The Agentic Stack: Every Layer Was Built for Humans¶
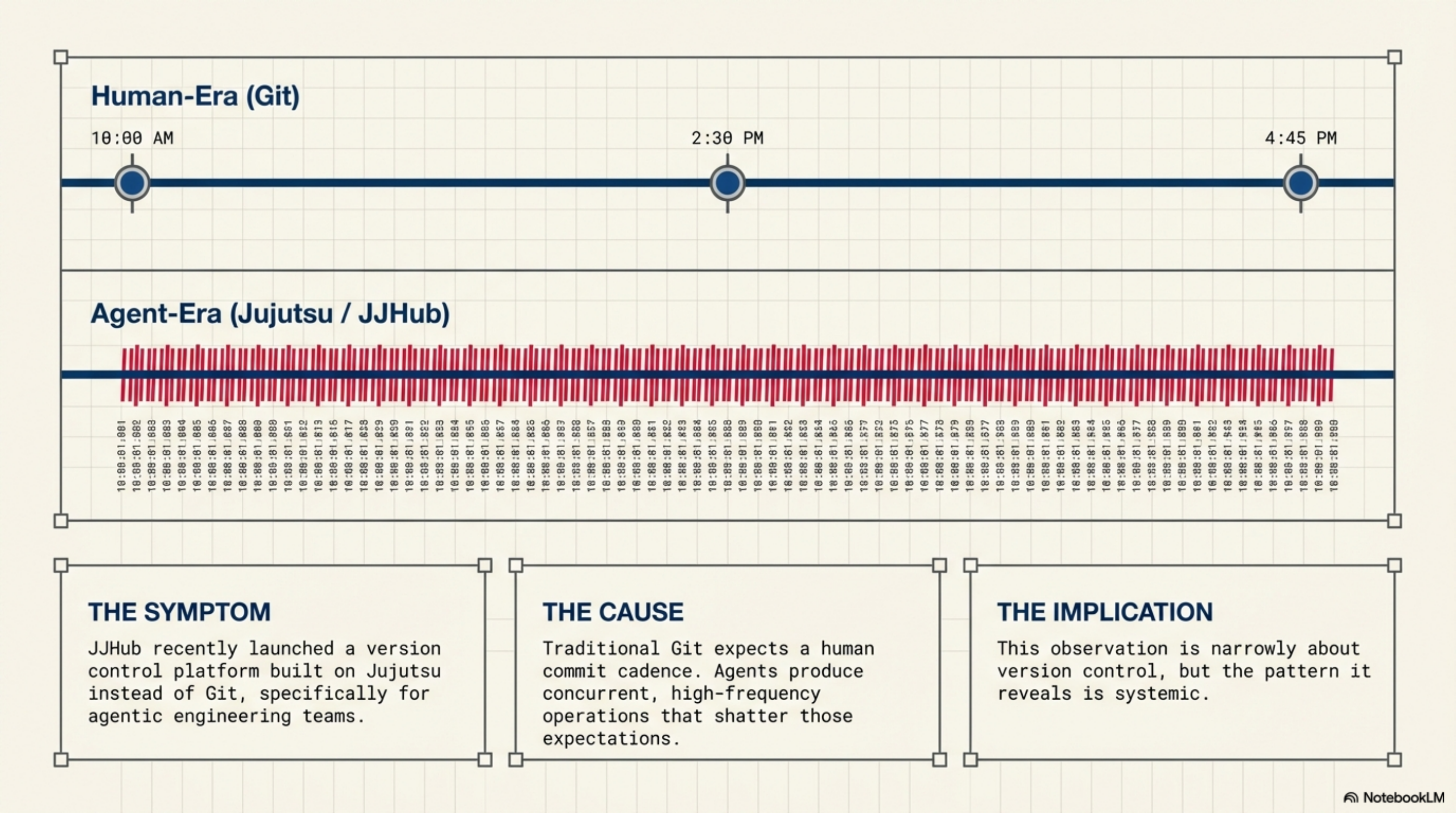
Something caught my attention this week. JJHub launched a version control platform built on Jujutsu instead of Git, designed specifically for agentic engineering teams. The premise: Git's data model breaks under the commit volume that agents produce.
That observation is narrowly about version control. But the pattern it reveals is much broader.
