Four Layers: How I Built an AI Development Environment That Partly Runs Itself¶
A technical walkthrough of the Synthesis + Claude Code + Mímir + Klaw stack — what each layer does, how they connect, and why the architecture matters.
This is Part 1 of three. Part 2 walks through a realistic day using this stack. Part 3 is written by the model running inside it.
The Problem No One Talks About¶
The productivity conversation in software development focuses almost entirely on generation speed. AI writes code faster. AI writes tests faster. AI writes documentation faster. All true.
What it does not address is the other half of the equation: comprehension speed.
When I built lib-pcb — a Java library for parsing eight proprietary PCB binary formats — in eleven days, the output was 197,831 lines of Java and 7,461 tests. The AI could generate at that rate. The problem was me. I cannot navigate 691 new files per day. I cannot hold the dependencies, the stale contexts, the relationships between modules in my head at that pace.
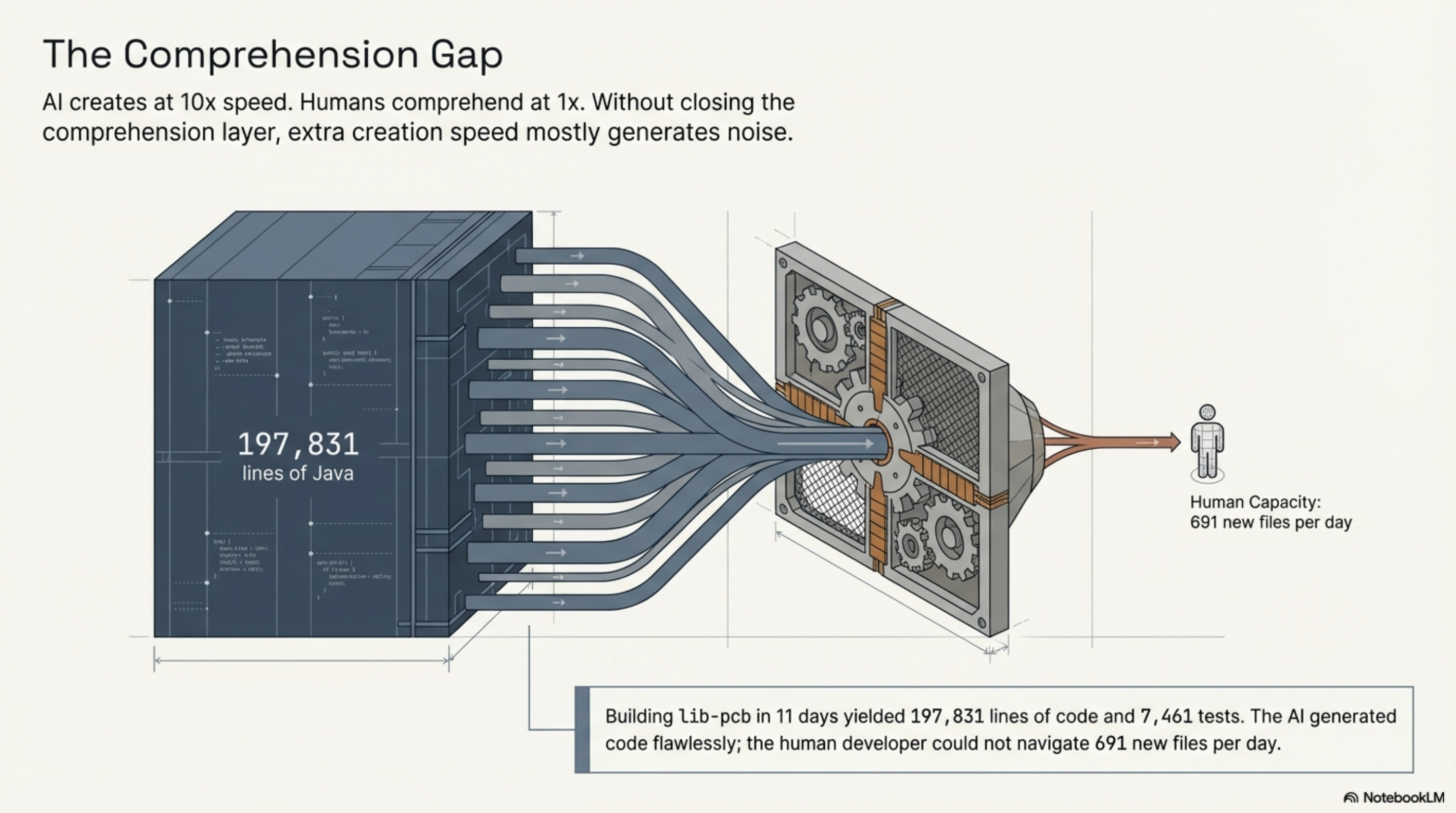
This is the gap nobody is designing for. AI creates at 10x speed. Humans still comprehend at 1x. If you do not close the comprehension layer, the extra creation speed mostly generates noise.
The stack I describe here is my answer to that gap.
