Google's Open Knowledge Format and the problems it deliberately doesn't solve¶
On June 12, 2026, Google Cloud published the Open Knowledge Format (OKF). I read it the same day. My first reaction was: this is good news. My second reaction was: they stopped exactly where it gets hard.
Both reactions were correct.
OKF is an honest piece of work. Sam McVeety and Amir Hormati at Google Cloud built something genuinely useful, documented it cleanly, and shipped reference implementations alongside the spec. They wrote the spec so it fits on one page. They made the format human-readable, git-friendly, and trivially adoptable. They were transparent about what the spec doesn't address. I respect all of that.
I also work on a protocol called KCP — Knowledge Context Protocol — that has been running in production for several months, across regulatory corpora and codebases, used by AI agents at client sites. When I read OKF, I recognized the same problem space. I also saw clearly where the paths diverge. This post is an attempt to be precise about both.
What OKF actually is¶
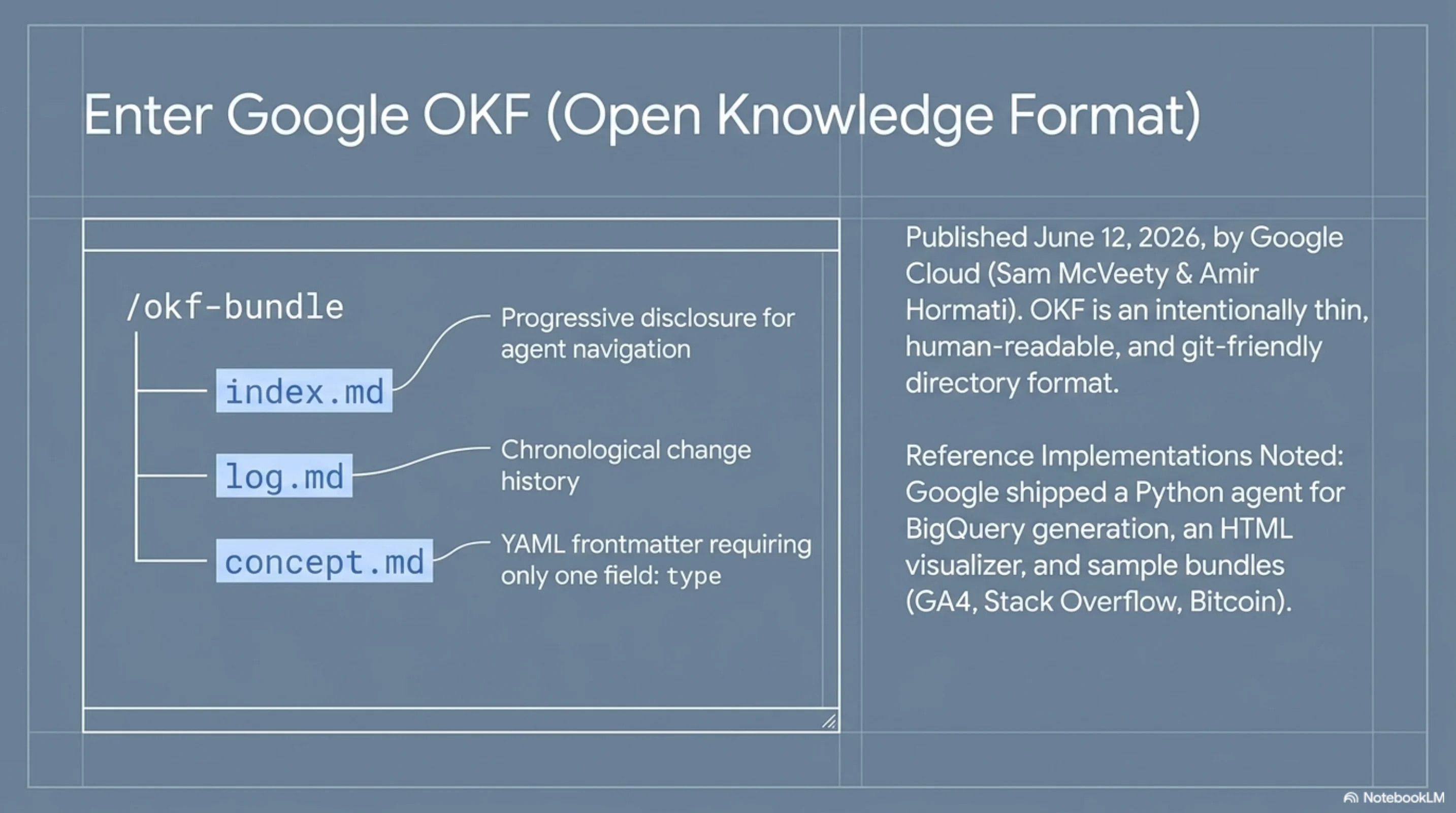
OKF is a directory format. Every non-reserved Markdown file in the directory is a knowledge document. Each document has YAML frontmatter with one required field: type. That's the spec. Everything else is optional metadata and convention.
