Agent Memory Rots. Here's How We Stopped It.¶
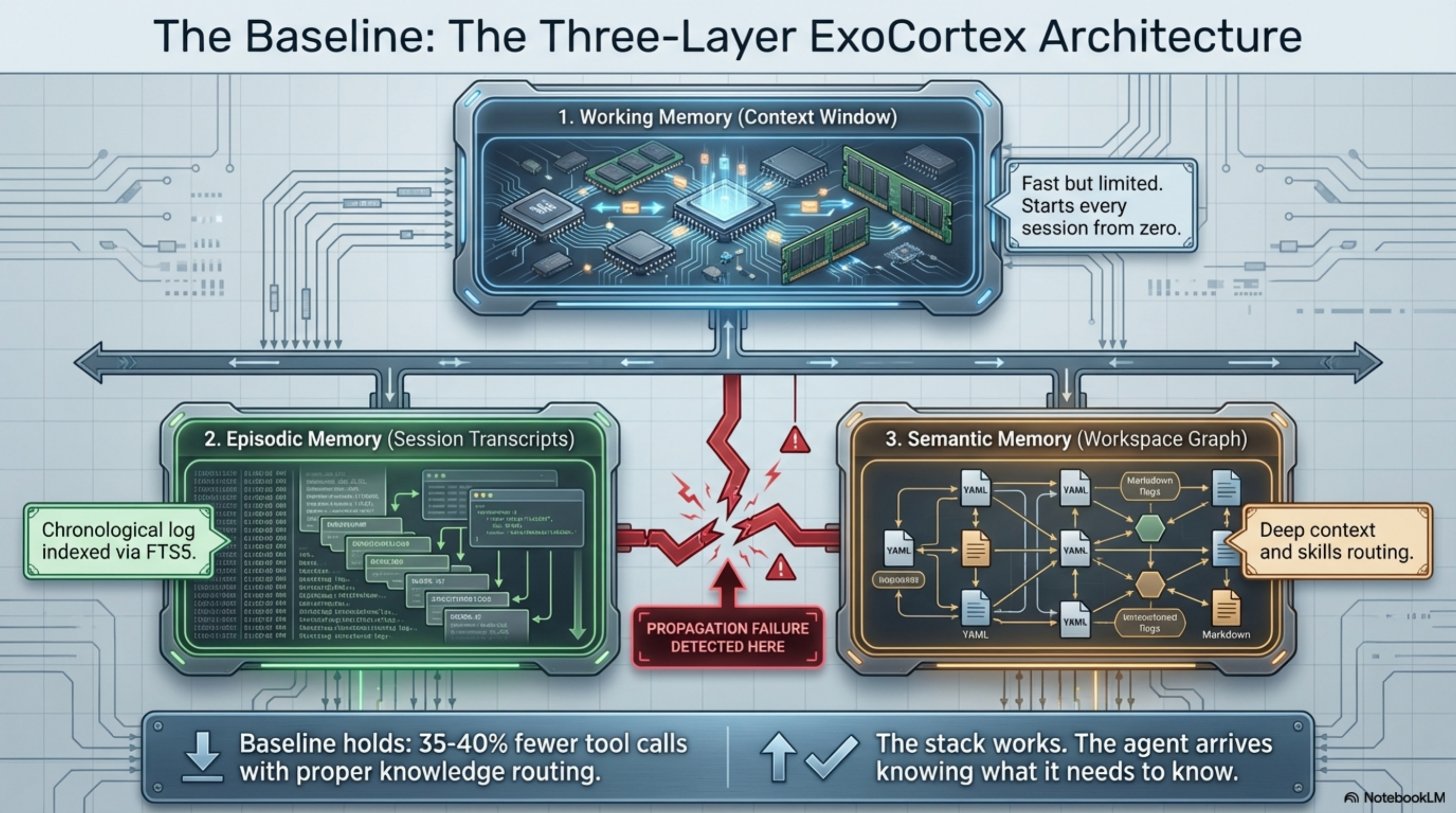
Five weeks ago I wrote about the three-layer memory architecture for AI agents: working memory (the context window), episodic memory (indexed session transcripts), and semantic memory (a workspace knowledge graph). The prescription was "build these layers." Yesterday I shipped the maintenance system that keeps them from decaying.