Four Layers¶
| Layer | Tool | Problem it solves |
|---|---|---|
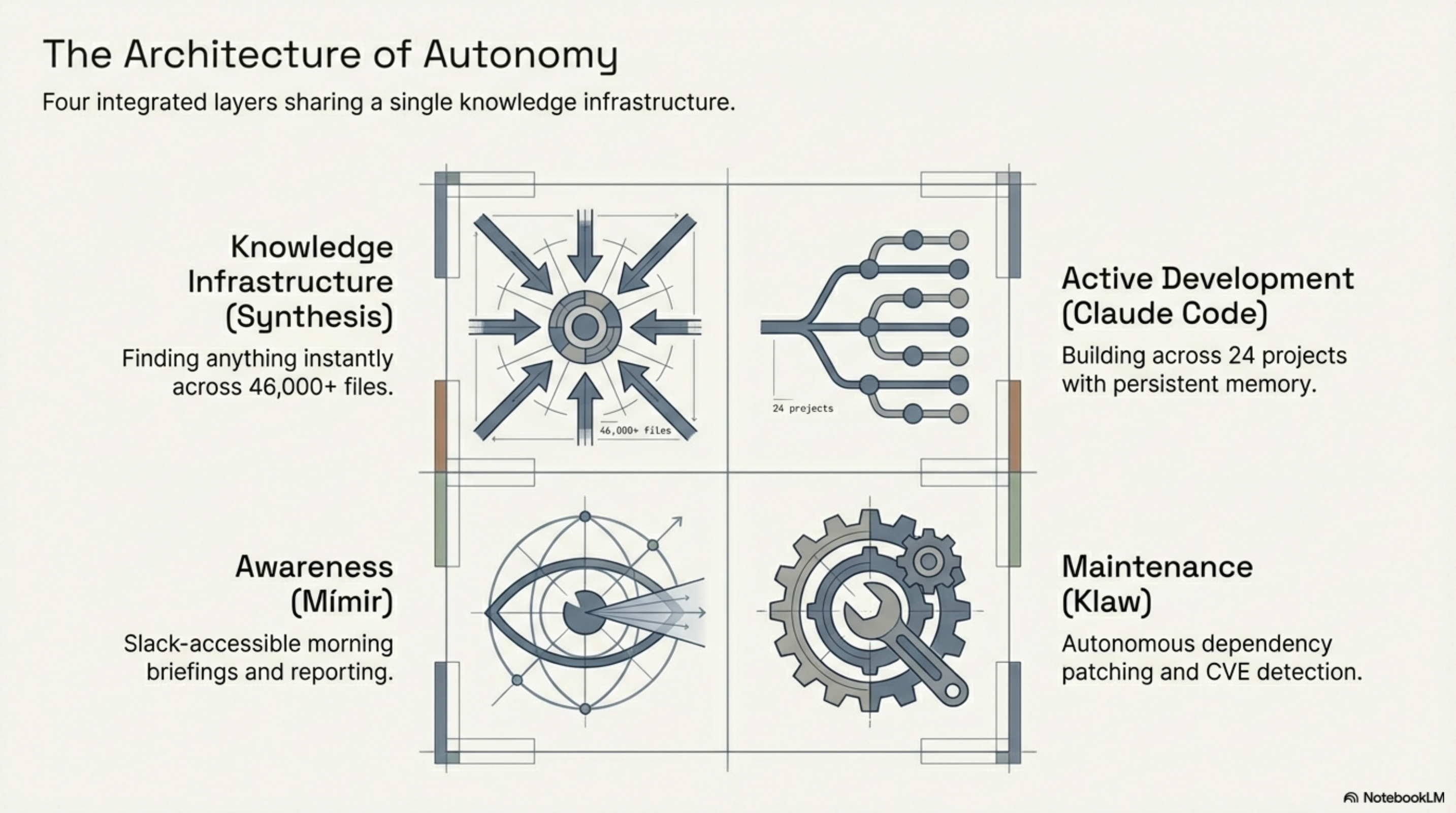
| Knowledge infrastructure | Synthesis | Finding anything instantly across 46,000+ files in 8 workspaces |
| Active development | Claude Code | Building across 24 projects with 150+ reusable skills and persistent memory |
| Awareness | Mímir | Morning briefing, Slack-accessible personal assistant |
| Maintenance | Klaw | Autonomous dependency patching, CVE detection, releases |
These are not independent tools running in parallel. They are integrated. Klaw uses Synthesis to read the codebase before patching dependencies. Mímir uses Synthesis to build context for my morning briefing. Claude Code uses Synthesis through MCP to navigate without scanning. They share the same knowledge layer — that is what makes the system coherent rather than a pile of tools.
