The Zombie in the Basement¶
A company spent three years planning an ERP migration. Their architecture catalog was clean, tidy, and fully documented. It was also seventeen connections short of the truth — before they even opened the deployment config.
The case study is fictional, but the pattern is not. Betonix GmbH had done their homework. Three years of planning. An 18-month migration timeline. An architecture catalog documenting 23 direct database connections to the legacy ERP. The kind of preparation that earns project confidence and budget approval.
Then someone ran the actual codebase through an AI agent.
The first discrepancy¶
The catalog said 23 connections. The source code had 40.
The extra 17 weren't exotic. They were inline SQL buried in application logic, committed years ago with messages like "Temp fix." Every development team has them. They accumulate in the space between "I'll document this later" and "later never comes." The catalog wasn't wrong — it documented what architects knew at the point it was written. But the codebase had kept moving.
This is what I'd call the documentation gradient: what the catalog says, what the code does, and what the runtime actually runs. In most systems, all three are different numbers.
The zombie in the basement¶
The more interesting find was DataBridgeRetail.
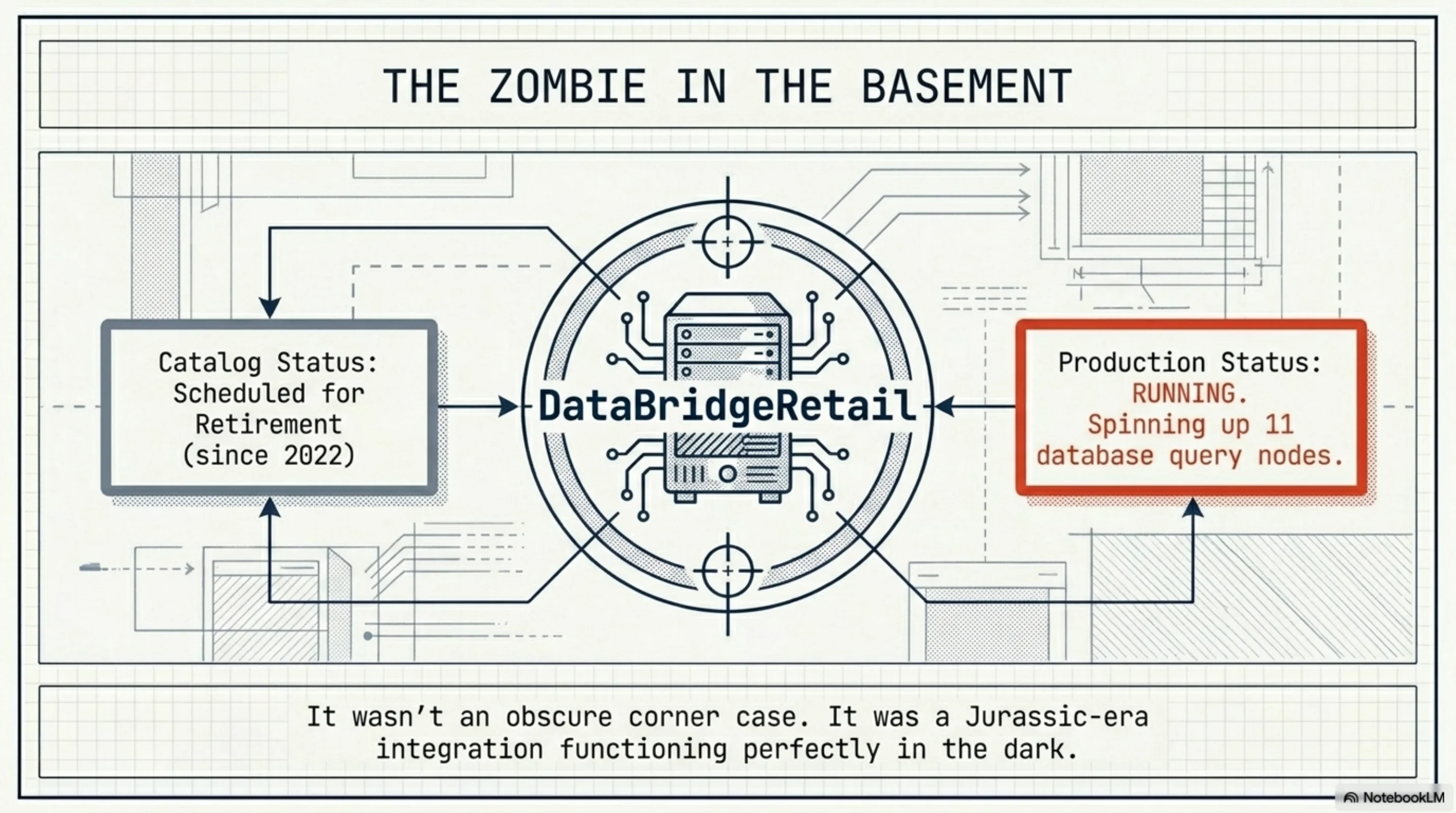
Catalog status: Scheduled for retirement (since 2022). The team knew about it. It was on the decommission list. Box ticked, decision made, forgotten.
