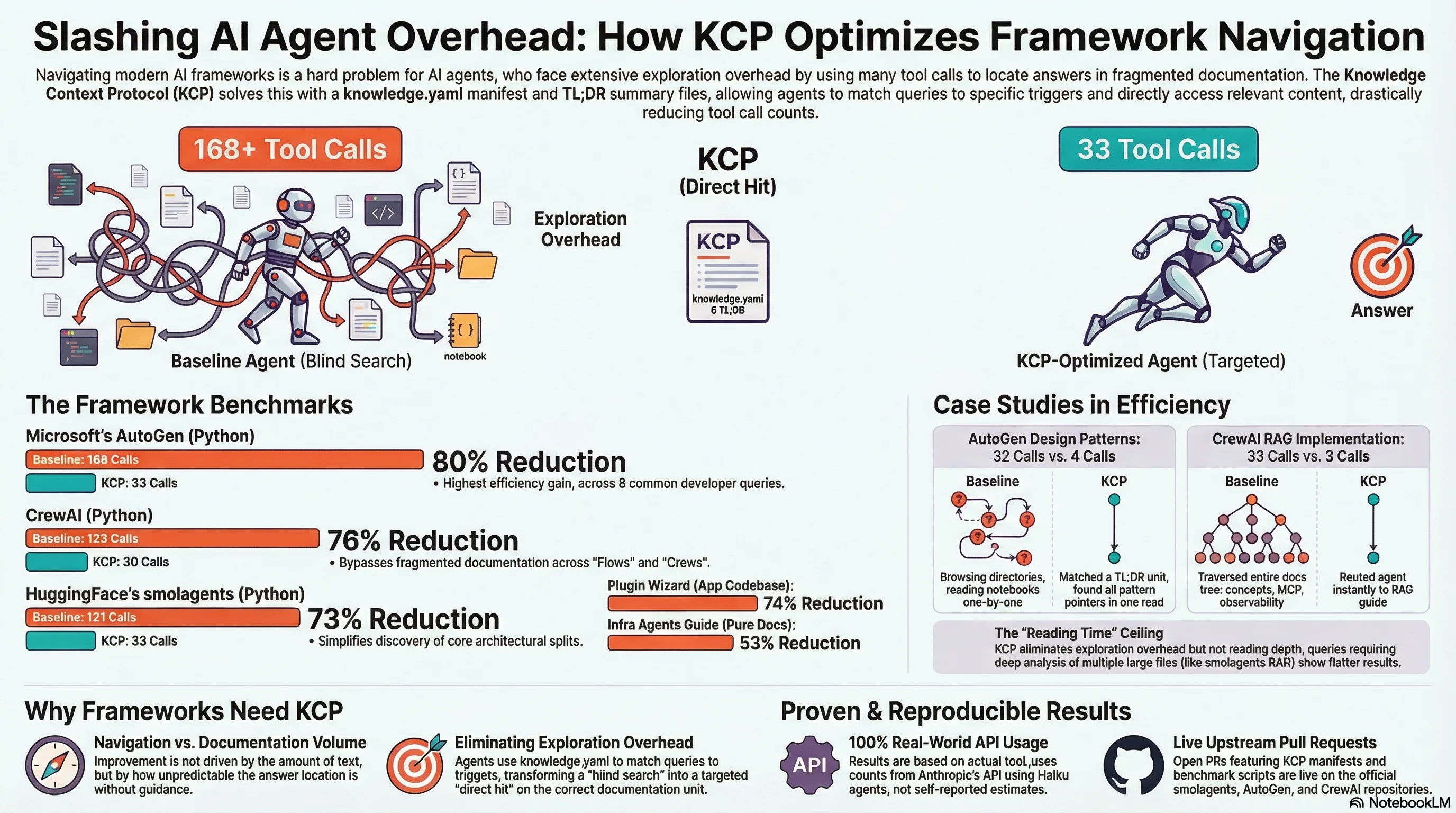
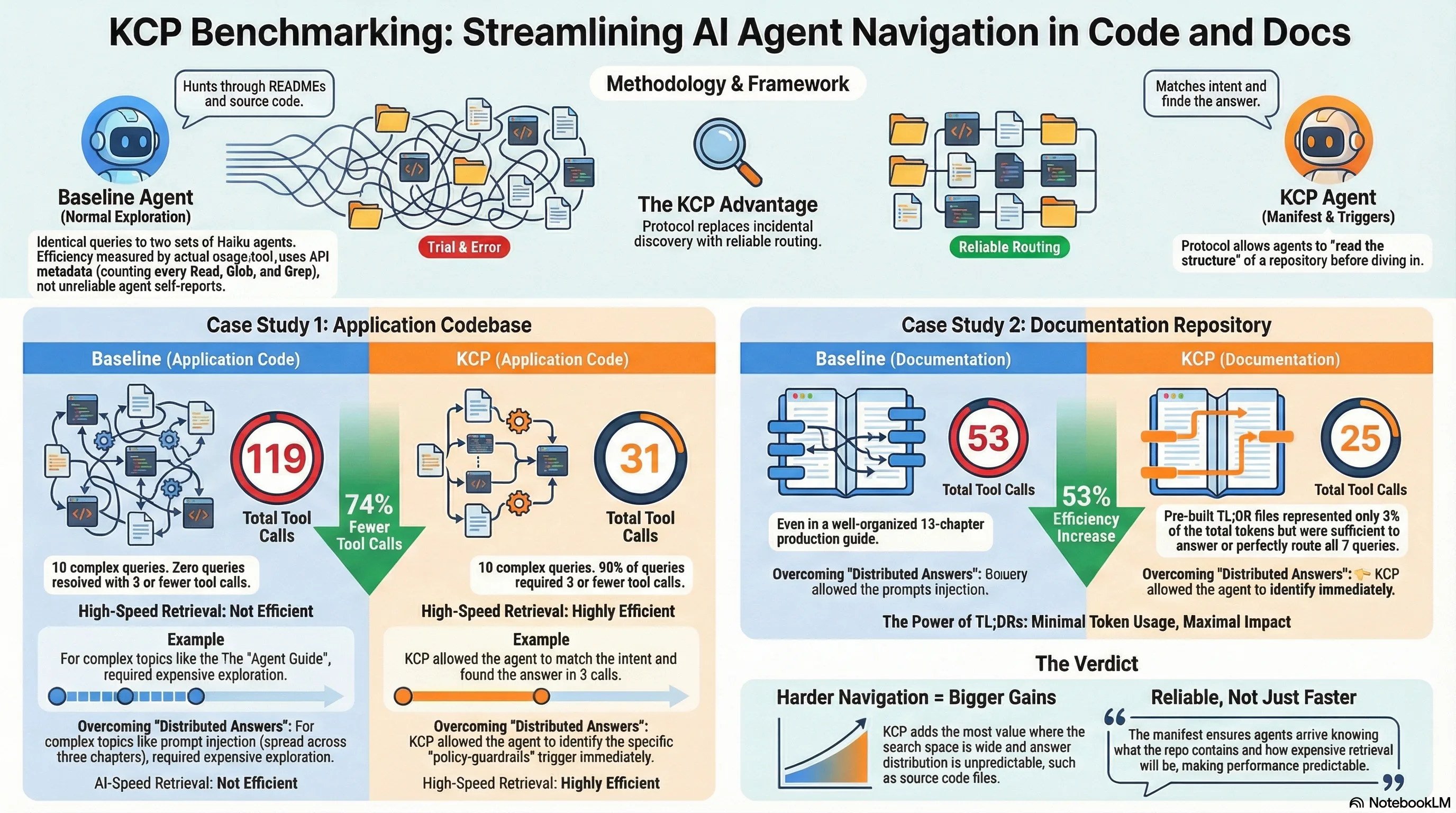
kcp-memory: Give Claude Code a Memory
Every Claude Code session starts the same way. The context window is empty. The agent has no recollection of what it did yesterday, which files it touched last week, or how it solved a similar problem three sessions ago. Each session is day one.
That is not a limitation of the model. It is a missing infrastructure layer.
Today we are releasing kcp-memory v0.1.0: a standalone Java daemon that indexes
~/.claude/projects/**/*.jsonl session transcripts into a local SQLite database with
FTS5 full-text search. Ask it "what was I working on last week?" and it answers in
milliseconds.
Update (same day — v0.2.0): kcp-memory now ships with tool-level granularity.
kcp-commands v0.9.0 writes every Bash tool call to
~/.kcp/events.jsonl; kcp-memory ingests that stream and makes individual commands
searchable via kcp-memory events search. Session-level and tool-level memory in one
daemon, one database, zero additional dependencies.
Update (same day — v0.3.0): kcp-memory now ships as an MCP server. Run
java -jar ~/.kcp/kcp-memory-daemon.jar mcp — registered in mcpServers in
~/.claude/settings.json — and Claude Code can call kcp_memory_search,
kcp_memory_events_search, kcp_memory_list, and kcp_memory_stats inline during a
session, without leaving the context window.
Update (same day — v0.4.0): Two new MCP tools close the remaining gaps.
kcp_memory_session_detail(session_id) returns full session content — user messages,
files touched, tools used — completing the search → read flow. kcp_memory_project_context()
reads PWD from the process environment and returns the last 5 sessions and 20 tool events
for the current project, with no query needed. Call it at the start of every session and
Claude immediately knows what it was doing here last time.