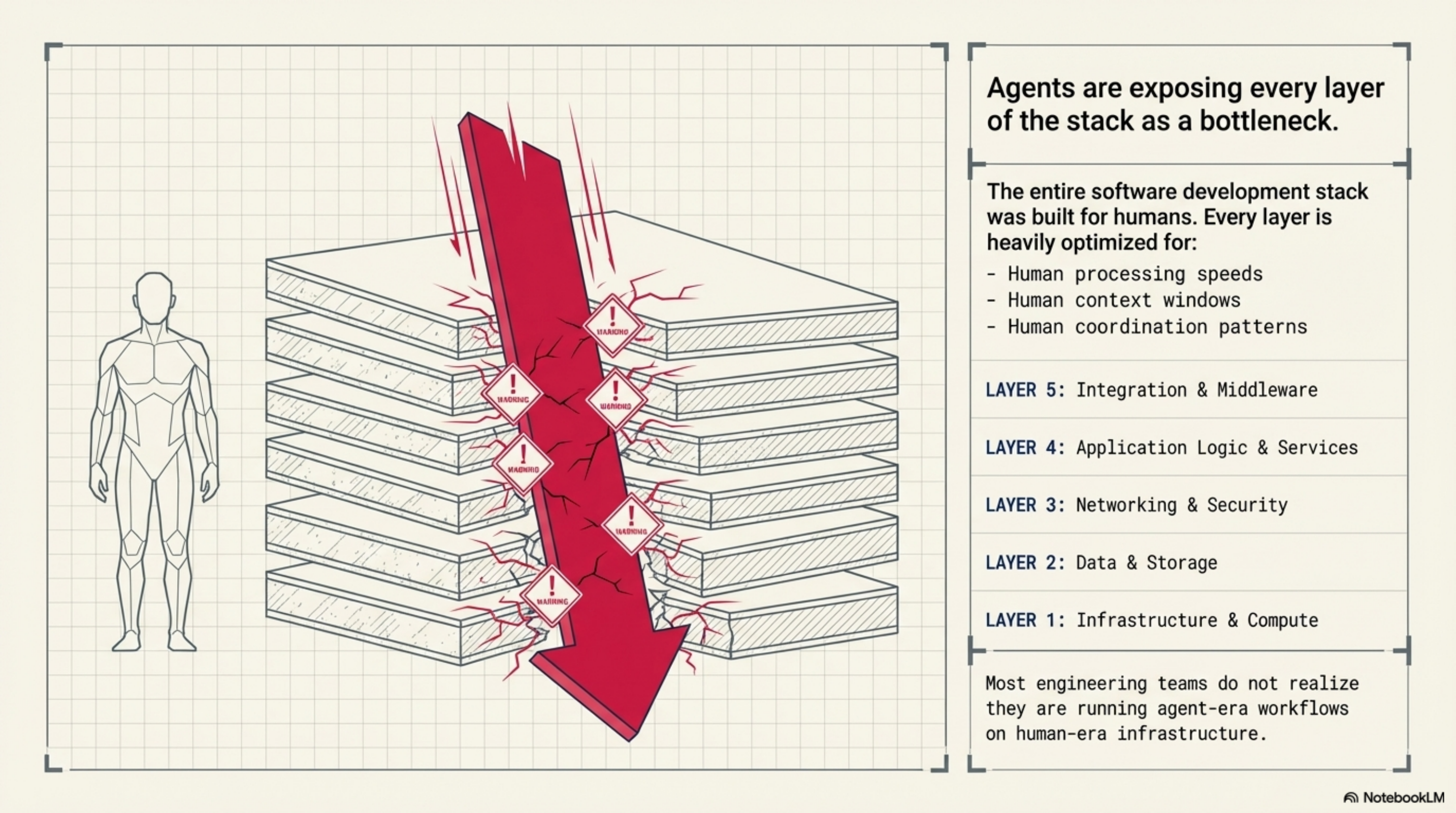
The entire software development stack was built for humans. Every layer optimised for human processing speed, human context windows, human coordination patterns. And now, layer by layer, agents are exposing each one as a bottleneck.
Most teams don't realise they're running agent-era workflows on human-era infrastructure.
