The agents were forgetting everything they discovered¶
Something felt off.
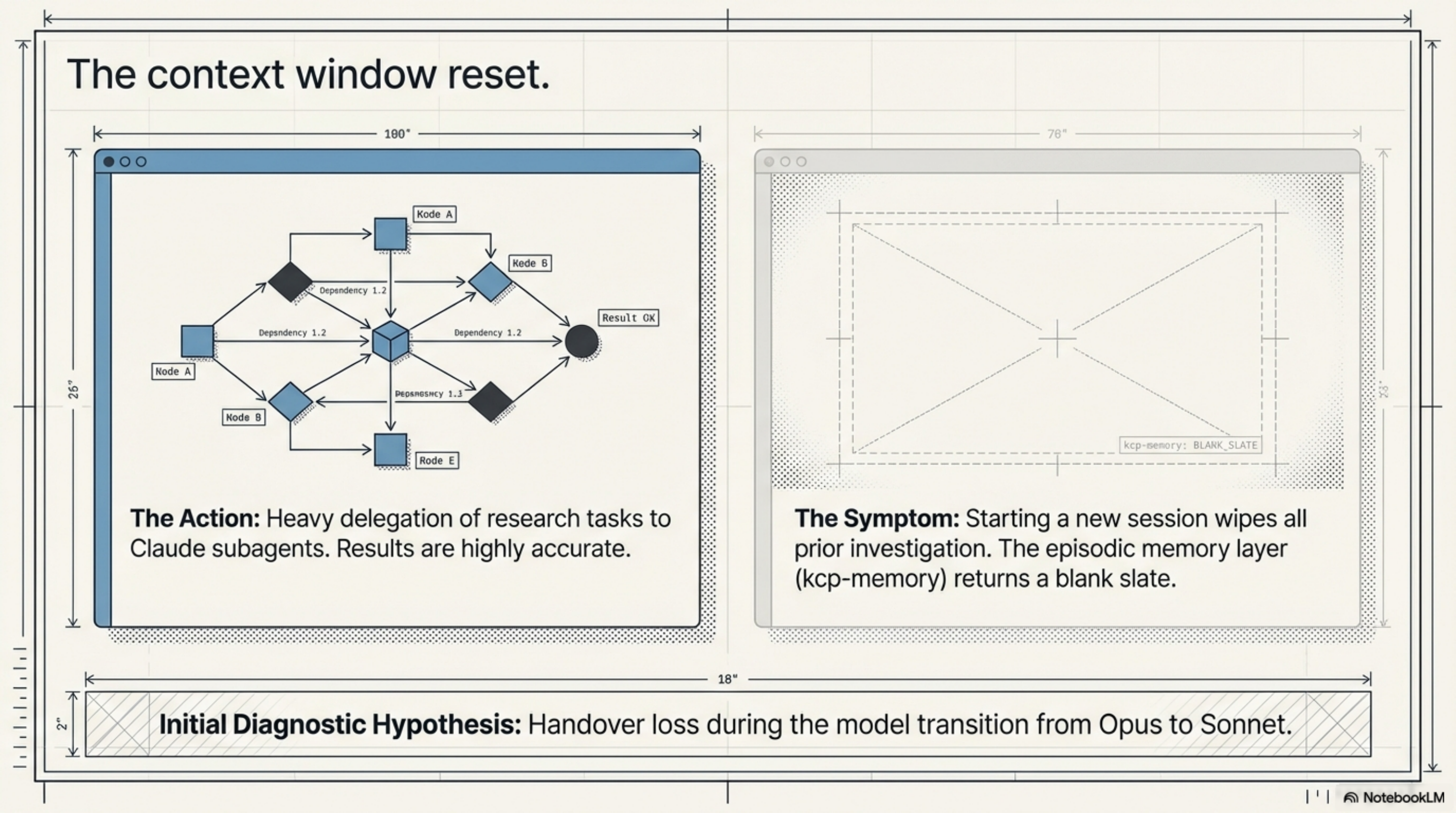
I'd been using the Task tool heavily — delegating research tasks to Claude subagents, letting them explore codebases, map dependencies, surface patterns. The results coming back were good. But when I'd start a new session and ask about the same topic, there was no trace of that prior investigation. The context window had reset, and the episodic memory layer — kcp-memory — wasn't helping.