Building the layers was the easy part.
The Part Nobody Writes About¶
The three-layer post got traction because the diagnosis was clear: your agent starts every session from zero, and the fix is to give it episodic and semantic memory layers alongside the context window. I run that full stack — the ExoCortex — and have for ten weeks now. Claude Code as the agent, Synthesis for semantic memory and session indexing, MEMORY.md as a routing index, 20+ topic files for deep context, 475 skills in YAML, 3,000+ sessions indexed via FTS5, 65,905 files across 11 workspaces.
The stack works. The agent arrives knowing what it needs to know. Session start is not a blank slate. The benchmarks hold: 35-40% fewer tool calls with proper knowledge infrastructure.
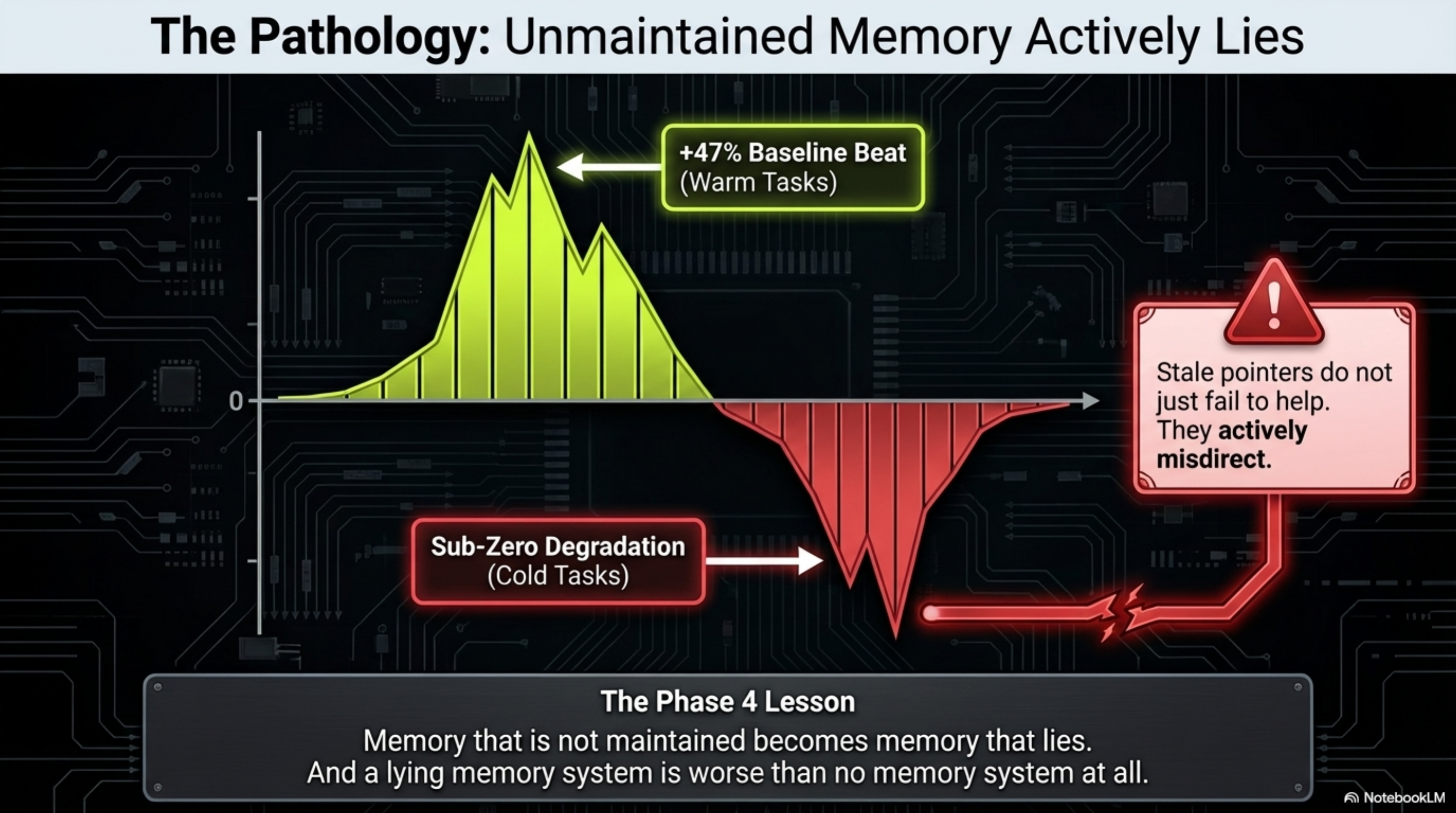
But here is what the original post did not say, because I had not lived through it yet: memory that is not maintained becomes memory that lies. And a lying memory system is worse than no memory system at all.
This is the Phase 4 lesson at the memory level. In my February benchmarks, skill files beat baseline by 47% on warm tasks — and then performed worse than having nothing on cold tasks, because wrong context is worse than no context. Stale memory pointers do the same thing. They don't just fail to help. They actively mislead.
Four Ways Memory Rots¶
I have been running the full three-layer stack in production since late January. Here are the specific rot patterns I observed, in the order I noticed them.

1. Topic Files Go Stale¶
You add a topic file about a client engagement. It contains architecture notes, contact details, meeting summaries. The engagement ends. The file stays in your routing index. Every session, the model "knows" about a project that finished two months ago.
