deterministic scores. Benchmarks catch hallucinations. Expert lenses encode judgment that can't be automated.
What this actually prevents¶
Let me be concrete about the failure modes this architecture stops.
Without authoritative knowledge: Agent tells a customer that consent suffices for processing employee health data. Wrong -- employer-employee power imbalance means consent is presumed not freely given (Recital 43, CJEU C-61/19). They need Art. 9(2)(b) employment law basis.
Without evaluator functions: Agent says "your GDPR compliance looks good" because a privacy notice exists. The evaluator shows: 3 of 7 activities lack a legal basis, no DPO despite mandatory criteria, zero DPIAs for high-risk processing. Score: 33%.
Without benchmarks: A developer changes the Art. 35 evaluator and removes the approved-DPIA check. No test catches it. The score silently becomes more lenient.
Without signing: Someone modifies the GDPR fragment to add a fictional Art. 6(1)(g) basis. Without signature verification, the sidecar serves tampered content. With it, the verification fails and the content is rejected.
Without expert lenses: The platform uses "document" throughout its compliance guidance where the regulation requires "demonstrate" -- a legally stronger evidentiary standard. The lens catches every instance.
The layer the architecture diagram doesn't show: audit logging¶
There's one thing the 6-layer stack doesn't make explicit, and regulators will ask about it directly: can you prove what the agent said, to whom, and which version of the law it was reading when it said it?
This is not the same as application logging. Compliance audit logs need to capture:
interface ComplianceAgentAuditEntry {
timestamp: string; // ISO 8601
requestId: string; // correlates to user session
orgId: string; // which customer/org received the advice
query: string; // what the user asked
unitsLoaded: string[]; // which KCP unit IDs were fetched (e.g. ["gdpr-art-006", "gdpr-art-009"])
unitVersions: Record<string, string>; // unit ID → content hash at time of fetch
response: string; // what the agent said
evaluatorSnapshot?: Record<string, number>; // obligation key → score at time of interaction
}
The unitVersions field is where the cryptographic signing from Layer 1 pays off at audit time. You don't just log that the agent read Article 6 -- you log which signed version it read, verifiable against the manifest hash. If the regulation text was later updated and re-signed, you can trace exactly which version informed which advice.
This matters in two scenarios:
Regulatory audit: A supervisory authority asks what advice your platform gave customer X on date Y regarding their legal basis for processing. You can show: the question, the exact article text the agent read (by hash), the answer, and the evaluator score at that moment.
Version rollback debugging: A regulation gets re-extracted after a correction. You need to know which customer interactions were affected by the old version. The unitVersions log makes this a query, not a manual investigation.
The logging itself is simple. The discipline of actually capturing unitsLoaded and unitVersions on every agent interaction is what most teams skip -- until they need it.
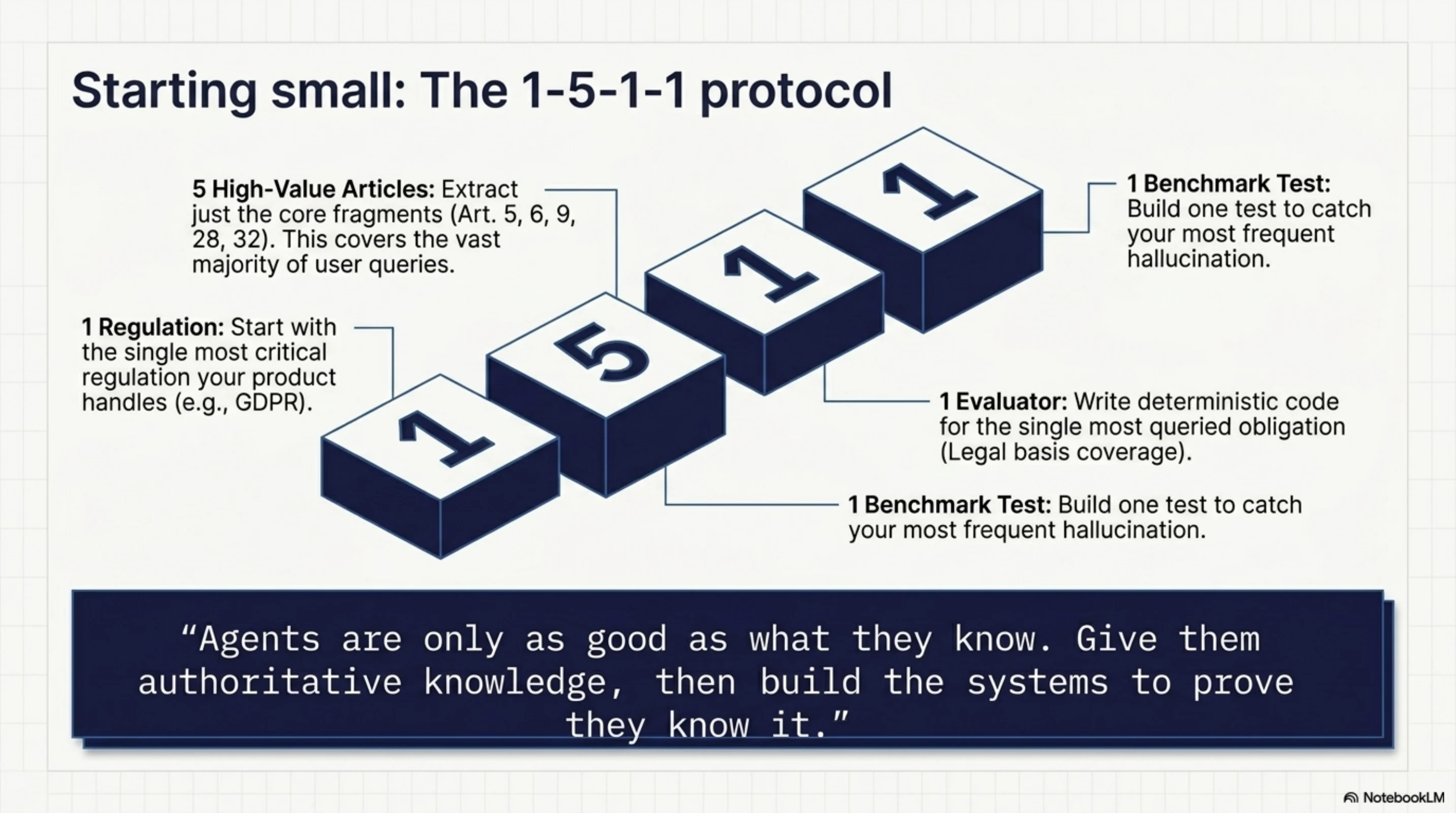
Starting small¶
You don't need hundreds of evaluator functions and a hundred knowledge units to start. You need:
- One regulation your product actually needs to handle (probably GDPR)
- Five high-value articles as fragments (Art. 5, 6, 9, 28, 32 cover most questions)
- One evaluator for the obligation your customers ask about most (legal basis is the safe bet)
- One benchmark test that catches your most common hallucination
Build those four things. Run them. Watch the agent's answers improve from "plausible" to "correct." Then expand.
The agents are only as good as what they know. Give them something authoritative to know. Then build the systems that prove they know it correctly.
The Knowledge Context Protocol spec is open source (Apache 2.0). This architecture runs in production at Mynder, a European compliance platform.
Slides: Deterministic Compliance Architecture (PDF) — 13-slide deck covering the full 6-layer architecture, produced with NotebookLM.