The Third Test Harness¶
![[ The Third Test Harness ] — Preventing specification drift in autonomous, AI-augmented development workflows. Terminal prompt: system_verify --target live --mode external_truth → STATUS: DRIFT DETECTED](/assets/images/blog/third-test-harness/th-hero.png)
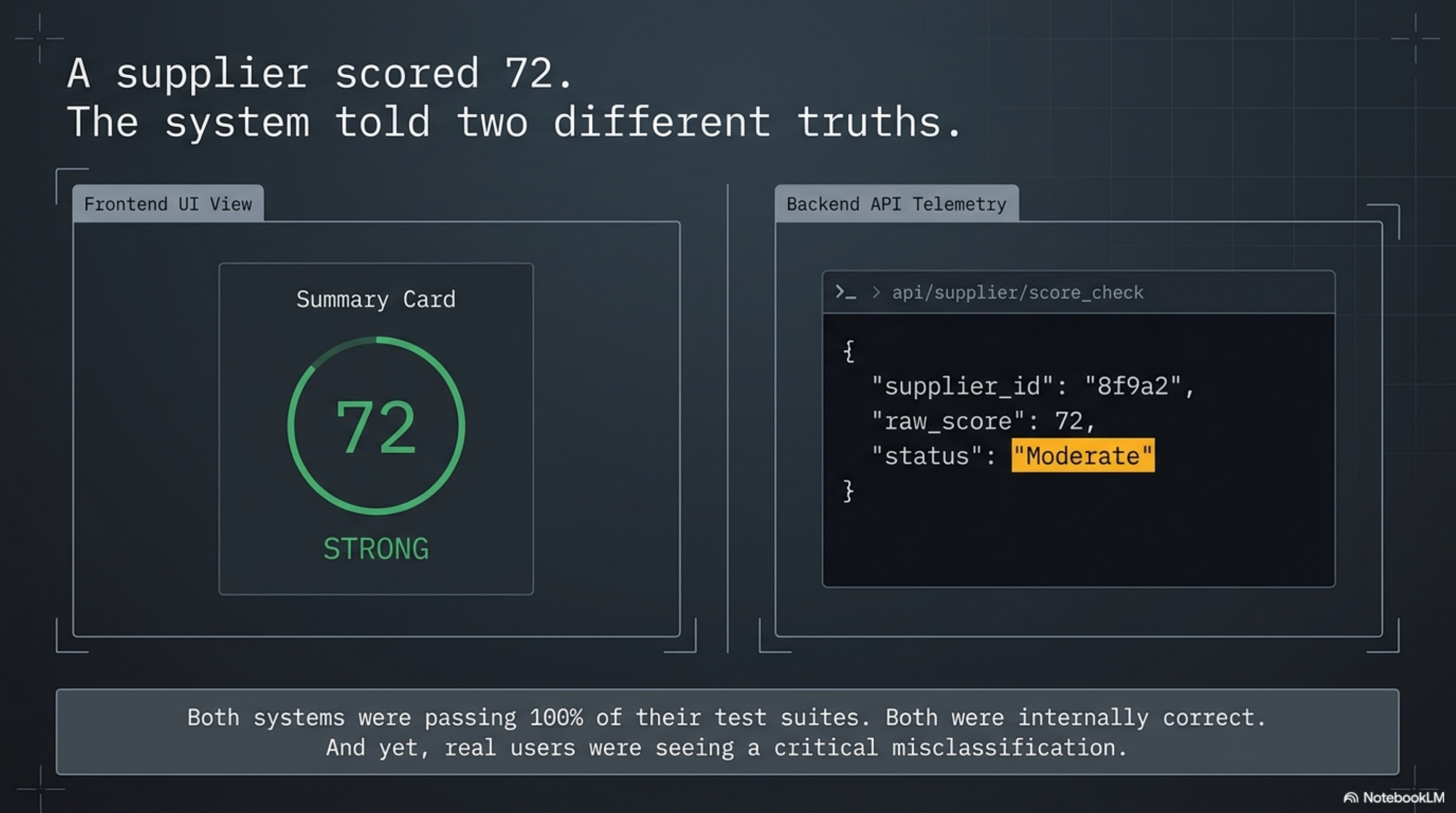
A supplier scored 72. The frontend showed a green ring and the label "Strong." The backend API returned "Moderate." Both systems were passing all their tests. Both were correct — according to their own definitions.
