The Front Door and the Filing Cabinet: A2A Agent Cards Meet KCP¶
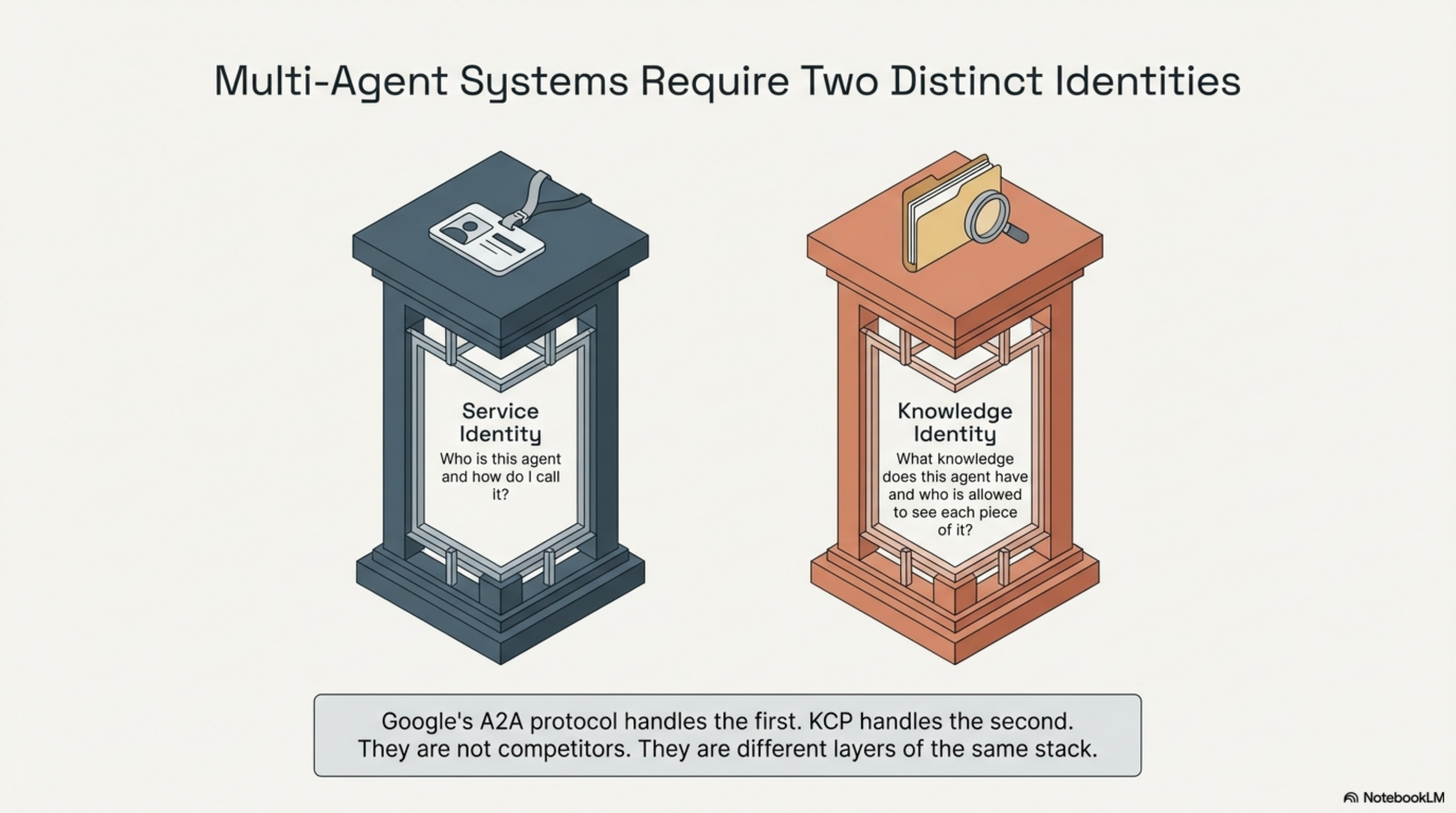
Multi-agent systems need two kinds of identity. The first answers "who is this agent and how do I call it." The second answers "what knowledge does this agent have and who is allowed to see each piece of it." Google's A2A protocol handles the first. KCP handles the second. They are not competitors. They are different layers of the same stack.
