The Human in the Loop — at Design Time¶
Tim O'Reilly posted something this week about craftsmanship in the AI age. The question he was circling: how do you maintain quality standards when agents are doing the work?
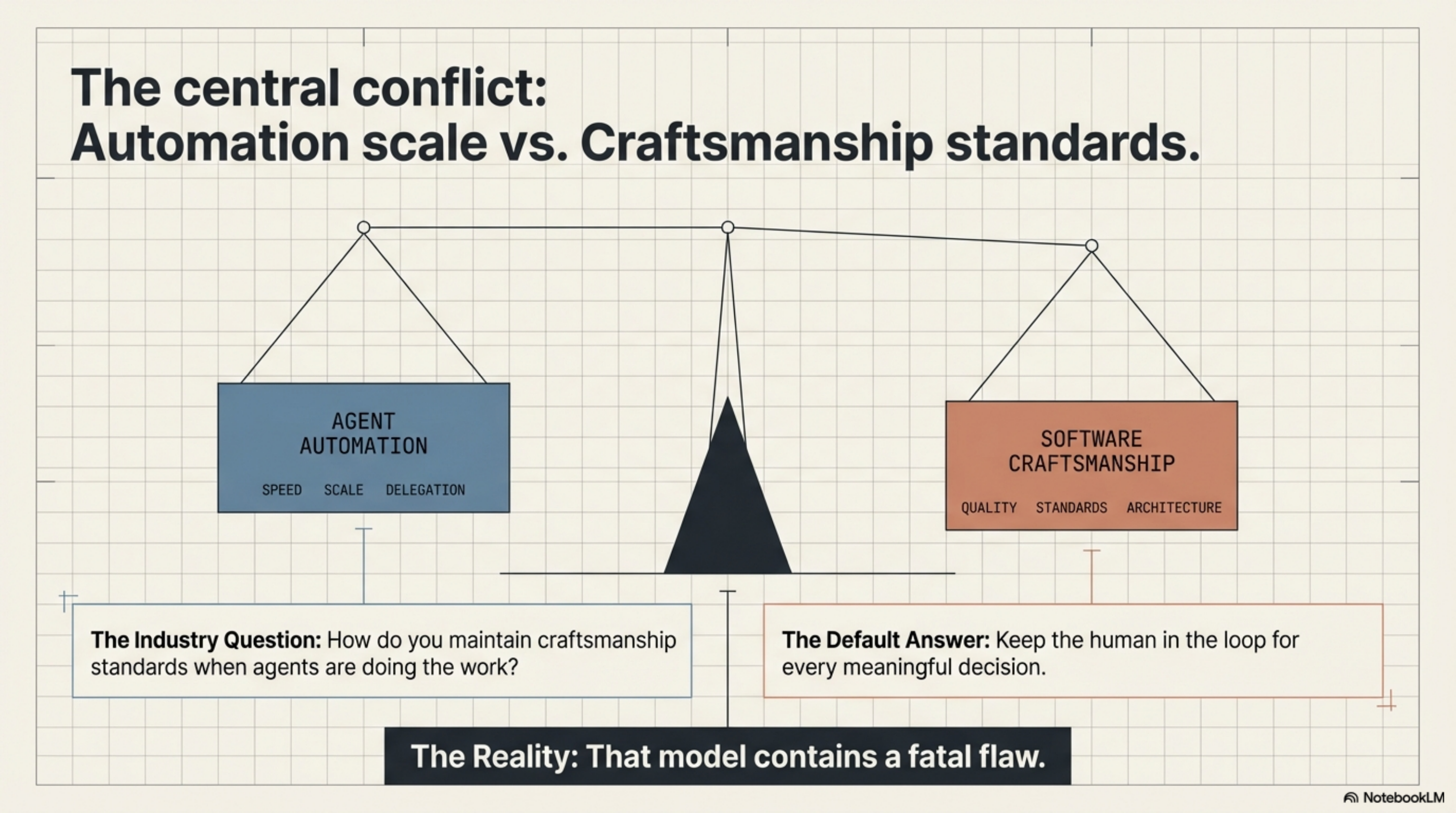
The default answer in the industry is: keep the human in the loop. For every meaningful decision, have a human review before proceeding.
That model contains a fatal flaw.

The central conflict¶
The tension is real. Agent automation gives you speed, scale, and delegation. Software craftsmanship requires quality, standards, and architectural judgment. These are not naturally compatible at volume.
