Working Memory, Episodic Memory, Semantic Memory. Your Agent Has One.¶
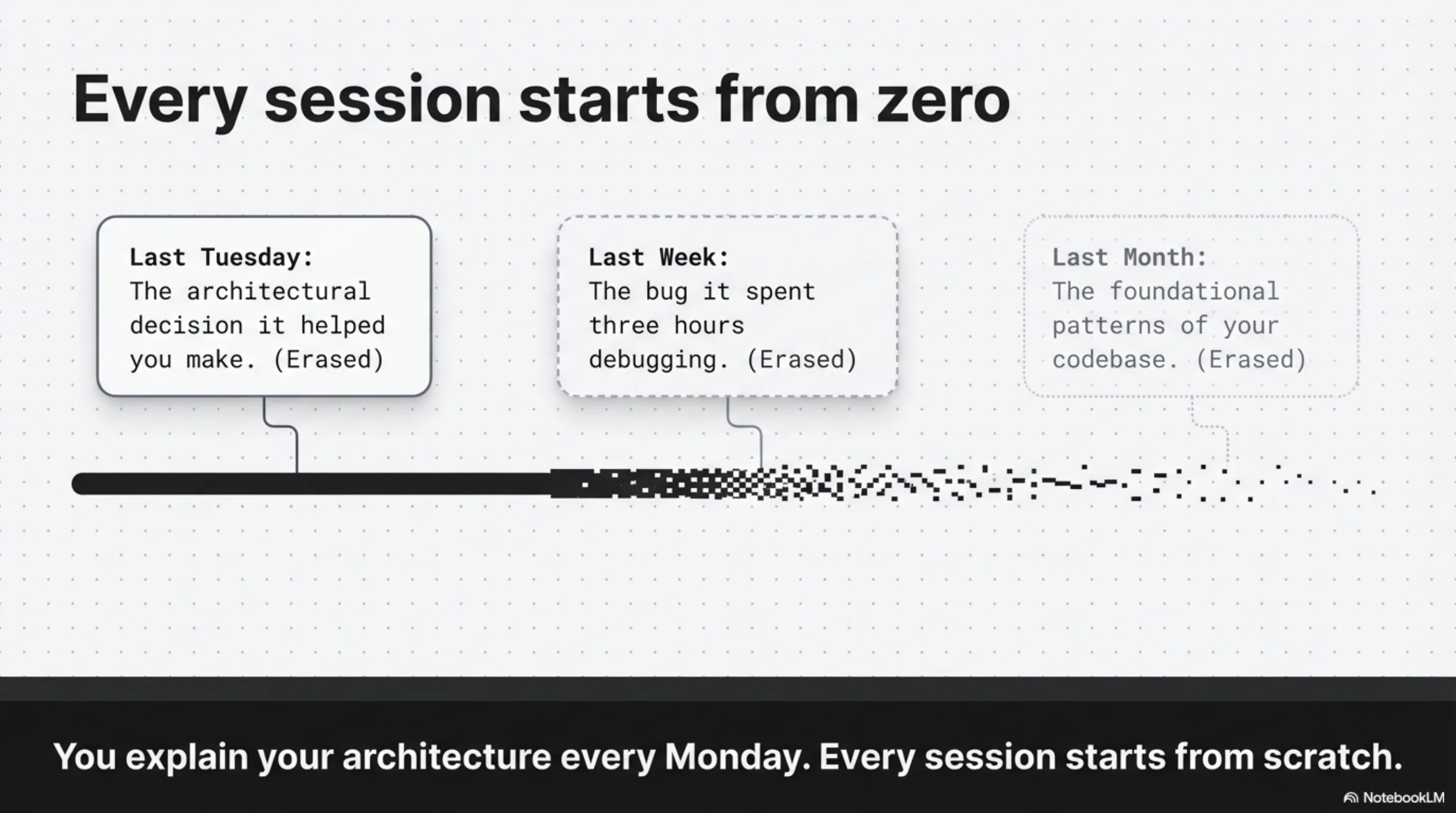
Every session starts from zero. The agent cannot remember the decision it helped you make last Tuesday, the bug it spent three hours debugging last week, or the architectural pattern you established last month. This is not a model capability problem. It is a memory architecture problem — and it has a tractable solution.

A few days ago, Jon Hammant published a LinkedIn post that got 757 reactions and triggered one of the more interesting comment threads I have seen in the AI tools space. He built a tool called Claude History MCP that indexes your Claude Code session transcripts and makes the resulting knowledge searchable — sub-200ms, no LLM required, 170 sessions in 9 seconds.
One commenter, Stefan Christoph, noted that what Jon built maps to episodic memory in human cognitive architecture. "We have working memory, episodic memory, semantic memory," he wrote. "Maybe AI agents need the same."
That observation is more precise than it might seem. It describes exactly what is missing — and it suggests a specific architecture for fixing it.
The memory problem is not what you think¶
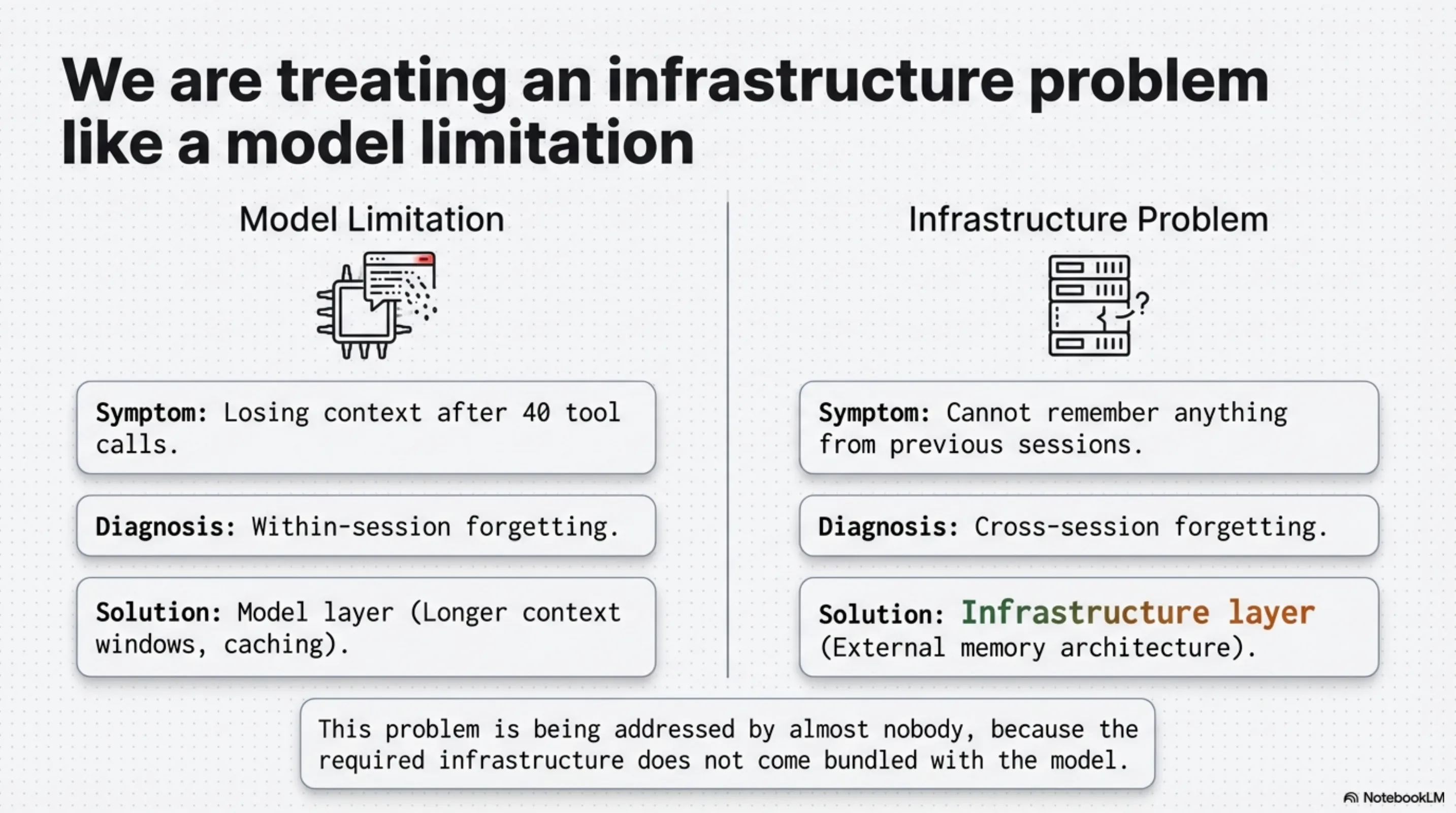
When developers complain that AI agents "don't remember things," they usually mean one of two different problems. The first is within-session forgetting — the agent loses context near the end of a long session, or struggles with something it was told about forty tool calls ago. That is a context window management problem.