The danger is not that the file exists. The danger is that the routing index — MEMORY.md, in my case — still points to it. A session about an entirely different client can accidentally load the stale file via keyword overlap. The model then arrives with context about the wrong engagement, and you spend the first ten minutes unwinding assumptions it should never have made.
2. Hot Topics Become Cold¶
I worked intensively on lib-pcb for 11 calendar days in January. The topic file grew to hundreds of lines. Then I moved on. Eight weeks later, the file was still in the routing index, still loaded when certain keywords appeared in conversation. The model "knew" about lib-pcb's internal architecture, even when the session was about something entirely different.
This is subtler than staleness. The content is accurate — lib-pcb's architecture has not changed. But the relevance has. Loading 400 lines of lib-pcb context into a session about regulatory compliance is pure noise. It consumes context window space and pushes out content that actually matters.
3. New Knowledge Has No Home¶
Sessions accumulate insights that never propagate to topic files. I discover a build quirk in Synthesis. I debug a deployment issue. I make a decision about API design. All of this lives in the session transcripts — the episodic layer. None of it automatically updates the topic files — the semantic layer.
Over weeks, the gap widens. The episodic layer grows (3,000+ sessions). The semantic layer stays static (the same 20 topic files, many untouched for weeks). The model can find what happened via synthesis sessions search, but the structured knowledge it loads at session start drifts further from reality.
This is the propagation problem. Knowing what happened (episodic) does not automatically update what we know (semantic). That propagation is still manual in my stack. I suspect it is manual in everyone's stack, because the alternative — automated summarisation of sessions into structured knowledge — requires an LLM in the maintenance loop, which creates a circular dependency I will come back to.