The stack that's being rebuilt¶
| Layer | Human-era assumption | What agents need |
|---|---|---|
| Version control | Git (human commit cadence) | Jujutsu / JJHub (high-frequency, concurrent) |
| Knowledge / context | README files, wikis, onboarding docs | Structured context protocols (KCP, etc.) |
| Tool integration | SDKs, manual documentation | Model Context Protocol (MCP) |
| Orchestration | Manual workflow coordination | CrewAI, autogen, smolagents |
| Identity / auth | OAuth, personal access tokens | SPIFFE, AgentControl |
| CI/CD feedback | Human code review | Agentic CI with automated judgment |

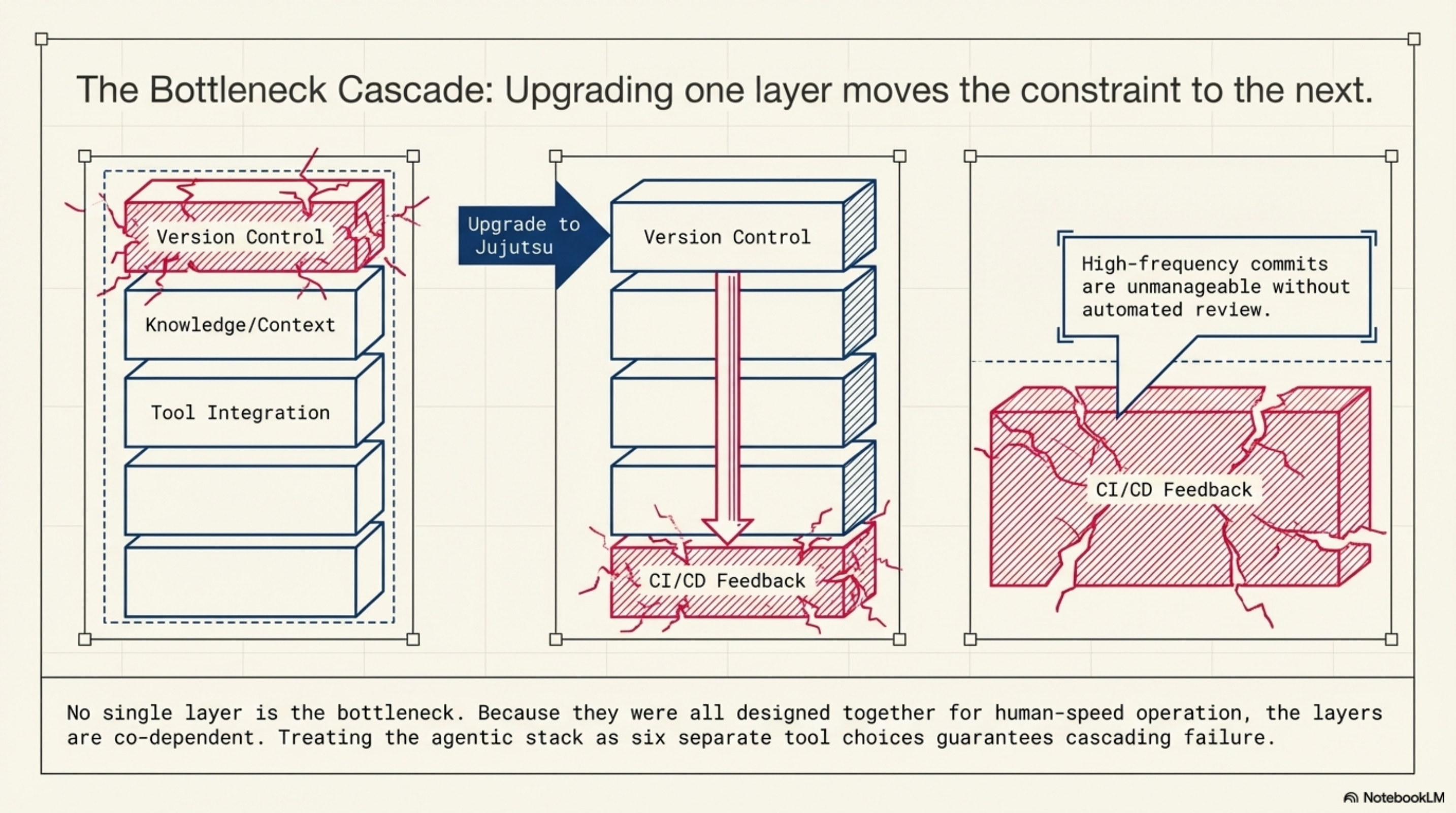
No single layer is the bottleneck. They all are. And because they were all designed together for human-speed operation, upgrading one layer often just moves the constraint to the next.