---
type: "BigQuery Table"
title: "events"
description: "Aggregated user events for analytics"
resource: "bigquery://my-project/dataset/events"
tags: ["analytics", "events"]
timestamp: "2026-06-12T14:30:00Z"
---
# events
The main events table for the analytics pipeline.
## Schema
...
Two reserved files manage the directory: index.md as an entry point (progressive disclosure for agents starting navigation), and log.md as a chronological change history.
Relationships between concepts are expressed as standard Markdown links. There's no typed relationship vocabulary — the semantics live in the surrounding prose.
Google shipped three things alongside the spec: a Python agent that generates OKF docs from BigQuery datasets, a static HTML visualizer, and sample bundles for GA4, Stack Overflow, and Bitcoin public datasets.
The explicitly named open problems in OKF v0.1: handling contradictions and staleness, verification and trust, and access control. These are flagged as "future work."
The convergence moment¶
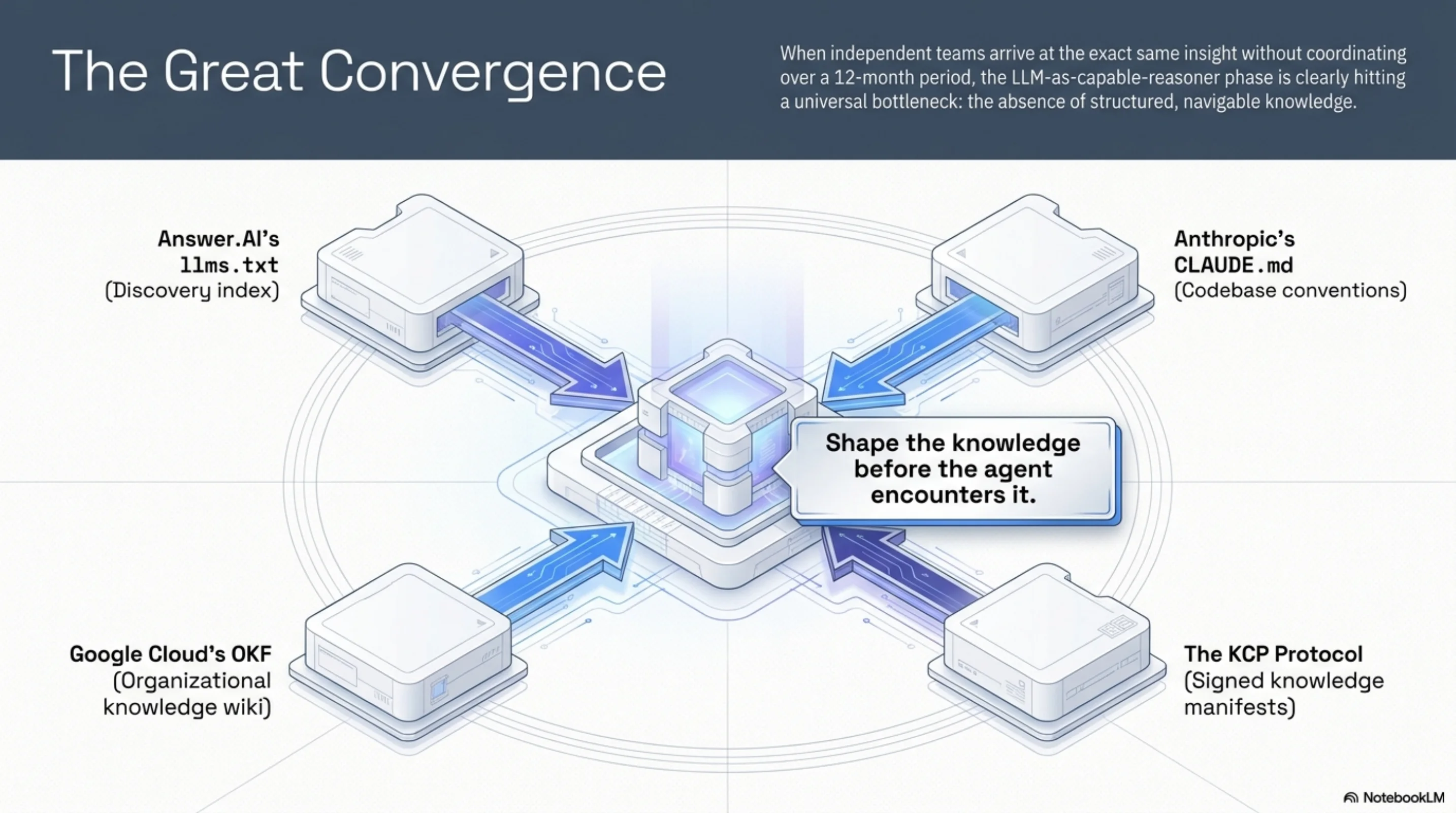
OKF is not happening in isolation. Several independent efforts have arrived at the same insight from different directions in the last twelve months:
- llms.txt (Answer.AI / Jeremy Howard): a convention for placing a machine-readable index at
/.well-known/llms.txtso AI agents know what a site contains. Text file, no schema, pure discovery. - CLAUDE.md / AGENTS.md: Anthropic's pattern of placing context files in repositories and home directories so AI coding assistants understand codebase conventions before they start working.
