Against the Swarm¶
The AI industry has decided the future is a swarm. Dozens of agents, competing, debating, voting on outputs, selecting the best result through evolutionary pressure. It sounds elegant. It borrows the right metaphors from biology. And it is a spectacular misunderstanding of what makes AI useful in real engineering work.
I know this because I've spent seven weeks shipping the alternative. ExoCortex — a persistent AI cognitive layer running across multiple codebases — has merged 414 pull requests, accumulated 548 skills, produces roughly 35,000 lines of code per week, and maintains 3,847 tests. Not through a swarm of competing agents. Through one agent that stopped forgetting.
The swarm is a search algorithm. ExoCortex is a judgment engine. These are fundamentally different tools for fundamentally different problems, and the industry is reaching for the wrong one.

What Swarms Actually Are¶
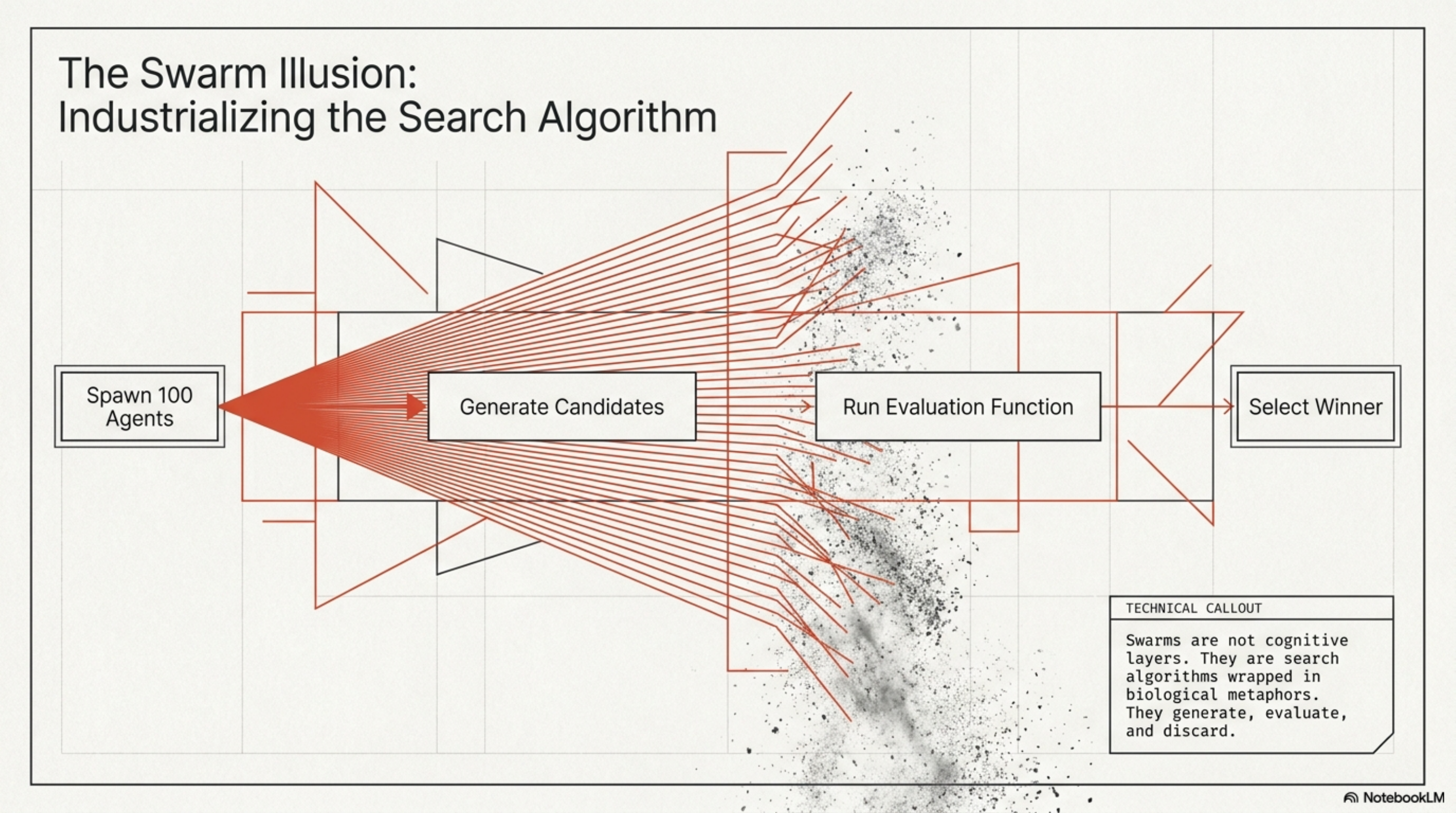
Let's be precise about what a swarm architecture does. You spawn multiple agents. Each one takes a different approach to a problem. You evaluate the outputs against some criterion and select the best one. Sometimes they debate. Sometimes they vote. Sometimes you run tournament brackets. The specifics vary, but the structure is the same: generate many candidates, select the fittest.
