Your AI Has One Layer. It Needs Four.¶
The debate is "RAG or knowledge graphs?" The answer is neither — and both. Most teams pick one retrieval approach and stop. The interesting question is which layer they are missing, and what blind spot that creates.
The question every agent faces¶
Before an AI agent can reason about your codebase, it has to answer a prior question: what do I know, and how do I find what I don't?
This sounds trivial. It is not. The answer determines whether the agent traces a dependency chain in three tool calls or thirty-two. Whether it cites a date that exists or invents one that sounds right. Whether it understands how your modules connect or treats your codebase as a bag of files.
Most teams solve this by picking an approach — usually RAG, sometimes a knowledge graph, occasionally just stuffing everything into the context window — and treating it as sufficient. That single-layer choice creates a blind spot. The blind spot determines where the agent fails. And because the agent fails confidently, you often do not notice until the damage is done.
The one-layer mistake¶
The industry conversation frames this as a competition. RAG vs. knowledge graphs. Vector search vs. structured retrieval. Embeddings vs. explicit relationships. Conference talks present benchmarks showing one approach outperforming the other on selected tasks.
The benchmarks are real. They are also misleading, because each approach answers a fundamentally different question. Choosing between them is like choosing between a dictionary and a map. They are not competing tools. They are different layers of the same problem.
Here is what each layer actually does, where it works, and where it breaks.
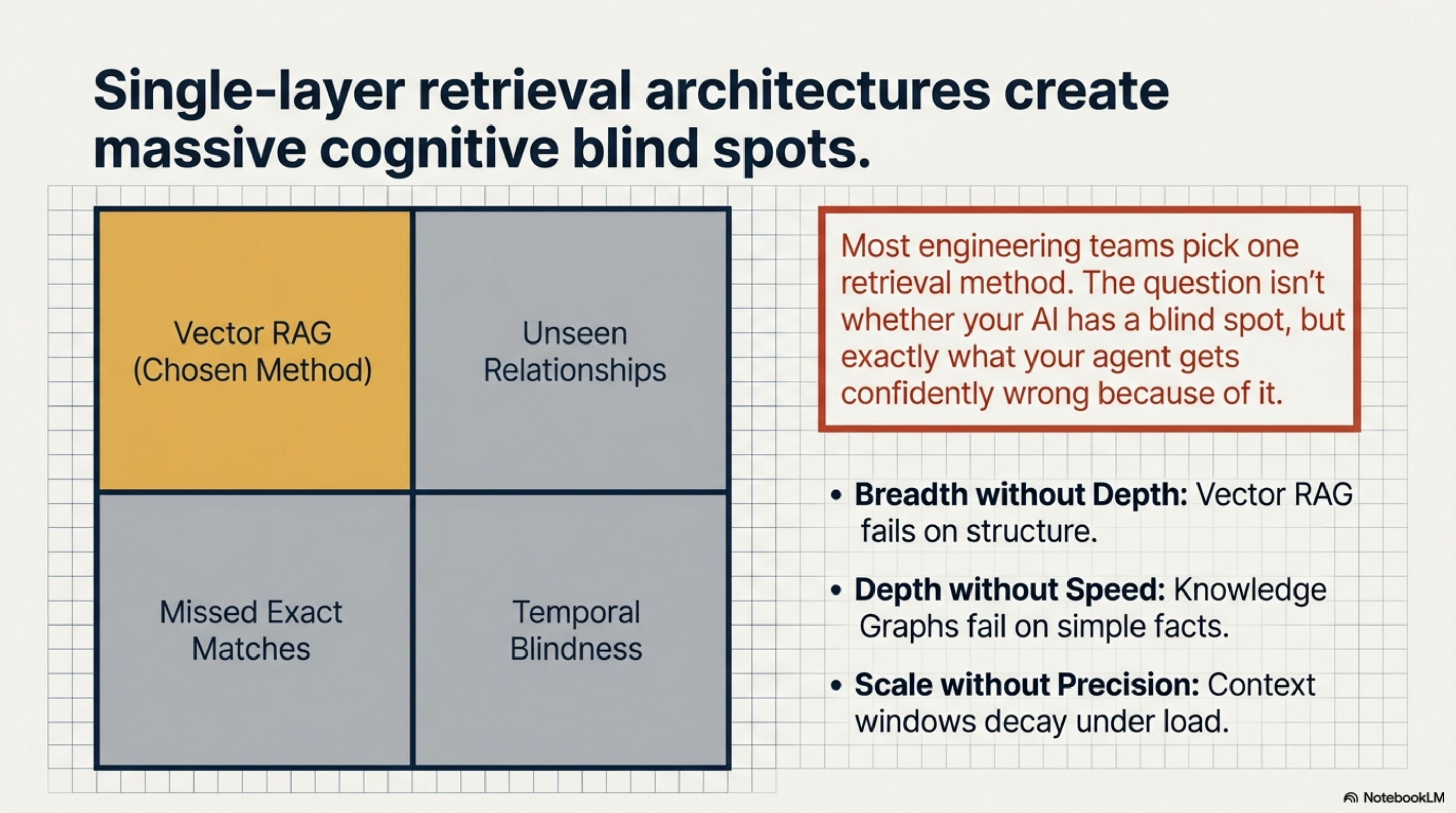
The honest breakdown¶
Keyword and BM25 search answers: does this exact term exist somewhere?