- OKF: Google Cloud's wiki-format approach to packaging organizational knowledge (schemas, runbooks, metric definitions) for agent consumption.
- KCP: Knowledge Context Protocol, the format I've been building since early 2025 — YAML manifests, signed, with temporal validity fields, fragment-based addressing, token budget hints, and governance metadata.
All four are saying the same thing: AI agents need structured, navigable knowledge, and the absence of that structure is a significant bottleneck. None of them are primarily saying "use RAG" or "use vector search." They're all saying: shape the knowledge before the agent encounters it.
That's a real convergence. When multiple independent teams arrive at the same insight without coordinating, the insight is probably correct.
Two different layers of the same problem¶
The convergence is real. But the efforts are operating at different layers of the problem, and conflating them would be a mistake.
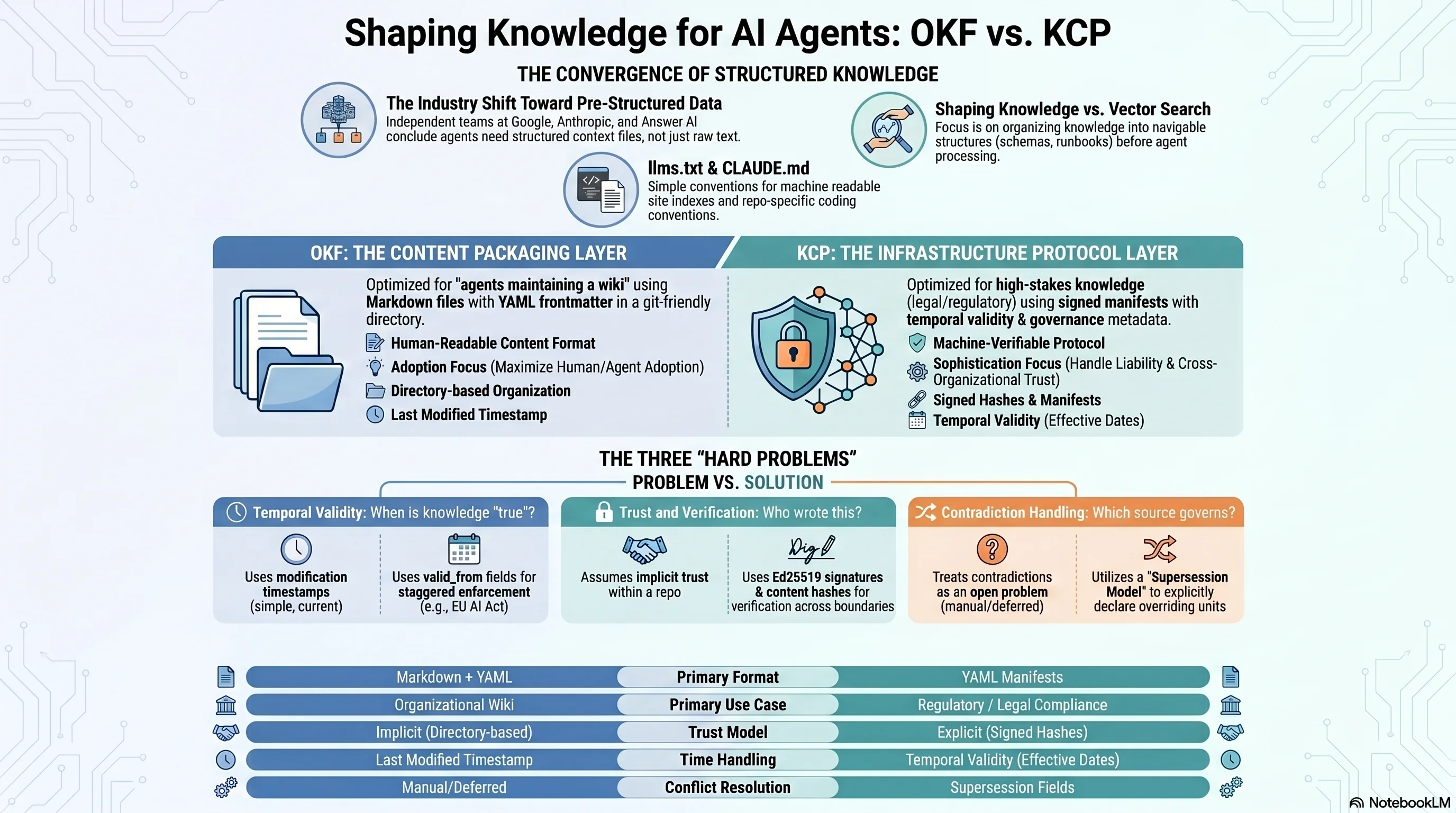
OKF is a content format. It answers: how do I package knowledge so that an agent (or a human) can navigate a corpus of organizational documentation? The unit of packaging is a Markdown file with typed metadata. The distribution mechanism is a git repository or directory. The agent reads OKF files the same way it reads any Markdown — naturally, without special tooling.