This post started as that explanation. Then, the same day it was published, we built four simulators and 150 adversarial tests against the spec. The tests found 8 concrete gaps. Those gaps are now driving KCP v0.7. The full story follows.
What an A2A Agent Card does¶
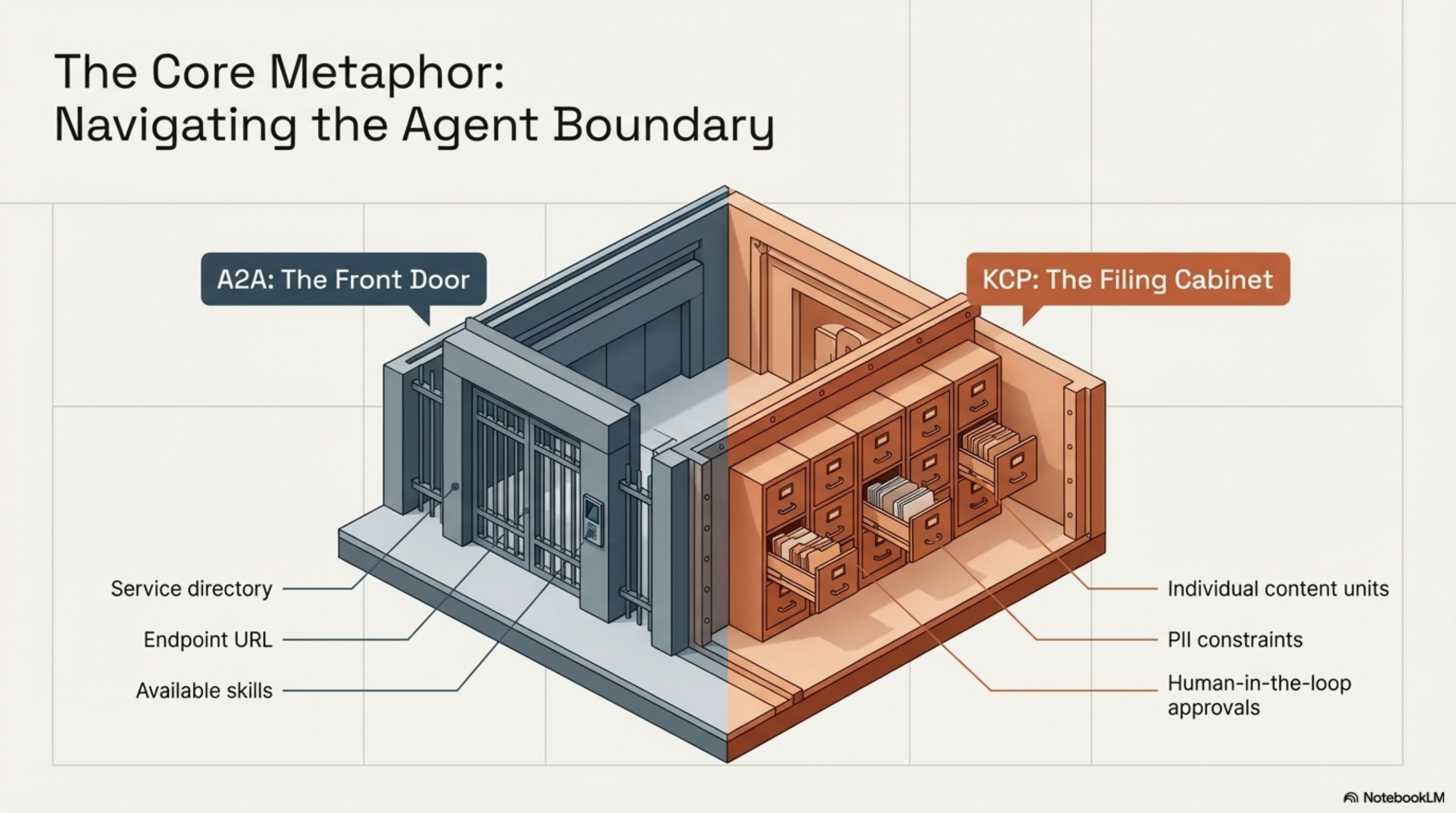
An A2A Agent Card is a JSON file published at /.well-known/agent.json. It describes an agent's identity, what it can do, and how to authenticate when calling it. Think of it as a service directory entry — the front door.