Layer 1: Synthesis — Knowledge Infrastructure¶
Synthesis is an open-source, local-first knowledge indexer I built to manage the output velocity of this workflow. It runs as watch daemons across eight workspaces. Current state:
- 46,000+ files indexed across 8 workspaces (Documents: 15,125 · Cantara: 12,946 · eXOReaction: 13,041 · plus 5 others)
- ~60 MB combined index footprint — roughly 2–3% storage overhead on source content
- Cross-format indexing: code, markdown, YAML, JSON, config, PDFs, images, videos, audio — not just source files
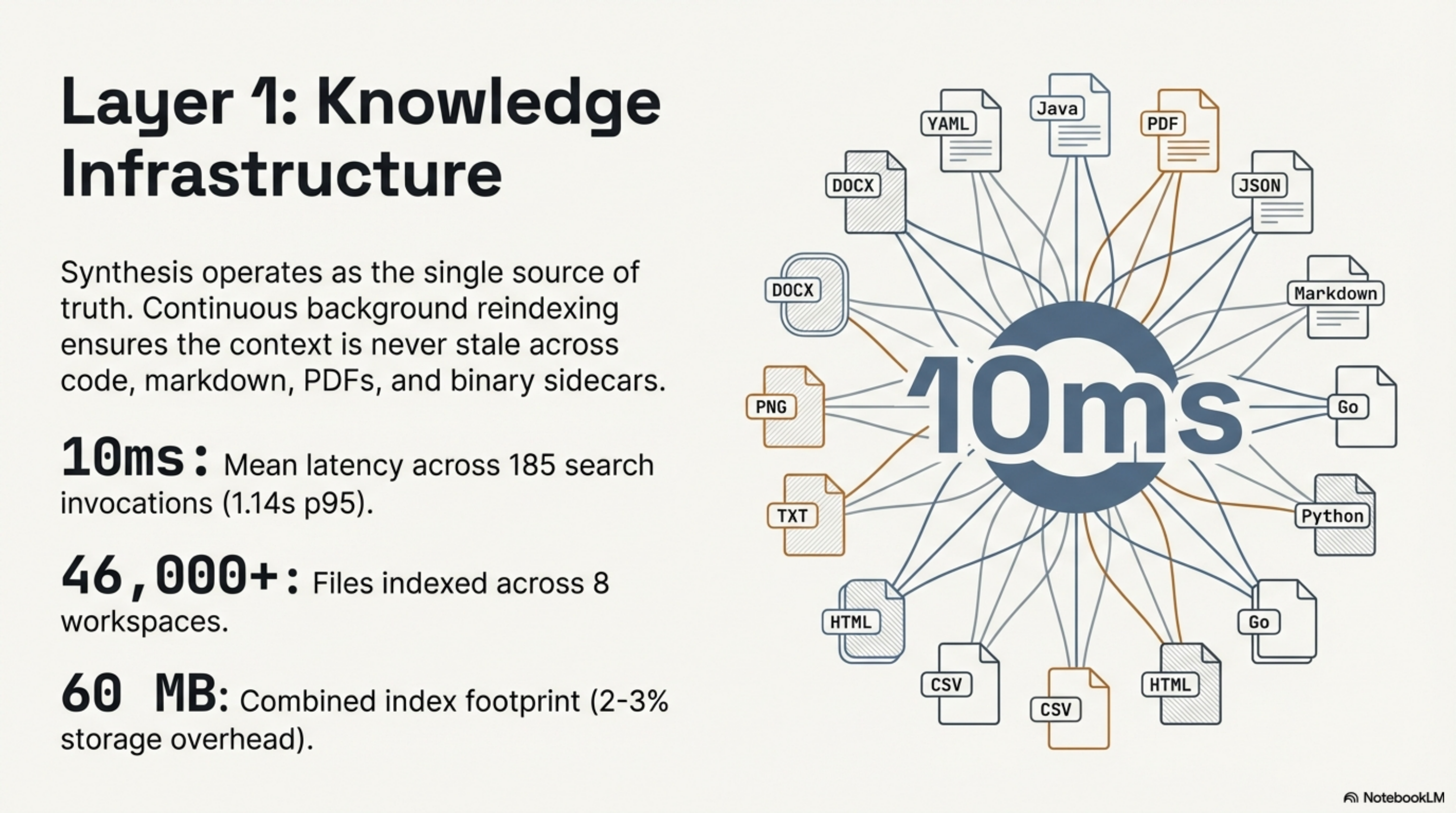
The search performance is where it matters. Over the past week, across 185 search invocations, the mean latency was 10 milliseconds. Not sub-second. Not hundreds of milliseconds. Ten. At p95, it was 1.14 seconds — still fast enough to feel instant in a development workflow. Success rate: 100%.
That 10ms matters because it determines whether search is something you invoke deliberately (like opening a browser tab) or something woven into every operation. At 10ms, tools can search on every keystroke, on every file open, on every commit. That is the difference between search as a feature and search as infrastructure.
Behind the search, the system is continuously reindexing. In the same 7-day window, there were 764 maintain invocations — background reindexing triggered by watch daemons after file changes and explicit maintain runs. The index is never stale. Every binary file gets a companion markdown sidecar (.synthesis.md) that makes its content searchable. Every code file gets dependency edges extracted. Every workspace gets a relationship graph that answers "what breaks if I change this?" in milliseconds.