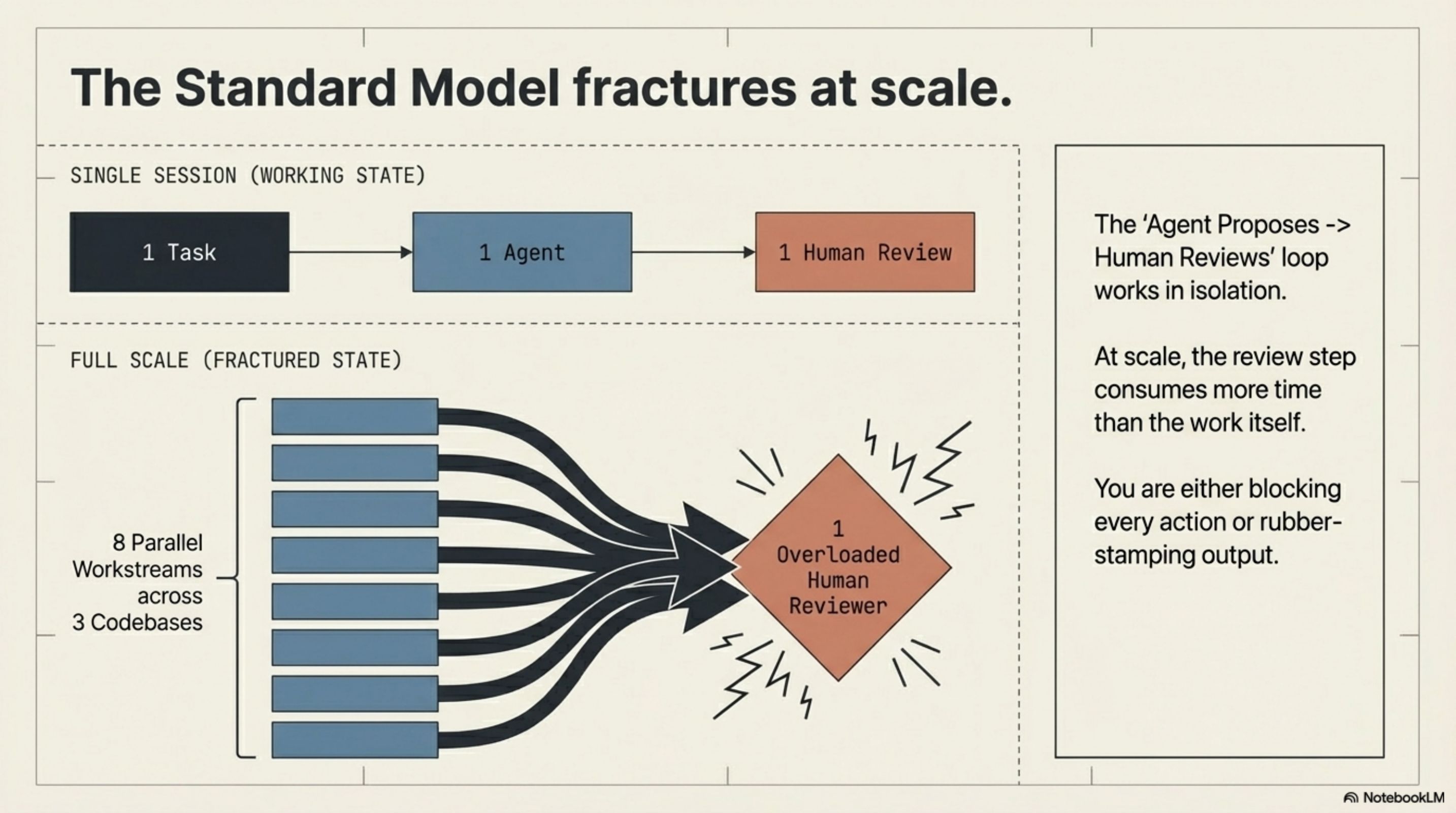
The industry default — agent proposes, human reviews, agent proceeds — works in a single session. The problem appears at scale.
The review bottleneck¶
When you run one agent on one task, the review step is manageable. When you run eight parallel workstreams across three codebases, the same review step becomes the bottleneck. You are either blocking every action waiting for human approval, or you are rubber-stamping output you don't have time to genuinely evaluate.