Consolidated fragility¶
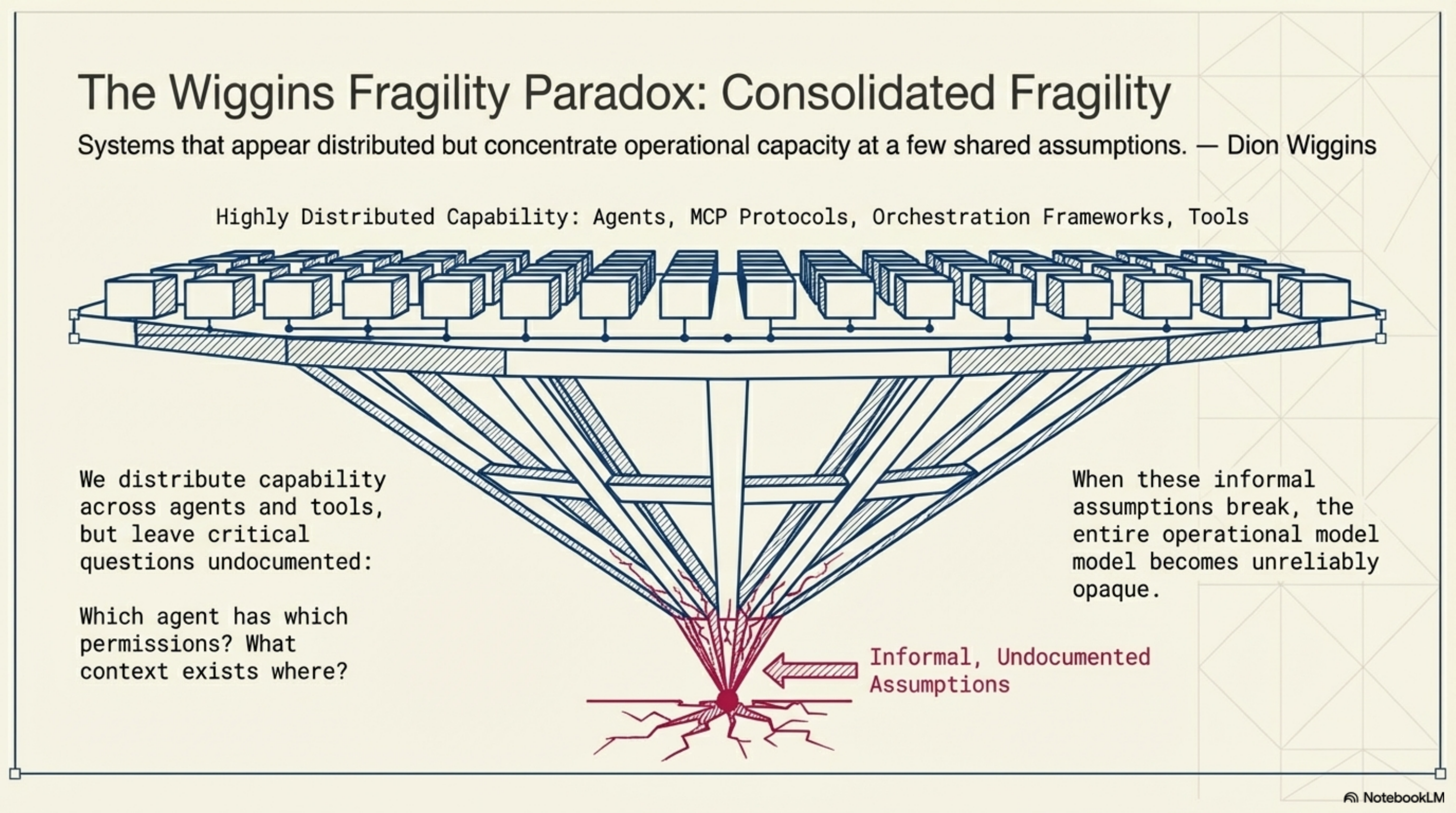
Dion Wiggins used a phrase recently that stuck with me: "consolidated fragility." Systems that appear distributed but concentrate operational capacity at a few shared assumptions.
That describes the current agentic stack precisely. We distribute capability across agents, tools, and protocols, but concentrate critical assumptions in informal, undocumented places. Which agent has which permissions. What context exists where. Who controls the definitions. When those assumptions break — and they do — the failure mode is not a single component going down. It is the entire operational model becoming unreliable in ways that are hard to diagnose.