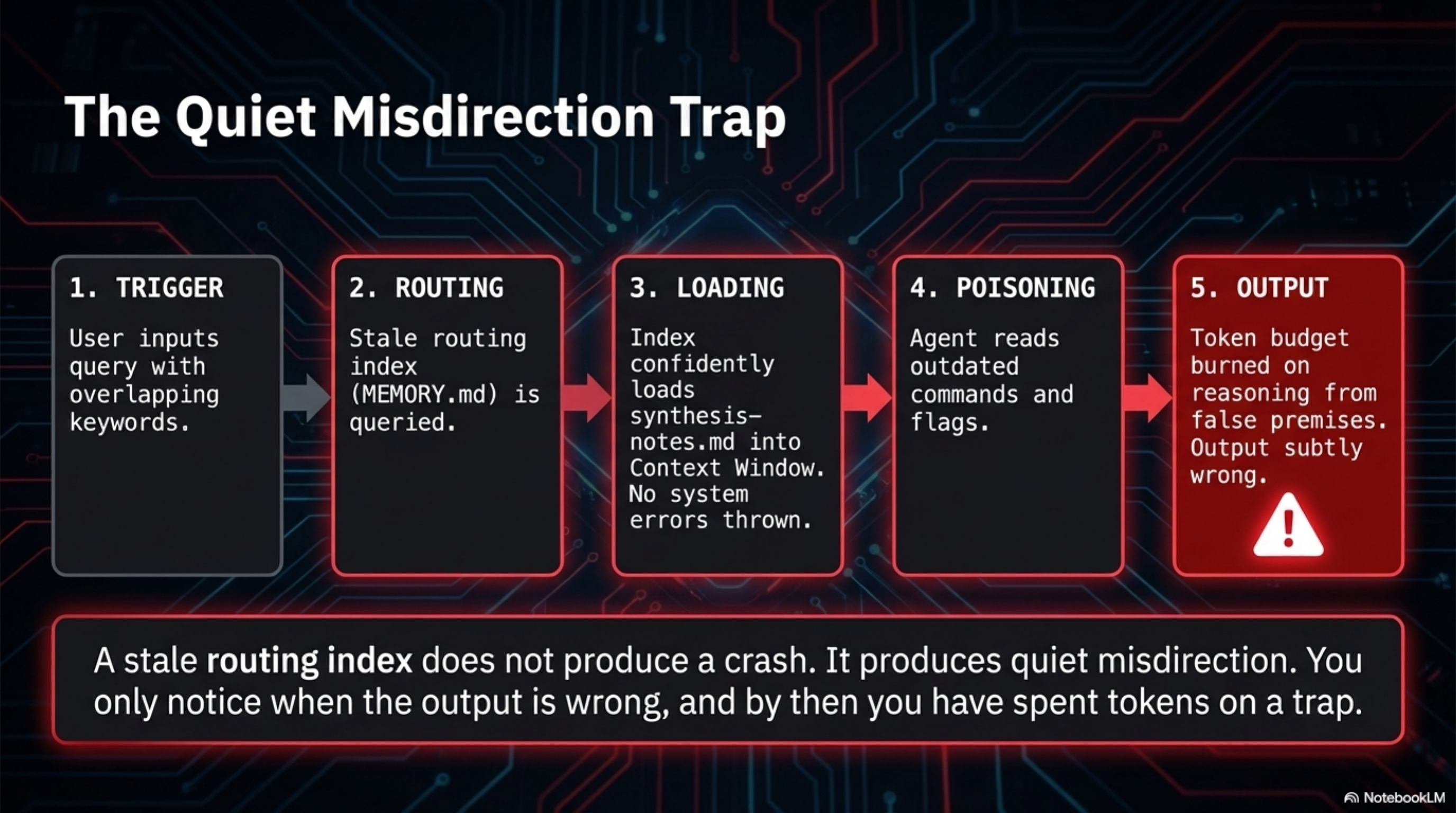
4. The Index Lies¶
MEMORY.md says: "For Synthesis CLI patterns, read synthesis-notes.md." But synthesis-notes.md was written when Synthesis was at v1.15.0. It is now v1.27.0. Twelve minor versions of changes, new commands, new flags, changed behaviours. The pointer in MEMORY.md is valid — the file exists, the path is correct. The knowledge behind the pointer is stale.
