From Policy to Practice: How KCP Makes Regulations Machine-Readable for AI Agents¶
A presentation version of this post is available as slides.
Your agent reads customer data. It makes a decision. It writes something to a database.
Somewhere in your system prompt, there is a line that says: "You must comply with GDPR data minimization principles when accessing customer data."
That line does nothing. It is not verifiable. It is not testable. It is not auditable. It is a string that your model may or may not attend to, depending on context length, prompt position, and the phase of the moon.
This is how most teams handle compliance for AI agents today. There are three common patterns, and all three are broken.
The Problem: Compliance as Afterthought¶
Pattern A: System prompt stuffing. You write your compliance requirements as natural language instructions in the system prompt. "Always follow GDPR." "Do not access fields beyond what is necessary." These instructions compete with every other instruction in the context window. They cannot be evaluated programmatically. An auditor cannot inspect them without reading your application code. And if you have twelve agents across three services, you have twelve copies of the same prose, each slightly different, each invisible to the others.
Pattern B: Post-hoc review. The agent runs. Someone reviews the output later. Maybe a human. Maybe another LLM. Either way, the damage is already done. You cannot un-access a field. You cannot un-send data to an external API. Post-hoc review catches visible mistakes. It misses invisible ones -- the field that was read but not surfaced, the API call that happened in a tool invocation three layers deep.
Pattern C: Periodic audit. Once a quarter, a compliance officer asks: "What did the agent do with customer data?" The engineering team scrambles to reconstruct logs, explain decisions, and demonstrate that the agent operated within its boundaries. This works when agents process ten requests a day. It does not work when agents process ten thousand.
The root cause is the same in all three patterns. The policy is encoded as prose. Prose is for humans. Agents need data.
A policy is a declaration. A declaration should be structured, versionable, and machine-readable. That is what KCP provides.
 All three patterns share the same root cause: the policy is encoded as prose. Prose is invisible to evaluators, unversioned across agents, and unauditable under examination.
All three patterns share the same root cause: the policy is encoded as prose. Prose is invisible to evaluators, unversioned across agents, and unauditable under examination.
The KCP Compliance Block: Declarations as Data¶
KCP -- Knowledge Context Protocol -- is a YAML-based manifest format that tells agents what knowledge exists, how to navigate it, and what constraints apply. The compliance block is where regulations become structured metadata.
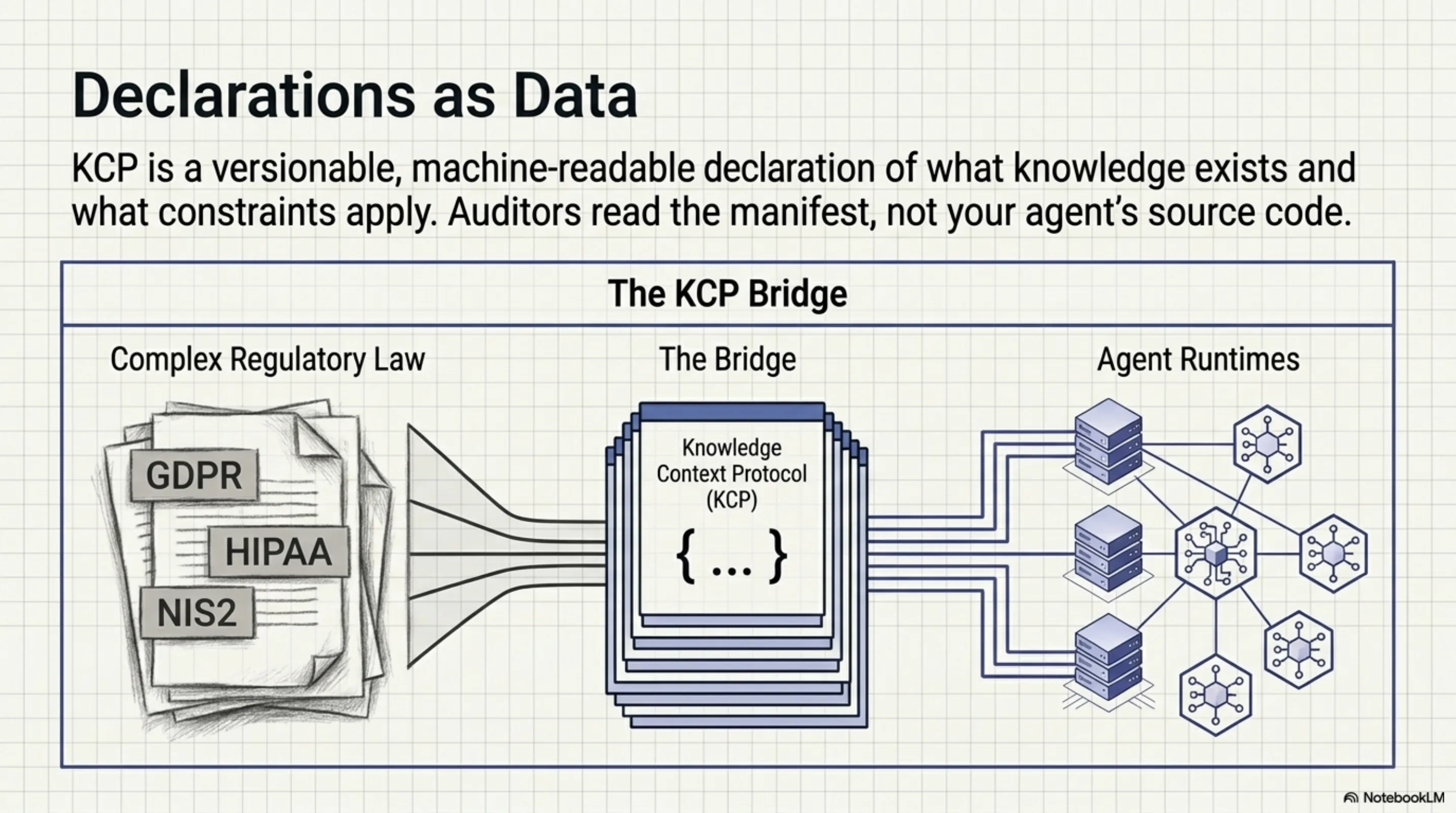 Complex regulatory law on the left. Agent runtimes on the right. KCP is the bridge — a versionable, machine-readable declaration that auditors can read independently of your source code.
Complex regulatory law on the left. Agent runtimes on the right. KCP is the bridge — a versionable, machine-readable declaration that auditors can read independently of your source code.