KCP is a knowledge infrastructure protocol. It answers: how do I make knowledge navigable, verifiable, temporally valid, and governable for autonomous agents operating across organizational and regulatory boundaries? The unit of packaging is a knowledge unit with addressable ID, content hash, intent metadata, audience targeting, and governance fields. The distribution mechanism is a signed manifest that can be federated across organizations.
The difference is not about sophistication or completeness. It's about the problem being solved.
OKF is optimized for the "agents maintain a wiki" use case. An agent explores a BigQuery dataset and generates documentation. Another agent reads that documentation later. The knowledge is organizational, relatively stable, and owned by a single organization. Human-readable, human-writeable, agent-readable, agent-writeable. The format is intentionally thin because adding requirements would reduce adoption.
KCP is optimized for cases where the knowledge has legal weight, comes from external authorities, changes on enforced schedules, needs to be verifiable by parties outside the originating organization, and where an agent acting on wrong knowledge creates measurable liability. Regulatory corpora. Cross-organizational trust. Compliance chains.
You could build an OKF bundle and describe it with a KCP manifest. The two can coexist at different layers of the same system.
The hard problems OKF deferred¶
OKF's three explicitly open problems are precisely where KCP has been working for months. It's worth being specific about why they're hard.
Temporal validity¶
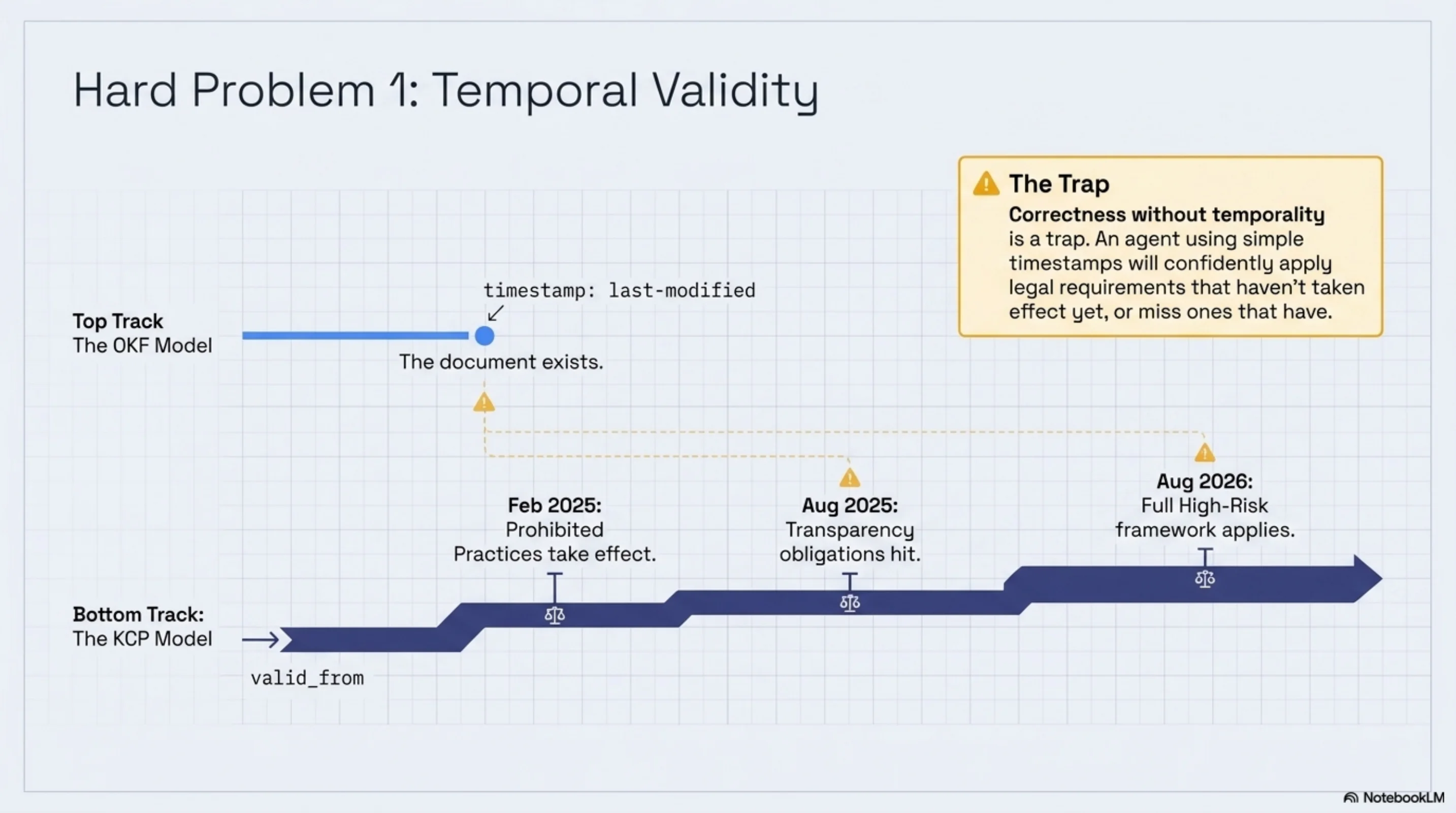
OKF has a timestamp field. It records when a document was last modified. That's a different thing from when the knowledge becomes true.