This was on a compliance SaaS platform where organizations track supplier risk through a three-tier scoring system. The tiers are simple:
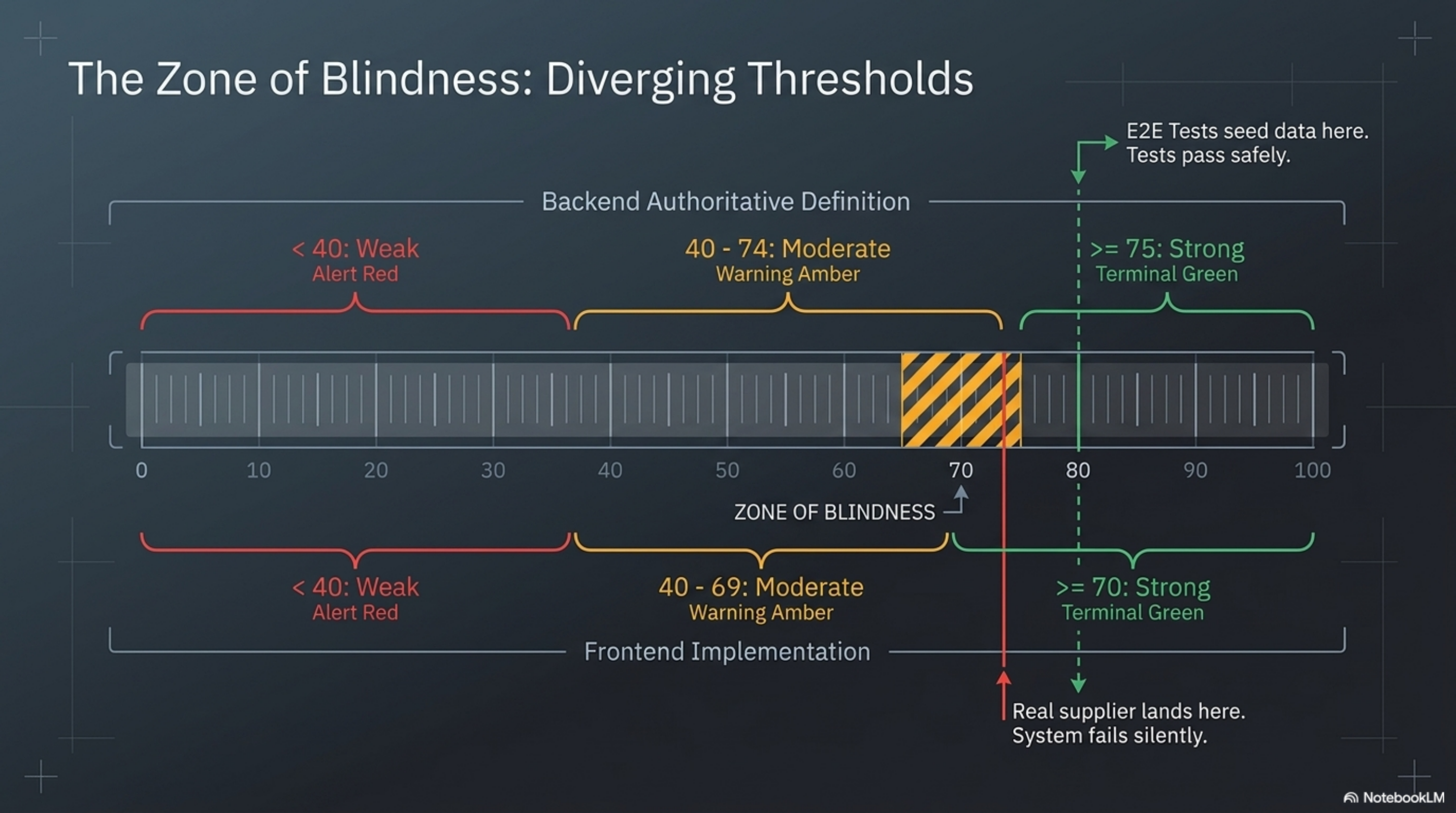
- Score >= 75: "Strong" (green ring)
- Score >= 40: "Moderate" (yellow ring)
- Score < 40: "Weak" (red ring)
The backend's authoritative scoring function used >= 75 for the "Strong" threshold. Four separate frontend components — a summary card, a detail view, a trust center panel, and a profile view — had all been implemented with >= 70. Each component was internally consistent. Each passed its own unit tests. Each rendered the right shape of UI in the integration test suite. And all four were wrong in a way that neither unit tests nor integration tests could detect.