Here is a real example. A customer onboarding agent needs to access personal data in the EEA under GDPR:
kcp_version: "0.9"
project: customer-onboarding
compliance:
data_residency: [EEA]
regulations: [GDPR]
sensitivity: confidential
restrictions:
- no-external-llm
- audit-required
trust:
audit:
agent_must_log: true
require_trace_context: true
units:
- id: gdpr_data_minimisation
path: compliance/gdpr/data-minimisation.md
intent: "What data fields is the agent allowed to access for this task?"
scope: global
audience: [agent, operator]
sensitivity: confidential
compliance:
data_residency: [EEA]
regulations: [GDPR, ePrivacy]
restrictions:
- no-external-llm
- no-logging
- audit-required
Look at what this gives you.
compliance.regulations: [GDPR] is not free text. It is drawn from a defined vocabulary that maps directly to real regulations. GDPR, NIS2, HIPAA, MiFID2, DORA, EU-AI-Act -- the spec defines these identifiers and their meaning. Unknown values are silently ignored, so you can extend the vocabulary without breaking existing parsers.
compliance.data_residency: [EEA] declares where data may be stored and processed. An agent deployed outside the EEA should refuse to access this unit. The declaration does not enforce this -- KCP is advisory by design -- but it makes the constraint visible, inspectable, and testable.
compliance.sensitivity: confidential uses a four-level classification aligned with ISO 27001: public, internal, confidential, restricted. Every unit inherits the root sensitivity unless it declares its own.
compliance.restrictions is a list of processing constraints. no-external-llm means the content must not be sent to an externally-hosted language model. audit-required means all access must be logged with sufficient detail for compliance audit. no-logging means the opposite -- the content must not appear in persistent logs. When no-logging and audit-required coexist on the same unit, the unit-level declaration wins. This is intentional: some data needs to be accessed under audit but never persisted.
The critical property of all these fields: an auditor can validate them independently of your application code. They do not need to read your agent's source. They do not need to understand your prompt. They read the manifest, compare it to the regulation, and determine whether the declaration is correct. That separation of concerns is the entire point.
Per-unit overrides mean that a single manifest can contain units at different sensitivity levels. A public README and a confidential customer data schema can coexist in the same knowledge.yaml, each with its own compliance block. The root block provides defaults. The unit block provides specifics. This is the same inheritance model developers already understand from CSS, from configuration, from database migrations.
The Trust and Delegation Layer: Pre-Negotiated Constraints¶
Declaring what regulations apply is only half the problem. The other half: who is allowed to do what, and how deep does the chain of delegation go?
In a multi-agent system, the human authorises an orchestrator. The orchestrator delegates to a sub-agent. The sub-agent may delegate further. Each hop is an opportunity for scope creep -- the original compliance constraint quietly dropping off as the chain extends.