This is search. It is a very good search. And for the right class of problem, it is unbeatable.
AlphaZero beat Magnus Carlsen because chess has a perfect evaluation function. You always know who is winning. You always know if a move was good. The search space is vast but bounded, and every position can be scored. Swarms excel in exactly these conditions:
- Bounded problems with clear edges. The solution space has walls.
- Verifiable outputs where you can mechanically check if the answer is right.
- Stateless evaluation where the quality of a solution doesn't depend on what you tried yesterday.
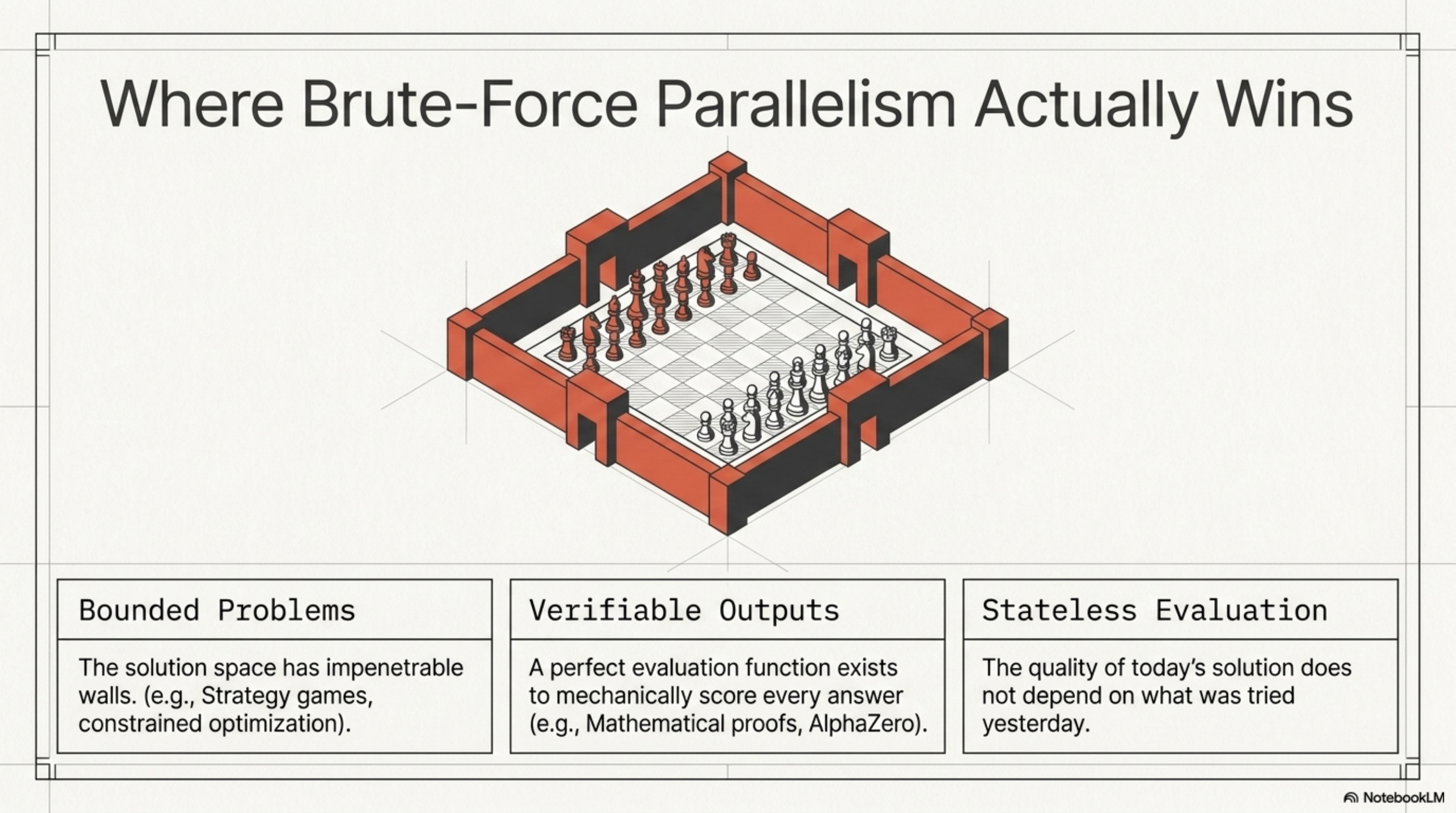
Code generation benchmarks, mathematical proofs, strategy games, constrained optimization — swarms are extraordinary here. If you can write an eval function, a swarm will find solutions you would never have considered.