I wrote about this last week — the problem emerged concretely while building the KCP regulatory corpus. The EU AI Act was fully indexed and present in the corpus. Whether a given chapter applied right now was a different question. Prohibited practices took effect in February 2025. Transparency obligations hit in August 2025. The full high-risk framework doesn't apply until August 2026. One document, three timelines, eighteen months of staggered enforcement.
timestamp: last-modified cannot represent this. You need valid_from at the unit level, derived from enforcement dates, with the ability to ask: "given a specific date, which of these units are currently in effect?"
An agent that cannot make this distinction will confidently apply requirements that haven't taken effect yet, or miss requirements that have. The knowledge is present. The knowledge is structured. But correctness without temporality is a trap.
The broader version of this problem: API endpoints that respond until they don't. Certifications that expire. Regulations that are repealed. CVEs that are filed before patches exist. In each case, the knowledge exists at a moment in time, but its truth value is time-indexed.
OKF's timestamp records the metadata modification date. It says nothing about when the content becomes true or when it expires.
Trust and verification¶
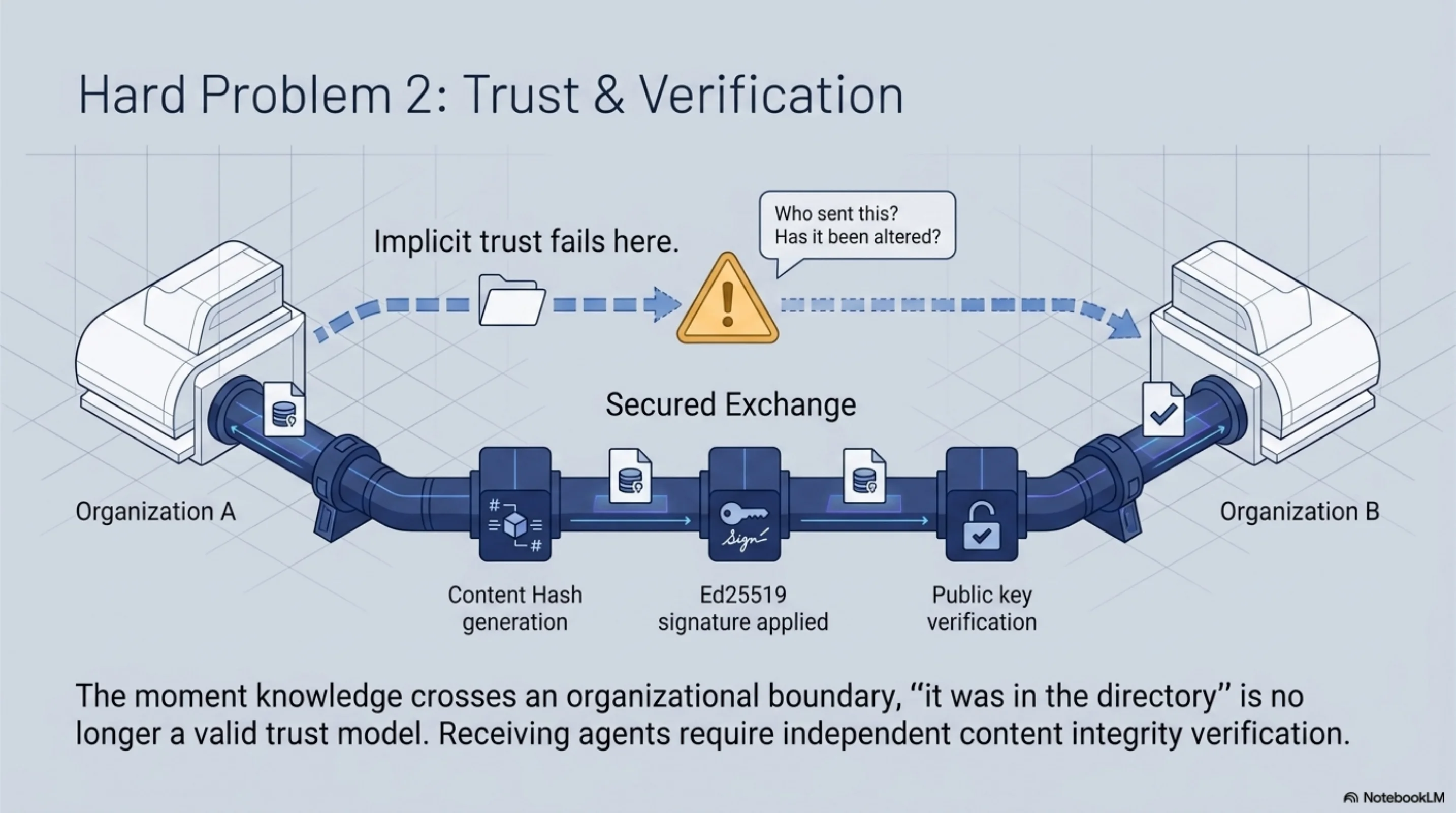
OKF has no trust model. A document is present or absent. There's no mechanism to verify who created it, whether it has been tampered with, or whether it was produced by an authorized source.