KCP addresses this with two blocks that compose with the compliance declaration:
trust:
audit:
agent_must_log: true
require_trace_context: true
delegation:
max_depth: 2
require_capability_attenuation: true
audit_chain: true
human_in_the_loop:
required: true
approval_mechanism: oauth_consent
delegation.max_depth: 2 means the resource owner is at depth 0, the first agent at depth 1, and one more delegation is permitted. Beyond that, access is denied. This prevents a single compliance review from unknowingly covering five nested agents that the reviewer never contemplated.
require_capability_attenuation: true means each hop in the chain must narrow permissions, never expand them. If the orchestrator has read access to ten fields, the sub-agent can have read access to five. Never eleven.
human_in_the_loop is declared in the manifest. Not decided at runtime. Not left to the orchestrator's judgment. The manifest says: this data requires human approval before an agent accesses it. The approval mechanism is specified -- oauth_consent, uma, or custom with a documentation URL. An agent that encounters required: true must obtain approval through the declared mechanism or refuse to proceed.
trust.audit.require_trace_context: true means agents must include W3C Trace Context headers -- traceparent and tracestate -- on all access requests. This is the same standard used by OpenTelemetry. It means every agent decision, across every delegation hop, can be correlated back to a single trace ID. The compliance unit, the agent action, and the audit log entry all share the same trace context.
This is the "pre-negotiated" pattern. Before any agent runs, the CTO and compliance officer agree on the delegation matrix: what autonomy level applies to each task-type and data-category combination. The agent does not decide its own constraints. It reads them from the manifest. The manifest is versioned. The version is logged.
Per-unit delegation overrides tighten the root defaults. A patient records unit can declare max_depth: 1 and human_in_the_loop.required: true even when the root manifest allows max_depth: 3. The rule: per-unit delegation must never relax root constraints. It can only tighten them.
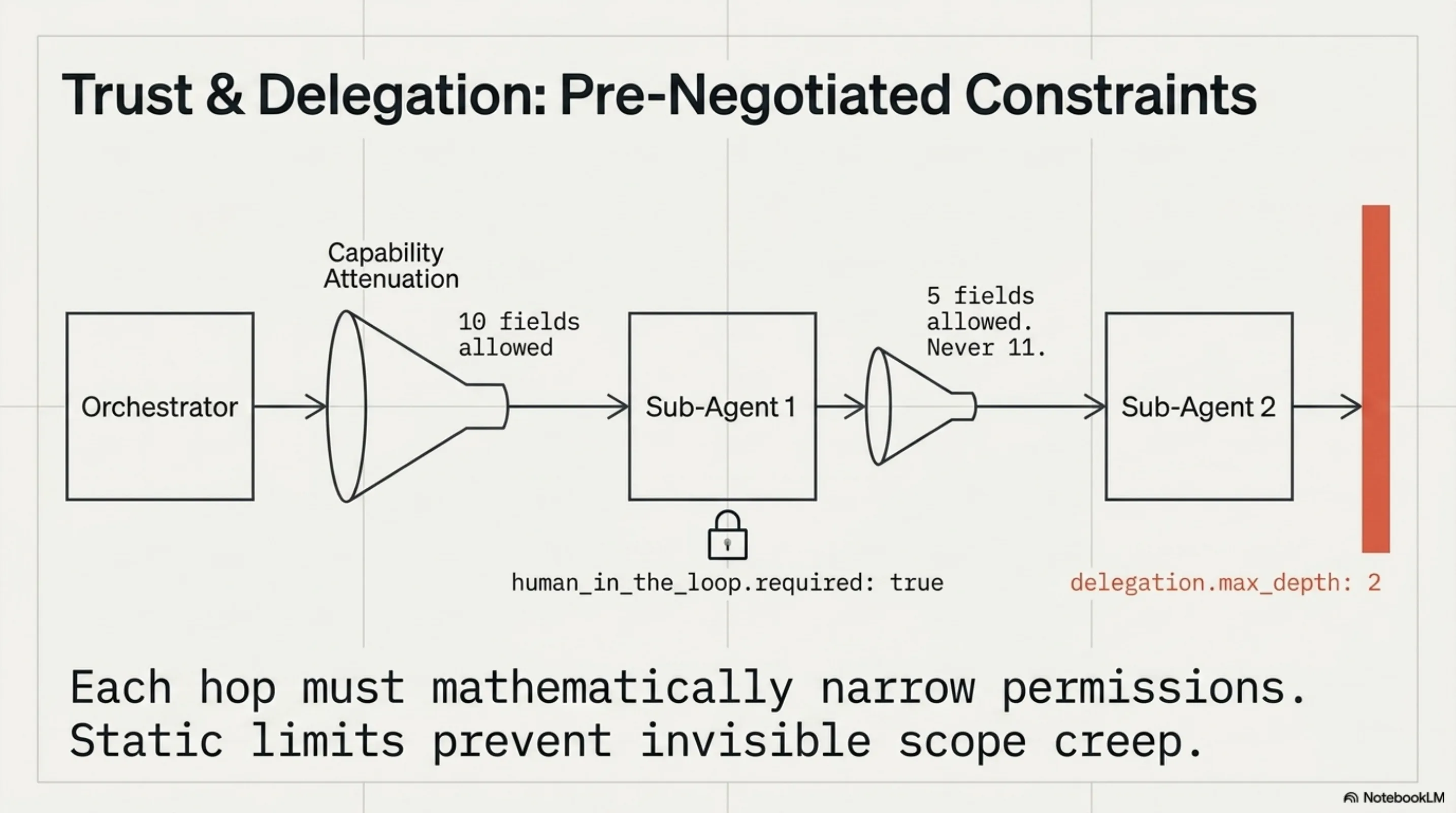 Each hop in the delegation chain must mathematically narrow permissions. Static limits in the manifest prevent invisible scope creep at runtime.