{
"name": "Clinical Research Agent",
"description": "Answers questions about clinical trial protocols and patient cohort data.",
"url": "https://research.hospital.example/a2a",
"version": "1.0.0",
"provider": {
"organization": "Hospital Research Division",
"url": "https://hospital.example"
},
"capabilities": {
"streaming": true,
"pushNotifications": false
},
"securitySchemes": {
"hospital-oauth": {
"type": "oauth2",
"flows": {
"clientCredentials": {
"tokenUrl": "https://auth.hospital.example/token",
"scopes": {
"agent:invoke": "Invoke this agent"
}
}
}
}
},
"security": [{ "hospital-oauth": ["agent:invoke"] }],
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain", "application/json"],
"skills": [
{
"id": "protocol-lookup",
"name": "Protocol Lookup",
"description": "Find clinical trial protocols by ID or condition.",
"tags": ["clinical", "research", "protocols"]
},
{
"id": "cohort-analysis",
"name": "Patient Cohort Analysis",
"description": "Statistical analysis of patient cohort data.",
"tags": ["analysis", "patients", "statistics"]
}
]
}
This tells a calling agent everything it needs to connect: the endpoint URL, OAuth2 token endpoint, supported content types, and available skills. It is the agent equivalent of a Swagger/OpenAPI definition for a REST service — discovery and invocation in one file.
What it does not tell you is which pieces of knowledge inside the agent are public, which require specific roles to access, and what delegation constraints apply when one agent passes context from this agent to a third agent.
What a KCP manifest does¶
A KCP manifest (knowledge.yaml) describes the knowledge an agent has access to, at the level of individual units. It does not describe the agent itself — it describes the filing cabinet inside the agent.
knowledge:
id: clinical-research-knowledge
version: "1.0"
description: "Knowledge context for the Clinical Research Agent."
auth:
methods:
- type: oauth2
flow: client_credentials
token_endpoint: "https://auth.hospital.example/token"
scopes: ["read:knowledge"]
trust:
audit:
agent_must_log: true
require_trace_context: true
delegation:
max_depth: 2
require_capability_attenuation: true
audit_chain: true
units:
- id: trial-protocols
intent: "What are the active clinical trial protocols?"
path: protocols/active-trials.md
scope: project
audience: [agent, researcher]
access: authenticated
triggers: ["trial", "protocol", "study", "phase"]
- id: public-guidelines
intent: "What are the published research guidelines?"
path: guidelines/public.md
scope: global
audience: [human, agent]
access: public
- id: patient-cohort
intent: "What does the patient cohort data show?"