The second is cross-session forgetting — the agent cannot remember anything from previous sessions. You explain your architecture every Monday. You describe the same constraint every time a related question comes up. Every session starts from scratch.
These are different problems with different solutions. The context window problem is being addressed by longer contexts, caching, and better memory management within the window. The cross-session problem is being addressed by almost nobody — because it requires infrastructure that does not come bundled with the model.
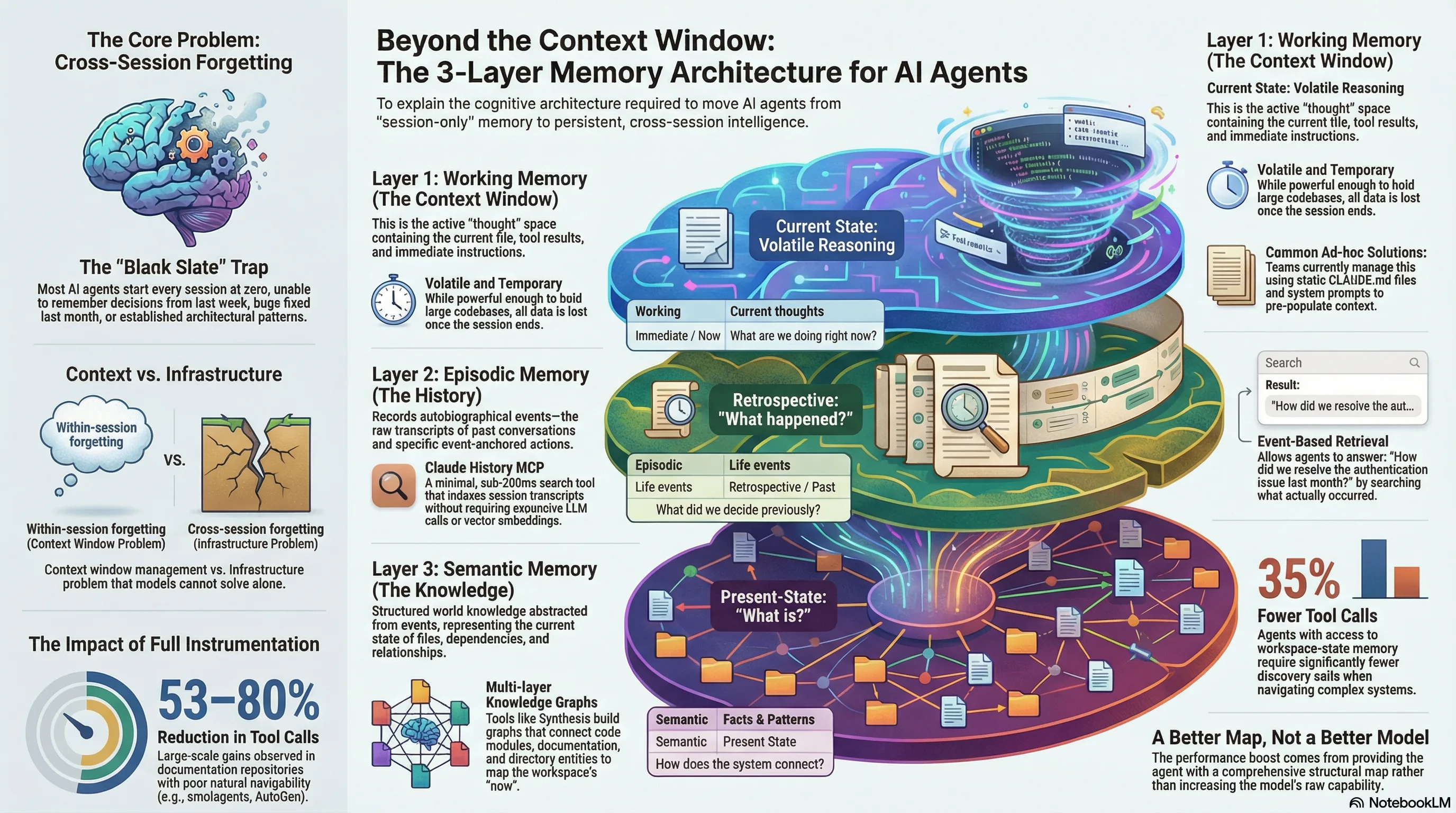
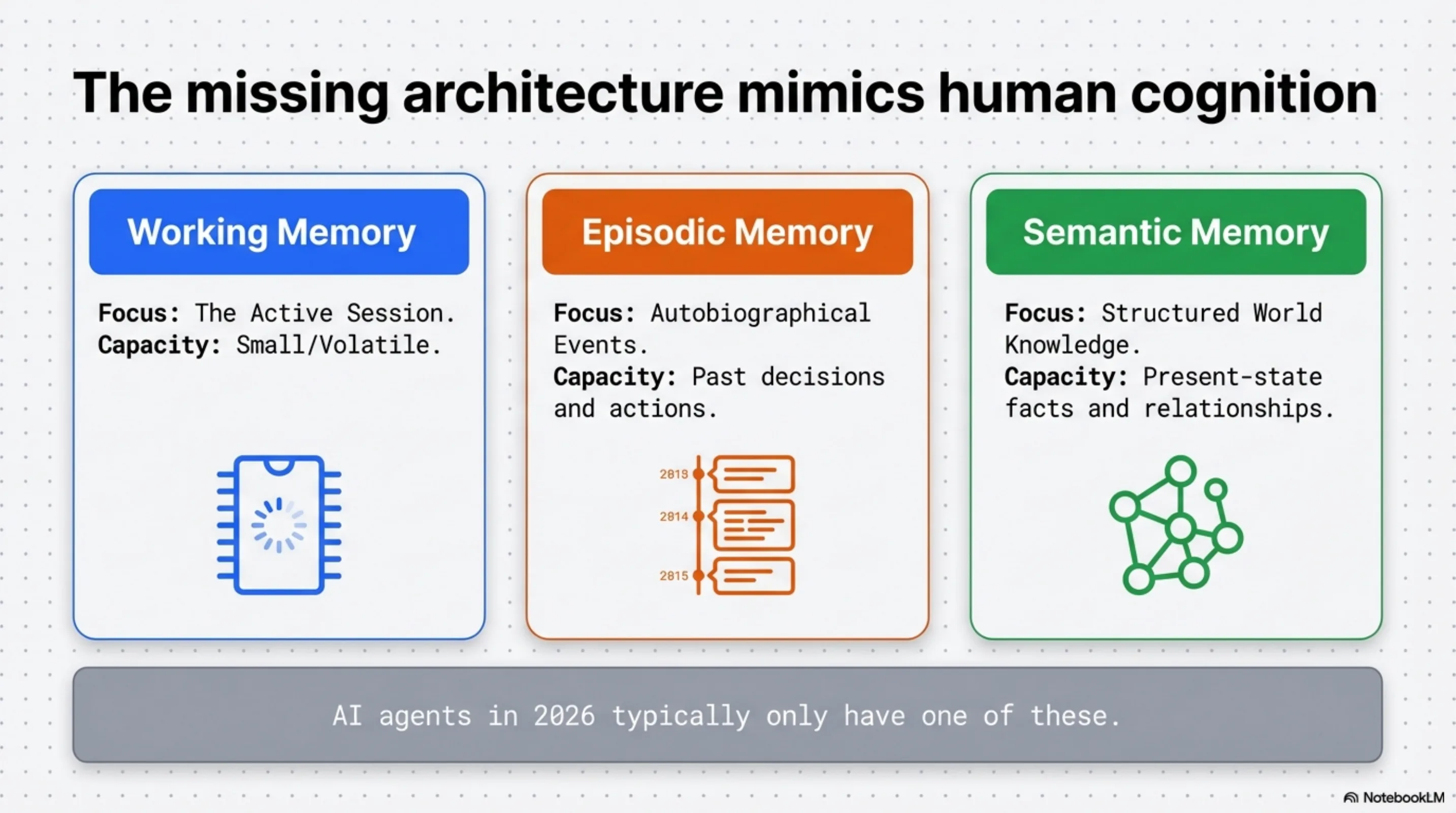
The human brain runs three memory systems in parallel. Working memory holds what you are actively thinking about right now — small capacity, fast access, volatile. Episodic memory holds