This is the foundation that everyone underestimates. Inverted index, term frequency, boolean matching. It is fast, deterministic, and requires zero machine learning infrastructure. When you know the function name, the config key, the error string — keyword search finds it in milliseconds.
Where it breaks: synonyms, concepts, relationships. Searching for "authentication" will not find a module called TokenValidator. Searching for "what changed last week" returns nothing, because that is a temporal query, not a term.
RAG (vector/semantic search) answers: what is conceptually similar to this query?
Embed your documents into vectors, embed the query, find the nearest neighbors. RAG bridges the synonym gap — it finds TokenValidator when you search for "authentication" because the embeddings are close in vector space. For unstructured text at scale, this is genuinely powerful.
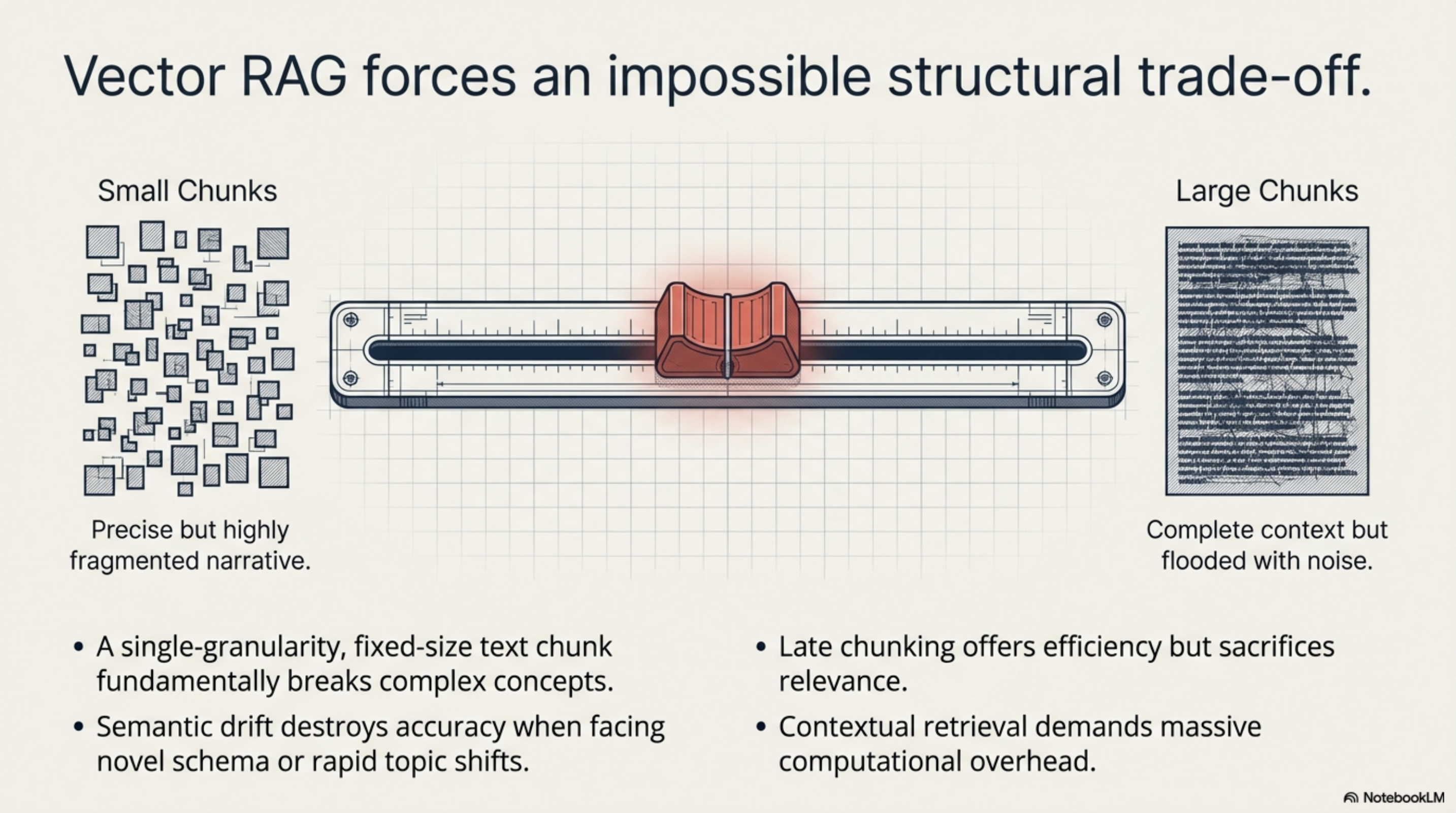
Where it breaks: relationships, structure, temporal queries, exact recall. RAG finds documents that sound relevant. It cannot answer "what depends on this module?" or "what changed since Tuesday?" or "show me every caller of this method." It also suffers from chunking problems — split a document wrong and the retrieved fragment loses its meaning. Research from Springer and arXiv documents the structural trade-off: small chunks retrieve precisely but fragment context; large chunks preserve context but introduce noise. There is no chunk size that solves both.