path: data/patient-cohort.md
scope: project
audience: [agent]
access: restricted
auth_scope: "clinical-staff"
sensitivity: pii
delegation:
max_depth: 1
human_in_the_loop:
required: true
approval_mechanism: oauth_consent
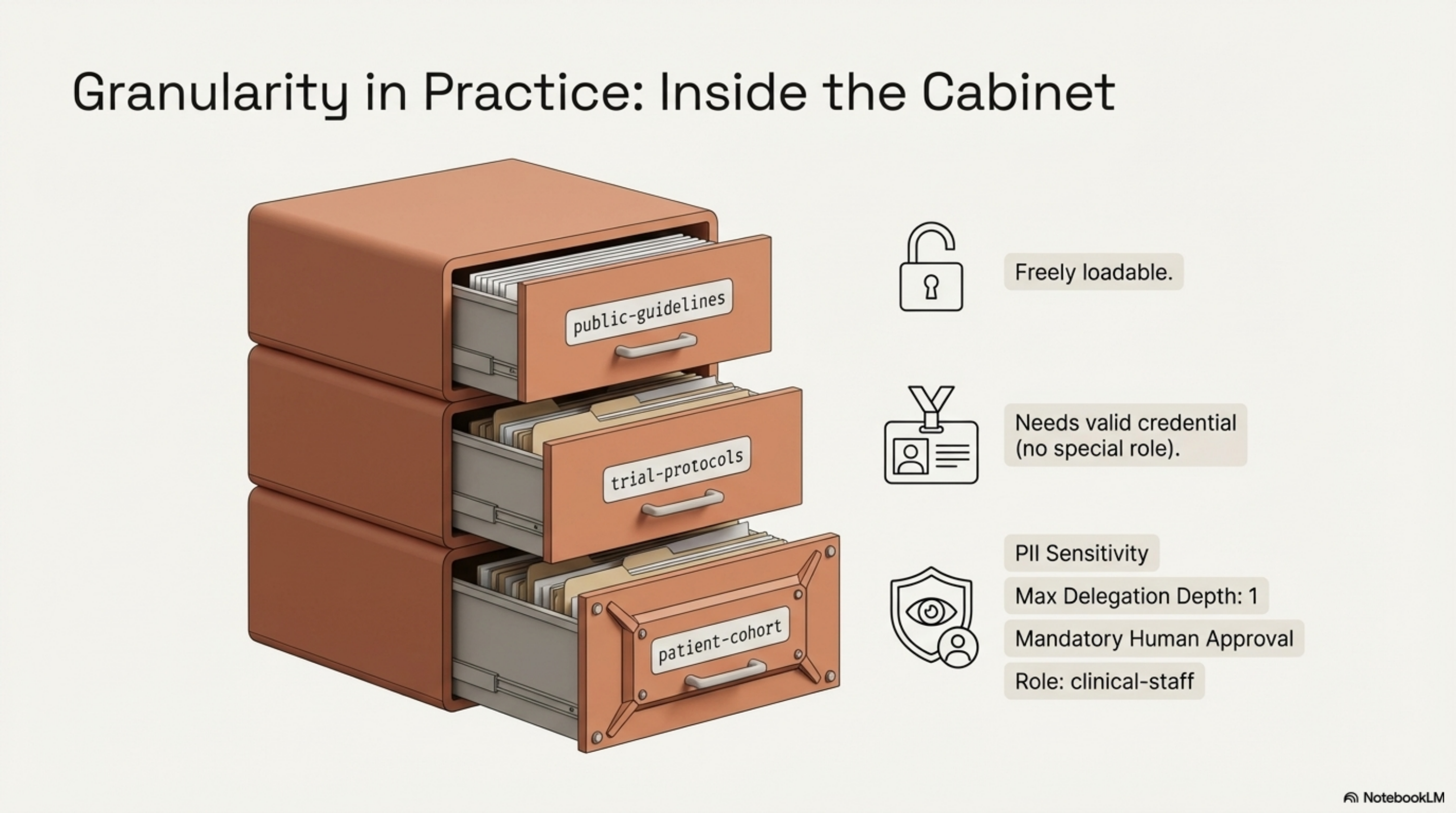
The patient-cohort unit carries constraints the Agent Card cannot express: PII sensitivity, a maximum delegation depth of 1, mandatory human approval before an agent reads it, and a specific role requirement (clinical-staff). The public-guidelines unit is freely loadable. The trial-protocols unit needs any valid credential but no special role.
