Two Architectures for Claude Code: What 19,700 Stars Got Right and What They Missed
A repository called claude-code-best-practice hit #1 trending on GitHub this week. 19,700 stars in days. Eighty-four tips from Boris Cherny, who created Claude Code, along with contributions from Thariq, Cat Wu, and the broader Anthropic team. It is the most comprehensive public document on how to get serious results from Claude Code, and it deserves the attention it is getting.
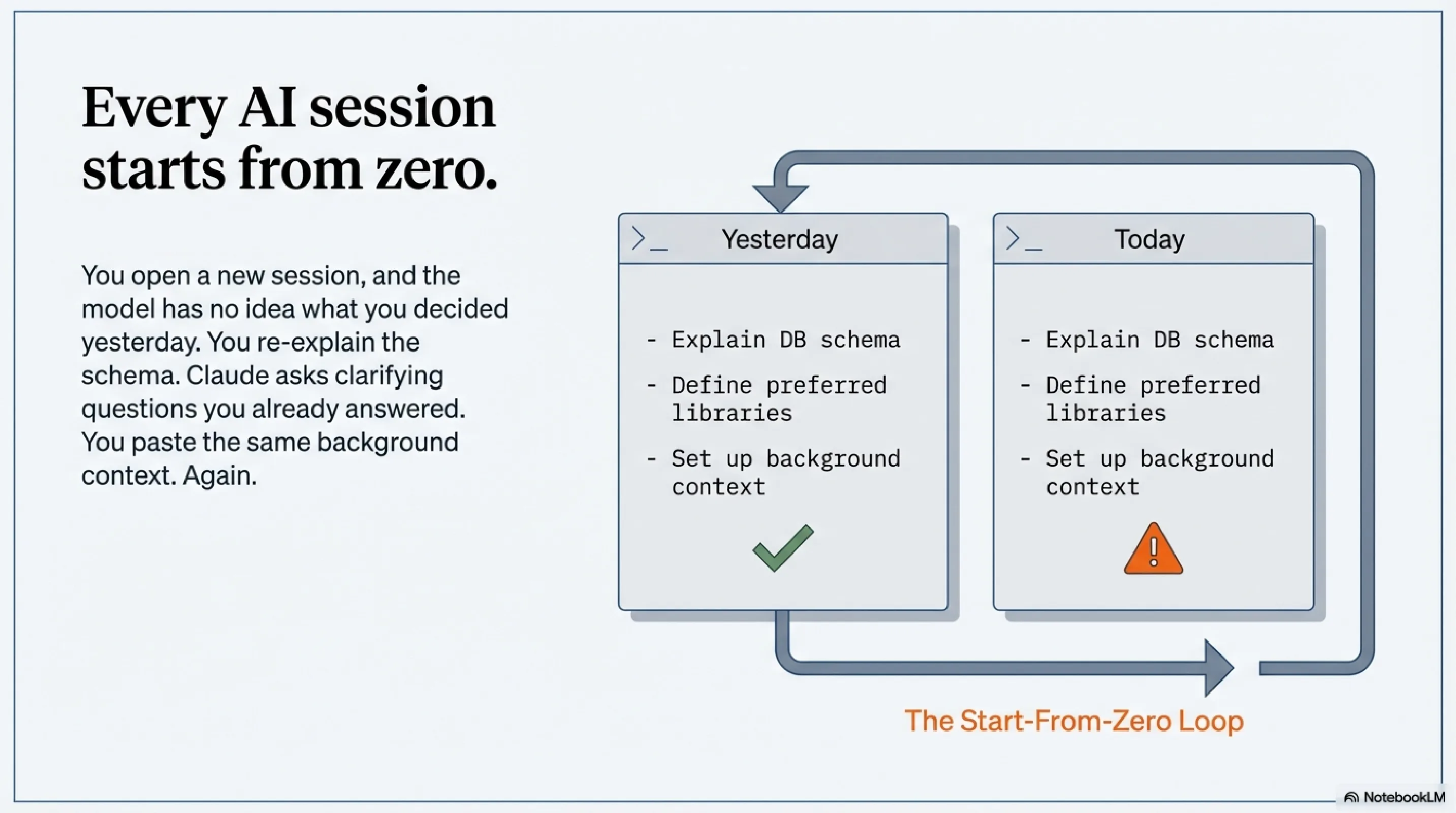
The reason it caught my eye is that the ExoCortex -- the eight-layer stack running my Claude Code setup for ten-plus weeks now -- solves many of the same problems from a fundamentally different direction. Same tool, same class of problem, different architectural assumptions. Comparing the two reveals something neither setup has articulated on its own: there are two distinct philosophies for extending Claude Code, and both have blind spots the other has solved.