For organizational wikis maintained by a single team, this is fine. The trust is implicit — if it's in the repo, it passed through the deployment pipeline.
For knowledge that is used across organizational boundaries — a regulatory knowledge base served to multiple client agents, a supplier's trust profile presented to a customer's compliance agent — implicit trust is not sufficient. You need to be able to verify that the knowledge came from where it claims to come from and has not been modified since signing.
KCP uses Ed25519 signatures over content hashes at the unit level. Every fragment manifest is independently signed. A receiving agent can verify the signing key against a published public key and confirm content integrity before using the knowledge.
This isn't paranoia. It's a practical requirement for cross-organizational knowledge flows. The moment knowledge crosses an organizational boundary, "it was in the directory" is no longer a sufficient trust model.
Contradiction handling¶
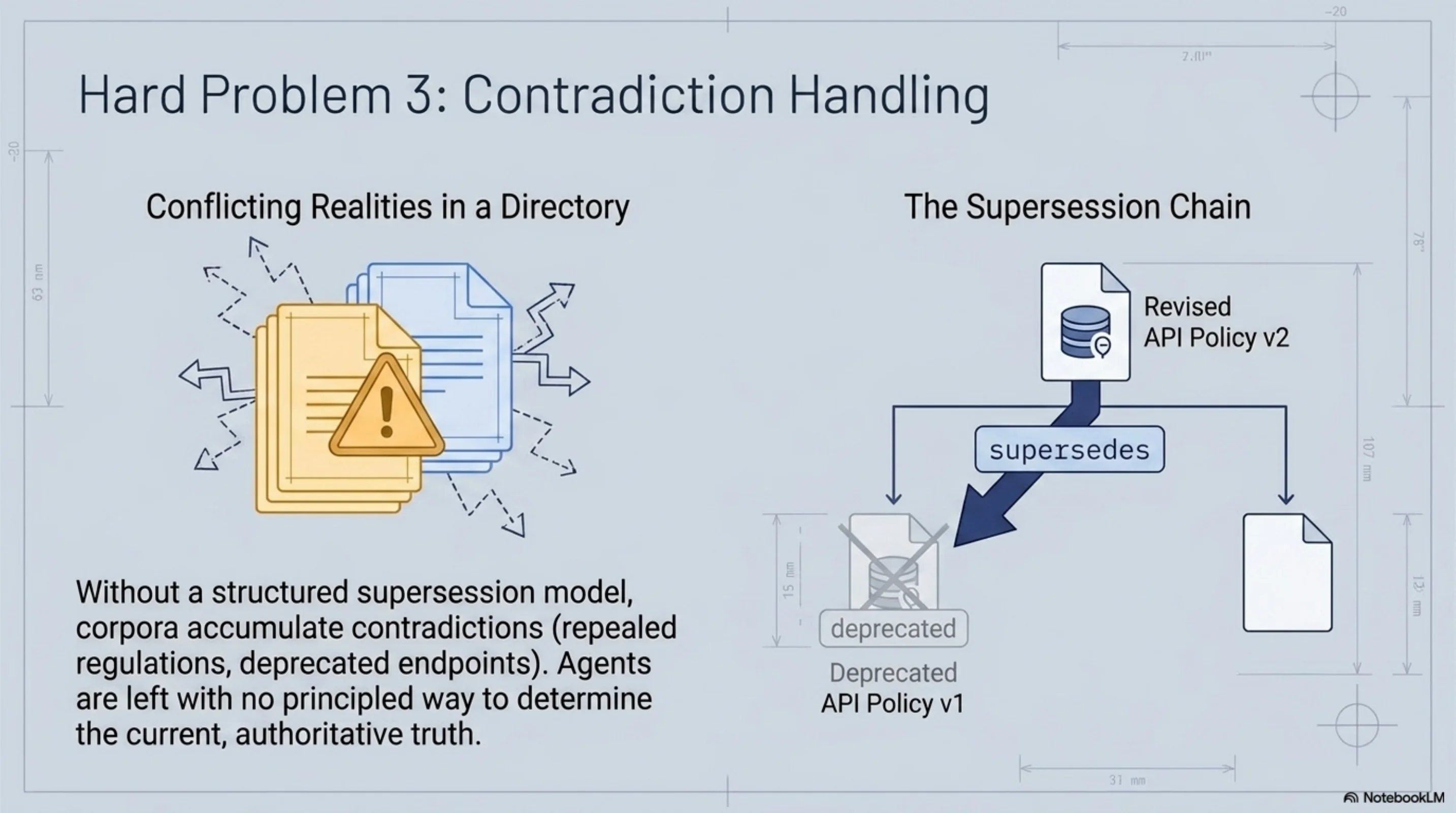
OKF v0.1 explicitly notes that handling contradictions between knowledge documents is an open problem. Two documents disagree about the same fact. Which one is authoritative? Which one is current?