autobiographical events — what happened when, who said what, what you tried and how it turned out. Semantic memory holds structured world knowledge — facts, relationships, patterns, concepts — abstracted from specific episodes and stable over time.
AI agents in 2026 typically have one of these. Working memory only. The context window. Every session starts from the blank slate — unable to remember decisions from last week, bugs fixed last month, or architectural patterns established last quarter. Call it the Blank Slate Trap.
Layer 1: Working memory (what you have)¶
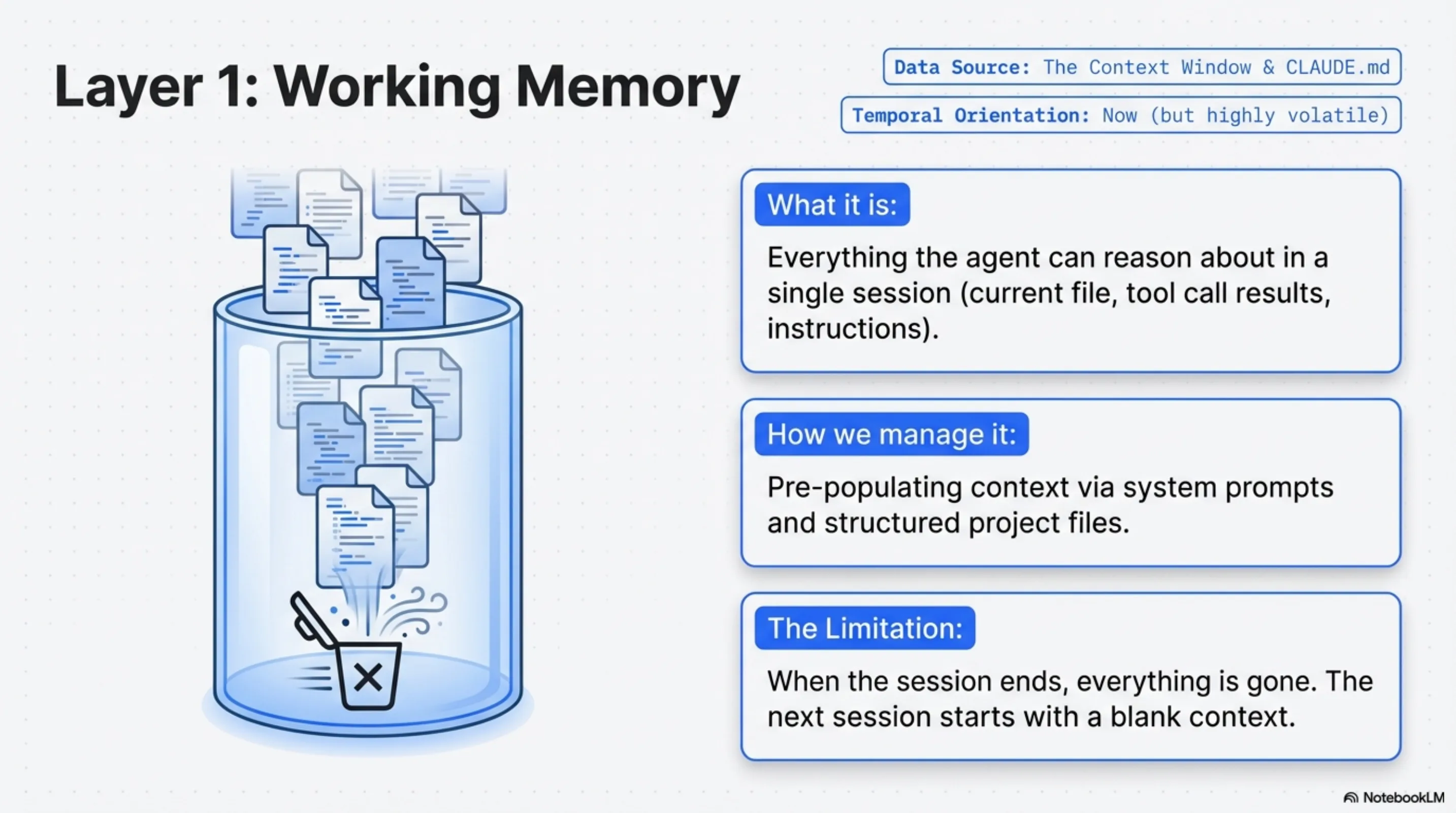
This is the context window. Everything the agent can reason about in a single session lives here: the current file, the previous tool call results, the instructions you gave at the start, the few-shot examples you included.