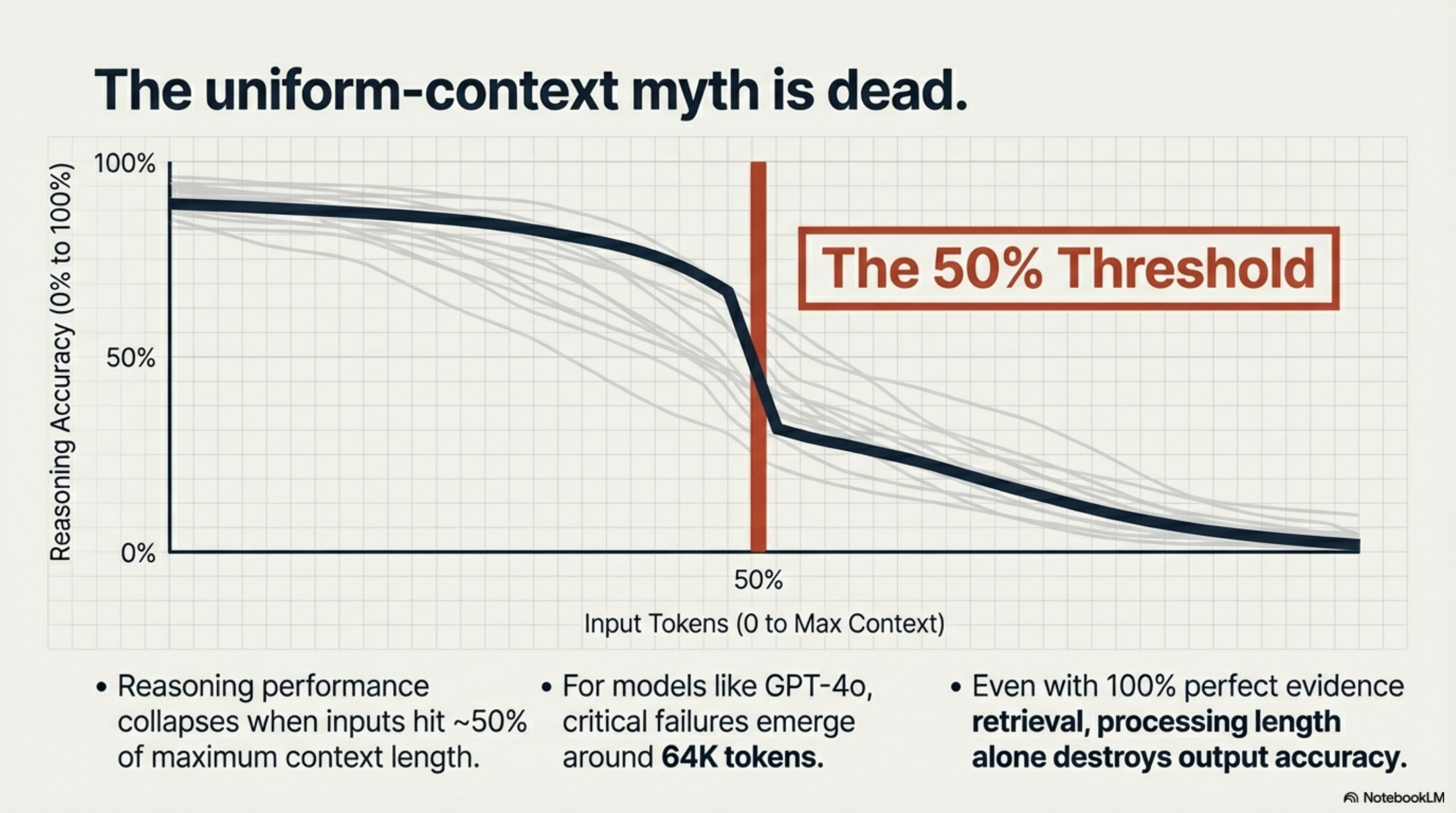
And then there is the lost-in-the-middle problem. Even when RAG retrieves the right documents, LLMs systematically under-weight information in the middle of the context window. Chroma Research tested 18 models and found that accuracy decays progressively as prompts grow — they call it "context rot." Adding more retrieved documents does not help linearly. Past a threshold, it actively hurts.