But here is the question nobody in the swarm-architecture keynotes is asking: what percentage of real engineering work has a perfect evaluation function?
What Swarms Cannot Do¶
Look at what a real production system actually contains.
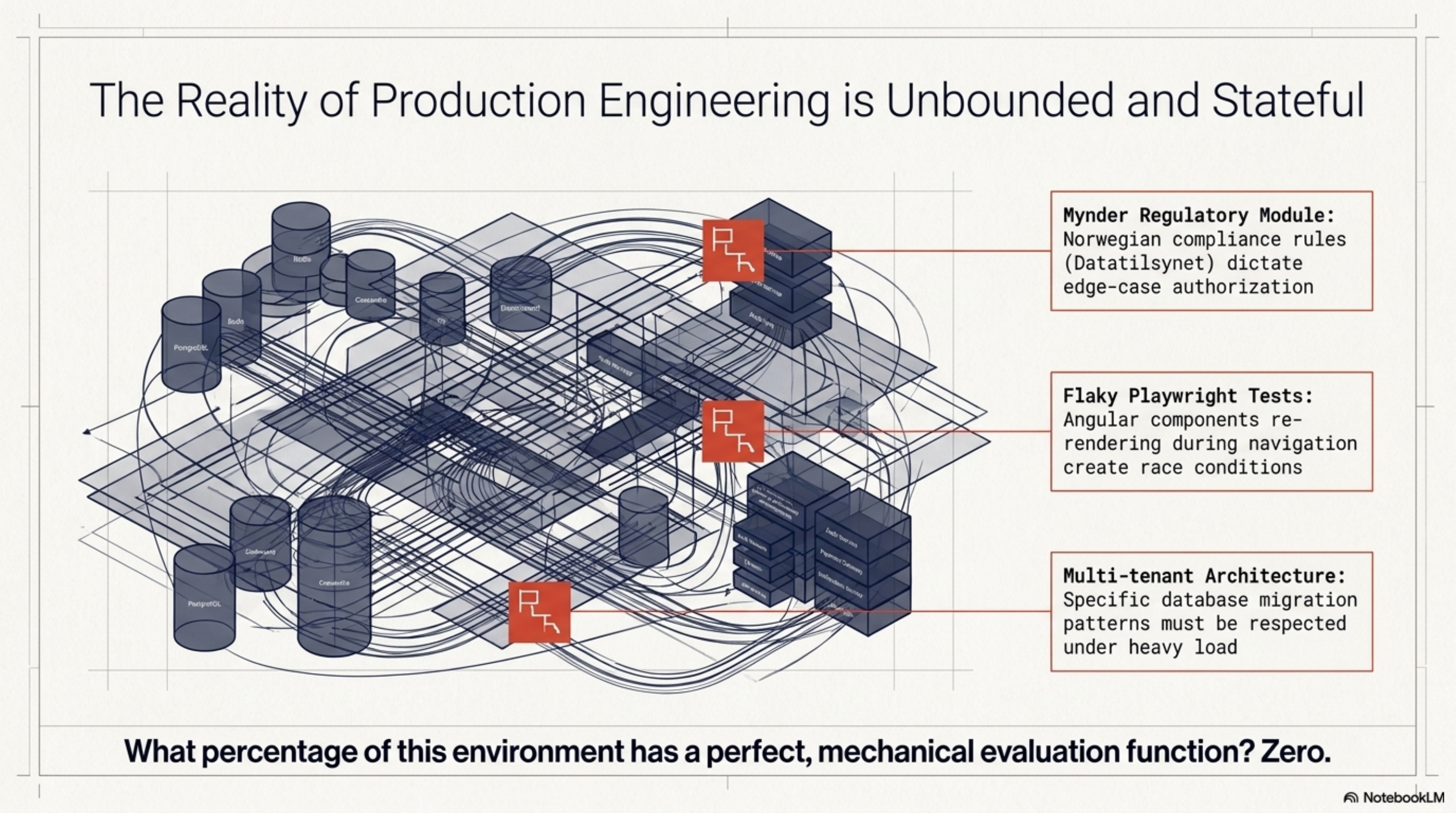
Last Tuesday, ExoCortex fixed a flaky Playwright test in Mynder's regulatory compliance module. The fix took four minutes. Not because the code was simple — because the agent already knew that this specific selector breaks when the Angular component re-renders during navigation, that the wait-for-stable pattern we adopted in week three handles this class of issue, and that the regulatory model has a particular data loading sequence that creates the race condition in the first place.
A swarm of ten agents, each with 10,000 tokens of context, has 100,000 tokens of total compute. ExoCortex, working from accumulated memory, had maybe 3,000 tokens of relevant context loaded. The swarm has 33x the raw capacity. It loses. Every time. Because the ten agents have zero shared understanding.
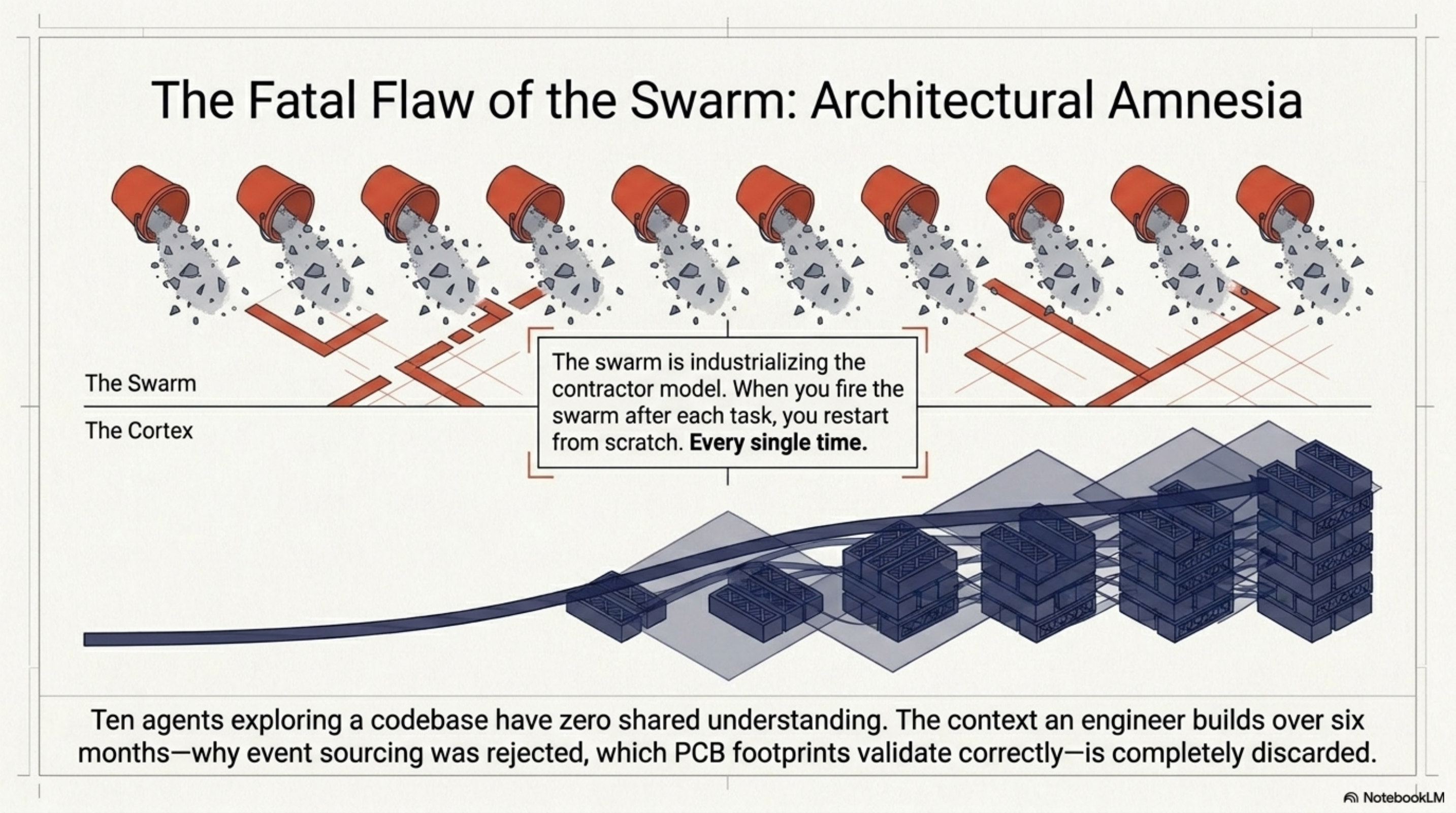