The bug was found by a third layer: a verification harness that runs against the live deployed environment and independently derives what every value on screen should be.
Two Layers That Passed¶

The platform has three testing layers. The first two are conventional.
Unit tests test each layer in isolation. The backend's scoring function returns "Moderate" for an input of 72. Pass. The frontend's equivalent function returns "Strong" for the same input. Also pass. Both functions are internally correct. The inconsistency lives in the gap between them, and unit tests do not test gaps. They test implementations.
Integration E2E tests with testcontainers assemble the full stack — real database, real backend, real frontend — and run Playwright assertions against the rendered UI. The test seeds a supplier with a specific score, navigates to the relevant page, and asserts that a label appears. If the seeded score is 80, the assertion expect(card.getByText("Strong")).toBeVisible() passes correctly. Both frontend and backend agree that 80 is "Strong." The threshold mismatch at 72 is invisible because the test data was chosen when the threshold was assumed to be 70.
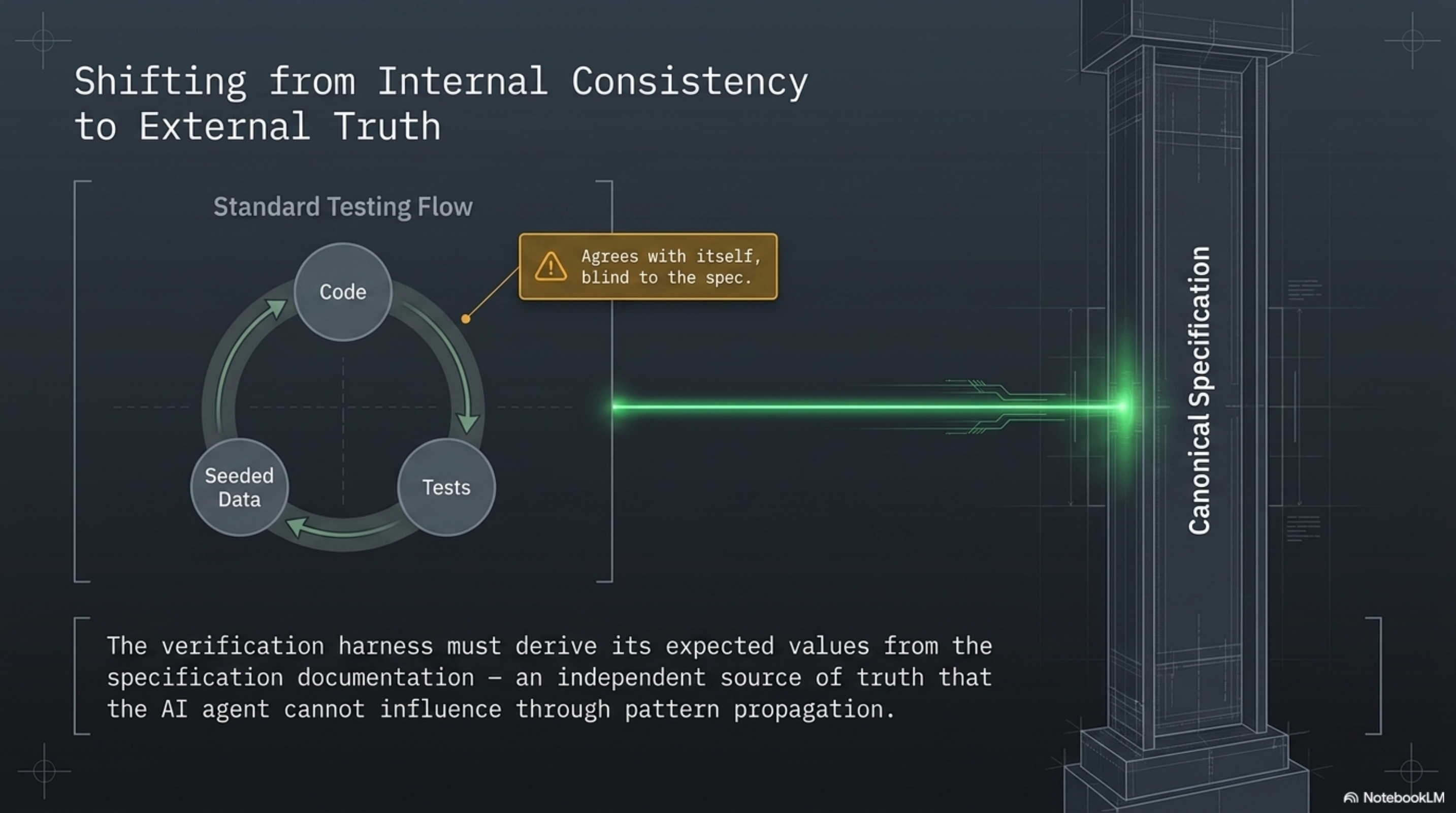
This is the mechanism of the blindness: the test itself was written with the same assumption as the code it was testing. The test and the code agree with each other. They just do not agree with the specification.
The Third Layer¶
The third layer is different in kind. It is not an extension of the first two. It is architecturally distinct.
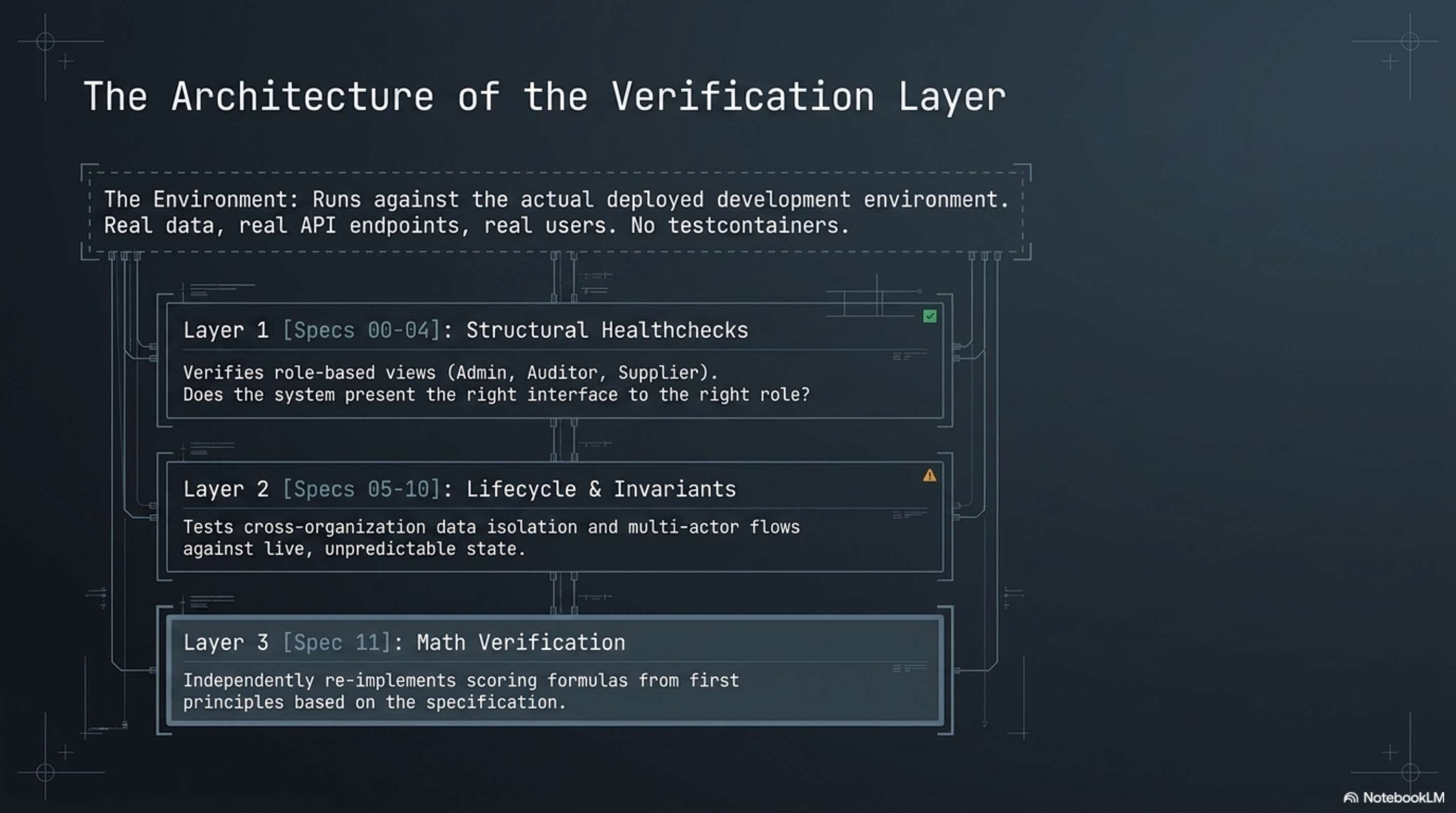
Twelve Playwright specs run against the actual deployed development environment. Not testcontainers. The live system, with real data, real API endpoints, real users, real state. The harness does not seed data. It reads whatever exists. It does not know in advance what values to expect. It derives them.