Property knowledge graphs answer: how do these entities connect?
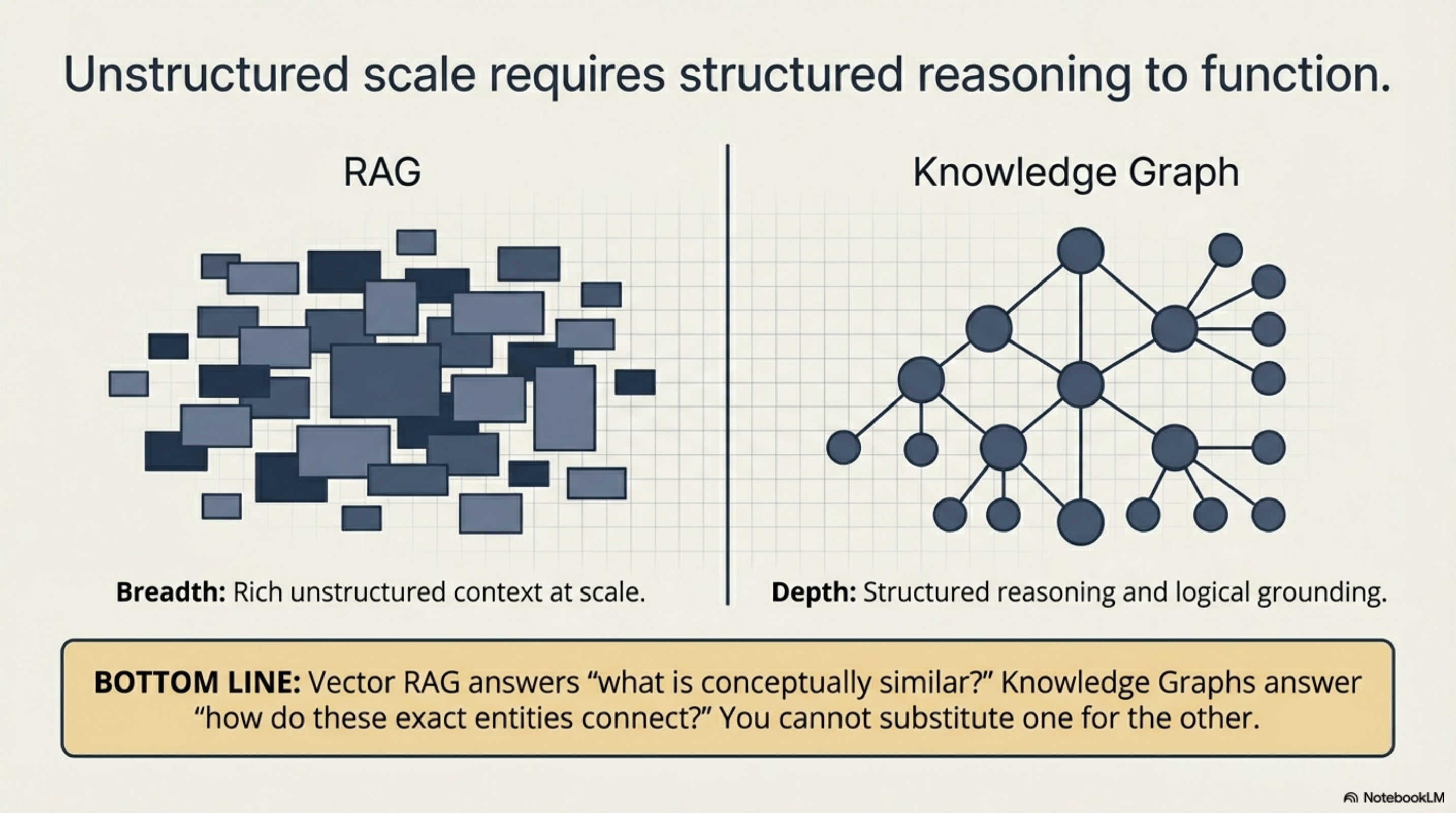
Explicit nodes, explicit edges, traversable relationships. A knowledge graph can answer multi-hop questions that RAG cannot even represent: "Which team owns the service that depends on the library that had a CVE last month?" The Diffbot benchmark showed GraphRAG outperforming vector RAG 3.4x on average for queries requiring entity relationships, with traditional vector RAG dropping to 0% accuracy when queries involved more than five entities.