A stale routing index does not produce an error. It produces quiet misdirection. The model loads synthesis-notes.md, reads about commands that no longer exist or flags that have changed, and proceeds with outdated assumptions. You only notice when the output is wrong, and by then you have spent tokens on reasoning from bad premises.
The Principle: Freshness Beats Completeness¶
Running the full stack for ten weeks forced a principle I would not have articulated from theory alone:
A thin, current index is worth more than a comprehensive, stale one.
Five entries in MEMORY.md that are all accurate right now are more useful than fifty entries where thirty percent of the links point to outdated content. This feels counterintuitive — more knowledge should be better. But more knowledge is only better if the knowledge is true. When it is not, every additional entry is a potential misdirection.
The corollary: the maintenance burden of a memory system is proportional to its size. A small memory system that you can keep current is strictly better than a large one that rots. "Memory yields to reality. Always." is the operating principle. But you need infrastructure to enforce it, because the natural tendency is accretion without pruning.

What We Built: topic-health and topic-triage¶
Synthesis v1.27.0 ships two new commands that address memory rot directly. Neither uses an LLM. Both run in milliseconds.
topic-health: Who's Hot, Who's Cold¶
synthesis topic-health scans all markdown files in the memory directory, extracts keywords from filenames, and queries the session store via FTS5 to count how many sessions referenced each topic in the last 30 days. It then computes a hotness score:
The formula weights session engagement at 60% and recency at 40%. A topic file that appears in many recent sessions scores high. A topic file that nobody has referenced in weeks and has not been modified in two months scores low.
Output: a HOT / WARM / COLD classification for each file, sorted by hotness. HOT is anything above 0.6. WARM is 0.3 to 0.6. COLD is below 0.3.

The signal is behavioural, not content-based. We do not analyse what the topic files say to decide if they are stale. We look at whether the practitioner's sessions keep referencing the topic. If I am working on Synthesis development every day, synthesis-notes.md has high session hits and scores HOT. If I have not touched lib-pcb in eight weeks, its topic file has zero recent hits and scores COLD.
This distinction matters. Content analysis would require an LLM — you would need to read the file, understand what it says, and determine whether it is still accurate. Behavioural analysis requires only a count query against the FTS5 index. The implementation is ~250 lines of Java. No model call. No API key. No latency. The information it produces is less nuanced than what an LLM could tell you, but it is available in milliseconds and does not create a circular dependency.
topic-triage: What Needs Attention¶
synthesis topic-triage goes a step further. It scores each topic file on four dimensions:

- Recency (0.3 weight): When was the most recent session that referenced this topic? Within 7 days = 1.0. Within 14 days = 0.7. Within 30 days = 0.4. Older = 0.1.
- Recurrence (0.25 weight): How many distinct sessions reference this topic? Three or more sessions in the lookback window = 1.0. Scaled linearly below that.
- Actionability (0.25 weight): Does the file contain prescriptive content? It scans the first 50 lines for patterns like "always," "never," "must," "critical," "before," "instead of." The presence of these patterns suggests the file contains operational rules, not just historical notes.
- Staleness (0.2 weight, inverted): How long since the file was last modified? 60+ days = maximum staleness. The composite inverts this:
0.2 * (1 - staleness), so fresher files score higher.
The composite score determines a recommendation for the top 5 files needing attention:
Each file gets one of four recommendations:

- ARCHIVE — staleness > 0.8 and recurrence < 0.2. Nobody references this, and it has not been updated in a long time. Remove the routing entry.
- PRUNE — more than 300 lines with recurrence < 0.4. Large file, low engagement. Cut it down.
- UPDATE — recency < 0.4 but recurrence > 0.6. People keep referencing this topic, but the file itself is old. It needs a refresh.
- KEEP — everything else. No action needed.