This is the central failure of the swarm architecture for production engineering work. When you fire the swarm after each task, you restart from scratch. Every time. The things that make an engineer fast after six months on a codebase — knowing the architectural decisions, knowing what was tried and rejected, knowing which patterns work and which ones look right but break under load — are exactly the things a swarm discards.
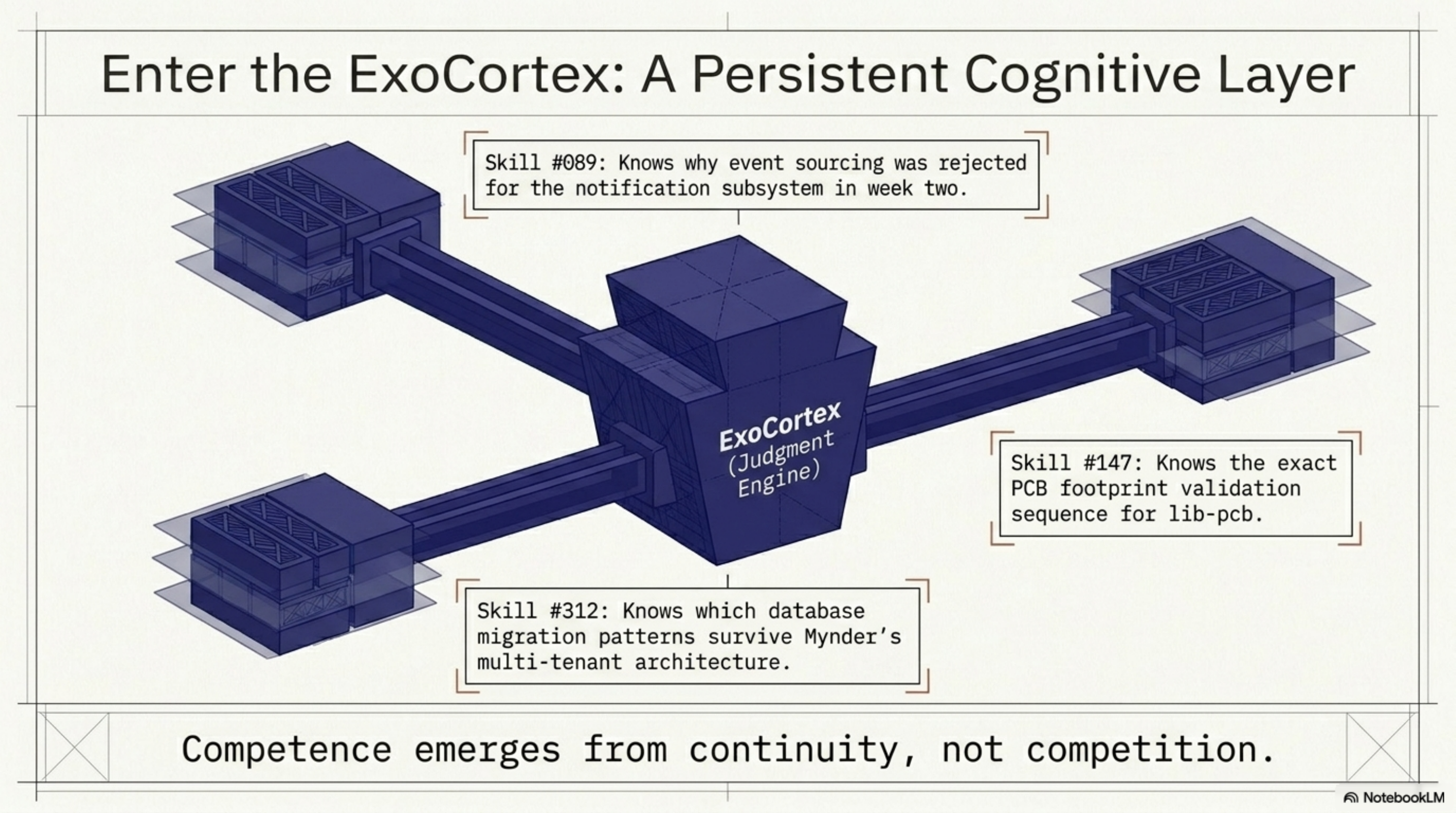
The 548 skills ExoCortex has accumulated didn't emerge from competition. They emerged from continuity. Skill #312 knows which database migration patterns work with Mynder's multi-tenant architecture. Skill #147 knows the exact PCB footprint validation sequence for lib-pcb. Skill #89 knows why we rejected event sourcing for the notification subsystem in week two and what we replaced it with. None of this survives a swarm's lifecycle.
The Inference Chain Problem¶
There is a deeper issue. A swarm doesn't just lack memory — it lacks the ability to build the inference chains that make memory useful.
When ExoCortex encounters a new feature request in Mynder, it doesn't start from the API spec. It starts from everything it knows: the regulatory model's structure, the tenant