Where it breaks: knowledge engineering cost. Someone has to design the schema, extract entities, map relationships, and maintain all of it as the underlying reality changes. The enterprise knowledge graph literature is blunt: many organizations build successful pilots but few deploy enterprise-scale graphs that deliver sustained ROI, because maintenance cost scales with the rate of change in the domain. And you still have to choose between property graphs and RDF — speed vs. semantic richness — before you write a single query.

GraphRAG (hybrid) answers: semantic similarity plus graph structure.
Microsoft's GraphRAG and similar approaches combine vector retrieval with knowledge graph traversal. The system identifies relevant entities through semantic search, then walks the graph to gather connected context. For multi-hop reasoning across large corpora, this is the current state of the art.
Where it breaks: it still needs a schema. It still needs entity extraction pipelines. Real-time updates are expensive — studies show a 16.6% accuracy drop for time-sensitive queries because re-indexing the graph is costly. And the GraphRAG-Bench evaluation found that GraphRAG frequently underperforms vanilla RAG on straightforward factual queries. The overhead is only justified for complex, relationship-heavy questions.
Context stuffing answers: what if we just put everything in the prompt?
It works at toy scale. At production scale — 1,000+ files, multiple repositories, months of history — it collapses. Research from ACL 2025 showed that even with perfect retrieval, LLM performance degrades as input length increases. Performance issues emerge at roughly 50% of the maximum context length. Context stuffing is not a strategy. It is the absence of one.

Where Synthesis fits — and where it does not¶
Synthesis is the tool we built when our AI-augmented development workflow generated 691 files per day and we could not find anything. It takes a different position in this landscape than any of the approaches above.
Synthesis is not a vector database. It does not do semantic similarity search by default — if your code says auth and you search for "authentication," you need to know to search for both. That is a real limitation. Embeddings are on the roadmap but not shipped.
What Synthesis does is integrate layers that are usually separate:
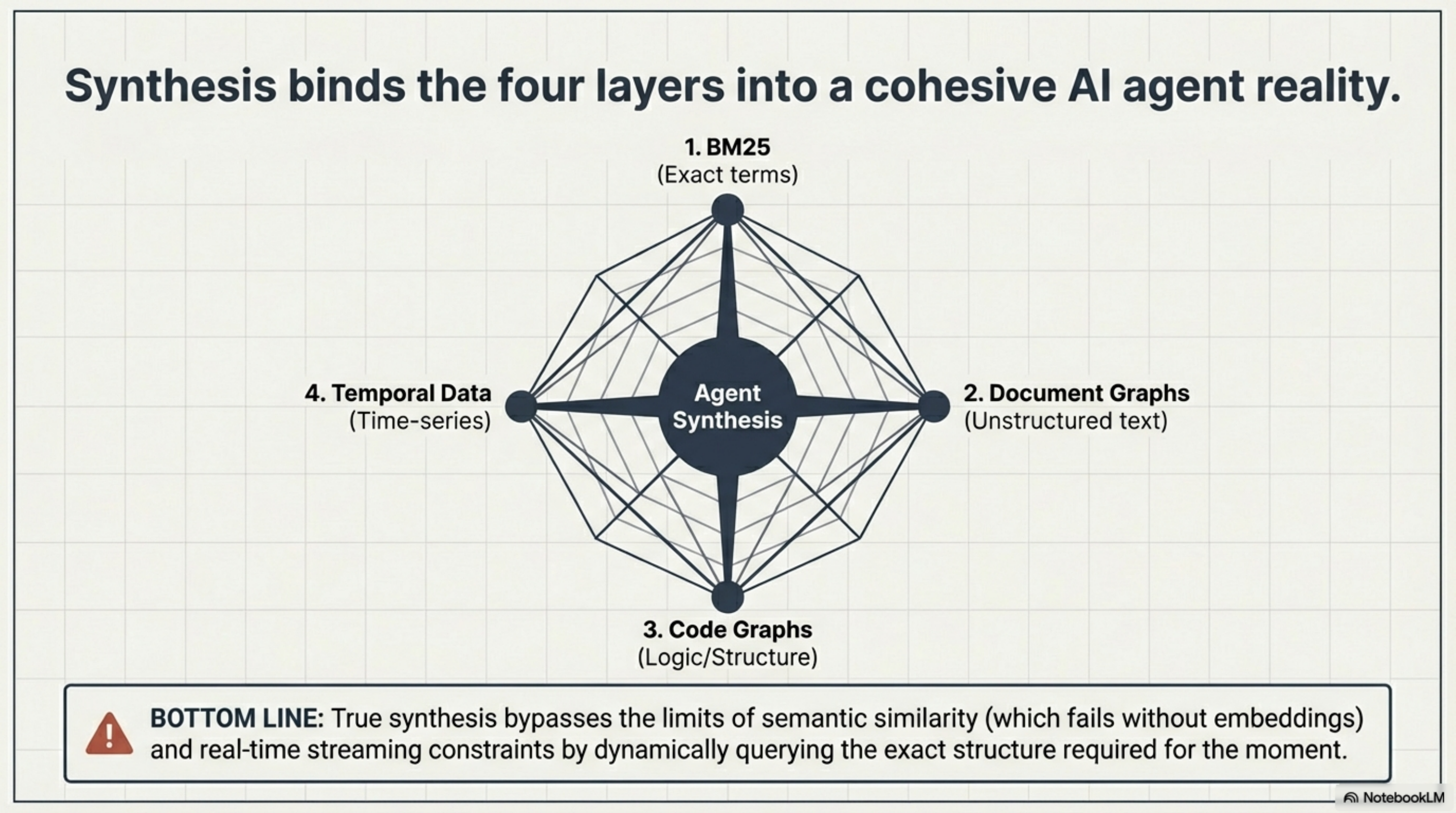
Full-text search (Lucene). Sub-second keyword and phrase search across code, docs, PDFs, configs, media metadata. 36,000+ files indexed at 200-300 files per second. This is the BM25 layer — fast, deterministic, zero ML infrastructure required.
Code dependency graph. Import analysis, module dependencies, bi-directional relationship tracking. "What depends on this file? What breaks if I change it?" This is the structural layer that code gets but knowledge usually does not. In our benchmark, reconstructing a module dependency graph took 32 shell commands with standard tools. With Synthesis via MCP, it took 2 tool calls — a 69% reduction.