Advisory only. No files are modified. The system tells you what to look at; the human decides what to cut.
ConsolidateState: Preventing Redundant Runs¶
Running topic-triage twice in an hour is wasteful. Running it never is worse. ConsolidateState persists an atomic JSON file at ~/.synthesis/consolidate-state.json tracking two values: when topic-triage last ran, and how many sessions existed at that time.
The --auto flag enforces a dual threshold: at least 24 hours since last run AND at least 5 new sessions since last run. Both conditions must be met. This prevents two failure modes:
- Running triage on a quiet weekend when nothing has changed (time threshold met, session threshold not met).
- Running triage every hour during an intensive work day (session threshold met, time threshold not met).
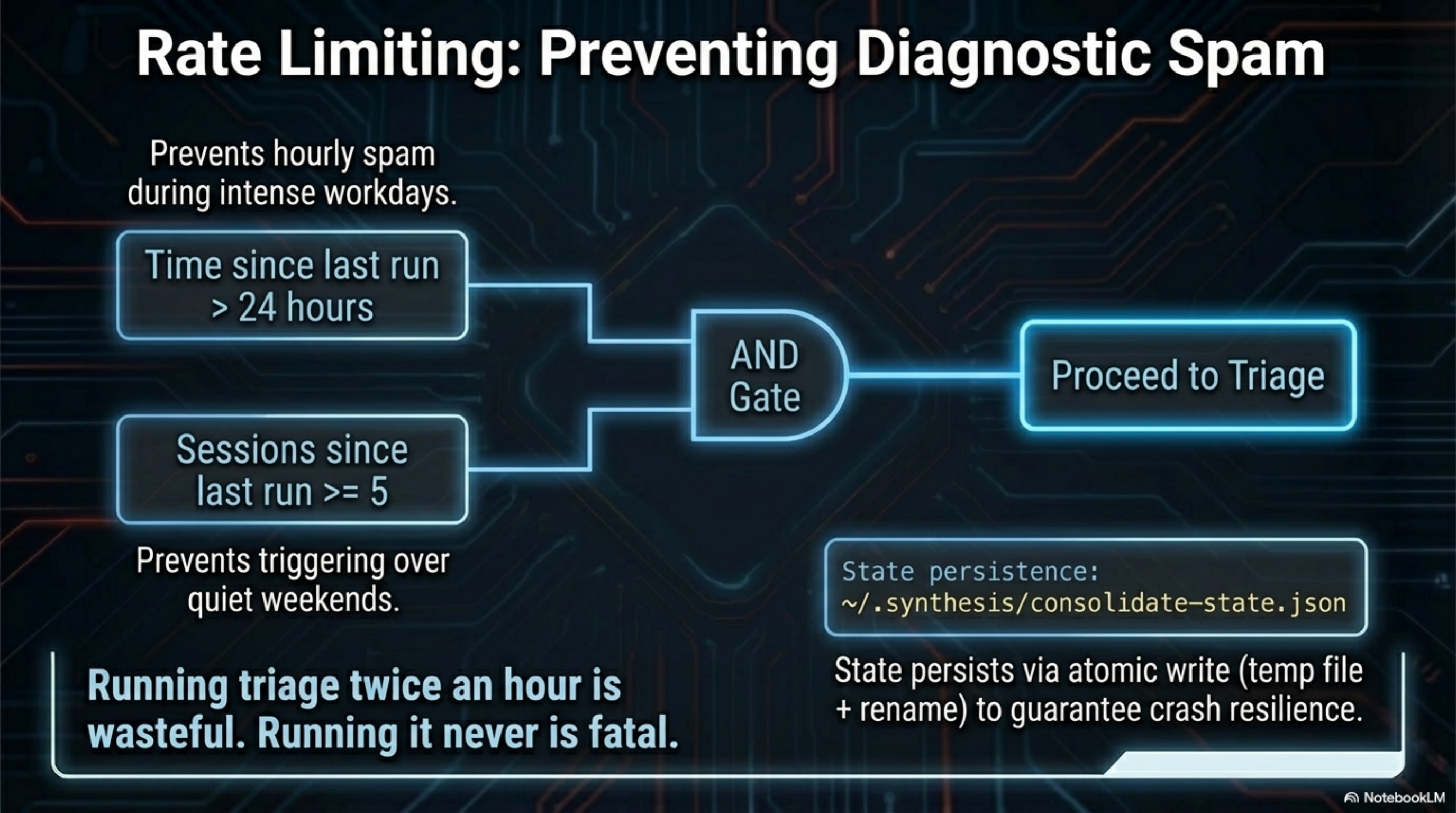
The write is atomic — temp file plus rename — so a crash during persistence cannot corrupt the state file.