Each hop in the delegation chain must mathematically narrow permissions. Static limits in the manifest prevent invisible scope creep at runtime.
Programmatic Evaluators: The Missing Layer¶
Everything so far is declaration. Declarations are necessary but not sufficient. You need enforcement.
This is where most compliance approaches stop. KCP provides the declaration layer. Your runtime provides the enforcement layer. But between declaration and enforcement, there is a third layer that almost nobody builds: programmatic evaluation.
Consider the difference.
Prompt-based "compliance":
System: You must comply with GDPR data minimization principles
when accessing customer data. Only access fields that are
strictly necessary for the task.
This is invisible to auditors. It cannot be tested. It cannot be versioned independently of the agent. It produces no evidence that it was followed. If the regulation changes, you search-and-replace across system prompts and hope you found them all.
KCP evaluator pattern:
// evaluator: field_access_check
import { AgentAction, KCPUnit, EvaluatorResult } from "./types";
export function evaluate(
action: AgentAction,
unit: KCPUnit
): EvaluatorResult {
const allowedFields = unit.compliance.declared_fields;
const accessedFields = action.fields_read;
const violations = accessedFields.filter(
(f) => !allowedFields.includes(f)
);
return {
passed: violations.length === 0,
violations,
unit_id: unit.id,
evaluator_version: "1.2.0",
evaluated_at: new Date().toISOString(),
};
}
Twenty lines of TypeScript. This evaluator does one thing: it compares the fields the agent actually accessed against the fields the KCP unit declares as permitted. If the agent read phone but the unit only allows email and name, the evaluator returns passed: false with the specific violation.
There are several properties of this pattern that matter more than the code itself.
The evaluator is code, not LLM judgment. It does not ask a model whether the access "seems reasonable." It compares two lists. Pass or fail. Binary. Deterministic. The kind of thing that survives a compliance audit because there is nothing to interpret.
The evaluator runs as a gate, not a review. You wire it into your agent pipeline -- before the action completes, or as a pre-flight check before it starts. If it fails, the action is blocked. Not reviewed later. Blocked now.
The evaluator is versioned independently of the agent. When the regulation changes -- when GDPR gets a new interpretation, when your DPO decides that phone is no longer a permitted field -- you update the evaluator. You update the KCP unit's declared_fields. You do not touch the agent's code. You do not touch the system prompt. The declaration layer absorbs the change.
The evaluator can be tested with unit tests. The KCP unit is the test fixture. You write a test: "Given this unit with these declared fields, and an action that accesses these other fields, the evaluator should return passed: false with these violations." Standard testing. Standard CI. Standard code review. No special tooling.
import { evaluate } from "./field_access_check";
import { test, expect } from "vitest";
test("rejects access to undeclared fields", () => {
const unit = {
id: "gdpr_data_minimisation",
compliance: {
declared_fields: ["email", "name"],
},
};
const action = {
fields_read: ["email", "name", "phone"],
};
const result = evaluate(action, unit);
expect(result.passed).toBe(false);
expect(result.violations).toEqual(["phone"]);
});
The evaluator can be written in TypeScript, Python, Java -- whatever your runtime supports. The KCP unit is YAML. The evaluator reads the unit, receives the agent action, returns a result. The boundary is clean.
This is the layer most teams skip. They have declarations (maybe). They have logs (usually). They do not have the 20-line function that connects the declaration to the log entry with a binary result. That function is the difference between "we have a policy" and "we can prove the policy was followed for this specific action at this specific time."
 Left: prompt-based compliance — fuzzy, invisible, unversioned. Right: the KCP evaluator pattern — deterministic, binary, CI/CD testable.
Left: prompt-based compliance — fuzzy, invisible, unversioned. Right: the KCP evaluator pattern — deterministic, binary, CI/CD testable.