This per-unit granularity is KCP's purpose. An agent reading the manifest knows — before fetching any content — what it can load freely, what needs credentials, and what needs human approval.
Different layers, different granularity¶
| Concern | A2A Agent Card | KCP Manifest |
|---|---|---|
| Identity of | The agent (service) | The knowledge (content units) |
| Published at | /.well-known/agent.json |
knowledge.yaml (project root) |
| Format | JSON | YAML |
| Auth answers | "How do I call this agent?" | "What credential do I need for this specific unit?" |
| Granularity | Per-agent | Per-knowledge-unit |
| Delegation controls | Not in scope | max_depth, capability attenuation, audit chain |
| Sensitivity labels | Not in scope | public, internal, confidential, pii |
| Human-in-the-loop | Not in scope | Per-unit, with approval mechanism |
| Discovery | Agent skills, I/O modes, capabilities | Knowledge units, intents, triggers, freshness |
| Complementary to | MCP (tool transport) | MCP (unit retrieval), A2A (agent invocation) |
A2A answers: Can I call this agent? What does it accept? How do I authenticate to it?
KCP answers: What knowledge does this agent have? Which pieces require which credentials? What happens when this agent delegates access to another agent?
How they compose in a multi-agent system¶
A concrete scenario. An orchestrator agent needs clinical trial data from a research agent.
Human
→ authorizes Orchestrator Agent
Orchestrator Agent
→ discovers Research Agent via A2A Card (/.well-known/agent.json)
→ authenticates TO Research Agent (OAuth2 bearer, per A2A securitySchemes)
Research Agent
→ reads its KCP manifest (knowledge.yaml)
→ unit "public-guidelines": access=public
→ loads immediately, no constraints
→ unit "trial-protocols": access=authenticated
→ caller has valid OAuth2 token, loads
→ unit "patient-cohort": access=restricted, auth_scope="clinical-staff",
delegation.max_depth=1, human_in_the_loop=required, sensitivity=pii
→ checks: does caller hold "clinical-staff" scope? (KCP auth)