Working memory is powerful — modern context windows are long enough to hold substantial codebases, conversation histories, and documentation. But it is volatile. When the session ends, everything in working memory is gone. The next session starts with a blank context.
Most teams manage this with system prompts and CLAUDE.md files — structured context that loads automatically at session start. This is the common response to the Blank Slate Trap, and it is a reasonable one. But it is still working memory, pre-populated. It addresses within-session context. It does nothing for the decisions made in past sessions, or for structural knowledge about the corpus the agent needs to navigate.
Layer 2: Episodic memory — retrospective, what happened?¶
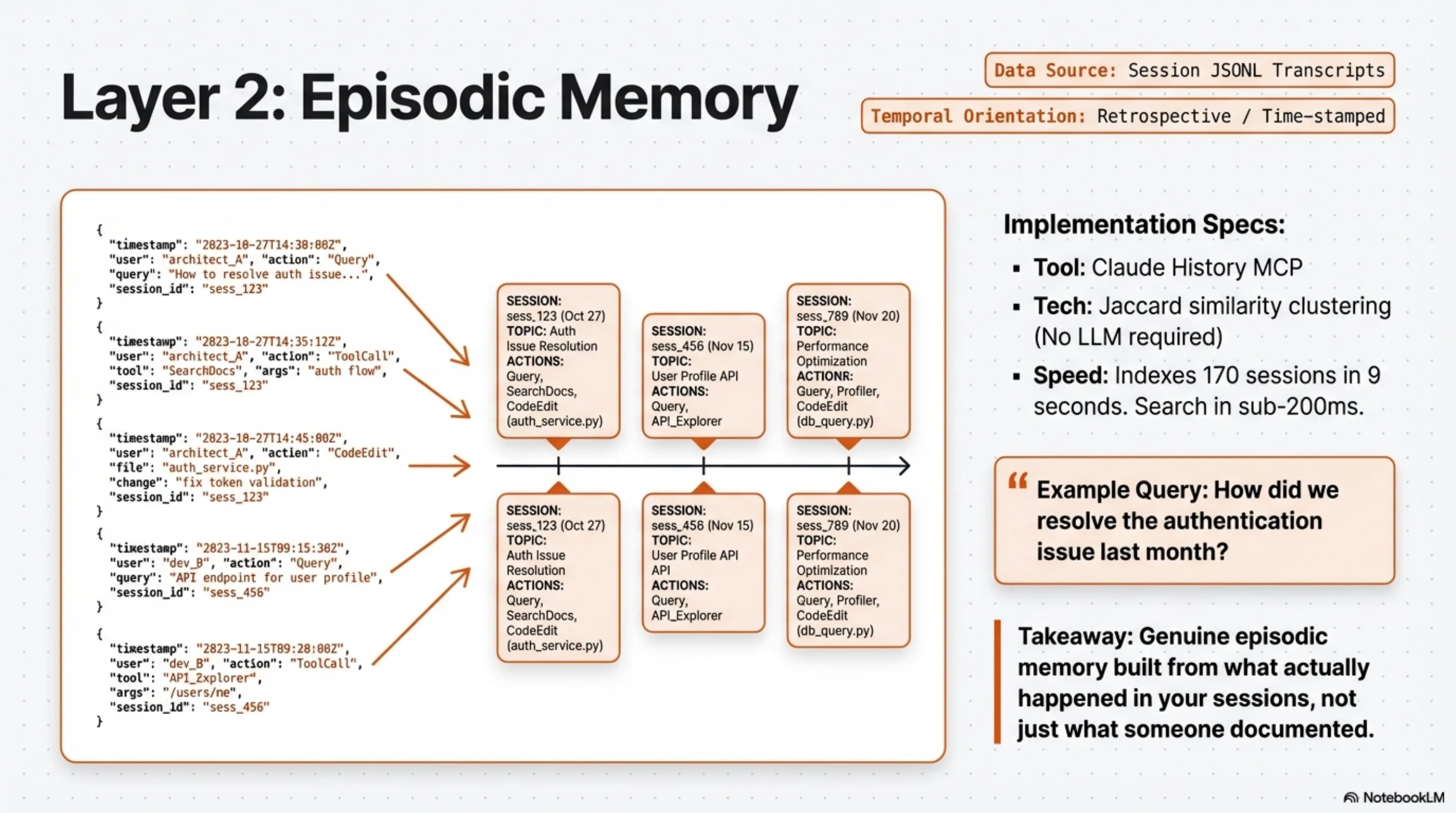
Jon Hammant's Claude History MCP addresses the episodic memory gap. It indexes your session JSONL transcripts — the raw records of every conversation you have had with Claude Code — and makes them searchable.
The implementation is interesting because it is deliberately minimal. No LLM calls. Jaccard similarity clustering on extracted learnings. 170 sessions indexed in 9 seconds. Search results in under 200ms. It is fast because it avoids the embedding pipeline and vector similarity infrastructure that most semantic search tools require.
What this gives you: the ability to find what you previously decided, what you tried that failed, what patterns emerged from past sessions. "How did we resolve the authentication issue last month?" becomes a tractable query instead of a memory exercise.
This is genuine episodic memory — time-stamped, event-anchored, retrospective. The index is built from what actually happened in your sessions, not from what someone decided to document.
The limitation is the same as episodic memory's limitation in humans: it is great for specific past events, less useful for answering structural questions about your current system. "What did we decide about authentication?" is episodic. "What does the authentication module depend on right now?" is semantic.
Update (March 3, 2026): Synthesis v1.21.0 ships native session indexing via synthesis sessions. The same tool that covers Layer 3 now covers Layer 2 without requiring a second MCP server. Sessions are scanned incrementally from ~/.claude/projects/, stored in SQLite with FTS5 full-text search, and exposed through both the CLI (synthesis sessions search "authentication") and the sessions MCP tool. The first scan indexed 2,971 sessions in 109 seconds; subsequent scans are near-instant. Claude History MCP remains a strong option — its Jaccard similarity clustering extracts learnings at a different granularity — but if you are already running Synthesis, Layer 2 is now one command away.
Also released today: kcp-memory — a standalone open-source Java daemon that covers Layer 2 without requiring Synthesis. If you use Claude Code but not Synthesis, kcp-memory gives you episodic memory as a single install: curl -fsSL https://raw.githubusercontent.com/Cantara/kcp-memory/main/bin/install.sh | bash. It indexes ~/.claude/projects/**/*.jsonl into SQLite with FTS5, runs on port 7735, and exposes a kcp-memory search CLI and a PostToolUse hook for near-real-time indexing. Part of the KCP ecosystem alongside kcp-commands (port 7734).
Same day — kcp-memory v0.2.0: The episodic layer now has two resolutions. Session-level ("what was I working on last week?") has been there since v0.1.0. v0.2.0 adds tool-level granularity: kcp-commands v0.9.0 writes every Bash tool call to ~/.kcp/events.jsonl; kcp-memory ingests that stream and makes individual commands searchable via kcp-memory events search "kubectl apply". The distinction matters: session-level memory answers which work session touched a problem; tool-level memory answers which exact commands Claude ran across all projects. Both are retrospective and event-anchored — the same episodic layer, at two different resolutions.