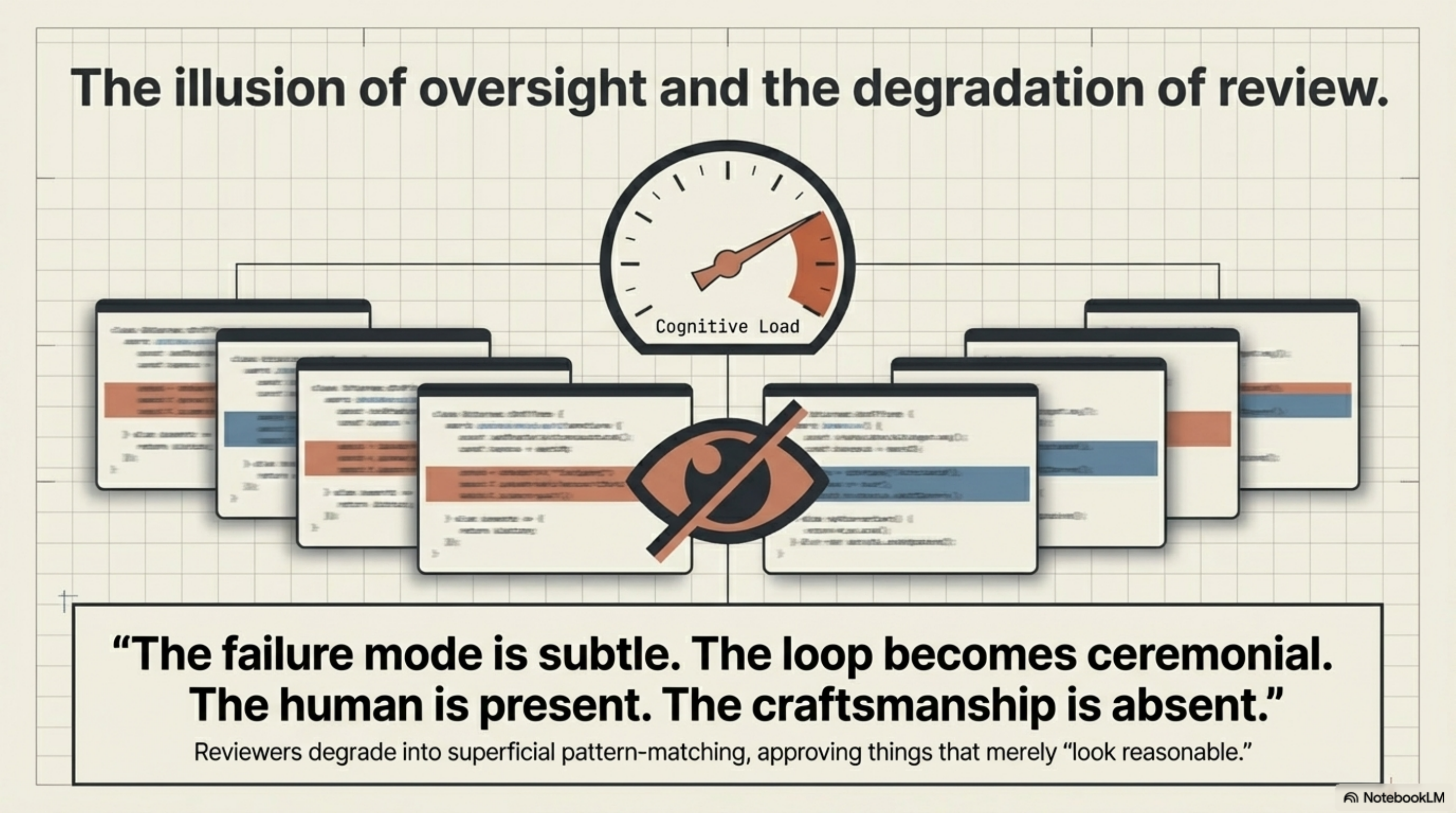
The failure mode is subtle. The review loop doesn't disappear — it continues to run. But the quality of the reviews degrades as cognitive load rises. The human is present. The craftsmanship is absent.