The Nightly Cycle¶
The maintenance automation runs on the local machine:
02:30 Oslo — synthesis maintain (re-indexes files, updates knowledge graph)
02:45 Oslo — synthesis topic-triage --auto (evaluates dual threshold, scores memory files)
The topic-triage output appends to ~/.synthesis/topic-triage-log.jsonl — one JSON record per run, with trigger type (auto or manual), sessions since last run, files scanned, and the scored suggestions with per-dimension breakdowns.

I review the log periodically. When something shows as ARCHIVE, I check whether the routing entry in MEMORY.md should be removed. When something shows as UPDATE, I spend five minutes refreshing the topic file with current information. When something shows as PRUNE, I cut lines that are no longer relevant.
This is not glamorous work. It is the maintenance equivalent of taking out the trash. But the alternative — letting the memory system accumulate stale entries indefinitely — is how you end up with a routing index where the model loads outdated context in 30% of sessions and you cannot figure out why its responses are slightly wrong.
Why No LLM in the Maintenance Loop¶
Both topic-health and topic-triage run without any LLM calls. This is a deliberate architectural choice, not a limitation.
If memory maintenance required an LLM, you would have a circular dependency: you need memory to use the LLM effectively (the whole point of the three-layer architecture), but you need the LLM to maintain memory. Every maintenance run would consume tokens. Every maintenance failure would require a model call to diagnose. The maintenance system would inherit the failure modes of the system it is maintaining.

The behavioural signal — session hits per topic keyword — is less sophisticated than what an LLM could produce. An LLM could read each topic file, compare it to recent session content, and generate a nuanced assessment of what is stale and what is still relevant. That assessment would be better than a hotness formula.
But the hotness formula runs in milliseconds, costs nothing, requires no API key, and works at 02:45 when no human is watching. It is good enough to surface the files that need attention. The human judgment about what to do with those files is where nuance matters, and that is where the human stays in the loop.

The broader principle: keep your maintenance infrastructure simpler than the system it maintains. If the maintenance layer is as complex as the operational layer, you need a maintenance system for the maintenance system, and you have an infinite regress.
Known Limitations (Honest)¶
The False-Hot Problem¶
Topic-health extracts keywords from filenames. java-refactoring.md generates keywords "java" and "refactoring." If 40 sessions mention "Java" for unrelated reasons — I write a lot of Java — then java-refactoring.md scores HOT even if nobody has thought about Java refactoring patterns in weeks.
Short, generic filenames are worst. mistakes-to-avoid.md has keywords "mistakes" and "avoid." Every session where someone discusses avoiding anything triggers a false hit. Distinctive filenames like ironclaw-infrastructure.md perform better because "ironclaw" is a rare term.
The fix is probably TF-IDF weighting that penalises common terms, or embedding-based similarity that captures topical relevance rather than keyword overlap. I have not built that. The current formula is useful but noisy, and I know exactly where the noise comes from.
The Episodic-Semantic Gap Remains Open¶
Knowing what happened in past sessions does not automatically update what the topic files say. I discover in a session that synthesis export now supports a --filter flag. That fact lives in the session transcript. It does not appear in synthesis-notes.md. The topic file is wrong by omission, and topic-triage has no way to detect this — it measures engagement, not accuracy.