Same day — kcp-memory v0.3.0: The episodic layer is now queryable from within a session. kcp-memory ships an MCP stdio server: register java -jar ~/.kcp/kcp-memory-daemon.jar mcp in ~/.claude/settings.json under mcpServers, and Claude can call kcp_memory_search, kcp_memory_events_search, kcp_memory_list, and kcp_memory_stats inline — without you having to manually surface context. The loop closes: Claude runs → kcp-memory indexes → Claude queries its own past in the next session.
Same day — kcp-memory v0.4.0: Two more MCP tools address the remaining gaps. kcp_memory_session_detail(session_id) completes the find → read flow: once search returns a session, Claude can read its full content — all user messages, every file touched, tools used. kcp_memory_project_context() flips the episodic layer from pull to push: it reads PWD from the process environment, requires no query, and returns the last 5 sessions and 20 tool events for the current project. Called at session start, it means Claude arrives knowing what it was doing here — not because you told it, but because the infrastructure did.
Layer 3: Semantic memory — present-state, what is?¶
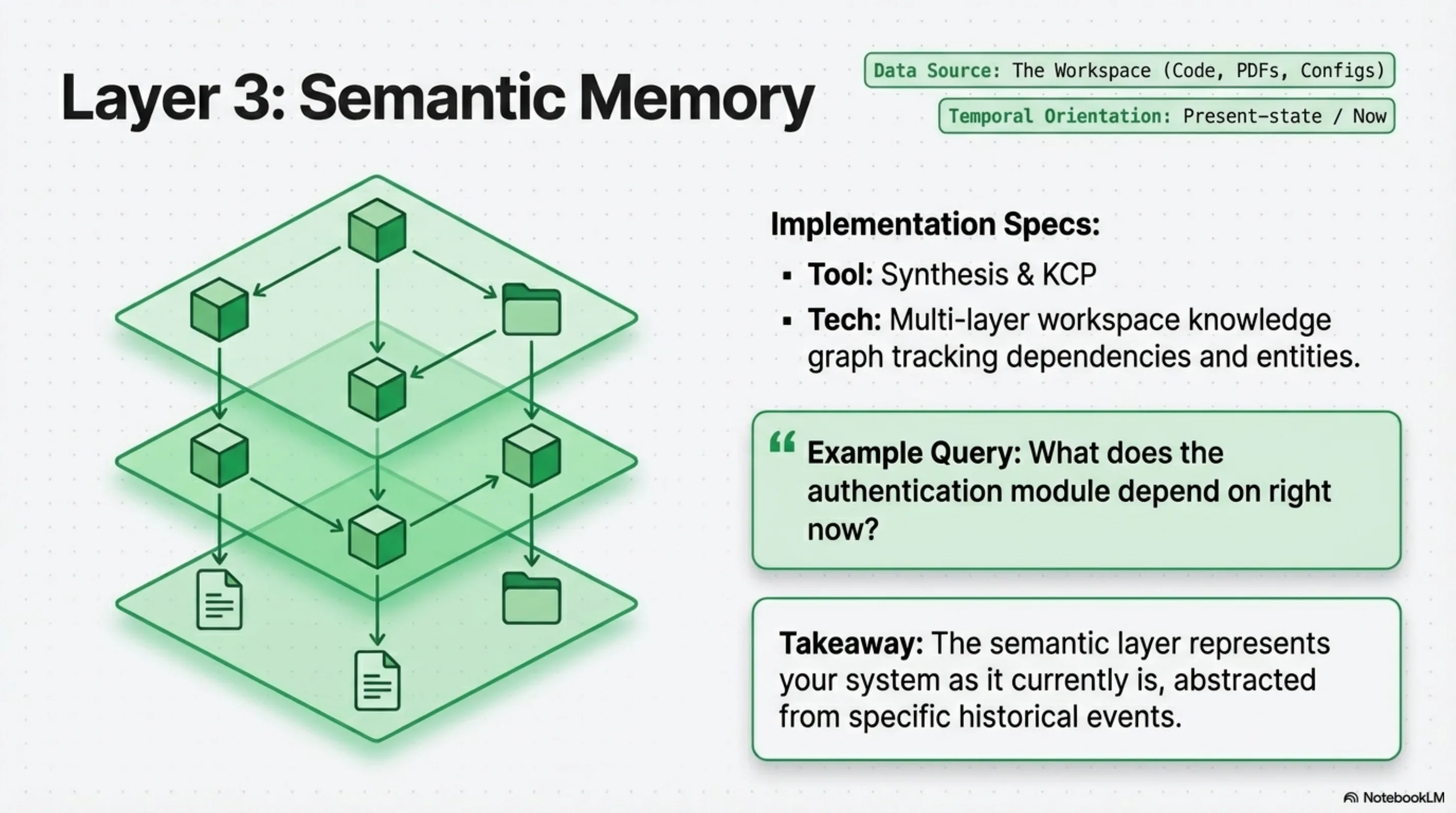
Semantic memory is structured world knowledge — abstracted from specific events, stable across time, relational. For an AI agent, this means: what content exists in the corpus it needs to reason over, how the pieces connect, what has changed and when.
Crucially, the corpus does not have to be source code. It can be a documentation repository, a regulatory framework, a domain knowledge base, or a collection of standards and guidelines. The pattern is the same regardless of content type: structure what exists so the agent can navigate it efficiently rather than exploring it blindly.
This is what Synthesis is designed to provide. It indexes a corpus — code, documentation, PDFs, media metadata, configuration files, regulatory texts — and builds a multi-layer knowledge graph on top of it. The graph has edges between documents that reference each other, between code modules that depend on each other, and between directories that share topics and entities.
The same principle applies to purpose-built knowledge bases like the Regulatory Knowledge Infrastructure — a structured index of regulatory frameworks with article-level fragment manifests, built specifically so an AI agent can load a single article in isolation rather than the entire regulation. That is semantic memory for a compliance domain: not "the regulation says X" retrieved from training data, but the actual text of Article X, including implementing regulations and supervisory authority guidance, navigable at fragment level.
The key property of semantic memory is that it represents current state — not history, but now. When you add a file or update a regulation, re-run the scan, and the new content's relationships appear in the graph. The semantic layer represents your knowledge domain as it currently is, not as it was during some past session.
In our MCP benchmark, agents with access to this layer used 35% fewer tool calls when navigating a complex workspace. The reduction comes from the agent arriving knowing what exists and how it connects — rather than spending tool calls discovering structure that the index already knows.
The KCP benchmark extended this to documentation repositories: 53–80% reduction in tool calls across five repositories including smolagents, AutoGen, and CrewAI. The larger gains came from repositories with the worst natural navigability — the ones where a baseline agent spends the most time exploring before finding anything. The pattern holds across domains: the harder the corpus is to navigate without a map, the bigger the improvement when you provide one.
The three layers are complements, not alternatives¶
This is the point worth pausing on.