The Audit Trail: Linking Actions to Rules¶
Every evaluator produces a result. Every result gets logged. The log entry links the action, the rule, and the outcome:
{
"action_id": "act_8f4e2a",
"agent_id": "customer-onboarding-agent/v2.3",
"timestamp": "2026-05-30T09:14:22Z",
"kcp_unit_applied": "gdpr_data_minimisation",
"evaluator_id": "field_access_check",
"evaluator_version": "1.2.0",
"fields_accessed": ["email", "name"],
"fields_declared": ["email", "name", "phone"],
"passed": true,
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"model": "claude-sonnet-4-6",
"legal_basis": "legitimate_interests"
}
Read this entry from the auditor's perspective.
kcp_unit_applied: "gdpr_data_minimisation" tells the auditor which rule governed this action. They can look up that unit in the manifest. They can see its compliance block, its sensitivity level, its data residency constraint, its restrictions. The manifest is versioned. The version at the time of the action is determinable from source control.
evaluator_id and evaluator_version tell the auditor which code evaluated the action. They can review the evaluator's source. They can run its test suite. They can confirm that evaluator version 1.2.0 was the one deployed at the time of this action.
fields_accessed and fields_declared show the raw data: what the agent did versus what it was allowed to do. The evaluator's judgment is reproducible -- anyone can compare these two lists and confirm that passed: true is correct.
trace_id is a W3C Trace Context identifier. If this action was part of a larger request chain -- an API call that triggered an orchestrator that delegated to this agent -- the trace ID correlates every step. The auditor does not need to reconstruct the chain from timestamps and guesswork. The distributed trace already exists.
model: "claude-sonnet-4-6" records which model was used. If a model version is later found to have a relevant deficiency, you can query your audit log for all actions taken by that model version and re-evaluate them.
Now consider what happens when something goes wrong.
The evaluator returns passed: false. The log records the violation. The violation names the specific field that was accessed outside the declaration. The unit ID points to the rule. The evaluator version points to the code. The trace ID points to the full request context.
This is not a dashboard. It is a ledger. Each entry links action to rule to result. The logging does not prevent wrong decisions. It makes wrong decisions expensive to hide -- because the action is recorded, the rule is recorded, and the evaluator's verdict is recorded. If the evaluator was wrong because the unit was stale, the validated date on the unit tells you when it was last reviewed. You know exactly where the failure originated.
One honest limitation: if a regulation changes and you have not updated the evaluator, the log will faithfully record passed: true for an action that should have failed. The record is complete. The action is wrong. This is why evaluator versioning matters. This is why the validated date on KCP units matters. Logging does not prevent errors. It prevents undetected errors.
 Each log entry carries four independent links: the rule (KCP unit), the code (evaluator version), the data (fields accessed vs declared), and the context (W3C trace ID). Any auditor can independently verify that
Each log entry carries four independent links: the rule (KCP unit), the code (evaluator version), the data (fields accessed vs declared), and the context (W3C trace ID). Any auditor can independently verify that passed: true was mathematically correct.
Getting Started: One Unit, One Evaluator, One Log Entry¶
You do not need to model your entire regulatory framework to start. The adoption path is intentional: start small, prove the pattern, then scale.
Step 1: Pick your highest-risk agent action. The one that touches personal data, makes a financial decision, or accesses something a regulator cares about. One action.
Step 2: Identify which regulation or policy applies. GDPR Article 6? An internal data handling policy? Even a single applicable rule is enough. You can expand later.
Step 3: Write a KCP unit with the compliance block. One unit. Declare the sensitivity level, the applicable regulations, the data residency constraint, and the restrictions. This takes five minutes. It is YAML.
units:
- id: customer_data_access
path: policies/customer-data.md
intent: "What fields may the agent read from the customer record?"
sensitivity: confidential
compliance:
data_residency: [EEA]
regulations: [GDPR]
restrictions:
- no-external-llm
- audit-required
Step 4: Write the evaluator. TypeScript, Python, Java -- whatever your runtime speaks. Twenty to fifty lines. It reads the KCP unit, receives the agent action, and returns pass or fail with the specific violation.
Step 5: Wire the evaluator result to your existing observability stack. OpenTelemetry span, structured log entry, whatever you already use. The evaluator result is JSON. It fits anywhere.
Step 6: You now have one auditable agent action. One unit, one evaluator, one log entry that links the action to the rule to the result. When the auditor asks "how do you know this agent followed the regulation?" you have an answer that is not "we told it to in the system prompt."
Scale from there. Add units as you identify more regulated actions. Add evaluators as you identify more rules. The manifest grows. The evaluator suite grows. The audit trail grows. Each addition is incremental.
Do not try to model your entire regulatory framework in week one. The adoption gradient -- Stage 1 equals one unit and three fields -- is intentional. The goal is to prove the pattern on one action, get the audit trail working, and then expand. The infrastructure pays for itself the first time an auditor asks a question and you answer it with a log entry instead of a meeting.
What this looks like at production scale: Mynder runs this pattern across 85+ Norwegian companies, 6 regulatory frameworks, with a batch evaluation strategy that processes entire documents in a single LLM call. The average GDPR trust score across the sample was 29.7/100. 88% of companies were missing required third-country transfer safeguards. The compliance gaps were not theoretical. They were invisible until the infrastructure could see them.