Synthesis is the knowledge infrastructure tool described in this series.
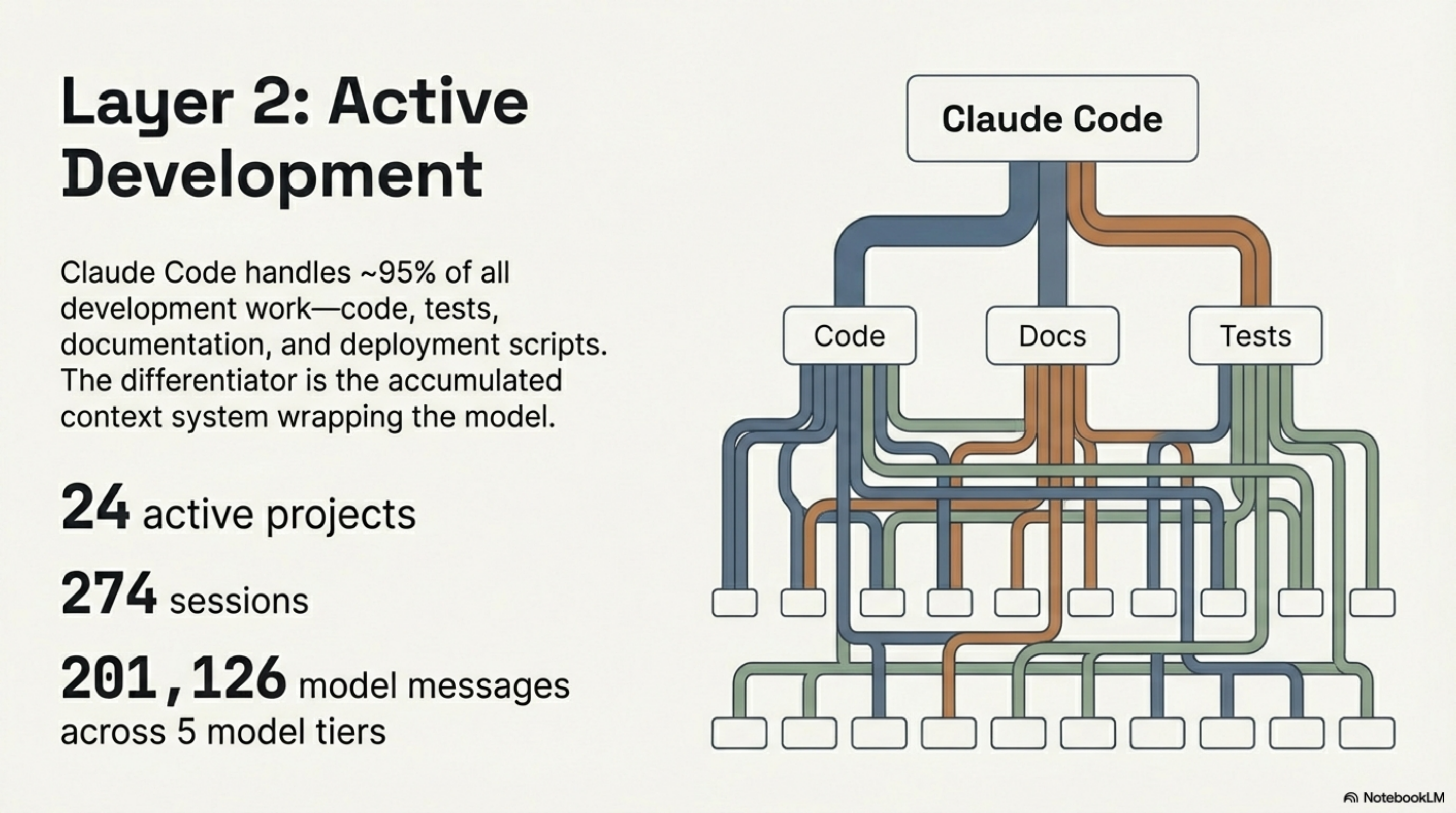
Layer 2: Claude Code — Active Development¶
Claude Code is where the building happens. What makes it different from ad-hoc AI coding is not the model — it is the accumulated context system around it.
Scale¶
Across all projects, my Claude Code usage currently spans:
- 24 active projects with logged sessions
- 274 sessions in the current log
- 201,126 model messages across 5 model tiers
- ~95% of all development work flows through Claude Code
The Cache Architecture¶
The most revealing number in my usage data is not the message count. It is the token distribution:
| Token type | Volume | What it represents |
|---|---|---|
| Cache read | 17.2 billion | Reused context served from prompt cache |
| Cache write | 844 million | New context written to cache (skills, memory, project context) |
| Direct input | 11.3 million | Fresh, uncached prompts |
| Output | 11.0 million | Model responses |
The ratio: 1,519 cache reads for every 1 direct input token. That means 99.93% of the context the model sees on any given interaction is served from cache — previously written knowledge being reused.