The specs are organized in layers of increasing depth:
Specs 00 through 04 are healthchecks and role-based views. They verify that each actor type — administrator, auditor, supplier — sees the correct pages and navigation elements. These are structural: does the system present the right interface to the right role?
Specs 05 through 10 are lifecycle tests. Regulation changes, supplier onboarding flows, multi-actor scenarios, cross-organization data isolation. One spec verifies the scoring priority chain — that when multiple scoring sources exist, the system resolves them in the documented order. These run against live state, so they must tolerate whatever data the environment contains. They are designed to be invariant-based, not value-based: not "this field equals 42" but "this field is consistent with the formula described in the documentation."
Spec 11 is the math verification spec. It independently re-implements the platform's three scoring formulas from the canonical documentation, calls the backend APIs to get raw scores, and computes expected values from first principles. If the API diverges from the formula, the spec fails with a human-readable breakdown showing every step of the computation.
The output looks like this:
════════════════════════════════════════════════════════════════
Compliance score verification — Regulation: GDPR
Scorable obligations: 14
Sum of scores: 1,247
Expected (round(1247/14)): 89
API returned: 89 ✓
Org overall score
Expected (round(avg([89, 76]))): 83
API returned: 83 ✓
════════════════════════════════════════════════════════════════
It is not checking that the system is internally consistent. It is checking that the system matches the canonical specification — a third, independent source of truth that neither the backend code nor the frontend code authored.
How It Found the Threshold Bug¶
The verification harness did not find the bug by asserting on a label. It found it through independent computation.
The sequence was:
- Call the backend API. Get the raw score for a supplier: 72.
- Apply the canonical formula: 72 < 75, so the expected label is "Moderate."
- Read what the frontend displayed: "Strong" with a green ring.
- Mismatch. Fail.
The spec reported exactly what diverged: the API's computed label, the harness's independently derived label, and the frontend's displayed label. Three values. Two matched. One did not. The spec pointed at the frontend.
The investigation took less than an hour. Four frontend components had all been implemented with a >= 70 threshold for "Strong." The backend used >= 75. The fix touched five files — four components and the test boundary assertions — all updated to >= 75 to match the authoritative backend definition. Discovered and resolved in the same day.
Why This Category of Bug Is Invisible¶
This is not a subtle bug. It is a five-point threshold difference that causes real misclassification of real suppliers. And yet it is structurally invisible to the first two testing layers.
Unit tests cannot see it because the inconsistency exists between modules, not within them. Each module's tests validate against the module's own definition. The backend says "Moderate" for 72, and the backend's tests agree. The frontend says "Strong" for 72, and the frontend's tests agree. There is no unit test that says "the frontend and the backend should agree on what 72 means." That assertion does not belong to either module. It belongs to the system.