→ checks: delegation depth ≤ 1? (KCP delegation)
→ requests human approval before loading (KCP HITL)
→ logs access with W3C Trace Context headers (KCP trust.audit)
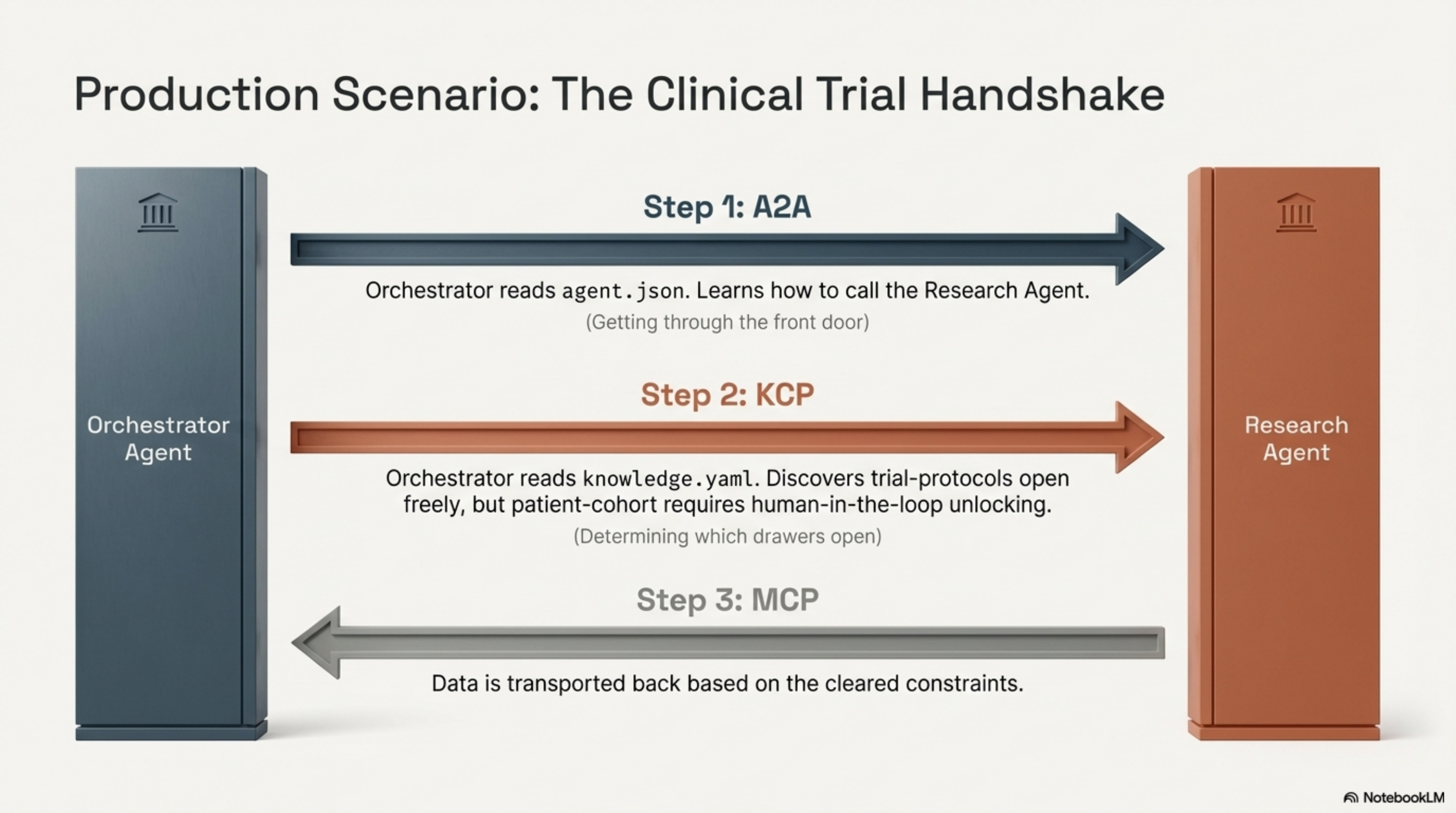
A2A got the orchestrator through the front door. KCP determined what happened once inside — which drawers opened freely, which required a specific key, and which required a human to unlock them.
Without A2A, the orchestrator does not know how to find or call the research agent. Without KCP, every unit inside the research agent has the same access level — all or nothing.
The auth overlap, honestly¶

Both protocols touch authentication. This is the area where a superficial reading might suggest redundancy. It is not.
A2A auth operates at the transport layer. It defines how a calling agent authenticates to the target agent — OAuth2 flows, API keys, bearer tokens. The question is: "Are you allowed to talk to this agent at all?"
KCP auth operates at the knowledge-access layer. It defines what credentials are needed to access a specific knowledge unit within the agent's context. The question is: "Now that you are inside, are you allowed to read this particular file?"
A2A cannot express: "The patient records unit requires human-in-the-loop approval, maximum delegation depth 1, audit trail required, PII sensitivity." There is no field for it. Agent Cards describe the agent, not the agent's knowledge.
KCP cannot express: "This agent accepts calls via OAuth2 bearer at this endpoint URL, supports streaming, and has these skills with these I/O modes." There is no field for it. Knowledge manifests describe the knowledge, not the service hosting it.
The overlap is that both support OAuth2. The difference is the question being asked and the granularity at which it is asked.
What this means for production deployments¶

If you are building a multi-agent system that handles data with mixed sensitivity levels — which is most production systems — you need both layers:
- Agent discovery and invocation (A2A): Which agents exist? What can they do? How do I call them?