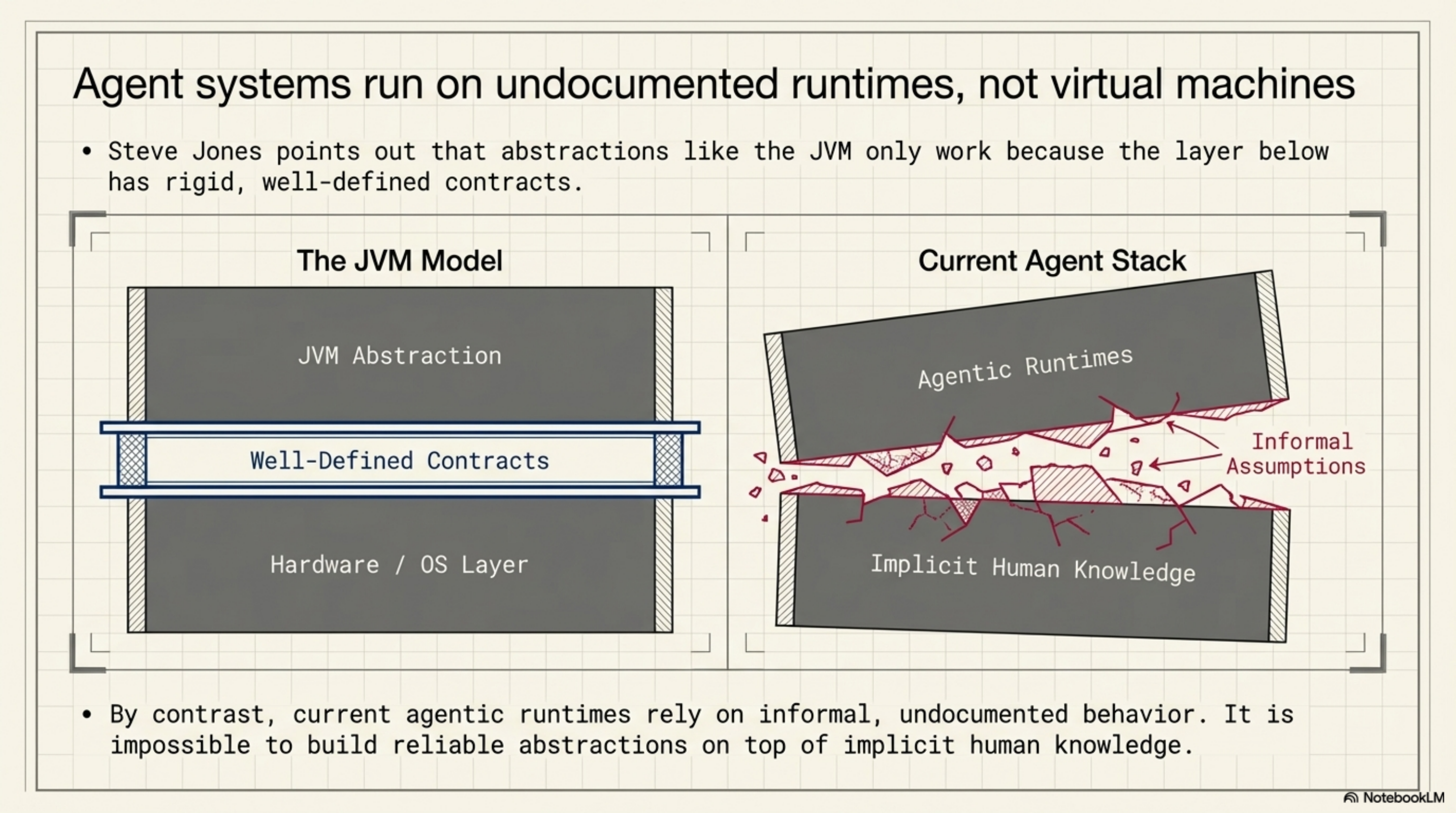
Steve Jones made a parallel observation about the JVM: abstractions work when the layer below has well-defined contracts. Most agentic systems today run on informal assumptions — that is not a virtual machine, that is a runtime with undocumented behaviour.