In KCP, this is addressed by the supersession model. A knowledge unit can declare that it supersedes a prior unit. The manifest contains a supersedes field. Agents querying the manifest can determine the current authoritative version of a piece of knowledge without reading every document in the corpus.
This matters most when knowledge evolves. A regulatory update supersedes a prior provision. An API version deprecates an endpoint. A policy revision overrides the previous policy. Without a supersession model, the corpus accumulates contradictions that agents have no principled way to resolve.
What the convergence signals¶
The fact that multiple teams — at Google, at Anthropic, at independent practitioners — are all converging on "structured knowledge for agents" as a first-class problem tells me something important: the LLM-as-capable-reasoner phase of AI adoption is running into the knowledge infrastructure problem at scale.
The pattern I've observed: organizations deploy AI agents successfully in controlled settings. The agents are capable. The problems start when the knowledge the agents depend on is distributed across sources, has different temporal validity, comes from different authorities with different trust profiles, or needs to be shared across organizational boundaries. The agent capability is there. The knowledge infrastructure is not.
OKF is an honest attempt to solve the content packaging layer of this problem. It's a well-designed wiki format with good ergonomics. The problems it defers — temporal validity, trust, contradiction handling — are not oversights. They're hard problems that require protocol-level decisions that would increase the adoption cost. OKF made a reasonable bet: get the easy layer right and build adoption before attempting the harder layers.
That's a defensible choice. It's not the choice I made with KCP, because the use cases I was building for couldn't defer those problems. But I understand the logic.
What I find interesting is that OKF's "future work" section maps almost exactly onto KCP's feature list. That suggests the hard problems are becoming unavoidable. As organizations move from "agents reading wikis" to "agents acting on knowledge with regulatory weight," the deferred problems will need to be solved.
Where this leaves things¶
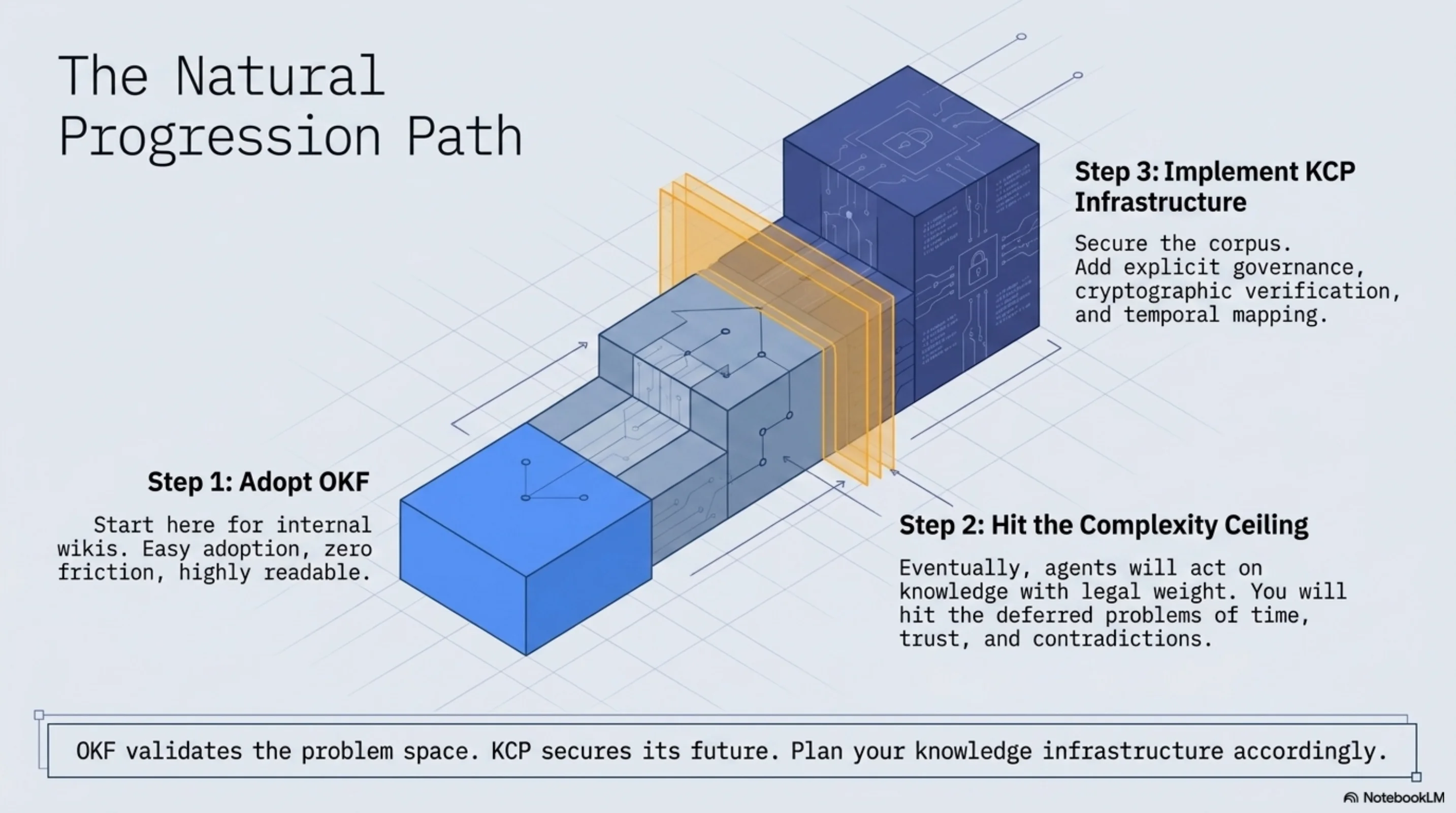
I don't see OKF as a competitor. It operates at a different layer. If anything, the existence of OKF is useful: it validates that the problem space is real, it creates a user base that will eventually run into the problems OKF deferred, and it may create a natural progression path.