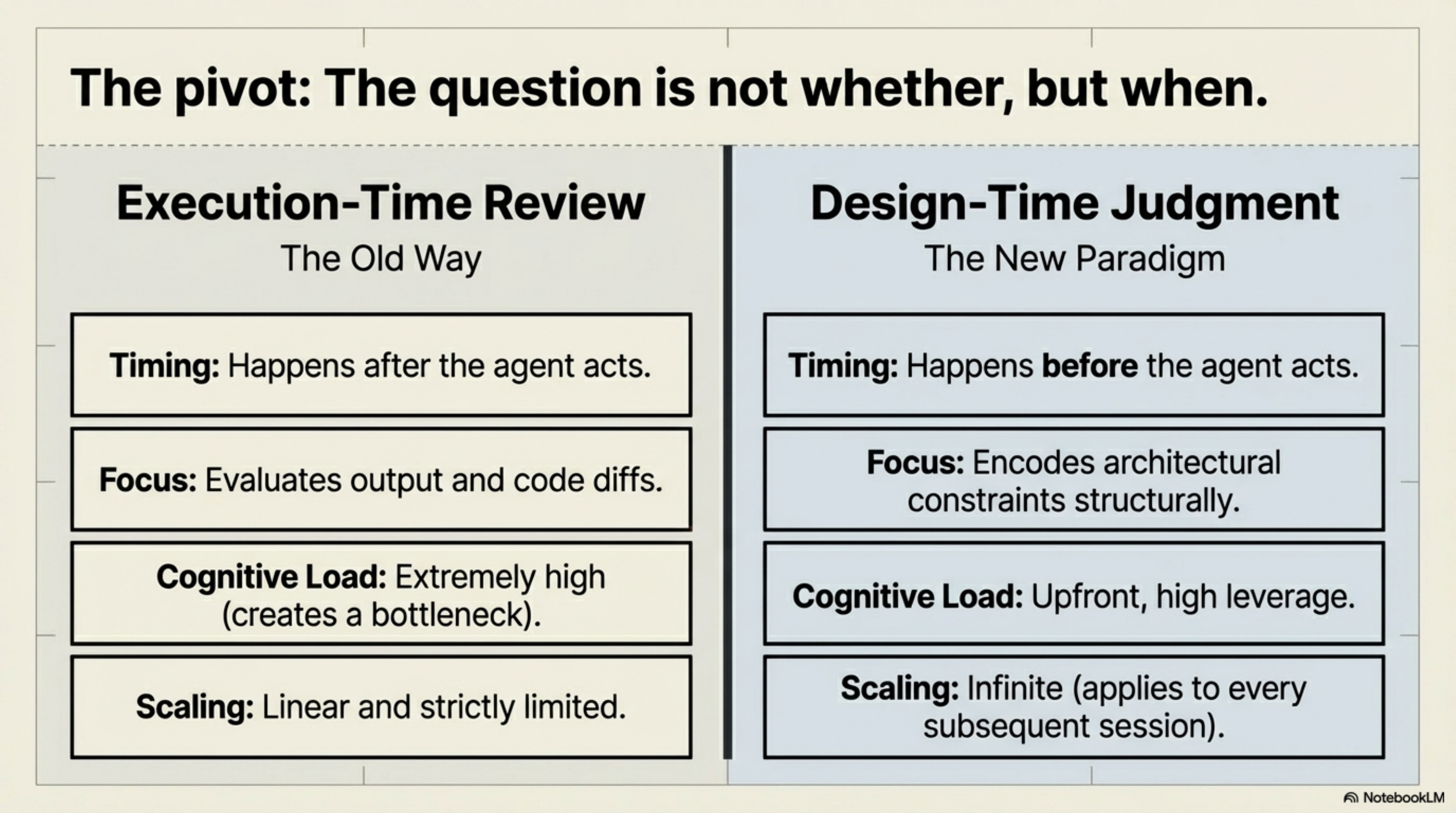
The pivot¶
The question is not whether to have humans in the loop. It is when.
Execution-time review — happening after the agent acts — is high cognitive load, creates bottlenecks, and scales linearly at best. Design-time judgment — happening before the agent acts — is upfront investment, high leverage, and scales to every subsequent session.
Encoding judgment before the loop starts¶
What does design-time judgment look like in practice?
Over the past year I've been building three types of infrastructure that encode it: knowledge.yaml manifests that describe repositories, dependencies, and baseline conventions; a Synthesis workspace graph that maps file relationships, security posture, and temporal changelogs; and skill files that encode domain-specific structural knowledge in YAML.