This is the economic and performance engine of the entire setup. The skill system — 150+ YAML files encoding specific workflows, project conventions, domain knowledge, and verification patterns — generates 844 million tokens of cached context. That cached context then gets reused 17.2 billion times across sessions. Each skill file is written once and amortised across hundreds of invocations.
Model Routing¶
Not everything runs on the same model. The five tiers reflect actual task complexity:
| Model | Messages | Share | Typical use |
|---|---|---|---|
| Sonnet 4.5 | 113,916 | 57% | Standard development: code, tests, refactoring |
| Sonnet 4.6 | 30,367 | 15% | Current-generation standard tasks |
| Haiku 4.5 | 21,484 | 11% | Fast/cheap: navigation, file search, simple edits |
| Opus 4.5 | 18,187 | 9% | Complex architecture, multi-file reasoning |
| Opus 4.6 | 17,172 | 8% | Hardest problems: cross-system design, novel solutions |

The 57/11/17 split between Sonnet, Haiku, and Opus mirrors the actual distribution of task complexity in real development. Most work is straightforward: implement this function, write this test, refactor this module. That is Sonnet. Navigation and simple lookups go to Haiku — fast and cheap, no need for deep reasoning. The hard problems go to Opus. Routing by complexity keeps costs proportional to value.
The Skill System¶
The 150+ skills are YAML files that encode reusable expertise. Examples:
track-linkedin-post: Workflow for capturing post metrics, updating the network index, attributing leadssynthesis-product-context: Complete product knowledge for Synthesis (architecture, features, positioning)integrate-assets: Pattern for processing new media files into the knowledge base with companion filesnetwork-index-management: Maintaining the contact/relationship database
Each skill is a compressed package of institutional knowledge. When I invoke track-linkedin-post, the model does not need me to explain the file structure, the metrics format, the index location, or the attribution rules. All of that is in the cached skill context.
Layer 3: Mímir — Awareness¶
Mímir is an IronClaw agent running on an EC2 instance in Stockholm. Its job is to be aware of things I am not actively looking at.
Every morning at 08:00 Oslo time, it composes a briefing from Oslo weather, top Hacker News stories, pipeline status, Synthesis changelog, and upcoming events. The briefing arrives in Slack. I read it over coffee in two minutes.

The key design decision: Mímir is a reader, not a writer. It observes and reports. It does not modify code, push commits, or make decisions. That boundary matters — mixing the reading and writing responsibilities in a single agent is where agentic systems go wrong.
Throughout the day, Mímir is accessible via Slack for quick questions. It has access to the full Synthesis index so it can answer questions about business state, pipeline, and codebase without me context-switching into Claude Code.
The Sync Pipeline¶
Mímir's knowledge stays current through a nightly sync from my local machine:
- Skills (~150 YAML files) synced via rsync to the EC2 workspace
- Memory files synced (persistent context across sessions)
- Documentation synced (pipeline status, proof points)
- Synthesis
maintainruns on the remote workspace to reindex
A separate hourly push (07:00–19:00 Oslo) keeps hot files current — pipeline status, network index, upcoming events. Worst-case staleness: 60 minutes for routine data, overnight for skills.
Layer 4: Klaw — Autonomous Maintenance¶
Klaw is the second IronClaw agent. Where Mímir reads, Klaw acts — but only within tightly scoped boundaries.
Current responsibilities:
- Dependency patching: Scanning 62 Cantara repositories for outdated dependencies
- CVE detection: Security analysis across the codebase. Current state: 230 findings (46 HIGH, 54 MEDIUM, 130 LOW) across 2,031 packages
- Release preparation: Assembling changelogs and version bumps
- Code health monitoring: 664 issues flagged across the Cantara workspace

Klaw has its own Synthesis MCP server with a separate workspace containing the full Cantara source code (62 repos, 12,946 files). It reads the codebase through Synthesis, identifies what needs attention, and either acts directly (for routine patches) or reports to Slack (for anything requiring judgment).
A security briefing runs at 05:30 Oslo time via cron, feeding Klaw's findings into the morning context before Mímir composes its briefing. By 08:00, I know both the business state and the code health state without opening a terminal.
