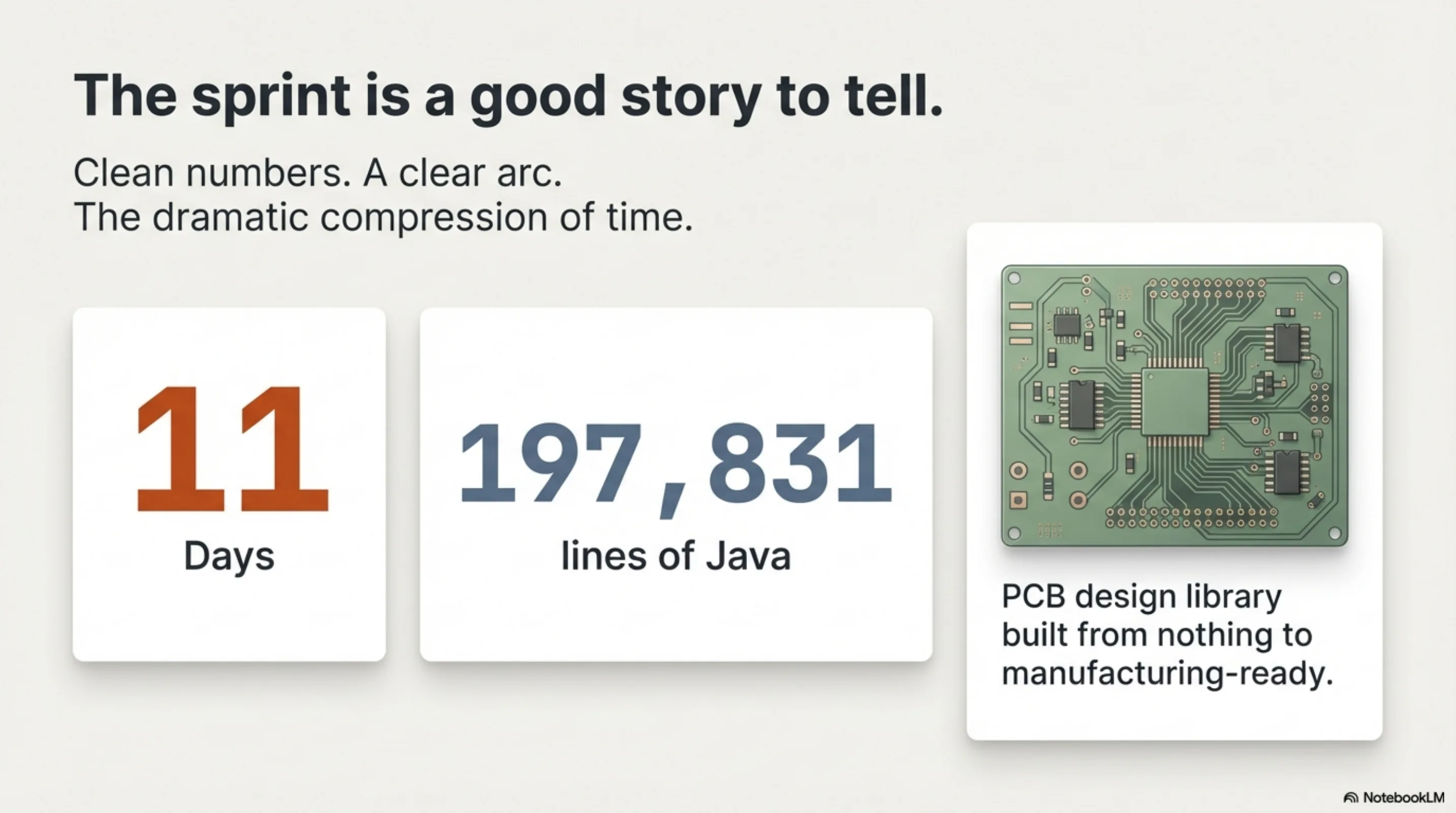
Eleven days. 197,831 lines of Java. A PCB design library built from nothing to manufacturing-ready. Clean numbers, clear arc, dramatic compression of time.
That was January 27. Six weeks ago.
Nobody asked what happened after. Which is the point.
A few days ago we prepared a roadmap for bringing KCP to GitHub Copilot users. Three phases,
estimated ten days. This is the post where I explain that we shipped all three phases today —
and then shipped a fourth: a complete zero-MCP path for enterprises that cannot run MCP servers.
Every token Claude Code's context window can hold is an opportunity — a tool call result
that stays in scope, a file that does not need to be re-read, a decision that does not
need to be recapped. Wasting those tokens on noise is a quiet tax on every session.
Today we are releasing kcp-commands: a Claude Code hook that recovers 33.7% of a
200K context window in a typical agentic coding session by intercepting Bash tool calls
at two critical points.
The full number across our benchmark session: 67,352 tokens saved.
Update (March 3, 2026 — v0.9.0): kcp-commands now writes a JSON event to
~/.kcp/events.jsonl on every Phase A Bash hook call. kcp-memory v0.4.0
ingests that stream to provide tool-level episodic memory — kcp-memory events search
"kubectl apply" returns every time Claude ran that command across all your projects.
Phase A gives Claude vocabulary. Phase B cleans output. Phase C remembers what ran.
Every session starts from zero. The agent cannot remember the decision it helped you make last Tuesday, the bug it spent three hours debugging last week, or the architectural pattern you established last month. This is not a model capability problem. It is a memory architecture problem — and it has a tractable solution.
A brief arrives on Friday afternoon. A compliance startup is building an AI-powered scoring engine. They have a working architecture. What they do not have are settled positions on five hard architectural questions. The deadline is Monday.
The question I asked myself was not "how do I answer these five questions?" It was "what knowledge infrastructure do I need to answer them well?"
That reframing is the entire methodology in one sentence.
We submitted a pull request to CrewAI adding a KCP manifest and TL;DR summary files. The goal was straightforward: contribute the same efficiency improvement that cut agent tool calls by 76% in our benchmark. Open it up, share the result, see if the maintainers want it.