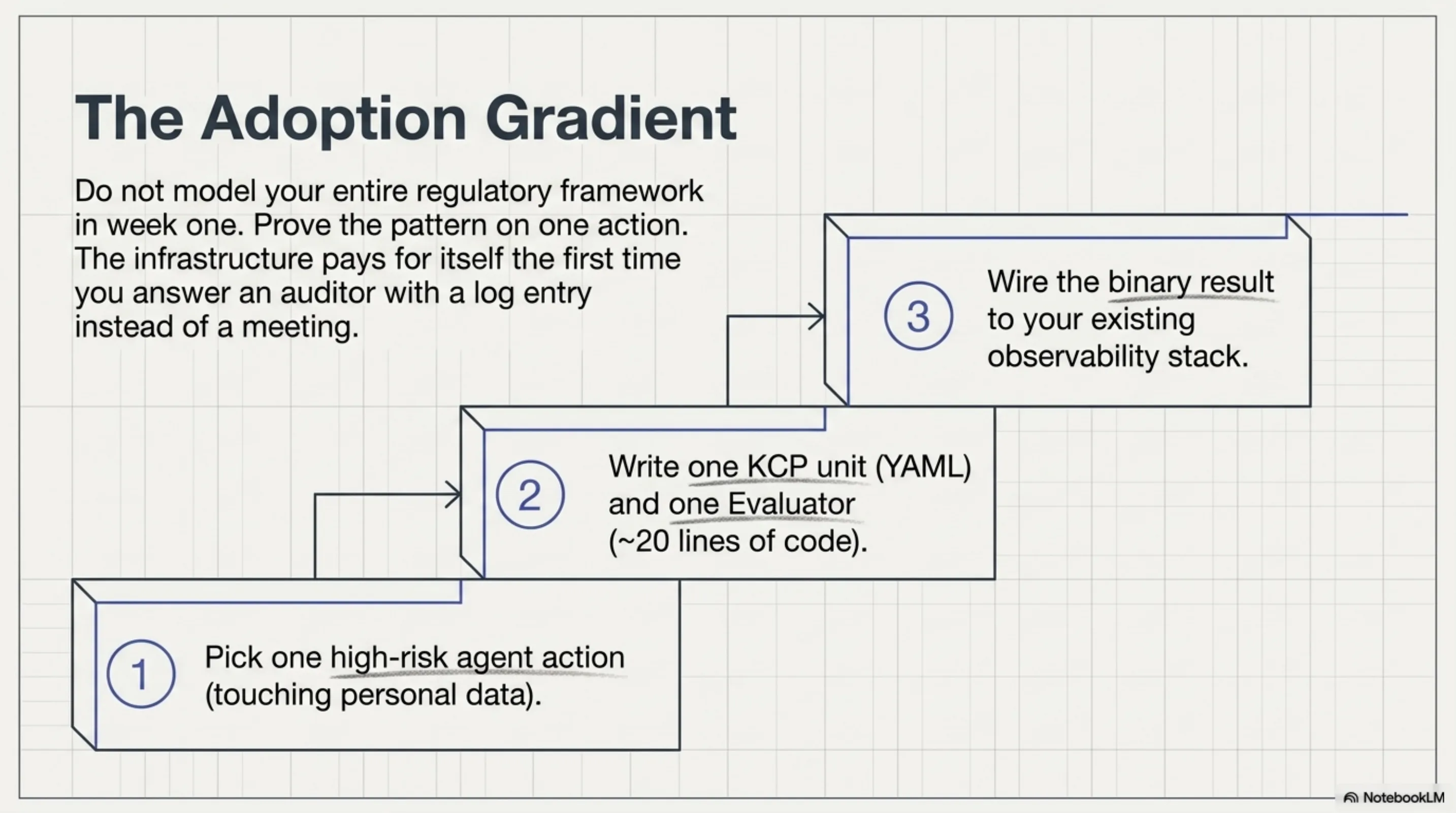 Three steps: one high-risk action, one KCP unit + evaluator (~20 lines), wire the binary result to your observability stack. The infrastructure pays for itself the first time an auditor asks a question.
Three steps: one high-risk action, one KCP unit + evaluator (~20 lines), wire the binary result to your observability stack. The infrastructure pays for itself the first time an auditor asks a question.
The architectural choice matters. A naive implementation evaluates each clause in a separate LLM call. Twelve GDPR clauses means twelve round-trips, twelve token budgets, twelve latency delays. Mynder's batch approach processes all clauses in a single structured JSON call, returning twelve evaluations at once. The measured result: 2.6x faster (6.1s vs 16.1s average latency), 7.9x token reduction (2,708 vs 21,460 tokens per document), 12x fewer API calls. Quality is within noise — 2.59/3 batch vs 2.63/3 per-clause. No accuracy trade-off. Just architecture.