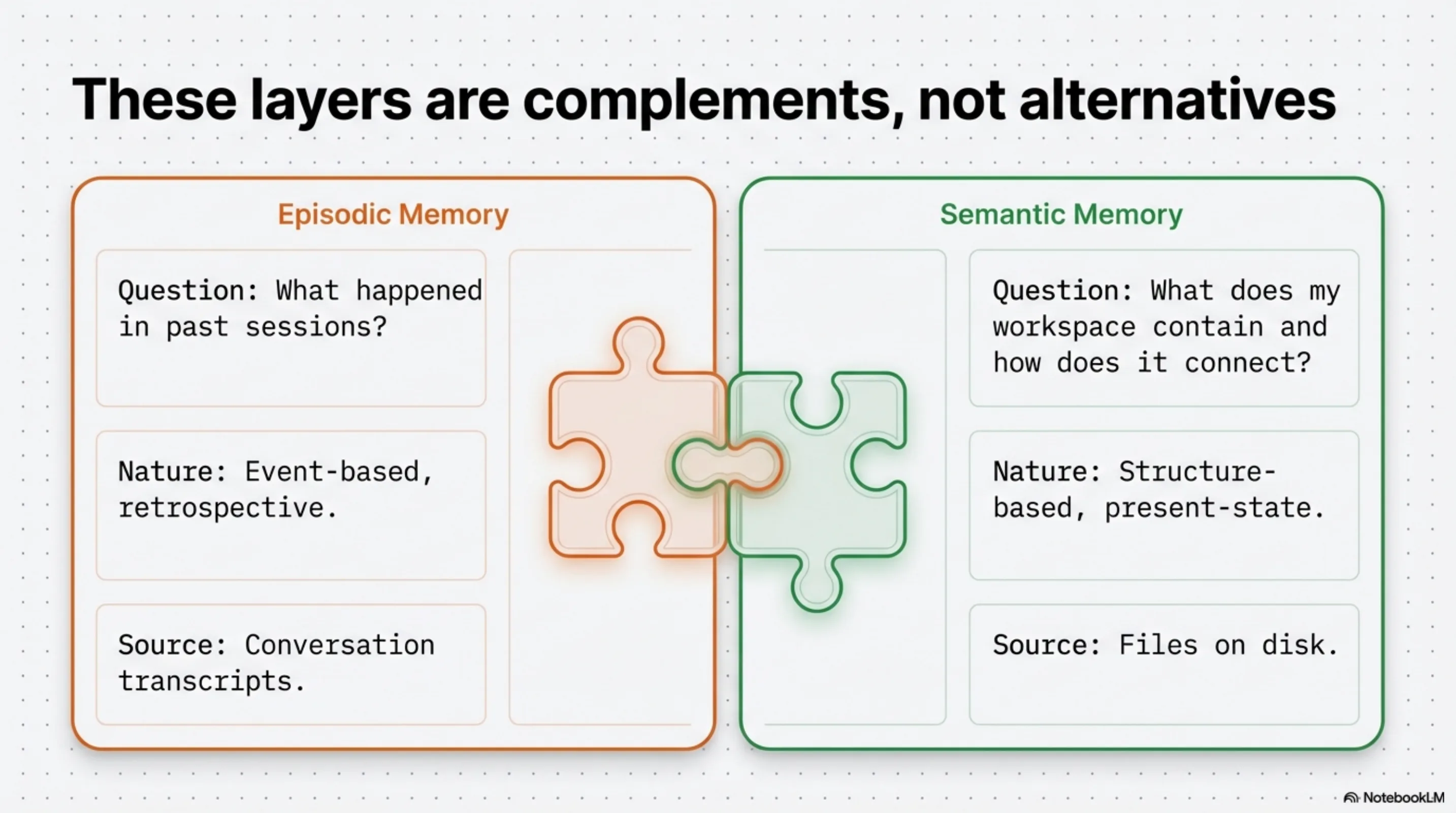
Claude History MCP and Synthesis are not competing approaches to the same problem. They answer different questions from different data sources with different temporal orientations.
Claude History MCP and kcp-memory answer: what happened in my past sessions? Retrospective, event-based, built from conversation transcripts. kcp-memory is the standalone option; Synthesis v1.21.0 sessions covers the same ground if you are already running Synthesis.
Synthesis answers: what does my workspace contain and how does it connect? Present-state, structure-based, built from files on disk.
A well-equipped AI agent needs both — plus working memory management at the session level. The human brain runs all three in parallel because they serve different cognitive functions. There is no reason to expect AI agents to be different.
As of v1.21.0, Synthesis handles both questions natively. The sessions module indexes the same JSONL transcripts as Claude History MCP and surfaces them through the same MCP server that already provides workspace search — so Layers 2 and 3 are queryable through a single integration point. The indexing gap between the layers is closed: synthesis sessions search and synthesis search share the same session and can be invoked from the same agent context.
kcp-memory v0.3.0 takes the same step for the standalone path. The episodic layer is now an MCP server: four tools (expanding to six in v0.4.0), stdio transport, registered with one entry in mcpServers. If you are not running Synthesis, the gap is now equally closed — Claude queries kcp-memory directly, without requiring you to copy-paste search results into the context window.
kcp-memory v0.4.0 goes further: the episodic layer shifts from pull to push. kcp_memory_project_context reads the current working directory from the process environment and surfaces recent session history automatically — no query, no session ID, no user prompt. The blank slate is no longer something the agent has to work around. It is structurally resolved at session start.
What remains manual is the deeper integration: architectural decisions documented in your session history are not automatically reflected as constraints in your semantic memory. "We decided to avoid synchronous database calls in the API layer" lives in a session transcript. The dependency graph in Synthesis does not know about that decision. Propagating episodic constraints into the semantic layer — tagging decisions, surfacing relevant history when the agent touches related code — is the next step. The infrastructure for it now exists. The plumbing between layers is still work to be done.
The adoption gap¶
The uncomfortable part of this picture is that most teams are not running any of these layers intentionally.
Working memory is managed ad hoc — sometimes a CLAUDE.md file, sometimes nothing. Episodic memory is zero: the session transcripts exist on disk, but nothing indexes them or makes them queryable. Semantic memory is zero: the workspace is a flat pile of files with no graph structure, no relationship tracking, no tightness metrics, no temporal changelog.