How the Layers Connect¶
Local machine (Claude Code + Synthesis)
├── Nightly rsync → EC2 ironclaw0 (Mímir workspace)
│ ├── Skills (150+ YAML files)
│ ├── Memory (persistent context)
│ ├── Docs (pipeline, proof points)
│ └── synthesis maintain (reindex)
│
├── Nightly rsync → EC2 ironclaw1 (Klaw workspace)
│ ├── Cantara source (62 repos)
│ └── synthesis maintain (reindex)
│
├── Hourly hot-push → EC2
│ └── Pipeline status, network index, events
│
└── 05:30 → Klaw security briefing
→ 08:00 → Mímir morning briefing → Slack
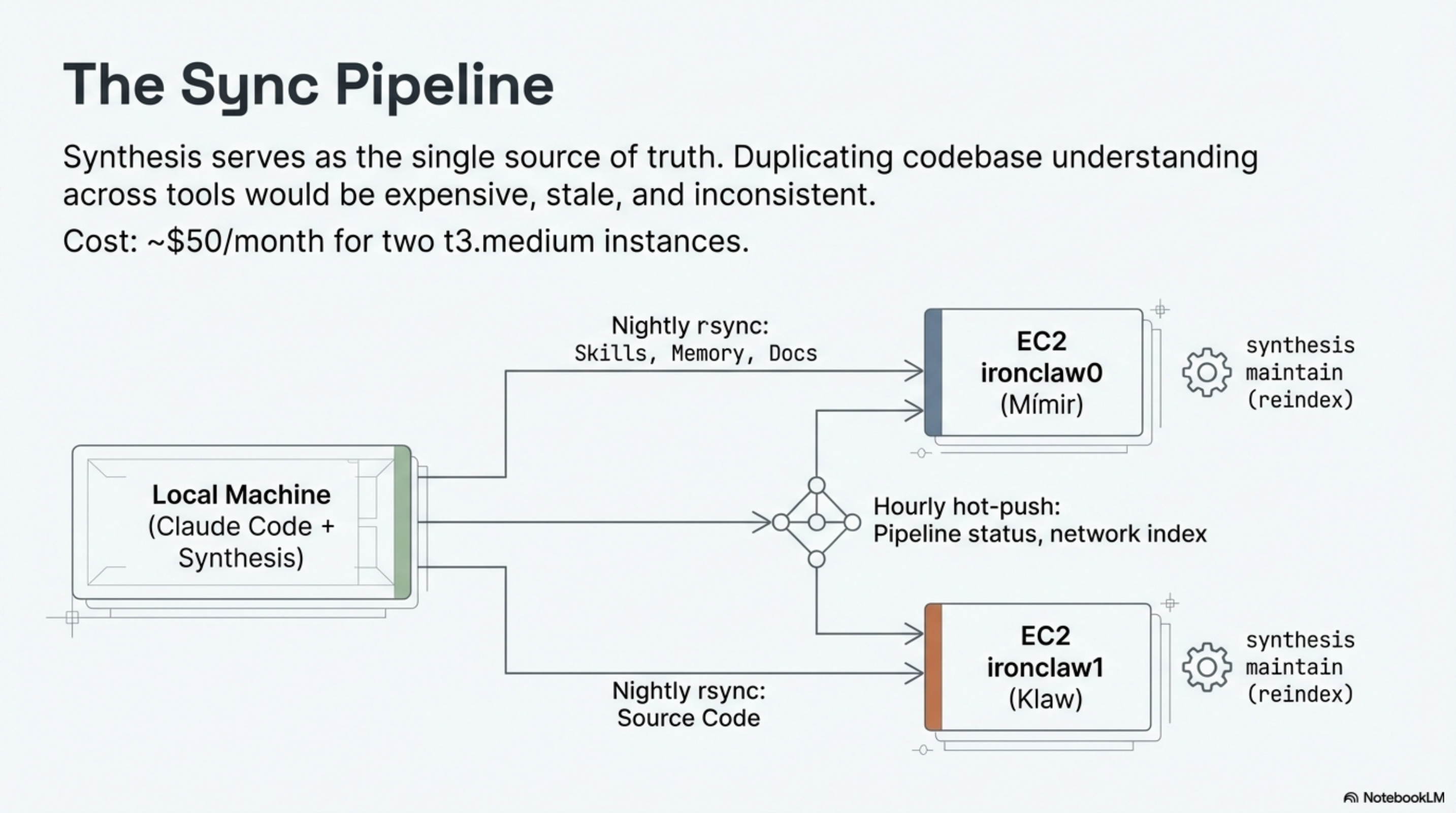
The critical path is Synthesis. Without a shared knowledge layer that all four components can query at 10ms, each tool would need its own understanding of the codebase. That duplication would be expensive, stale, and inconsistent. Synthesis is the single source of truth. Everything else is a consumer.
Cost: approximately $50/month for two t3.medium instances in Stockholm. The Synthesis index is ~60 MB combined. The infrastructure fits in a backpack.
What Breaks¶
Sync staleness. The nightly rsync means Mímir and Klaw can be up to 24 hours behind on skill changes. A skill written at 15:00 will not be available to remote agents until 02:00.
Agent stability. The current version of IronClaw has a stuck-state bug: after about an hour of idle time, the agent stops processing new turns. The briefing health check auto-restarts on detection, and the agents monitor each other via cron every 15 minutes. It works, but it requires maintenance.
Single point of failure. If my local machine goes down, the sync pipeline stops. The EC2 agents continue running on stale data. There is no redundancy for the local node.
Cost at scale. Five model tiers, two EC2 instances, continuous Synthesis indexing. The cache architecture keeps per-interaction costs low, but the infrastructure cost is real. This setup makes economic sense at 24 active projects. It would not at 3.