Here's what that looked like in practice: I'd asked a subagent to map the co-events repository ecosystem earlier this week. It came back with a clear picture — co-events is the CatalystOne HRIS event-sourcing platform, seven repos, with a dependency chain running from co-event-typelib through co-event-sdk into co-analytics-vanilla (which, by the way, uses Neo4j with APOC, not SQL — a non-obvious choice). Two days later, I started a new session, asked about co-events architecture, and got a blank stare. The agent had no idea any of this had been mapped. It treated the question as entirely novel.
My first hypothesis was handover loss. Maybe something was being compressed or summarized too aggressively when agents returned their findings. Maybe the model transition (often Opus for the delegated tasks, Sonnet for the orchestrating session) was dropping context. That felt plausible, and a little unsettling.
The real cause was more concrete — and more fixable.
What kcp-memory is supposed to do¶
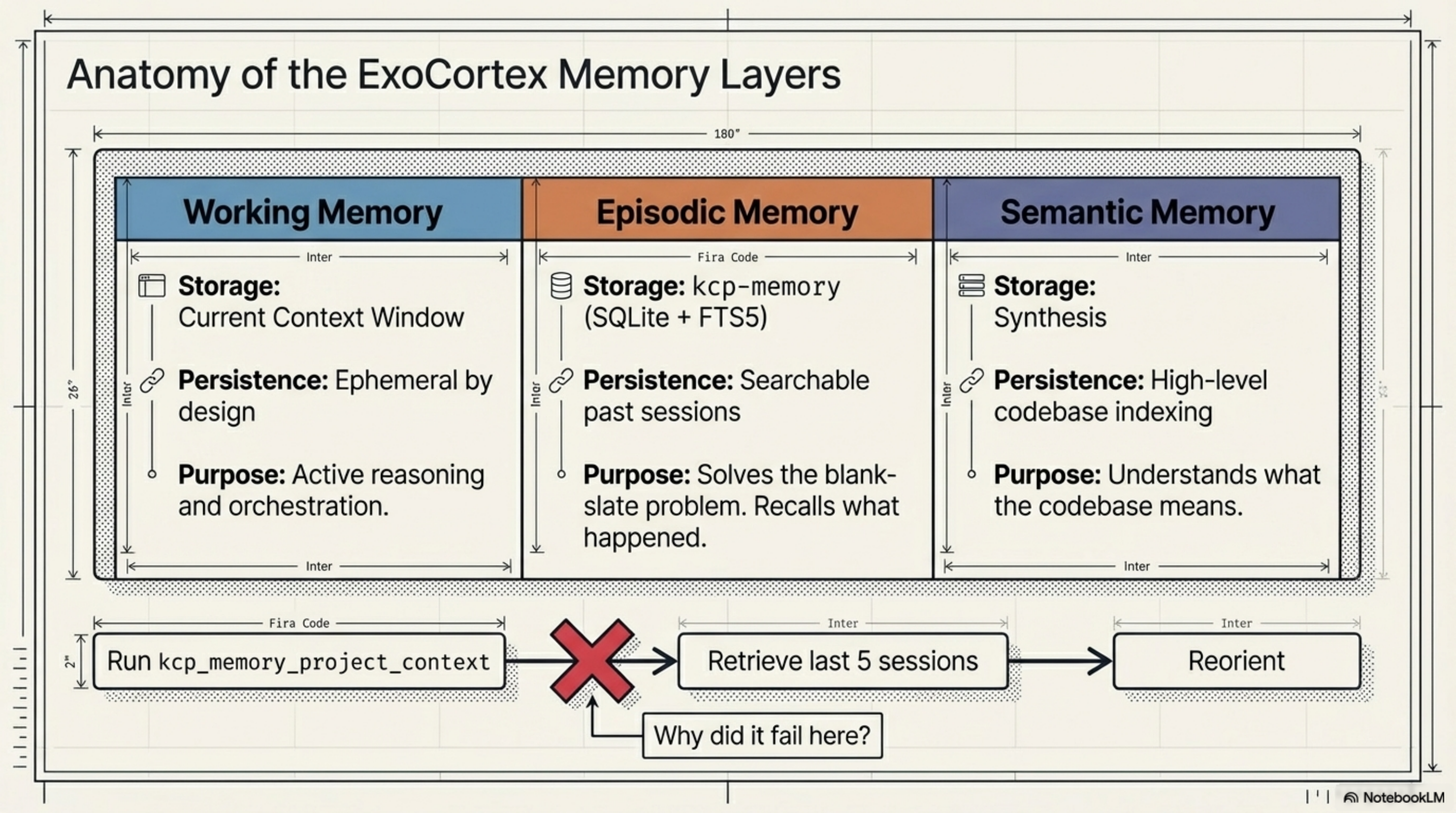
The ExoCortex rig I work in has three memory layers:
- Working memory: the current context window — ephemeral by design
- Episodic memory: kcp-memory — indexes past sessions into SQLite+FTS5 so you can search them
- Semantic memory: Synthesis — indexes what the codebase means, not just what happened
kcp-memory solves the blank-slate problem. Every Claude Code session starts with no recollection of prior work. kcp-memory scans ~/.claude/projects/**/*.jsonl and makes the past searchable in milliseconds. Before a non-trivial task, I run kcp_memory_project_context and get the last five sessions for the current project. Usually that's enough to reorient.
