The KCP Ecosystem: How Five Tools Turn Claude Code Into a Persistent Intelligence Platform

The Problem
Every session with Claude Code starts from zero.
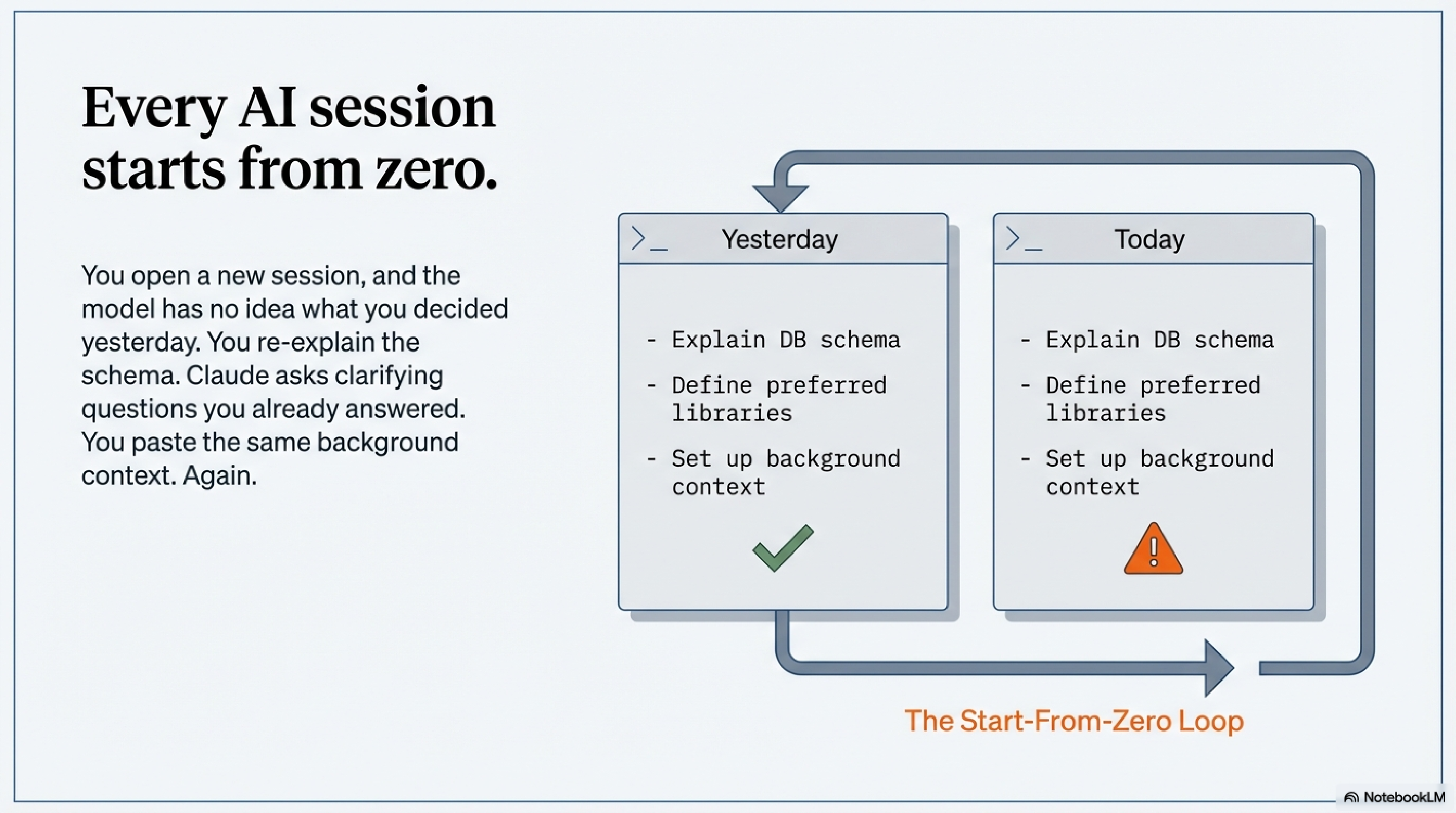
You open a new session, and the model has no idea what you were doing yesterday. Which services are running. What you decided about the database schema last Thursday. Why you chose the library you chose. You re-explain it. Claude asks clarifying questions you answered two sessions ago. You paste the same background context you always paste. Then the work begins.
And when the work does begin, there's a different problem: output flooding the context window. Run mvn package and you get 400 lines of Maven lifecycle noise. Run terraform plan and the diff buries the actual changes in scaffolding. Run kubectl get pods cluster-wide and you've spent 8,000 tokens on status rows you didn't need.

The context window is your working memory. Filling it with boilerplate and re-explaining the same setup repeatedly is waste — not just inconvenient, but structurally limiting. A 200K token context sounds vast until a third of it is recovery overhead.
What's missing is infrastructure. Not smarter prompting. Not longer context. Infrastructure — a persistent layer that handles memory, filters noise, and gives the model the right knowledge at the right moment without you having to manage it manually.
That infrastructure is KCP.