Integration tests cannot see it because the test data was chosen to avoid the mismatch zone. A score of 80 is "Strong" by both definitions. A score of 30 is "Weak" by both definitions. The test passes because the test's data was picked from a region where the two definitions happen to converge. The five-point gap between 70 and 75 is a narrow band of disagreement, and the probability that randomly chosen test data lands exactly in that band is low enough that it never happens — until it happens in production, to a real supplier, with real consequences.
The verification harness sees it because it has no pre-chosen test data. It reads whatever the live system contains. If a supplier happens to score in the 70-74 range, the mismatch surfaces. But more importantly, the harness does not use the frontend's definition or the backend's definition. It uses its own, derived from the specification document. It is an independent observer. It catches the gap because it does not share the gap's assumptions.
The Three-Layer Model¶
Each layer tests something the others cannot.
| Layer | Environment | What it catches | What it misses |
|---|---|---|---|
| Unit tests | Isolated, mocked | Logic bugs within a module | Cross-layer inconsistency |
| Integration E2E (testcontainers) | Assembled, seeded | Runtime assembly bugs, CORS, port races | Spec drift between layers with different assumptions |
| Verification harness (live deployment) | Real environment, real state | Spec drift, formula divergence, UI/API mismatch | Seeded-state edge cases, performance |
The third layer is expensive. It requires a live deployed environment, pre-configured test accounts with appropriate roles, and a harness that knows enough about the system's specification to independently derive expected values. It cannot run in CI the way testcontainers can — it needs a real deployment target. Its specs must be designed to tolerate variable state, which makes them harder to write than specs that control their own data.
It is not a replacement for the first two layers. It is the thing the first two layers cannot be.