The ingestion problem¶
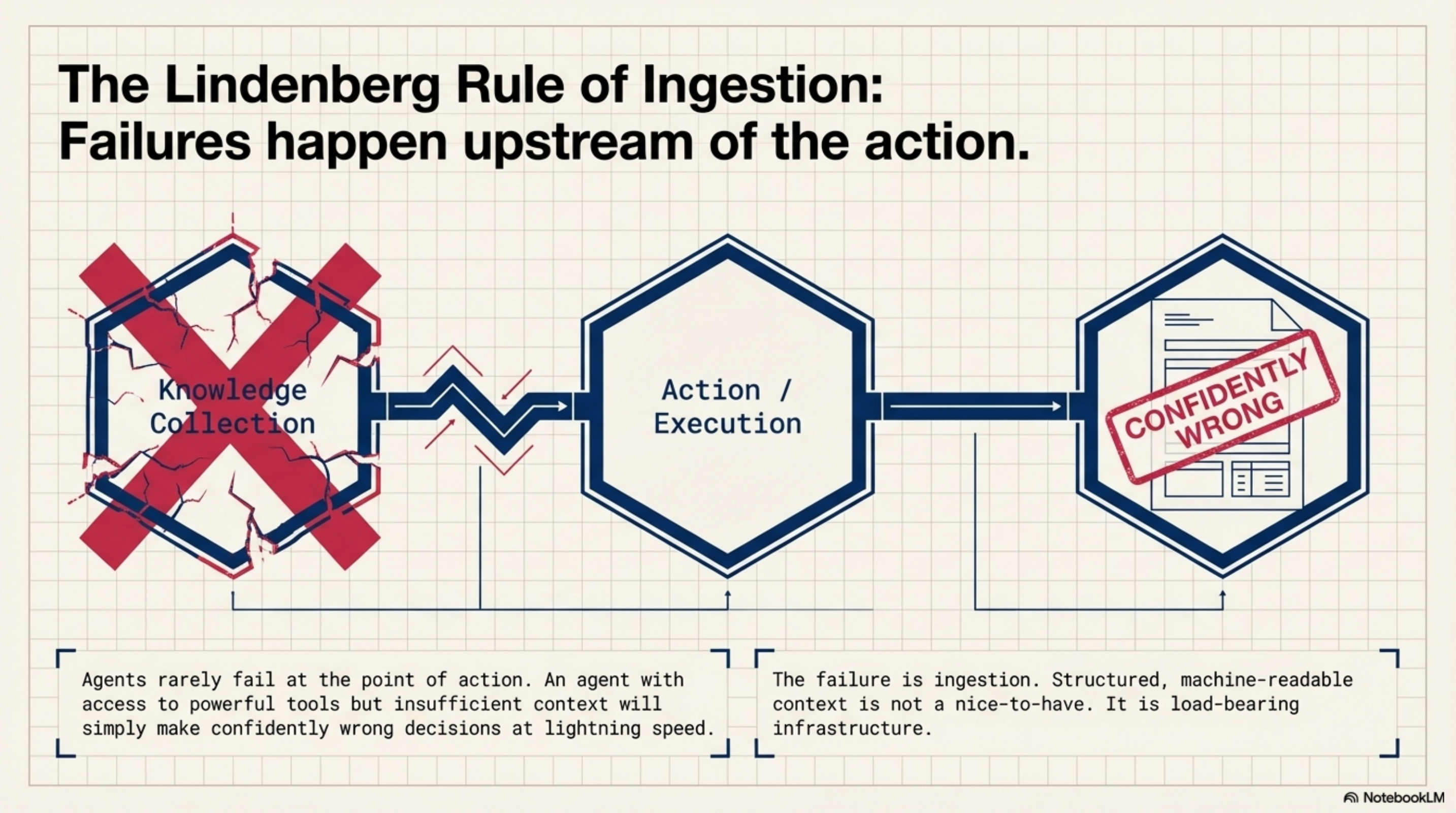
André Lindenberg pointed out something that matches my own experience: agents don't fail at the action. They fail at what they knew before they acted.