An organization could start with OKF — it's easy to adopt, has Google's backing, and works well for the wiki use case. When they hit the temporal validity problem (an agent applying a regulation that hasn't taken effect yet), or the trust problem (how do we verify this knowledge bundle came from our compliance team and wasn't tampered with), or the contradiction problem (two policy documents say different things — which one governs?) — those are the problems KCP was built to solve.
The knowledge infrastructure problem has layers. OKF is a solid implementation of one of them. The layers above it are where things get hard and interesting.
The bridge is now a command¶
The progression I described above — start with OKF, hit the complexity ceiling, implement KCP infrastructure — is now mechanical.
Today I shipped kcp import-okf as part of KCP v0.21.2:
Point it at an OKF directory. It reads the frontmatter, skips the reserved files (index.md, log.md), maps OKF types to KCP kinds, turns description into a question-form intent, extracts Markdown links as depends_on references, computes sha256 content hashes for each document, and writes a knowledge.yaml manifest.
The output looks like what I showed at the start of this post — except now the scaffolding is generated, not hand-written. The # TODO markers flag every intent that needs human review, every unit that should have a valid_from date added. The review checklist is printed to the console and embedded at the top of the file.
✔ Imported 2 units from /tmp/my-okf-bundle → knowledge.yaml
⚠ 2 units have auto-generated intents — search "# TODO" and refine
ℹ 0 units have a temporal block — add valid_from if content has an enforcement date
Review checklist:
1. Search for "# TODO" and address each annotation
2. Add temporal.valid_from where content has an enforcement or effective date
3. Refine auto-generated intents into precise task-oriented questions
4. Run: kcp validate
5. Run: kcp sign --key <ed25519.pem> --key-id <id>
What it deliberately doesn't do: it doesn't backfill the three hard problems for you. It can't infer valid_from from an OKF timestamp — those are different things, as I described above. It can't synthesize a trust model from a directory of Markdown files. It can't resolve which of two conflicting OKF documents is authoritative.
What it does is eliminate the mechanical work so you can focus on the judgment work. The structure is there. The hashes are there. The depends_on graph is inferred. The temporal and signing fields are stubbed with # TODO comments so nothing gets silently skipped.
The migration path now has a first step that takes thirty seconds instead of half a day.
KCP specification and reference implementation: github.com/Cantara/knowledge-context-protocol
OKF specification: github.com/GoogleCloudPlatform/knowledge-catalog/tree/main/okf
Series: Knowledge Context Protocol
← Stale Knowledge Is Worse Than No Knowledge: KCP v0.19 and v0.20 Close the Temporal Gap · Part 33 of 50 · The Agentic Web Has No Login Page →