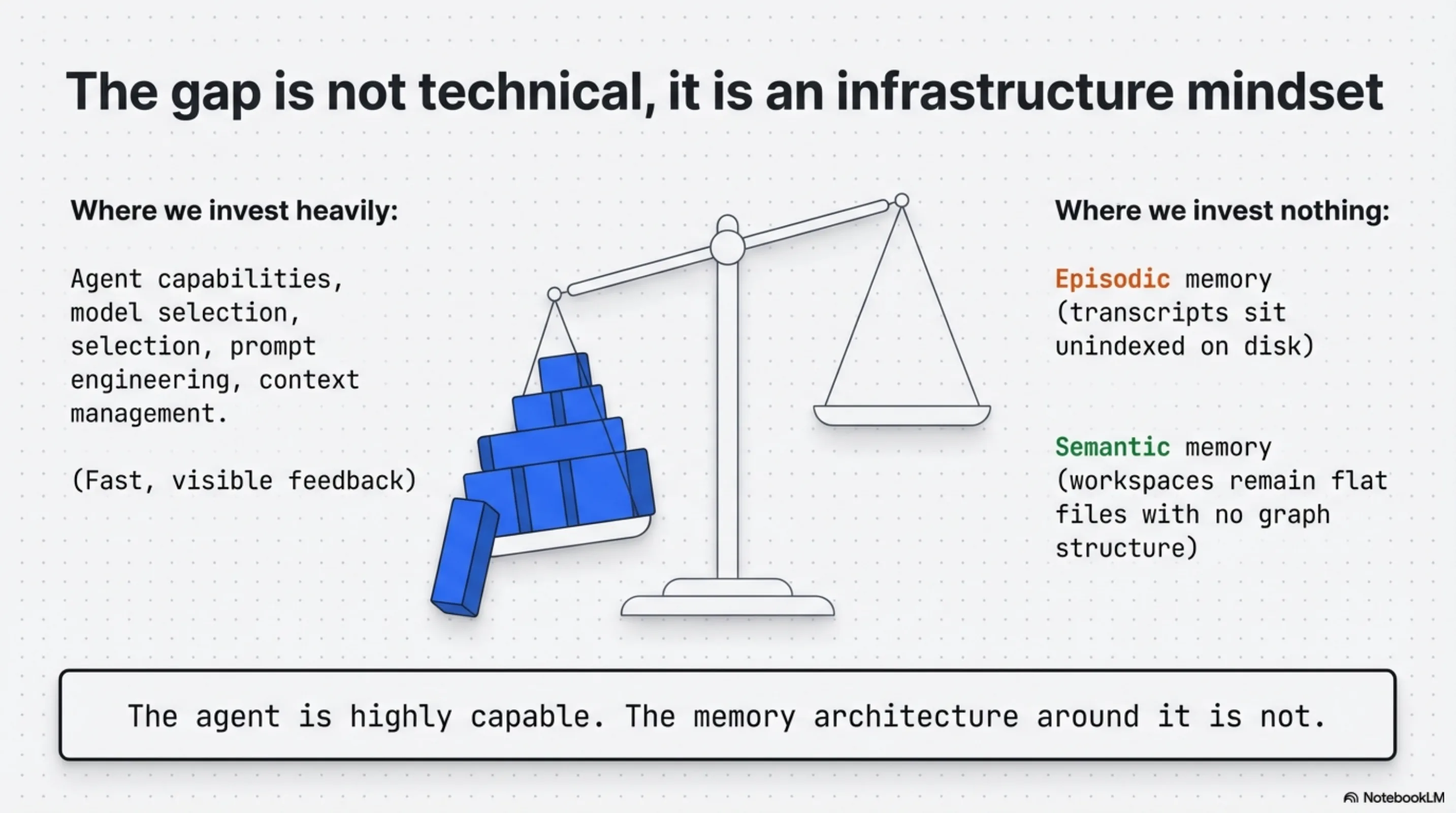
The agent is capable. The memory architecture around it is not.
Jon Hammant built his episodic layer because he encountered the problem directly and wrote the tool to solve it. That is how useful infrastructure gets built — someone hits the wall, builds the thing, and it turns out others needed it too.
The gap between "the tools exist" and "teams are running them" is not a technical gap. It is an infrastructure mindset gap. Developers invest in the agent's capability (model selection, prompt engineering, context management) because that investment is visible and fast-feedback. Memory architecture investment is slower to pay off and harder to attribute.

The payoff is real. The 53–80% tool call reduction is not from a better model. It is from a better map. A better map, not a better model — that is the reframe the field has not yet made.
What the architecture looks like when it is complete¶
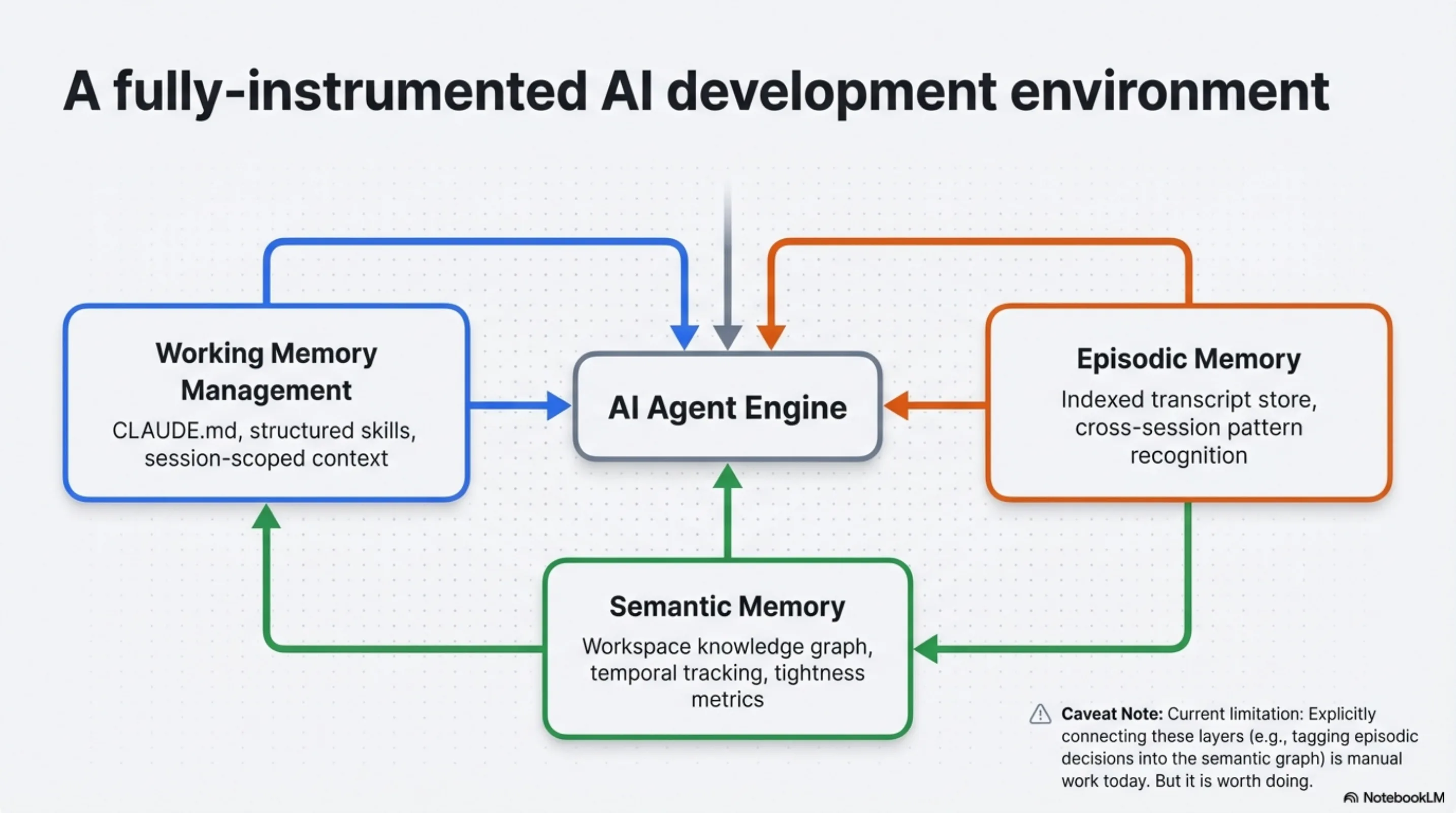
A fully-instrumented AI agent development environment has:
Working memory management. CLAUDE.md with project context. Structured skill files with domain knowledge. Session-scoped context that loads in seconds and grounds the agent's responses in verified sources rather than training-data approximations.