Or so I thought.
The forensic analysis¶
I asked Claude Opus to do forensic analysis of the knowledge infrastructure. Not a quick check — a proper audit. I wanted to understand what was actually being captured versus what was slipping through.
What made this interesting was the method. Opus started by examining the JSONL transcript format itself — the structure of each line, the metadata fields, how sessions get stored to disk. It found that subagent transcripts carry a distinctive signal: isSidechain: true in the JSONL content, and they're stored in a subagents/ subdirectory under the parent session with a predictable naming pattern (agent-<hash>.jsonl). Then it counted. Per project, per directory, measuring file sizes and compression ratios between what a subagent produced and what made it back into the parent session's summary.
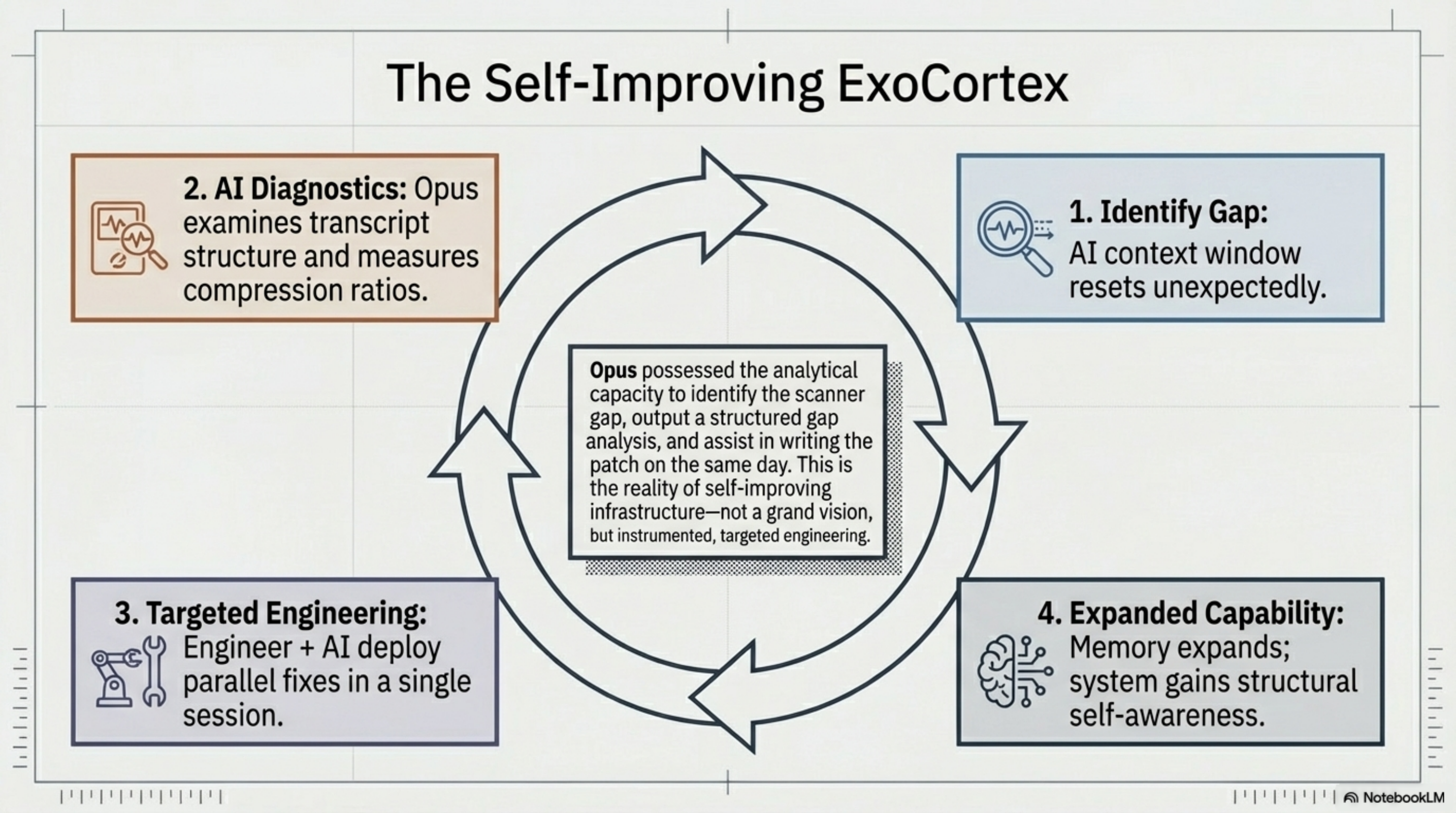
There's something genuinely strange about watching an AI agent do introspective analysis of the AI agent transcript system. Opus was reading its own kind's output, understanding the storage format, and identifying the architectural gap — all in a single delegated task. The findings came back as a structured gap analysis with numbers.
And the numbers were stark.
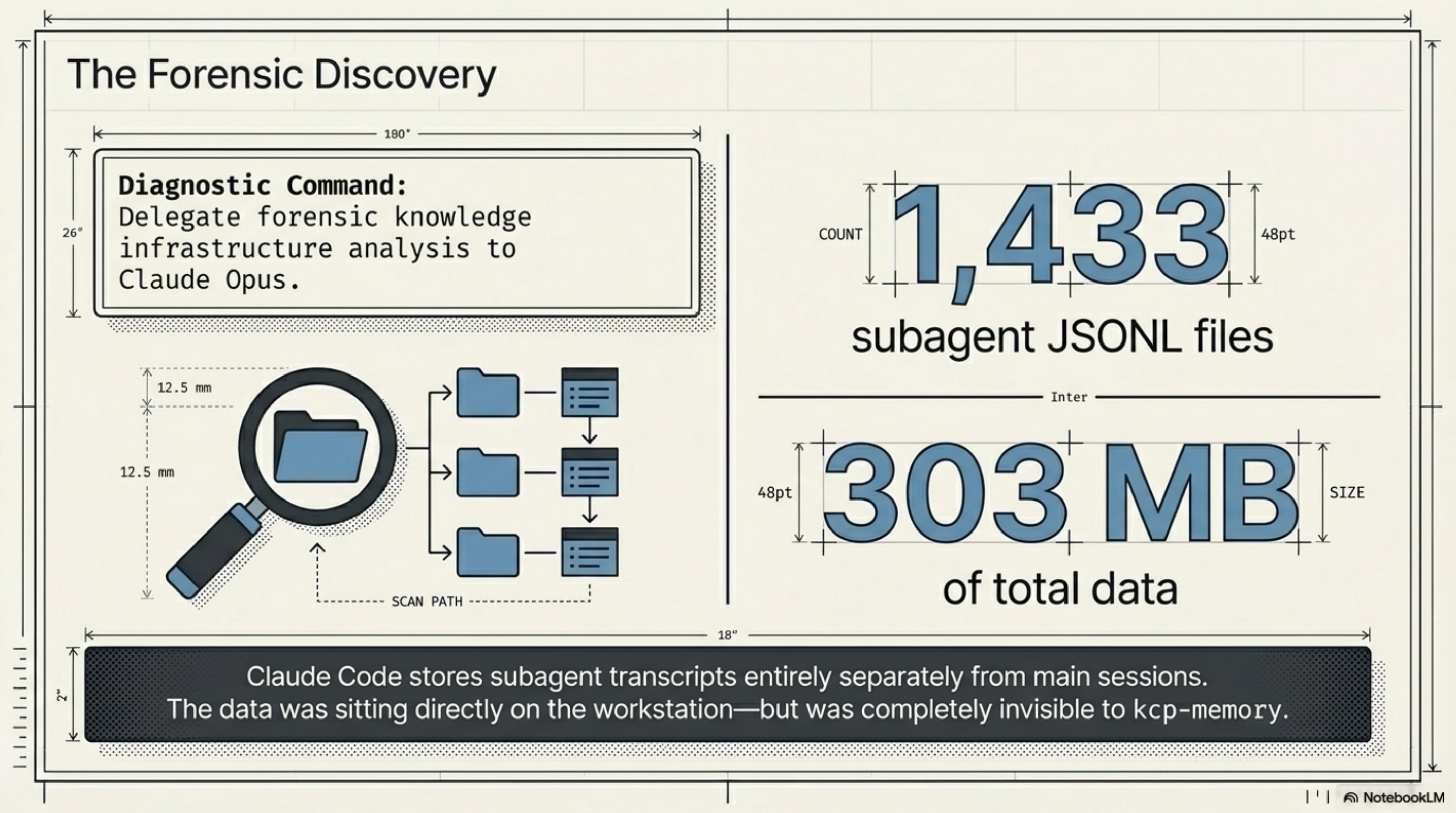
Claude Code stores subagent transcripts separately from main sessions:
~/.claude/projects/<project>/<session-uuid>/
├── <session-uuid>.jsonl ← main session (indexed)
└── subagents/
├── agent-ae5fb06d98fb195b2.jsonl ← NOT indexed
├── agent-a6036b037ec3f4eed.jsonl ← NOT indexed
└── ...