isolation patterns, the frontend component hierarchy, the test fixtures that already exist, the deployment pipeline's constraints, the last three times a similar feature was attempted and what went wrong. This isn't retrieval. It's judgment — the compound product of accumulated context applied to a new situation.
A swarm of ten agents, each loaded with a different slice of documentation, can collectively "know" the same facts. But knowing facts and having judgment are different things. Judgment is what tells you that this particular feature request, which looks like a simple CRUD addition, will actually require changes to the authorization model because of an edge case in the Norwegian regulatory framework that surfaced during the Datatilsynet compliance review in week four. No amount of parallel search finds that. It requires the kind of longitudinal context that only persistence builds.

This is what I call the inference chain problem. Ten agents with ten thousand tokens each have one hundred thousand tokens of information and zero inference chains connecting them. The value isn't in the tokens. It's in the chains.
The Evidence¶
Here are the numbers, because claims without evidence are just opinions.
414 pull requests merged in 7 weeks. That is roughly 60 per week, or about 12 per working day. The pace didn't come from spawning more agents. It came from each subsequent PR being faster than the last, because the agent accumulated context about what worked.
Week 1 versus Week 7:
- Week 1: Average PR took significant context loading. The agent needed to learn the codebase, understand patterns, discover test conventions.
- Week 7: The same class of PR completes in a fraction of the time. Not because the model got smarter. Because the skills file grew. Because the memory of what was tried and rejected eliminated dead-end exploration.
35,000 lines of code per week across Mynder SaaS, lib-pcb, Synthesis knowledge graph, and Cantara open source projects. Simultaneously. Not by running a swarm across them — by maintaining persistent context for each.
3,847 tests maintained. Not generated and forgotten — maintained. When the regulatory model changed, ExoCortex updated the tests that depended on the old model. It knew which tests to update because it wrote them. A swarm would need to rediscover that dependency graph from scratch.