Document knowledge graph. This is the layer we built most recently, and the one that makes the architecture unusual. Synthesis extracts entities from AI-generated directory summaries, matches them across the workspace, and creates implicit edges with confidence scores. Two directories that both discuss "temporal analytics" get connected — not because someone declared the relationship, but because the content makes it obvious. Cross-references found in markdown files become explicit edges. And you can declare relationships manually with a related: field when the automation misses something.
The result: our main workspace went from zero virtual links to 11,777 in a single engineering session. Entity-match edges (9,010) plus cross-reference edges (2,767), covering 542 directories. No schema design. No knowledge engineering pipeline. The graph emerged from content that already existed.
Temporal tracking. File movement detection, changelogs, daily snapshots. "What changed since last Tuesday?" is a first-class query. This is the layer that almost no retrieval system provides, and the one that prevents the temporal confabulation problem — where an agent invents a plausible date because it has no temporal signal to extract.
Tightness metrics. Edges divided by possible edges, computed per sub-workspace. A tightness of 0.10 tells you that 315 directories have sparse connections — fragmented organizational memory. That number is actionable: it points to where AI agents will struggle to connect context.
What Synthesis does NOT do well, and I want to be specific:
- Semantic similarity. Without embeddings, it cannot find "authentication" if the code says
authunless you search for both terms. This matters for natural-language discovery tasks. - Natural language Q&A without an AI layer. Synthesis is infrastructure, not a chatbot. The
askandexplaincommands use Claude's API on top of the index. Without that AI layer, you get search results, not answers. - Deep ontological reasoning. A properly modeled RDF knowledge graph with formal ontologies can do inference that Synthesis cannot — class hierarchies, transitive closure, logical entailment. Synthesis trades ontological depth for zero-schema simplicity.
- Real-time streaming. The index updates on scan, not on file save. There is a freshness gap measured in minutes. For most workflows this is invisible. For real-time incident response, it is not.
The missing layer argument¶
The pattern I see across teams adopting AI tools:
Teams that deploy RAG get semantic search but no structure. They can find documents that sound relevant but cannot answer "what does this connect to?" or "what changed last week?" They hit the chunking wall, the lost-in-the-middle wall, and the relationship wall — all at once — when queries get complex.