When a subagent finishes, the main session receives a compressed summary. The ratio Opus measured was 40:1 to 100:1. Meaning 95–98% of the reasoning trail — the tool calls, the dead ends, the intermediate discoveries — was stored to disk but never indexed.
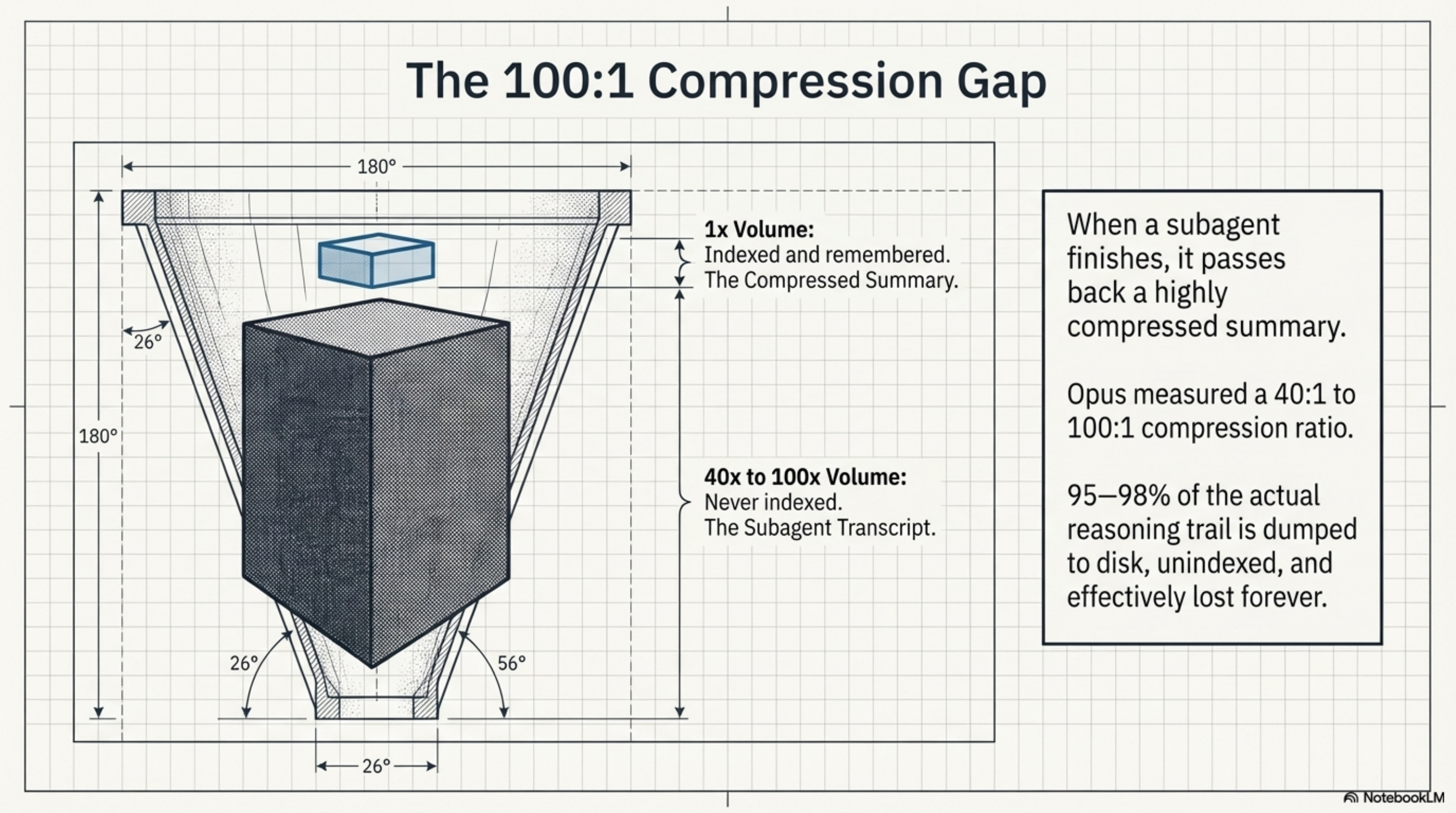
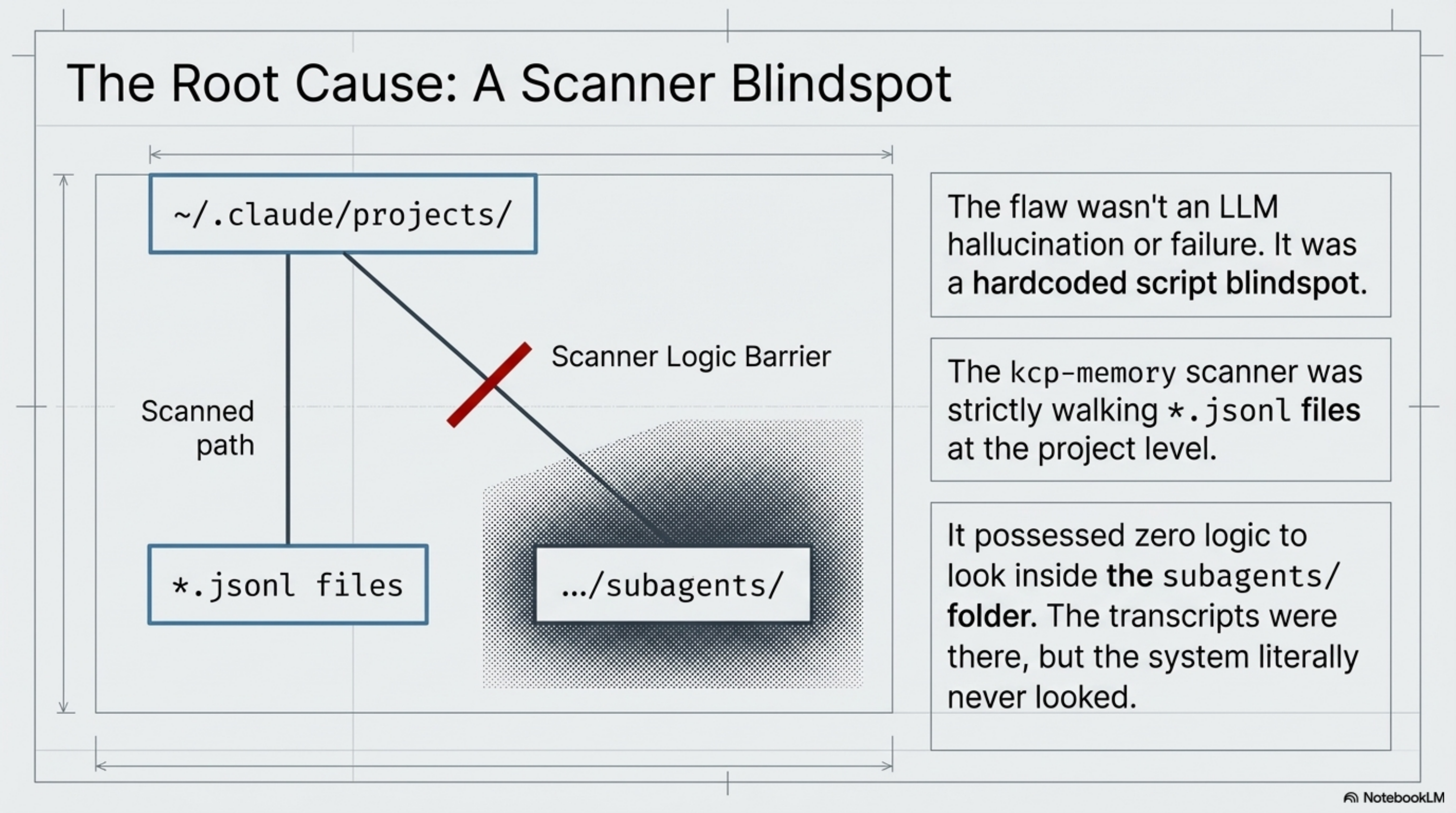
The root cause was simple once you saw it: the kcp-memory scanner was strictly walking *.jsonl files at the project level. It had zero logic to look inside the subagents/ folder. The transcripts were there, but the system literally never looked.
What was being lost¶
This matters more than it sounds. Subagent transcripts aren't just logs. They contain:
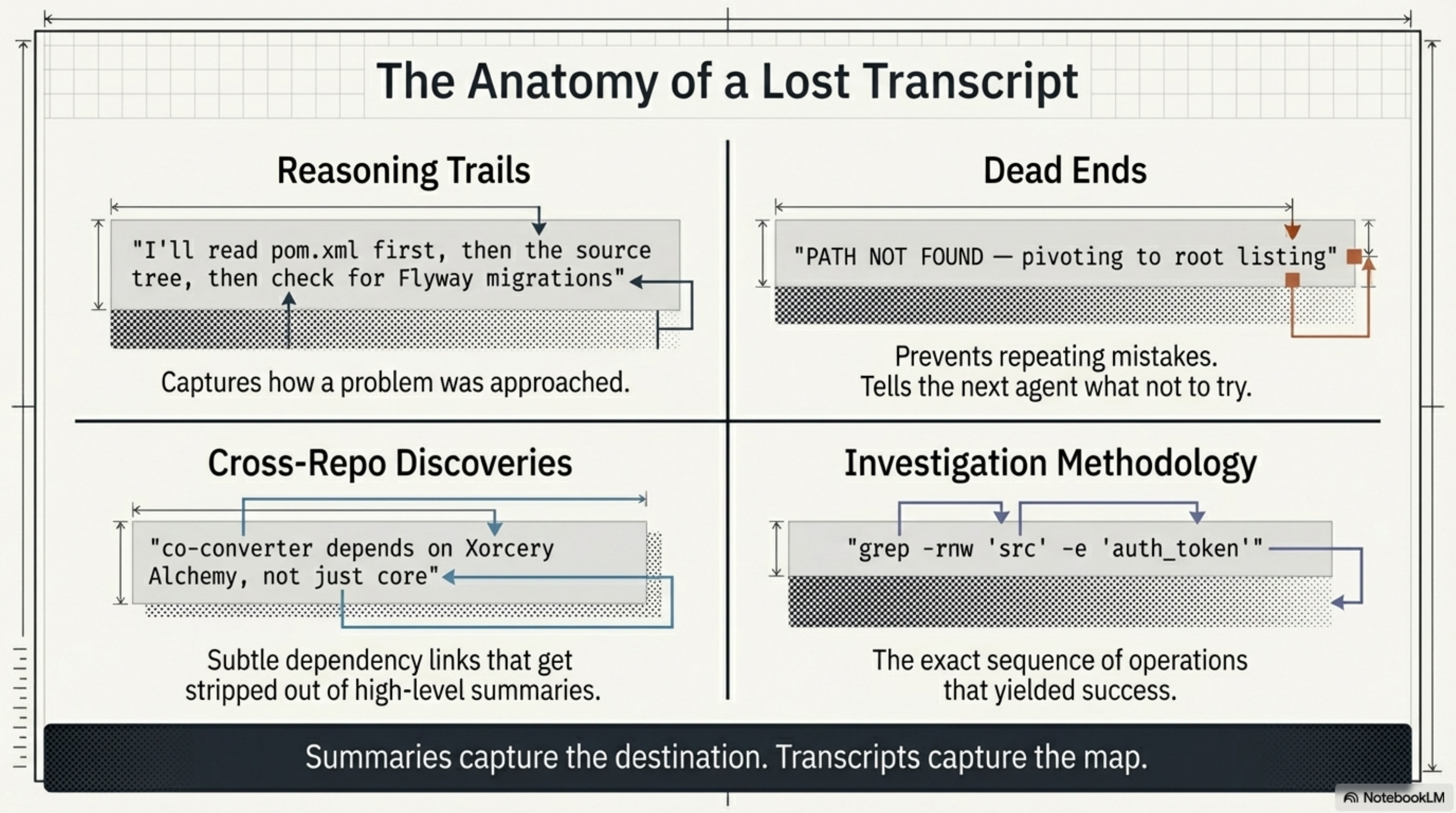
- Reasoning trails: "I'll read pom.xml first, then the source tree, then check for Flyway migrations" — how a problem was approached