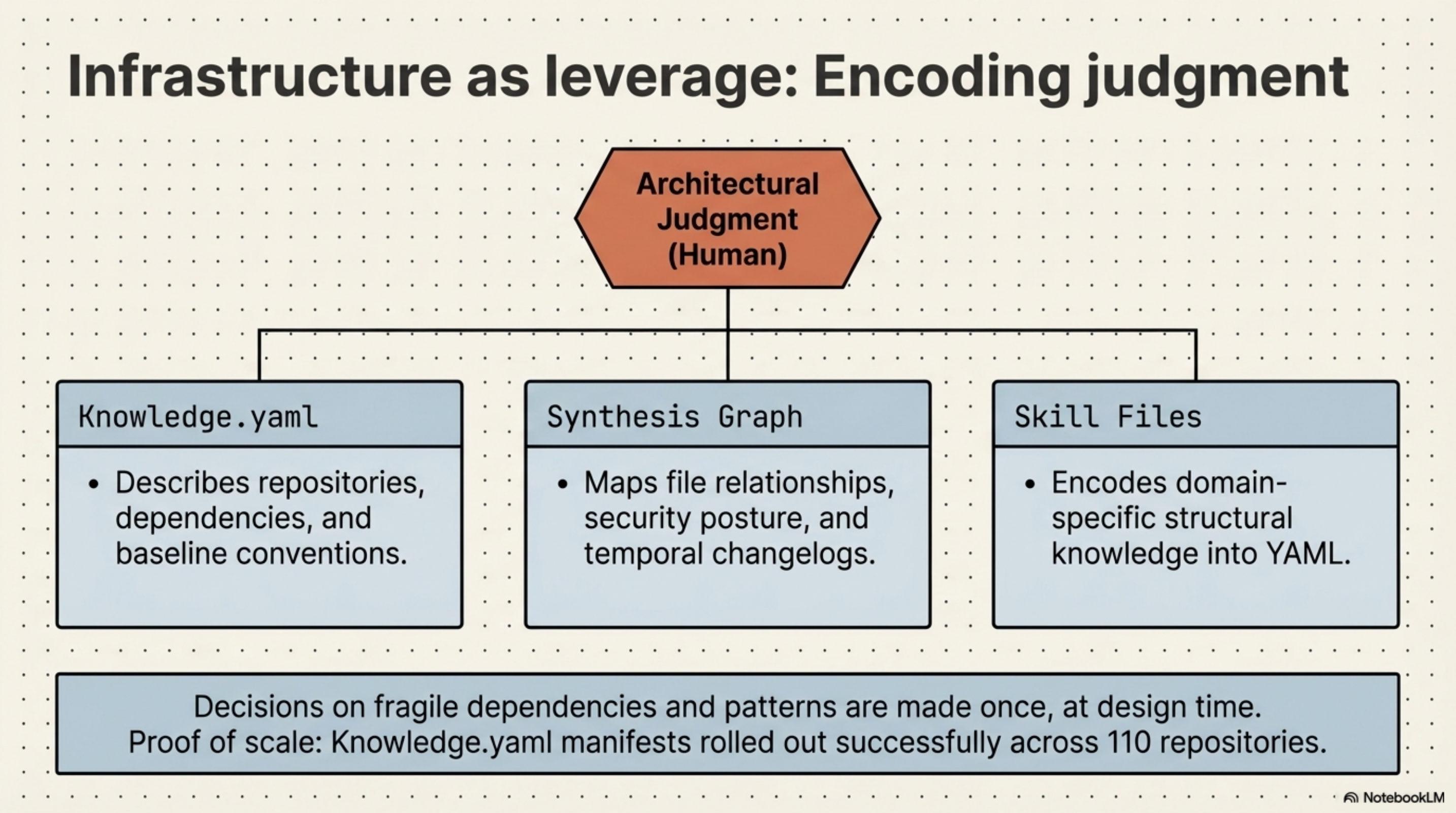
The decisions about fragile dependencies, risky patterns, and architectural constraints are made once, at design time. After that, every agent session that runs on this codebase inherits those constraints without requiring a human to re-apply them.