Production status: Running. Spinning up 11 database nodes. Actively serving requests.
Nobody had decommissioned it because nobody wanted to own the blast radius. So it sat in the basement for four years — scheduled for death but very much alive. A Jurassic-era integration functioning perfectly in the dark.
The catalog's version of the system didn't really contain it, except as a footnote. The production system had it at the center of a dependency chain that ended at the live pricing feed that populated sales quotes.
![The Blast Radius of Unmapped Dependencies — Legacy ERP → DataBridgeRetail [11 connections, crossed out] → Live Pricing Feed [SILENT VOID] → Sales Quotes. No alerts. Unmapped dependencies fail quietly.](/assets/images/blog/architectural-x-ray/slide-06.webp)
No alerts. No budgeted error handling. Just silence, until the day someone migrated the legacy ERP and sales discovered that all their quotes were wrong.
The physics of large systems¶
The architects weren't incompetent. They worked from documented information, which is what architects are supposed to do. The problem is structural.
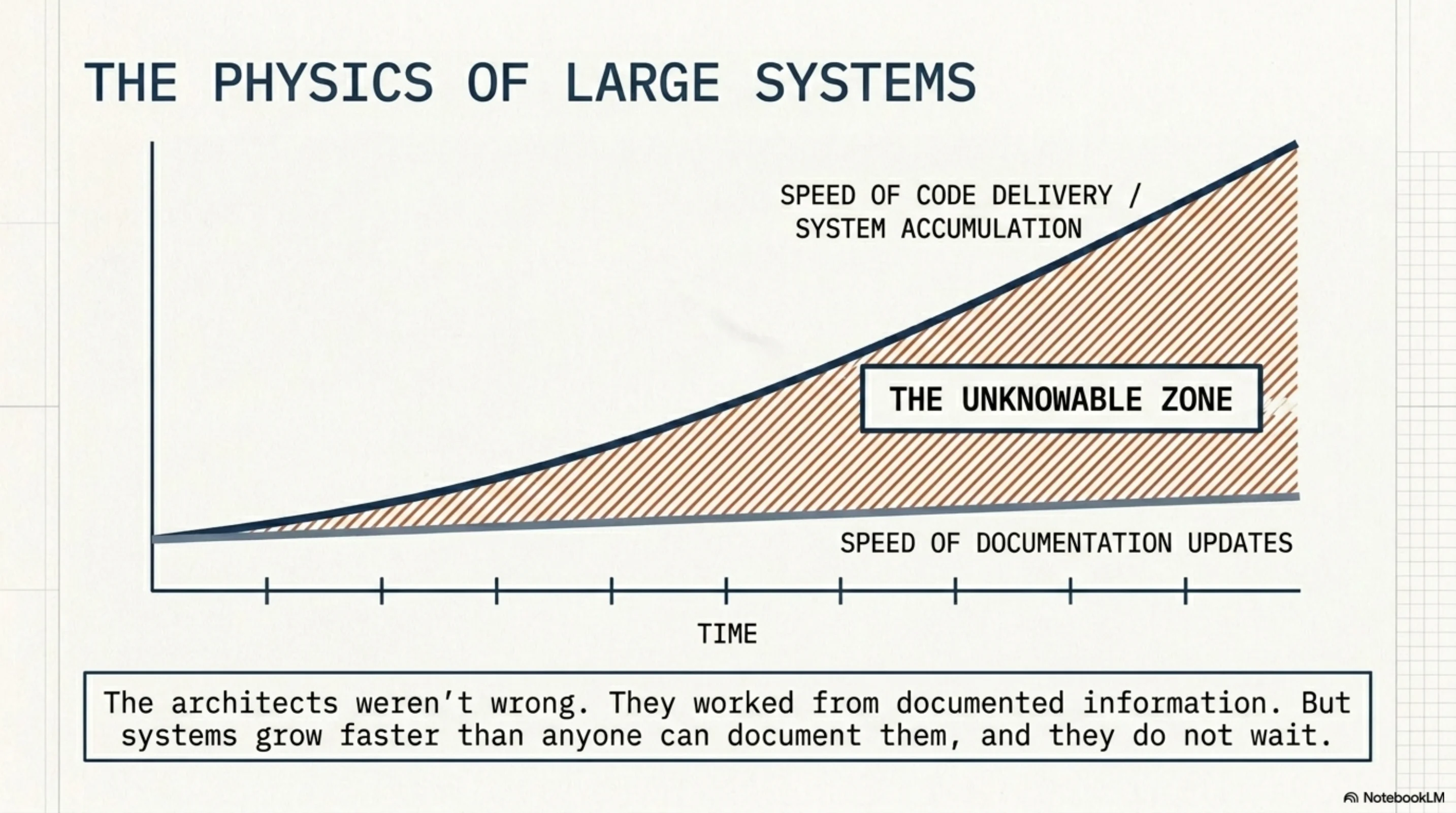
Systems accumulate faster than documentation gets updated. There's a gap between the speed of code delivery and the speed of documentation updates, and that gap only widens over time. The catalog is always behind — not occasionally, not in edge cases, but always, in every system that has been in production for more than a year.
What AI brings to this problem isn't speed. It's something more specific: relentless, sustained throughput across extremely boring surface area. A human architect loses the will to cross-reference around connection #34. They fatigue at the 900th XML binding file. The agent doesn't. It processes connection #34 the same way it processed connection #1, and it keeps going.
That's not a capability difference. It's a character difference. AI isn't better at understanding architecture. It's better at reading 62 runtime configuration files without abandoning the naming convention map halfway through.
In this case, those 62 config files were the third layer — runtime deployment overrides that added another 7 to 12 connections nobody had counted. Final tally: 23 in the catalog, 40 in source, 47 to 52 in production reality. The system was more than double its documented footprint.
From the count to the graph¶
Here's where the analysis has to stop being arithmetic and start being architecture.
Knowing you have 52 connections instead of 23 is useful information. But it doesn't tell you what happens if you migrate the legacy ERP on March 14th. It doesn't tell you which services fail silently rather than alerting. It doesn't tell you that DataBridgeRetail feeds a live pricing feed that populates a quote generation service your sales team uses in real time.
The question isn't what do we have. The question is what breaks if we touch it in the wrong order.