Episodic memory. An indexed transcript store that makes past decisions, debugging sessions, and architectural discussions retrievable. Pattern recognition across sessions: "we've tried this approach three times, here's what we learned." Claude History MCP provides this as a standalone tool; synthesis sessions provides it natively if you are already running Synthesis.
Semantic memory. A structured knowledge graph — something like Synthesis — that represents the current state of everything the agent needs to reason over. Code, documentation, regulatory frameworks, domain knowledge bases. Relationships between files, between modules, between directories. Temporal tracking for "what changed since last Tuesday." Tightness metrics for "where is our knowledge fragmented?" The corpus can be a codebase, a documentation repository, or a purpose-built regulatory index — the architecture is the same.
None of this is science fiction. All three layers exist as tools you can deploy today. The missing piece is treating them as a system rather than as isolated experiments.
The practical starting point¶
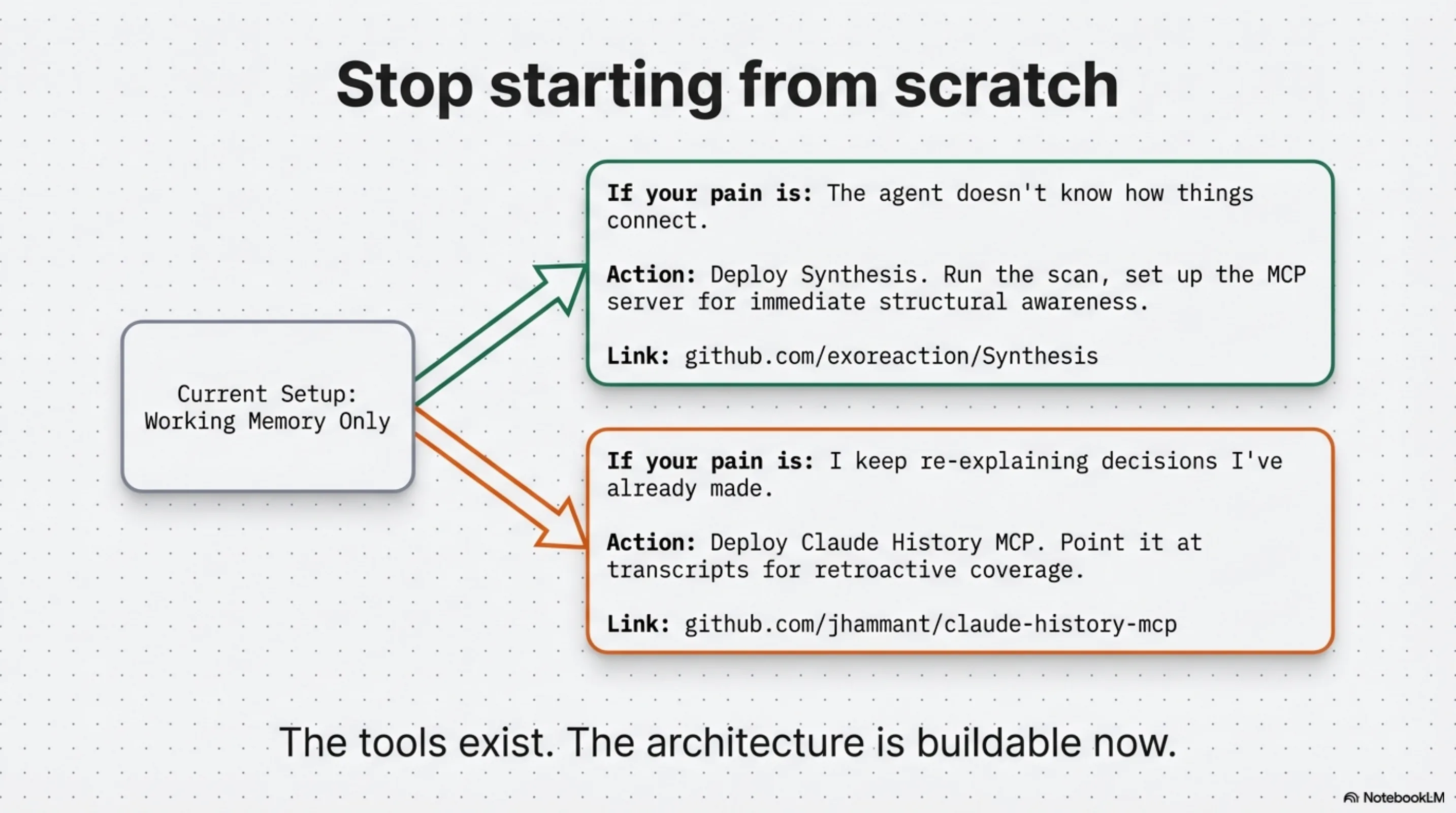
If your current setup is working memory only:
Add semantic memory first if your primary pain is "the agent doesn't know how things connect." Deploy Synthesis, run the scan, set up the MCP server. One setup session. This applies whether your corpus is a codebase, a documentation repository, or a regulatory knowledge base — the agent arrives knowing what exists and how it connects, rather than discovering it one tool call at a time.
Add episodic memory first if your primary pain is "I keep re-explaining decisions I've already made." Three options exist today:
- kcp-memory — standalone daemon, one-curl install, no other dependencies required. Session-level:
kcp-memory search,list,stats. Tool-level (v0.2.0, requires kcp-commands v0.9.0):kcp-memory events search "kubectl apply". MCP server (v0.3.0, 4 tools; v0.4.0, 6 tools), register inmcpServers— Claude queries inline.kcp_memory_project_context(v0.4.0): readsPWD, returns last 5 sessions + 20 events at session start — no query needed. PostToolUse hook for near-real-time indexing. Open-source, Apache 2.0. synthesis sessions— if you are already running Synthesis v1.21.0+, runsynthesis sessions scan— indexes your existing transcripts retroactively and is searchable immediately through the same MCP server.- Claude History MCP — standalone tool with Jaccard similarity clustering that extracts learnings at a different granularity from the raw session events.
The layers complement each other and can be deployed independently. Start with whichever solves the pain you feel most acutely.
The goal is an agent that does not start from zero. That knows what your workspace contains, remembers what you decided, and loads the relevant context in seconds rather than requiring you to re-establish it from scratch each session.
This is not a model capability question. It is a memory architecture question. The architecture is buildable now.
kcp-memory: github.com/Cantara/kcp-memory
Claude History MCP: github.com/jhammant/claude-history-mcp
Synthesis: AI Agents Without Knowledge Infrastructure Are Interns With Amnesia
KCP (Knowledge Context Protocol): github.com/cantara/knowledge-context-protocol