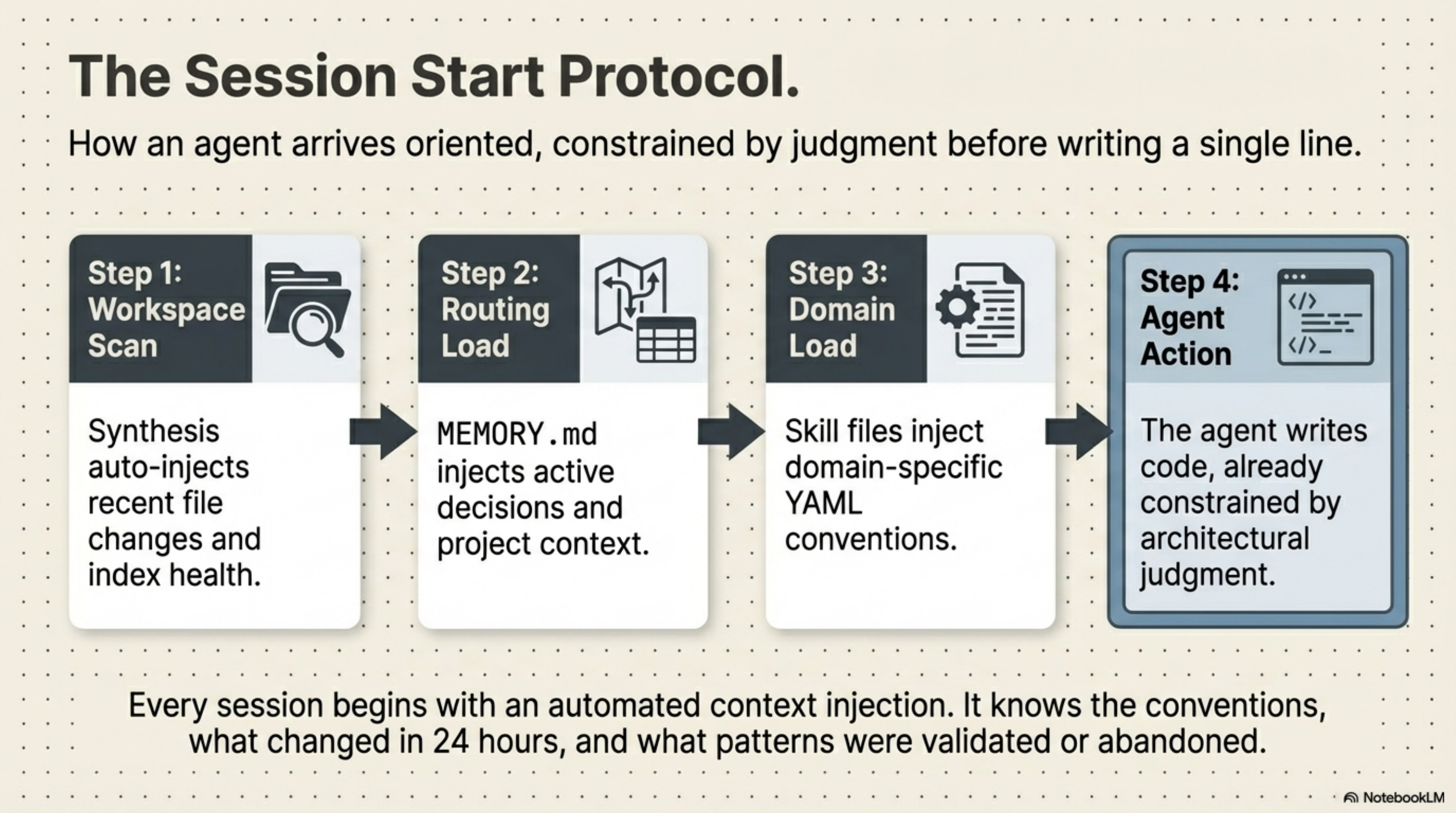
This is what the session start protocol looks like in practice: Synthesis auto-injects recent file changes and index health. MEMORY.md injects active decisions and project context. Skill files inject domain-specific conventions. By the time the agent writes a single line of code, it is already constrained by accumulated architectural judgment.
The continuity problem¶
Craftsmanship is cumulative. It is the residue of a hundred past decisions — patterns that were tried and rejected, constraints that were discovered the hard way, approaches that turned out to matter in ways that weren't obvious at the start.