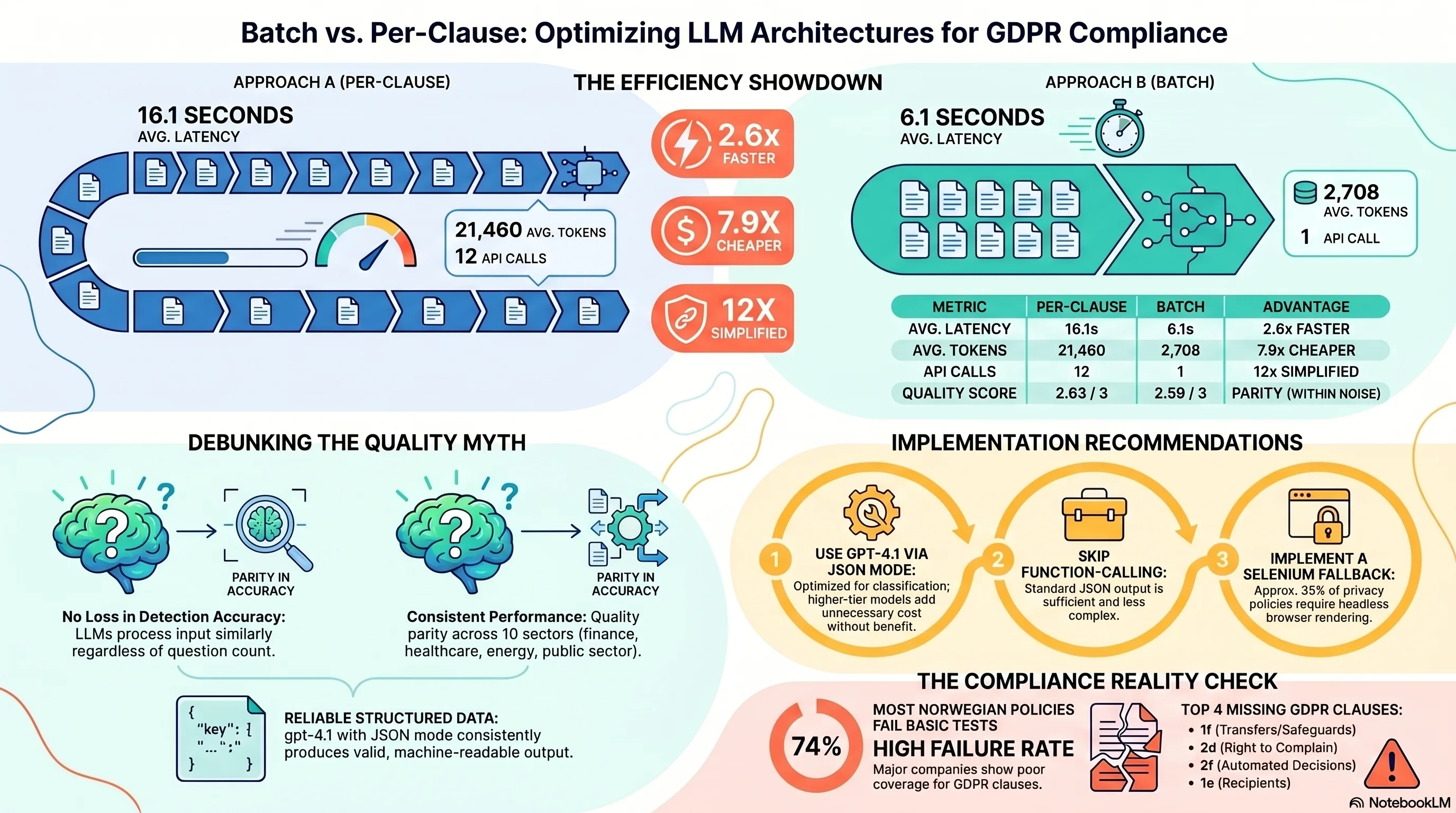 Batch evaluation: one API call per document, all clauses evaluated together. The per-clause loop is simpler to implement but does not scale.
Batch evaluation: one API call per document, all clauses evaluated together. The per-clause loop is simpler to implement but does not scale.
The Infrastructure Mindset¶
You do not put your database schema in comments. You put it in migrations. You do not put your API contract in a wiki page. You put it in an OpenAPI spec. You do not put your infrastructure in a runbook. You put it in Terraform.
Why would you put your compliance policy in a system prompt?
The answer, usually, is that nobody has built the infrastructure layer for it yet. System prompts were the only tool available, so teams used them. They are better than nothing. But they are the wrong layer for something that needs to be versioned, tested, audited, and evaluated independently of the agent that consumes it.
KCP is that infrastructure layer. The compliance block declares what regulations apply. The trust block declares what audit trail is required. The delegation block declares how deep the agent chain goes and where humans must intervene. The evaluator -- your code, in your language, in your CI pipeline -- connects the declaration to the action and produces a binary result. The audit log records all of it.
Regulations change. When they do, you update the KCP unit and the evaluator. You do not touch the agent's code. You do not rewrite system prompts. The declaration layer absorbs the change. The evaluator version increments. The audit trail records the transition.