Why This Matters More in an Agent-Augmented Workflow¶
Here is the angle that no existing testing post seems to cover.
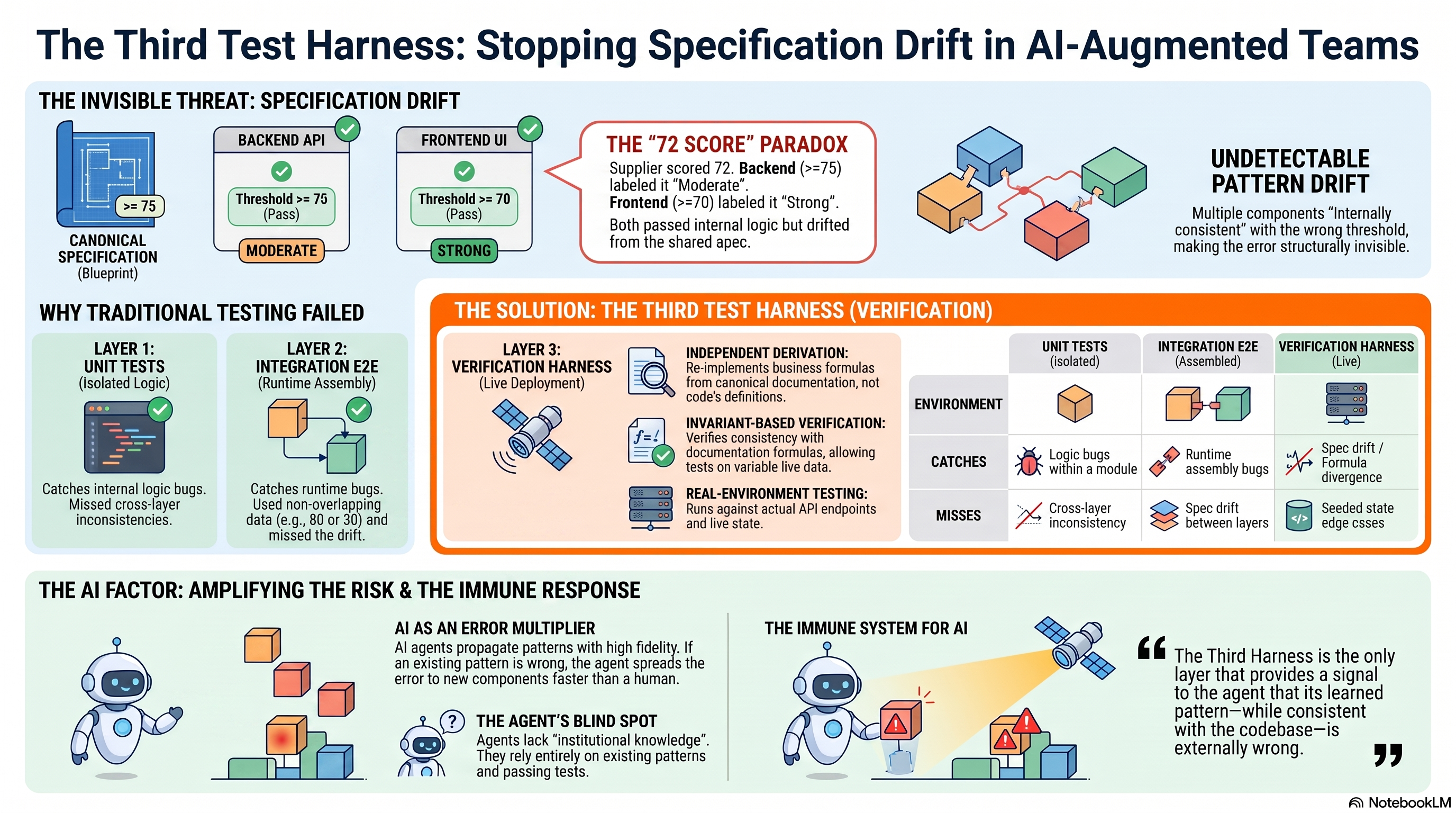
When an AI agent writes a new frontend component, it writes consistent code. Internally correct. Pattern-matched against the examples it has seen in the codebase. If the other four frontend components use >= 70 for the "Strong" threshold, the agent will use >= 70 for the fifth. It is doing exactly what it should: learning from existing patterns and propagating them faithfully.
The agent does not know it introduced a threshold mismatch. It did not introduce one. It inherited one. The mismatch was already there, baked into the four existing components, each one individually correct, collectively wrong. The agent propagated the error with the same fidelity it propagates everything else. The unit tests pass. The integration tests pass. The verification harness fails.
This is the specific failure mode that agent-augmented development amplifies: specification drift propagation. An agent's consistency is both a feature and a liability. It propagates existing patterns with high fidelity. If the existing pattern has drifted from the specification, the propagation accelerates the drift. Every new component the agent writes using the wrong threshold makes the problem wider. The gap between implementation and specification grows proportionally to the agent's productivity.
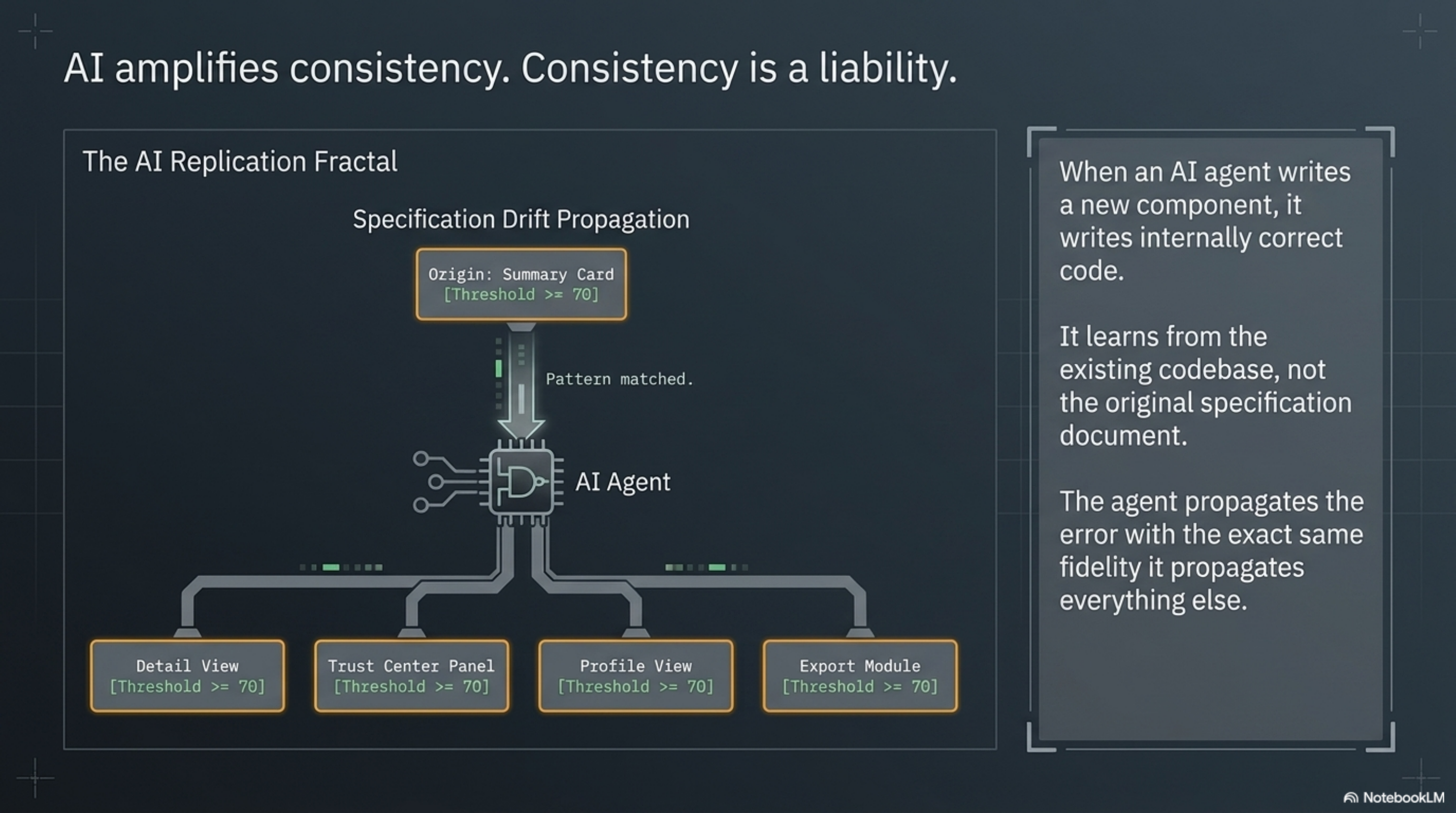
Traditional human development has a weak but real defense against this: the developer might check the spec. Might remember a conversation about the threshold. Might notice that 70 feels wrong because they recall it should be 75. The defense is unreliable — hence the four components that were already wrong — but it exists. The agent does not have it. The agent has patterns and tests. If the patterns are wrong and the tests agree with the patterns, the agent has no mechanism to detect the drift.