Teams that build knowledge graphs get structure but pay an engineering tax. The schema needs design, the entities need extraction, the graph needs maintenance. It works for stable, well-modeled domains. It struggles with the rate of change in a development organization where the codebase shifts daily.
Teams that stuff context get simplicity but hit a ceiling. Research confirms what practitioners already know: more tokens in the prompt does not mean more understanding. Past a threshold, it means less.
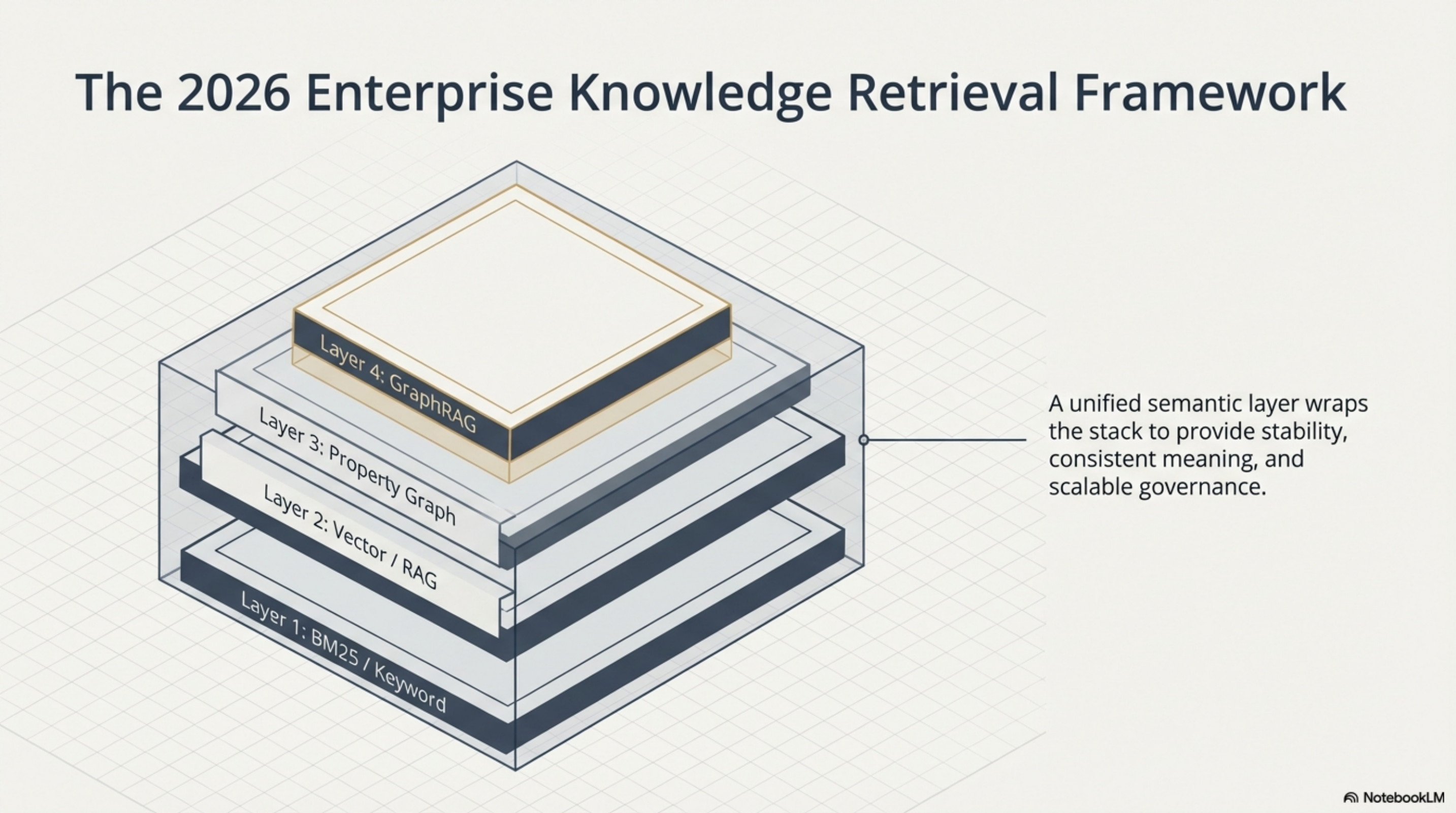
What is missing in most AI agent setups is not a better version of any single layer. It is the layer underneath — a local, structure-aware, temporally-tracked index of everything the agent needs to reason about, covering both code and documents, that does not require schema design and updates automatically when you scan.