This is not a compliance feature. It is infrastructure. The same boring, unglamorous, essential infrastructure that makes everything else trustworthy.
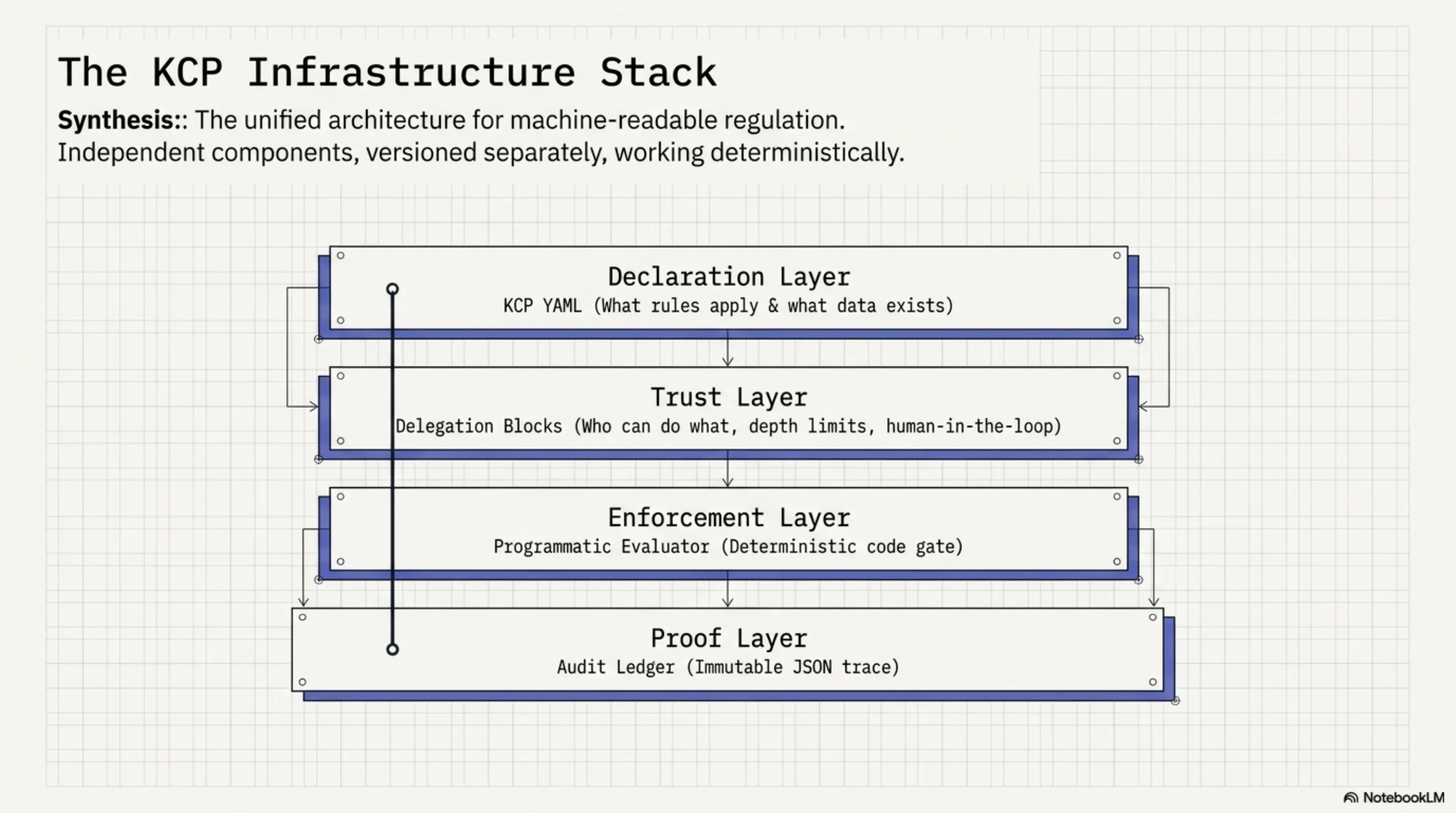 Four independent, versioned layers: Declaration (KCP YAML) → Trust (delegation blocks) → Enforcement (programmatic evaluator) → Proof (audit ledger). Each layer can be updated without touching the others.
Four independent, versioned layers: Declaration (KCP YAML) → Trust (delegation blocks) → Enforcement (programmatic evaluator) → Proof (audit ledger). Each layer can be updated without touching the others.
Boring passes audit.

The KCP spec is Apache 2.0: github.com/Cantara/knowledge-context-protocol
The compliance-audit example, including a GDPR Article 30 ROPA generator that reads from KCP manifests, is in the repo under examples/compliance-audit/.
Series: Knowledge Context Protocol
← AI agents forget everything. That's a choice, not a constraint. · Part 26 of 45 · The Law Is Also Knowledge. Package It. →