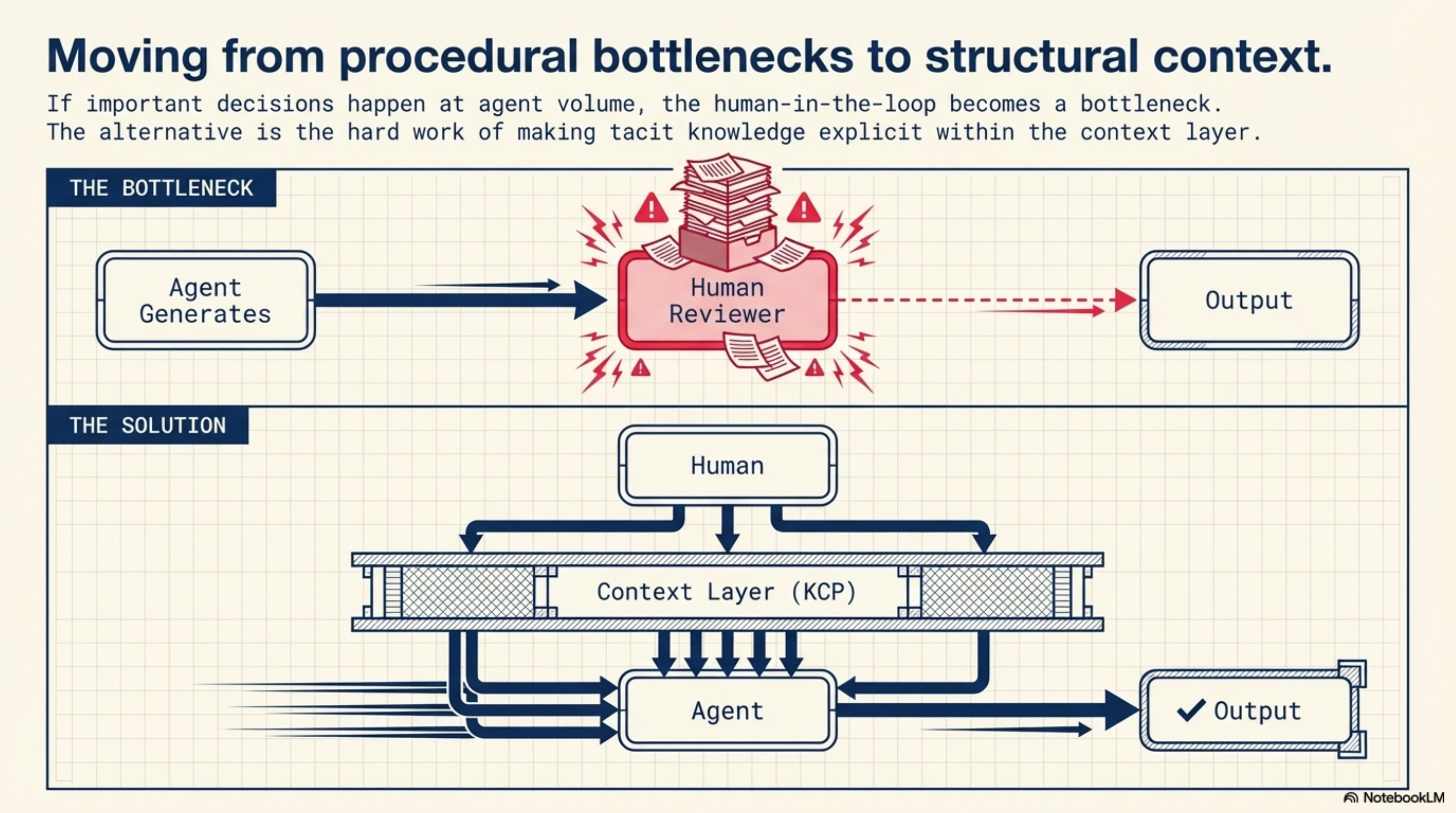
This is the knowledge/context layer, and it is where I've spent most of my building time. When I started working on KCP (Knowledge Context Protocol) and Synthesis, it was because I kept running into the same problem: an agent with access to powerful tools but insufficient context makes confidently wrong decisions. The failure is upstream of the action, not at the point of execution.
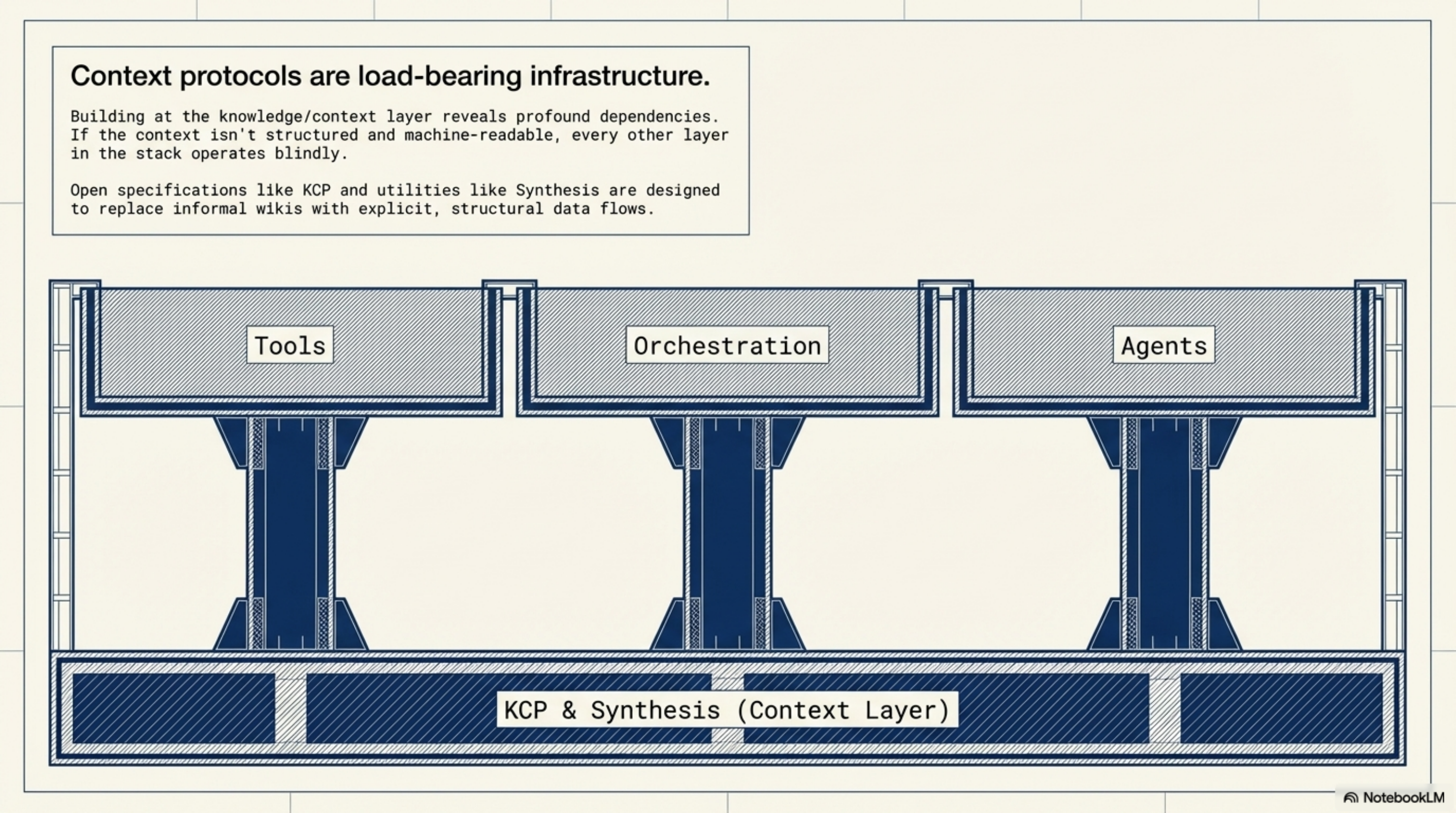
Structured, machine-readable context is not a nice-to-have for agentic workflows. It is load-bearing infrastructure. Without it, every other layer in the stack operates on incomplete information.
Encoding judgment before the loop starts¶
Lasse Andresen at IndyKite raised a point that I think is underappreciated: judgment, aesthetics, and deliberative reasoning need to be encoded before agents act, not preserved as human competitive advantages.
This is uncomfortable for a lot of practitioners. The instinct is to keep humans in the loop for "the important decisions." But if the important decisions happen at agent speed and volume, the human loop becomes either a bottleneck or a rubber stamp. Neither is useful.

The alternative is to encode the judgment — quality standards, architectural principles, compliance requirements, risk thresholds — into the context layer itself. Make the guardrails structural, not procedural. This is hard work. It requires making tacit knowledge explicit in ways that most organisations have never had to do.
But it is the only approach I've found that scales.
What I've learned building at one layer¶
I've spent the past year building tooling at the knowledge/context layer — KCP as an open specification, Synthesis as a CLI, kcp-commands and kcp-memory as utilities. All open source, all driven by specific problems I kept hitting in practice.
What building at one layer teaches you is how dependent it is on every other layer. Structured context is useless if the agent cannot authenticate to the system that serves it. High-frequency commits are unmanageable without automated review. Orchestration frameworks assume tool protocols that may not exist yet.
The layers are not independent. They are co-dependent. And the teams that figure this out earliest — that treat the agentic infrastructure stack as a coherent problem rather than six separate tool choices — will compound their advantage in ways that are difficult to catch up to.
The question I keep coming back to¶
We are in a window where every layer is being rebuilt simultaneously, mostly by different teams who are not talking to each other. Version control people are solving version control. Context protocol people are solving context. Auth people are solving auth.
But the real constraint is the integration between layers. The informal assumptions. The undocumented contracts.
Who is working on the seams?

The visual companion to this post — a slide deck generated from these field notes — is available here: Agentic Infrastructure: The Stack That's Being Rebuilt