That is what Synthesis is trying to be. Not a replacement for RAG's semantic layer. Not a replacement for property graphs in domains where formal ontologies matter. The foundation layer — the thing that has to exist before the other layers are useful. The graph that emerges from your content rather than being imposed on it.
Our MCP benchmark showed 35% fewer tool calls when agents had native access to this layer. The knowledge graph session showed that the graph can go from zero to 11,777 edges in a day without schema design. The temporal confabulation finding showed that even one missing layer — temporal tracking — causes failures that better models cannot fix.
None of this means Synthesis is sufficient on its own. It means the debate about which single retrieval layer to adopt is the wrong debate. The question is: which layer are you missing? And what is your agent getting confidently wrong because of that gap?

Synthesis is the knowledge infrastructure tool described throughout this series. The knowledge graph, temporal tracking, and MCP integration are all shipping.
Knowledge Infrastructure Series¶
This post is the capstone of a series exploring what happens when you treat AI agent knowledge as an engineering problem rather than a prompt engineering problem. Each post below documents a specific finding — a benchmark, a failure mode, an engineering session — that shaped the four-layer framework presented above.
How the posts connect to this framework
The four-layer argument did not start as a framework. It started as a collection of problems encountered while building and deploying Synthesis against real workspaces. Each post below contributed a specific insight:
- The MCP benchmark revealed that tool integration architecture matters more than documentation quality — and that one line of guidance outperforms 41 rewritten tool descriptions.
- The invented date proved that temporal confabulation is a representation failure, not a model failure — you cannot prompt-engineer around missing metadata.
- The zero-links session demonstrated that a knowledge graph can emerge from existing content without schema design, using entity matching and cross-reference parsing.
- The code-gets-graphs asymmetry framed the core question: why do we graph code dependencies religiously but leave organizational knowledge as a flat pile of files?
- The excavation showed what "coverage" actually means when 84.8% of your knowledge base is invisible binary files.
- The KCP proposal addressed the format gap between static index files and running knowledge servers.
- The foundational post made the argument that knowledge infrastructure — not model capability — is the real bottleneck in AI agent deployments.
The findings¶
Benchmarks and evidence
-
We Gave the AI Better Documentation. It Got Slower. — CLI documentation increased tool calls by 11%. MCP decreased them by 35%. One sentence in the system prompt beat 41 rewritten tool descriptions. The benchmark that reframed how we think about agent integration.
-
The Date the AI Invented — The agent answered with zero tool calls, every metric correct — except a date it confabulated from surrounding narrative. Feb 19 appeared nowhere in the context. The finding that proved temporal metadata needs structured fields, not prose.
Knowledge graphs and structure
-
Zero Links: An Engineering Session with Claude Code and Opus — 777 directories, zero edges. One day later: 11,777 edges, 23 new tests, 4 bugs fixed. The TDD session that built entity-match and cross-reference edges from scratch — including one honest workflow mistake and its recovery.
-
Code Gets Graphs. Knowledge Doesn't. That's Backwards. — Every team graphs their code dependencies. Almost no one graphs their knowledge. The asymmetry argument, tightness as a diagnostic metric, and why the "second brain" concept needs to apply to organizations, not just individuals.
Coverage and standards
-
The Synthesis Excavation: Recovering 3.5 Years of Lost History — Text coverage was 99.6%. Real asset coverage was 15.2%. One working day, twelve enrichment rounds, 4,852 binary files surfaced. The dogfooding story that proved the shoemaker's children were barefoot.
-
Beyond llms.txt: AI Agents Need Maps, Not Tables of Contents — The six things llms.txt cannot express: topology, selective loading, intent, freshness, tooling connection, scale. Introducing the Knowledge Context Protocol (KCP) as the knowledge equivalent of MCP for tools.
The foundational argument
- AI Agents Without Knowledge Infrastructure Are Interns With Amnesia — The post that started the series. AI output increased 10-50x but shipping speed improved only 2x. The bottleneck is not code generation — it is comprehension. The case for treating knowledge infrastructure as the missing layer in agent deployments.
Reading guide¶
New to the series? Start with AI Agents Without Knowledge Infrastructure Are Interns With Amnesia for the problem statement, then read The Date the AI Invented for the most concrete failure mode. This capstone post synthesizes the rest.
Building agent infrastructure? Read the MCP benchmark and the KCP proposal — they address the two integration surfaces (tools and knowledge) that determine agent efficiency.
Evaluating knowledge tools? The excavation and zero-links session show what real-world deployment looks like — including what breaks and how long recovery takes.
Series: The Four-Layer AI Stack
Part 1 of 4 · Four Layers: How I Built an AI Development Environment That Partly Runs Itself →