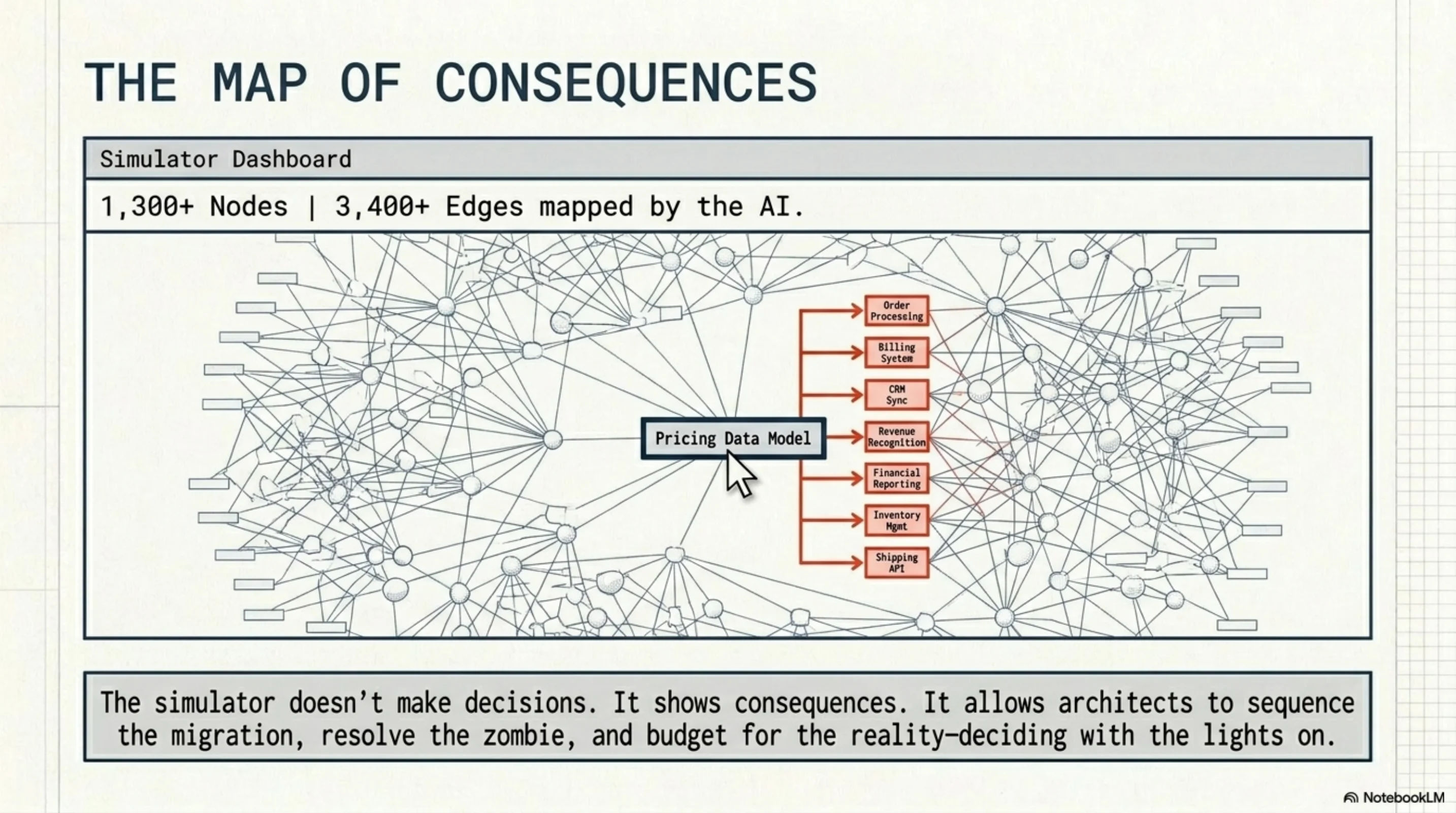
The answer to that question is a graph. 1,300+ nodes. 3,400+ edges. The pricing data model at the center, connected to order processing, billing, CRM, revenue reporting, financial reporting, inventory, and shipping — each with their own dependency chains reaching back through systems the catalog had forgotten to mention.
A simulator built from that graph doesn't make decisions. It shows consequences. It lets architects sequence the migration correctly, resolve the zombie first, and budget for the actual system — deciding with the lights on instead of hoping the documentation was complete.
What the catalog is¶
The line that stuck: "The catalog is the source of truth, right up until someone reads the code."
Architecture catalogs aren't lies. They're snapshots. They document a system as understood at a point in time, maintained by people who also have other jobs, subject to the same entropy as every other artifact in a software organization.
The mistake is treating a snapshot as a live feed. The migration risk isn't that the architects were wrong. It's that they were working from a document whose accuracy nobody had verified against production since 2022.
The difference between a migration that succeeds and one that fails is usually not the big things — the major services, the obvious integrations, the flagged dependencies. It's the seven integrations downstream of the zombie nobody decommissioned.
Verify the basement before you touch anything.