Closing this gap properly requires either automated propagation (LLM reads sessions, updates topic files) or structured session annotations (the practitioner tags insights during sessions for later extraction). Both have costs. Automated propagation reintroduces the LLM dependency I want to avoid in maintenance. Structured annotations add friction to the session workflow.

synthesis reflect — the skill synthesis layer — is the closest thing I have to automated propagation. It reads sessions and generates YAML skill files. But it operates on skill files, not on memory topic files. Extending reflect to update memory topics is conceptually straightforward and practically tricky, because topic files have a different structure and a different failure mode than skills.
The Warm/Cold Tension at the Memory Level¶
The Phase 3/4 benchmark finding — skills help for warm tasks, hurt for cold tasks — applies identically to memory topic files. A memory routing entry that points to the right topic file for the current task is a teleport. A routing entry that points to the wrong file is a trap.
Topic-triage reduces this risk by identifying stale entries, but it cannot eliminate it. The fundamental tension is that you cannot know at session start whether today's task will be warm (covered by existing topic files) or cold (not covered). Pre-loading too many topic file pointers wastes context. Pre-loading too few leaves the model uninformed. The optimal configuration is task-dependent, and you do not know the task until the session starts.
What This Means for Anyone Building Agent Memory¶
You do not need my specific stack. The patterns transfer.

1. Budget for maintenance from day one. If you are building a memory system for an AI agent — any memory system, any agent — plan for how you will maintain it. Not "eventually." On day one. The memory will rot. The question is whether you have instrumentation to detect the rot and a process to address it.
2. Measure engagement, not just content. Content analysis tells you what the memory says. Engagement analysis tells you what the memory is used for. The second signal is cheaper to compute and more actionable. If a memory artefact has not been referenced in 30 days, it does not matter how accurate its content is — it is noise in the system.
3. Keep maintenance simpler than operations. If your memory maintenance requires the same LLM that uses the memory, you have a circular dependency. Use cheaper signals — counters, timestamps, keyword hits — for the maintenance loop. Save the expensive reasoning for the operational loop where it produces value.
4. Freshness beats completeness. A small, current memory is better than a large, partially stale one. Prune aggressively. A routing index with five accurate entries beats one with fifty entries and fifteen stale ones. The stale entries are not neutral — they actively mislead.
5. Make it advisory, not automatic. The system should tell you what to look at. The human should decide what to cut. Automated pruning sounds attractive until it deletes the one topic file you needed for next week's engagement. Advisory-only output with human review is slower but safer, especially for a system where the cost of a bad deletion is re-creating knowledge from scratch.
6. Nightly, not real-time. Memory maintenance does not need to be instantaneous. A nightly pass that identifies files needing attention is sufficient for most workflows. Real-time maintenance adds complexity without proportional benefit — you are unlikely to notice a stale topic file mid-session, and by the time the session ends, the nightly pass is close enough.
The Arc¶
The March post said: your agent has one memory layer and needs three. Build them.
This post says: you built them. Now they are rotting. Here is what the rot looks like, why it matters, and the tooling that detects it.
The next post will probably say: the detection works, but the propagation from episodic to semantic is still manual, and that is where the real friction lives. Each layer addresses the failure mode of the previous one. Memory management is no different.
Ten weeks in. 3,000+ sessions. 65,905 files indexed. 19 topic files in the routing index, down from a peak of about 25 — the ones that got pruned were all COLD. The system is smaller than it was a month ago, and it works better.
Freshness beats completeness. We validated it the hard way.
Totto is the founder of eXOReaction, an enterprise architecture consultancy in Oslo. He builds Synthesis, the ExoCortex, and the KCP specification. Thirty-plus years of enterprise systems, currently figuring out how to keep AI memory from lying to him.