The verification harness is that mechanism. It derives from the specification, not from the codebase. It is an independent source of truth that the agent cannot influence through pattern propagation, because it was written from a different source document. When the agent writes a component with the wrong threshold and the harness catches the mismatch, the agent gets a signal that its learned pattern is wrong — a signal that no amount of unit testing or integration testing could provide.
This is not a theoretical concern. The threshold bug was real. Four components were wrong. The verification harness found it. The fix was five files. Without the harness, the bug would have persisted indefinitely — undetectable by every other testing layer, propagating into every new component, growing wider with every sprint.
The Cost of Not Having It¶
Most teams have two testing layers. Some have one. Very few have three. The third layer is the most expensive to build and maintain, and it is the one that catches the category of bugs the other two cannot.
In a pre-agent world, the cost-benefit calculus was borderline. Specification drift accumulated slowly. Humans caught some of it through institutional knowledge. The bugs it produced were infrequent enough to manage through incident response.
In an agent-augmented world, specification drift propagates at agent speed. A team producing 60 pull requests per week through an AI agent can spread a threshold mismatch to a dozen new components in a week. Each one passes its tests. Each one looks correct. The mismatch grows silently.
The third test harness is not a luxury. It is the immune system against the specific failure mode that AI-augmented development introduces: the systematic propagation of patterns that are internally consistent and externally wrong.
The supplier scoring 72 was real. The green ring was wrong. Five files were touched. The verification harness — the one that derives expected values from the specification rather than from the codebase — is the only layer that could have found it. In an agent-augmented workflow, it is the layer you cannot afford to skip.