- Knowledge access control (KCP): Within each agent, which knowledge units exist? What are their access levels? What delegation constraints apply?
Neither protocol alone covers the full stack. A2A without KCP gives you a well-described front door with no access control inside. KCP without A2A gives you fine-grained knowledge control with no standard way for agents to find or invoke each other.
The composability model extends to MCP as well. KCP and MCP already work together — KCP provides the knowledge manifest, MCP provides the transport for retrieving units. A2A adds the agent-to-agent discovery layer on top.
The simulation suite¶
The explanation above is the theory. To test whether the spec actually holds up, we built four Java simulators against different domains, each pushing the KCP v0.6 spec harder than the last.
| Simulator | Domain | Agents | Units | Tests | Key behaviour tested |
|---|---|---|---|---|---|
| Clinical Research | Hospital trial data | 2 | 3 | 30 | Baseline: escalating access levels, HITL gate, audit trail |
| Scenario 1: Energy Metering | Smart grid telemetry | 2 | 4 | 36 | Public through restricted with unit-level delegation override |
| Scenario 2: Legal Delegation | Law firm document review | 3 | 4 | 36 | 3-hop delegation chain, max_depth=0, capability attenuation |
| Scenario 3: Financial AML | Bank anti-money-laundering | 5 | 5 | 48 | Adversarial rogue agent, 4 attack types, GDPR compliance block |
| Total | 12 | 16 | 150 |
Each simulator is a runnable Java application with structured output tagged [A2A], [KCP], [HITL], [AUDIT]. All source lives in examples/.
The clinical research simulator walks through the clinical trial scenario from the first section of this post — A2A discovery, KCP manifest loading, OAuth2 token exchange, per-unit access decisions. It is the happy path.
The scenarios then escalate. Scenario 1 (energy metering) adds a 4-unit escalation from public tariff data to restricted 15-second smart meter telemetry. Scenario 2 (legal delegation) chains three agents — Case Orchestrator, Legal Research, External Case Law — and tests what happens when sealed court records carry max_depth: 0 (no delegation permitted) and when a delegatee tries to pass the same scope it received (capability attenuation violation). Scenario 3 (financial AML) is the adversarial test: five agents including a RogueAgent that attempts depth exceeding, scope elevation, and accessing no-delegation units, plus a GDPR data residency enforcement test that blocks requests originating from outside the EU.
A sample from Scenario 3:
-- Phase 4: RogueAgent -- Delegation Depth Violation ------------------------
[P4] RogueAgent claims depth=3 delegatee for 'customer-profiles' (max_depth=2)
[KCP] Result: BLOCKED (Depth 3 exceeds max_depth=2)
[AUDIT] VIOLATION: RogueAgent depth=3 exceeds max_depth=2
-- Phase 5: RogueAgent -- Scope Elevation Attempt --------------------------
[P5] RogueAgent has 'read:transactions' token, requests 'customer-profiles'
[KCP] Result: BLOCKED (Invalid token or missing scope: aml-analyst)
[AUDIT] VIOLATION: RogueAgent scope elevation attempt
-- Phase 7: Compliance Block (GDPR Data Residency) -------------------------
[P7] Request for 'customer-profiles' with data_residency claim: US
[KCP] Result: BLOCKED (Data residency violation: request from 'US' but unit restricted to [EU])
[AUDIT] COMPLIANCE VIOLATION: GDPR data residency
The RogueAgent gets blocked. That is the test passing. But writing the blocking logic forced us to confront exactly where the spec stops and implementation guesswork begins.
What the tests found: 8 spec gaps¶
150 passing tests, 8 gaps. Each was found by writing a test that should have been straightforward, then discovering the spec did not define enough for us to implement it deterministically.