The throughput improvement isn't linear. It's compound. Each skill makes every subsequent task faster. Each memory of a rejected approach saves the time of re-exploring it. This is the compound interest of persistent context, and swarms cannot accumulate it.

The Comparison¶
| Dimension | Swarm Architecture | Persistent Cortex |
|---|---|---|
| Best at | Bounded search, verifiable outputs | Accumulated judgment, cross-cutting context |
| Context model | Distributed, isolated, disposable | Continuous, connected, compounding |
| Learning curve | Flat — restarts every task | Steep — every task makes the next one faster |
| Evaluation | Requires explicit eval function | Builds implicit quality model over time |
| Failure mode | Expensive exploration of known dead ends | Single point of failure if context corrupts |
| Token efficiency | High total spend, low utilization per agent | Low total spend, high utilization |
| Organizational knowledge | Cannot retain | Primary asset |
| Ideal problem | "Find the best solution among many" | "Build the right solution given everything we know" |
| Real-world analogy | Hiring 10 contractors for one day each | One senior engineer who's been on the team for six months |
The last row is the one that matters most. Every engineering leader knows the difference between ten day-one contractors and one engineer who understands the system. The swarm architecture is industrializing the contractor model. ExoCortex is industrializing institutional knowledge.
Where the Industry Bets Wrong¶
The swarm convergence is not accidental. It is driven by the same incentive structure that gave us story points, velocity metrics, and the entire Agile-industrial complex: optimizing for the measurable at the cost of the valuable.
Swarms produce great benchmark numbers. You can measure them. You can graph the improvement. You can publish papers with clean ablation studies showing that eight agents outperform four. The evaluation function is right there in the architecture — it's what selects the winning output. This is catnip for research teams and venture capitalists alike.
But the most valuable things in engineering — the reason your senior architect is worth five juniors — cannot be benchmarked. Taste. Judgment. The instinct that says "this approach is technically correct and strategically wrong." The memory of what was tried eighteen months ago and why it failed. The understanding that this simple-looking change touches a load-bearing assumption in the authorization model.
Swarm architectures optimize for the measurable. Persistent architectures accumulate the valuable. The industry is pouring billions into the former because it's easier to fundraise around benchmark improvements than around "our agent remembers what happened last month."
This is the story points mistake all over again. We optimized for velocity and got feature factories. We are about to optimize for agent parallelism and get code factories — high throughput, zero judgment, impressive metrics, mediocre systems.
The Right Synthesis¶
I am not arguing that swarms are useless. I am arguing they are misapplied.
The right architecture uses both, but in different roles. The persistent cortex produces. It holds the context, makes the judgment calls, writes the code that reflects accumulated understanding of the system. It is the senior engineer.
The swarm verifies. Multiple agents review the same output from different angles. One checks for security issues. One checks for performance regressions. One checks for consistency with existing patterns. One tries to break it. This is adversarial review, and it is where parallel, independent, stateless agents genuinely shine — because verification is a bounded problem with clear evaluation criteria.
Produce with judgment. Verify with search. This is the architecture that works. Not because it's theoretically elegant, but because it matches the actual structure of engineering work: most of the value is in making the right decision, not in exploring every possible decision.
ExoCortex produces the PR. A verification layer can check it. But the verification layer cannot produce it, because production requires knowing why the last three approaches were rejected, what the regulatory model demands, which database patterns survive under load, and what the team decided in the architecture review that isn't written down anywhere.
The Stake in the Ground¶
Here is what I believe, grounded in 414 merged pull requests and seven weeks of production evidence:
Persistent context with accumulated judgment will outperform swarm architectures at every task that matters in production engineering. Not at benchmarks. Not at constrained puzzles. At the work that actually ships products — the work that requires knowing your codebase, your team's decisions, your users' constraints, and your system's history.
If you are building AI-augmented development infrastructure, stop optimizing for agent count and start optimizing for agent memory. Stop measuring parallel throughput and start measuring accumulated context. Stop asking "how many agents can we run?" and start asking "how much does our agent know?"
The future of AI in engineering is not a swarm. It is a cortex — one agent that knows your work deeply enough to exercise judgment, not just search. Build that, and the compound returns will make the swarm's parallelism look like what it is: an expensive way to rediscover what you already knew.