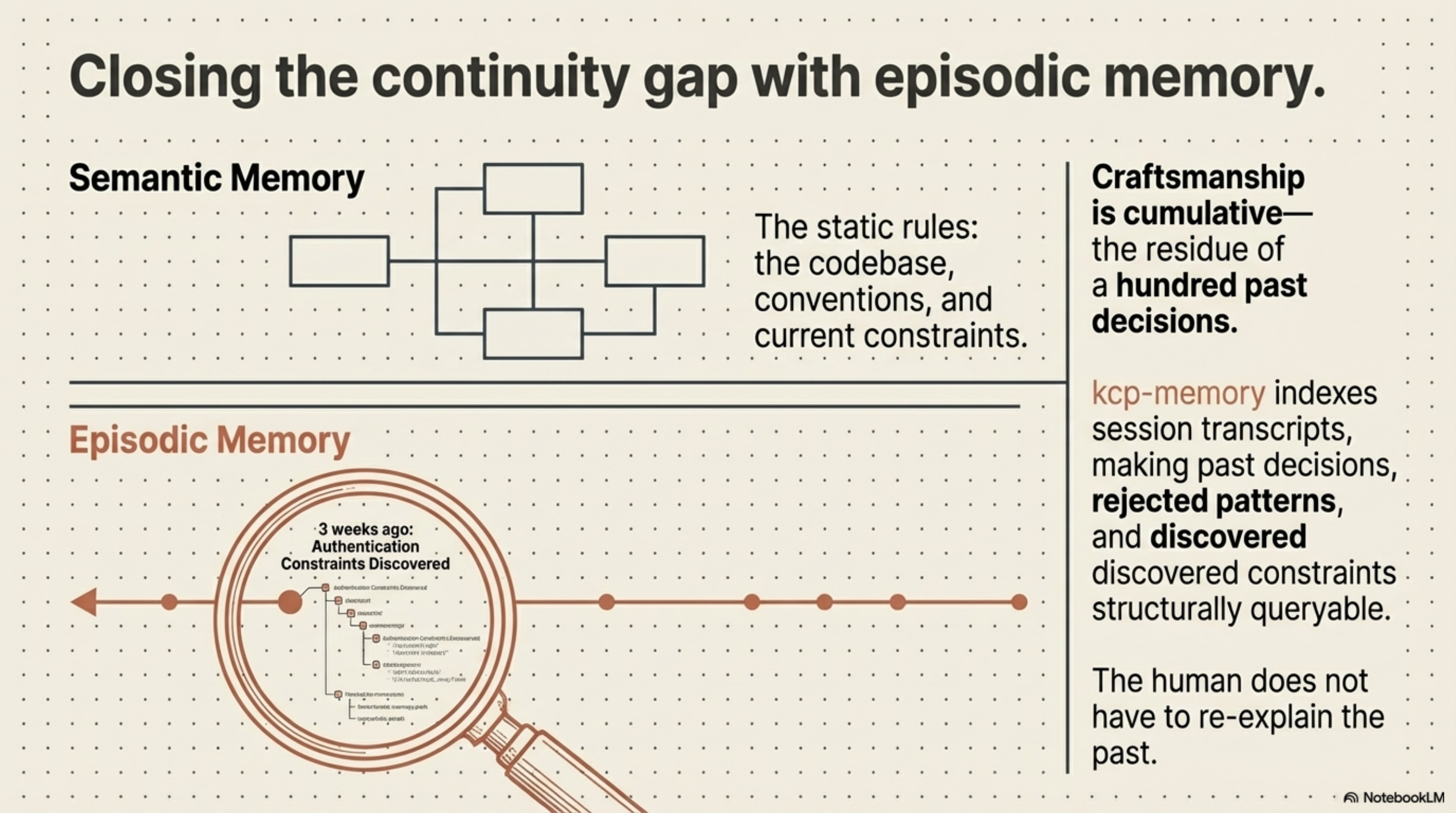
The gap between what a new session knows and what previous sessions learned is where craftsmanship leaks out. kcp-memory addresses this by indexing session transcripts and making past decisions, rejected patterns, and discovered constraints structurally queryable. The human does not re-explain the past. The infrastructure carries it forward.
The ExoCortex as architecture¶
What I've been building is a four-layer stack: Claude Code at the execution layer, Synthesis at the state layer, KCP and skill files at the knowledge layer, and kcp-memory at the continuity layer.