The Compound Effect¶
The value is not in any single layer. Klaw finds a vulnerability at 05:30. The finding flows into Mímir's briefing at 08:00. I read it over coffee. At 09:00, I open Claude Code, which has the Synthesis index and the relevant skills cached, and fix the vulnerability in the context of the full codebase. The fix is committed, Synthesis reindexes, the watch daemons update, and Klaw's next scan shows the finding resolved.
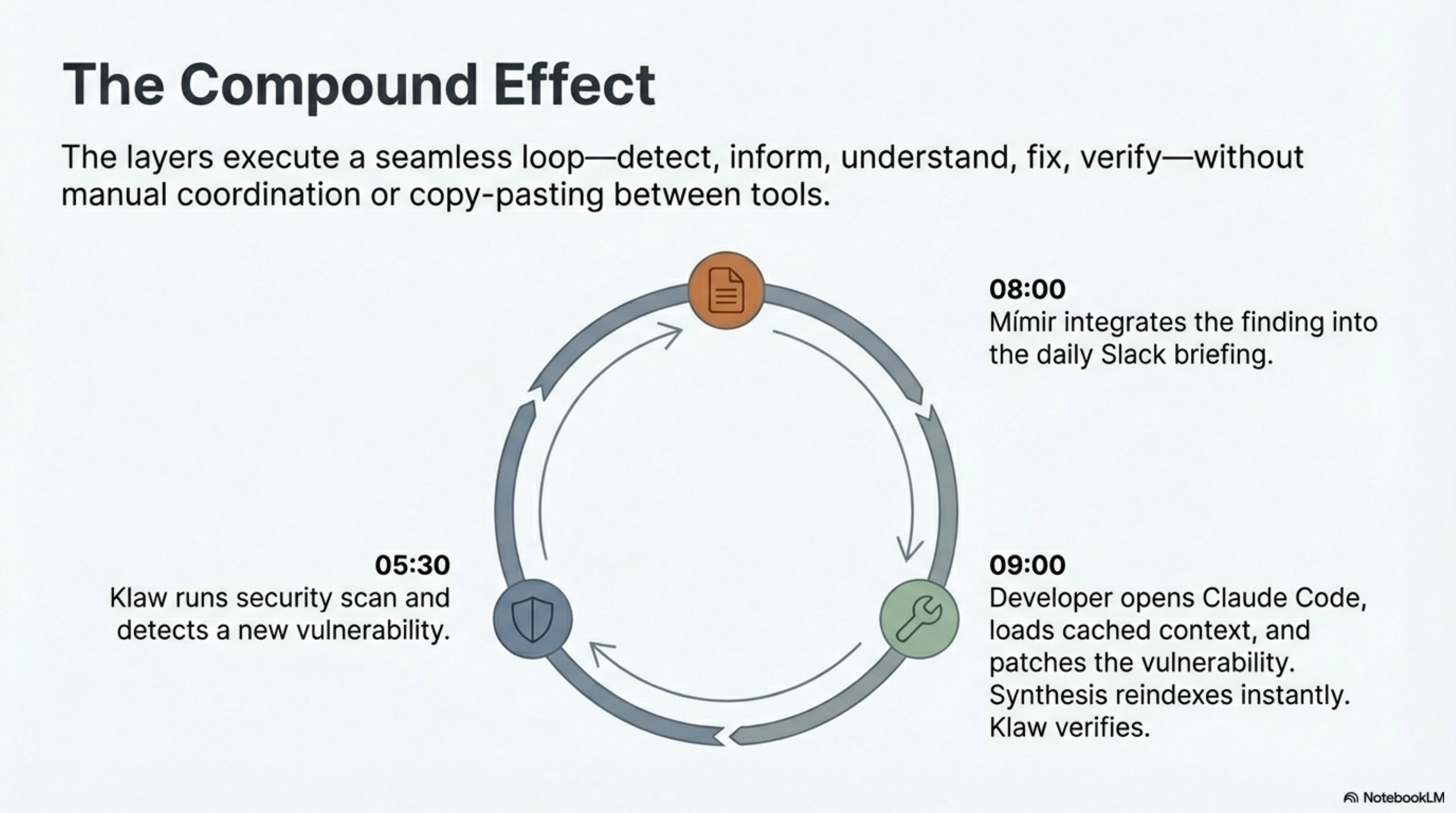
That loop — detect, inform, understand, fix, verify — runs across all four layers without manual coordination. No copy-pasting between tools. No re-explaining context. No searching for where the vulnerability lives. The knowledge infrastructure handles the comprehension layer so I can focus on the decision layer.
That is the gap I set out to close: not how fast AI can write code, but how fast a human can understand what needs to happen and verify that it happened correctly.
The Asset Is Not the Tools¶
Some of this stack is reusable. Synthesis is the knowledge infrastructure tool at the centre of this stack. The skill system is a pattern anyone using Claude Code can adopt. IronClaw is open-source infrastructure. But the specific configuration — which skills exist, which workspaces are indexed, which agents handle which domains — is bespoke.
That is the point.