1. HITL approval_mechanism is declared but undefined. The manifest says approval_mechanism: oauth_consent, but v0.6 defines no consent request format, no verification protocol, and no trust chain between the HITL gate and the knowledge owner. Every implementer will build a different approval flow. Cross-vendor HITL interoperability is impossible until this is standardised.
2. Capability attenuation is declarative, not mechanical. require_capability_attenuation: true says delegated agents must receive a narrower scope. But the spec does not define how the receiving agent verifies this (it would need to see both tokens), what "narrower" means formally (is read:case:external-summary narrower than read:case?), or whether scope hierarchy is prefix-based, lexicographic, or defined by a separate ontology. The simulator uses a "not-equal means narrower" heuristic, which is clearly insufficient for production.
3. Delegation depth counting is ambiguous. The spec does not state whether the resource-owning agent is at depth=0 or depth=1. With max_depth: 2, the owner=0 convention allows 3 agents in the chain; the owner=1 convention allows only 2. One normative sentence resolves this.
4. max_depth: 0 needs an explicit statement. The simulator interprets max_depth: 0 as "no delegation — only the resource owner may access this unit." This is equivalent under the owner=0 convention, but without a normative note, implementers will disagree.
5. Compliance blocks are advisory. compliance.data_residency, compliance.regulations, and compliance.restrictions come from RFC-0004, not the v0.6 core spec. An agent can ignore them entirely and remain spec-compliant. Cross-vendor compliance enforcement is impossible until these fields become normative.
6. No cryptographic delegation chain. When RogueAgent claims to be a depth=3 delegatee, the spec provides no mechanism to verify the claim. W3C Trace Context helps with audit but does not prevent spoofing. A malicious agent can fabricate any delegation depth. Without signed delegation tokens where each hop signs the narrowed scope and depth, max_depth enforcement is advisory.
7. no_ai_training restriction has no enforcement mechanism. The restriction is purely declarative. An agent can claim compliance, but nothing prevents it from feeding the data into a training pipeline. The system cannot verify the claim.
8. Multiple HITL gates are undefined. The spec says HITL is per-unit, but when an orchestrator needs approvals for multiple units in one workflow (Scenario 3 triggers two sequentially), should they be sequential, batched into a single approval screen, or parallel with aggregation? The sequential approach has poor UX for compliance officers facing many individual prompts. The batched approach requires a standard batch format the spec does not define.
What changes in v0.7¶
The 8 gaps above are now the v0.7 work list. The key promotions:
- Delegation block moves from RFC-0002 into core, with normative depth counting (owner=0), an explicit
max_depth: 0definition, and a scope comparison model. - Compliance block moves from RFC-0004 into core, making
data_residencyandregulationsenforceable fields rather than advisory metadata. - HITL protocol gets a minimal interoperability contract: consent request schema, signed approval token, verification endpoint.
- Delegation token format is specified for cryptographic chain verification.
The simulators will be updated alongside the spec, maintaining the same 150-test suite as a conformance baseline. The intent is that any v0.7-compliant implementation can run these scenarios and produce equivalent output.
Related¶
- Who Let the Agent In? — KCP auth and delegation (RFC-0002) in detail
- KCP and MCP: One Protocol for Structure, One for Retrieval — how KCP and MCP compose
- A2A Protocol specification
- KCP spec and RFCs
- Simulation source code
A note on methodology¶
This post was written, published, simulated, tested, and fed back into the spec in a single day. The explanation came first. Then four working simulators in Java. Then 150 adversarial tests. Then 8 findings that none of us had identified by reading the spec. Then the v0.7 roadmap. That is what AI-augmented standards work looks like in 2026: the iteration cycle that used to take months — write spec, implement, discover gaps, revise — compressed to hours. The gaps were real. Finding them through testing is the methodology working correctly.
Series: Knowledge Context Protocol
← kcp-mcp v0.10.0: GitHub Copilot Gets KCP — Including MCP-Locked Enterprises · Part 18 of 24 · The Autonomous Agentic Web Needs a Foundation Layer →