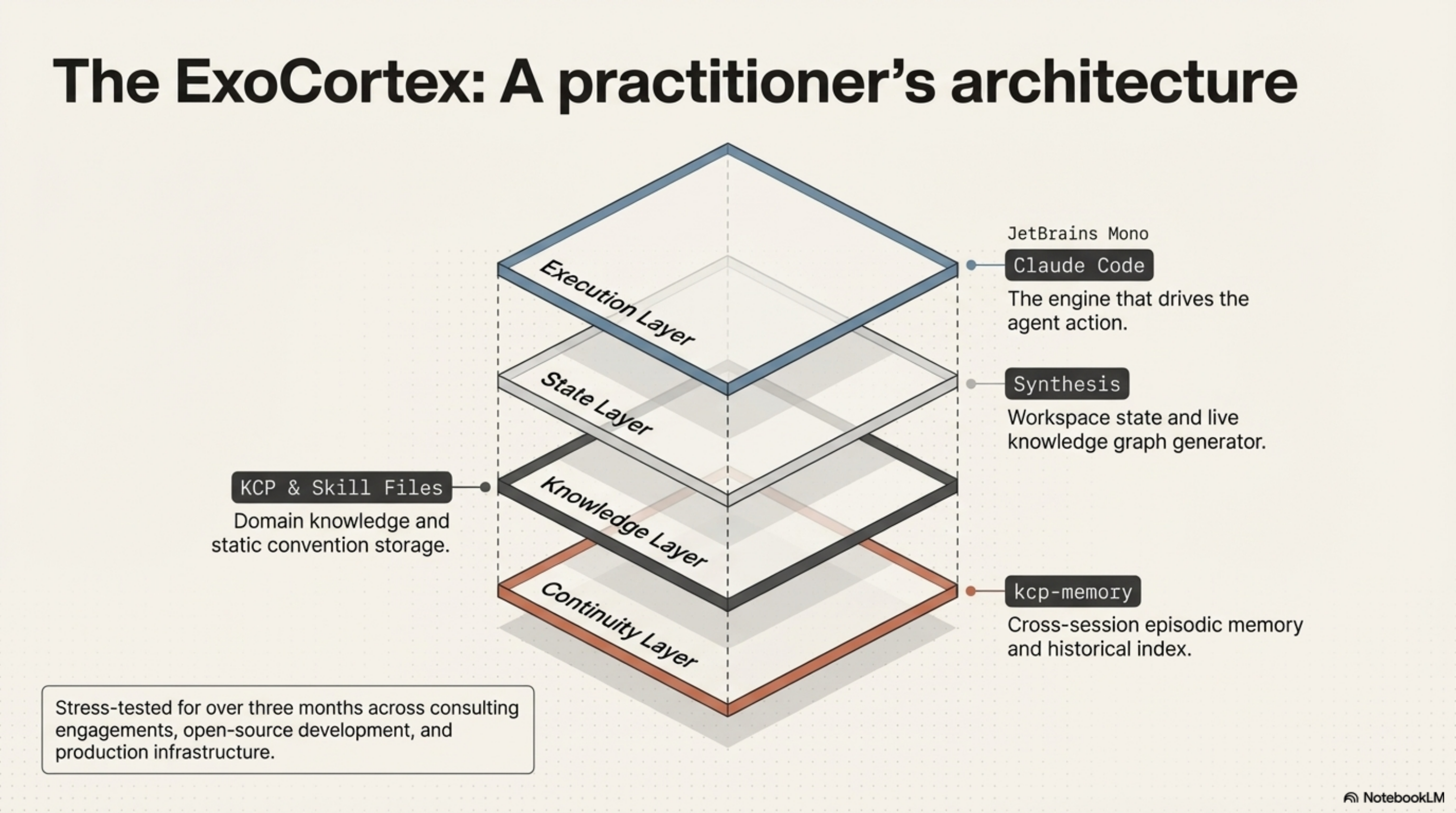
This isn't a product. It's a practitioner's architecture, built from specific problems encountered across three months of production use. Each layer exists because the one above it kept failing without it.
This is not a solved problem¶
I want to be honest about the limits. The bridge between episodic and semantic memory still requires a human to make the connection — to notice that a past session discovered something important and ensure it gets encoded into the static layer. Stale skill files are a persistent risk: conventions that were correct six months ago but no longer apply.
But this maintenance is itself the new form of human judgment. Instead of reviewing individual code changes at agent speed, the human is tending the infrastructure that shapes every agent action. The leverage ratio is completely different.
The reframe¶
Stop asking: "How do we keep humans reviewing agent output fast enough?"
Start asking: "How do we make human judgment persistent enough that it does not need to be re-applied at every step?"

Human-in-the-loop does not mean human-at-every-step.
It means human-at-the-design-step.
The visual companion to this post — a slide deck generated from these field notes — is available here: Scaling Craftsmanship at Design Time