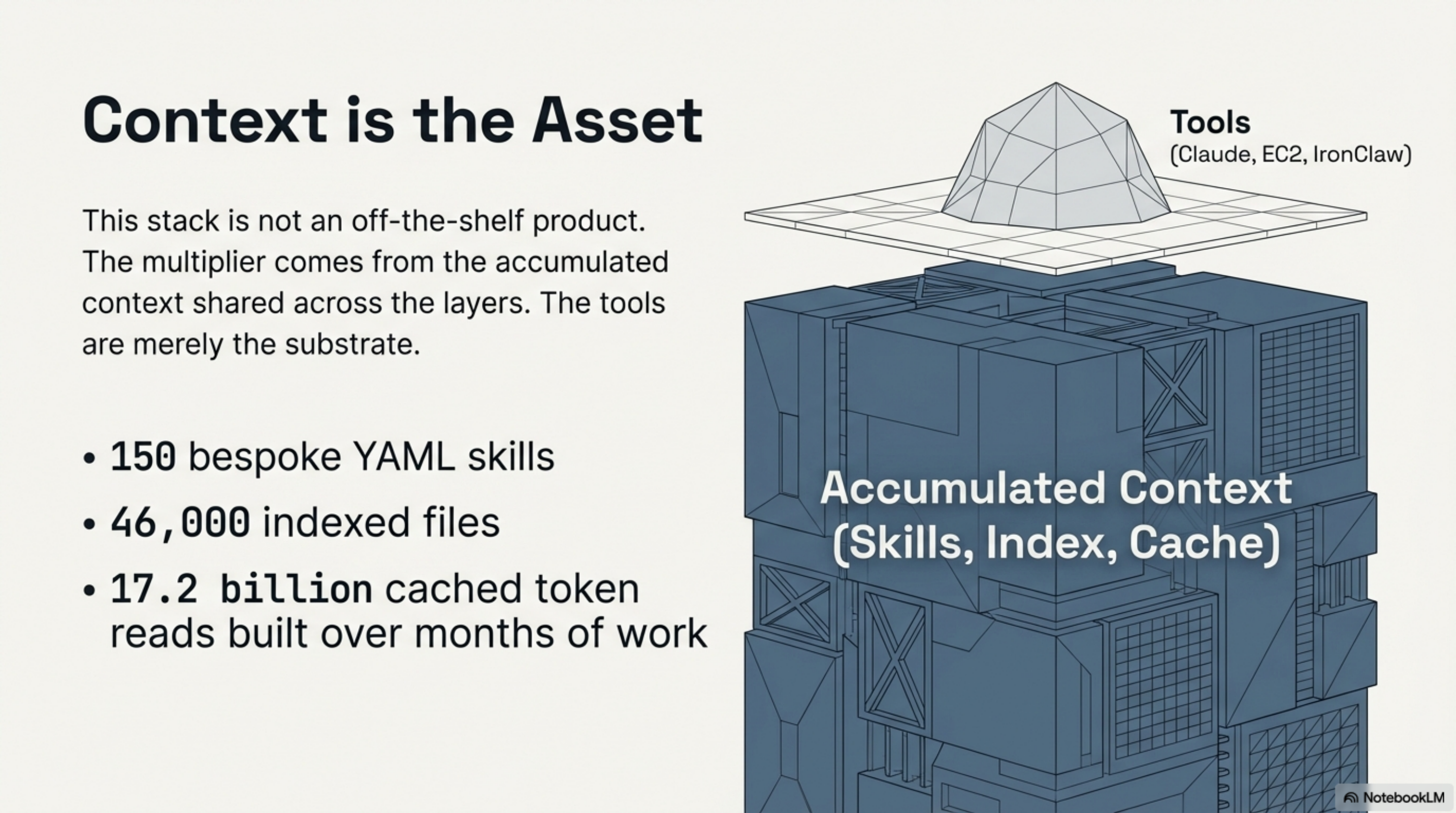
The multiplier comes not from the tools themselves but from the accumulated context they share: 150 skills, 46,000 indexed files, 17.2 billion cached token reads. That context took months to build. The tools are the substrate. The knowledge is the asset.
Getting Started¶

- Synthesis: Synthesis — knowledge infrastructure, Java 21, runs locally
- Claude Code:
npm install -g @anthropic-ai/claude-code— then invest time in building skills - IronClaw: github.com/nearai/ironclaw — open source, runs on any Linux instance
- KCP: cantara.github.io/knowledge-context-protocol — YAML standard for making knowledge navigable
Start with one skill for your primary codebase. Build from there. The rest — the agents, the automation, the nightly sync — are refinements on top of the thing that actually shifts your daily experience.
Part 2: What a 10× Workday Actually Looks Like — real output numbers, eight tasks, and the parts nobody talks about.
Part 3: What It Looks Like from Inside the Stack — a first-person account from the AI running inside this environment.
Series: The Four-Layer AI Stack
← Your AI Has One Layer. It Needs Four. · Part 2 of 4 · What a 10× Workday Actually Looks Like →