- Dead ends: "PATH NOT FOUND — pivoting to root listing" — what not to try again. The co-event-sdk source path from knowledge.yaml was incorrect; the agent had to discover this and find an alternative. That's valuable the second time around.
- Cross-repo discoveries: things like "co-converter depends on Xorcery Alchemy, not just core" that never made it into the compressed summary clearly enough to be retrieved. Or that LMAX Disruptor is used for write-path throughput in co-events — a ring buffer pattern you'd never guess from the README.
- Domain corrections: "co-events is the CatalystOne HRIS integration layer, not a generic event bus" — the kind of nuance that doesn't survive a 100:1 compression ratio. An agent that explored this once should never have to discover it from scratch.
- Investigation methodology: the sequence of reads and searches that actually worked. For Java multi-module Maven projects, several agents independently converged on the same approach: read knowledge.yaml first, then root pom.xml for versions, then module-level poms, then interfaces before implementations. That pattern was rediscovered every time because it was never indexed.
Today's session alone produced ten subagent runs across two parent sessions — 3.2 MB of transcripts, spanning Cantara, Quadim, Elprint, eXOReaction, and Mynder repos. In one run, an agent discovered that Elprint's platform service has three LLM backends (Claude primary, OpenAI fallback, local stub for dev) with a daily spend cap and a quality feedback loop where user ratings feed back into the prompting strategy. That's 402 KB of detailed investigation. The parent session got maybe a paragraph.
The fix: two places, one session¶
We fixed it in the same session where Opus identified it. Two parallel tracks:
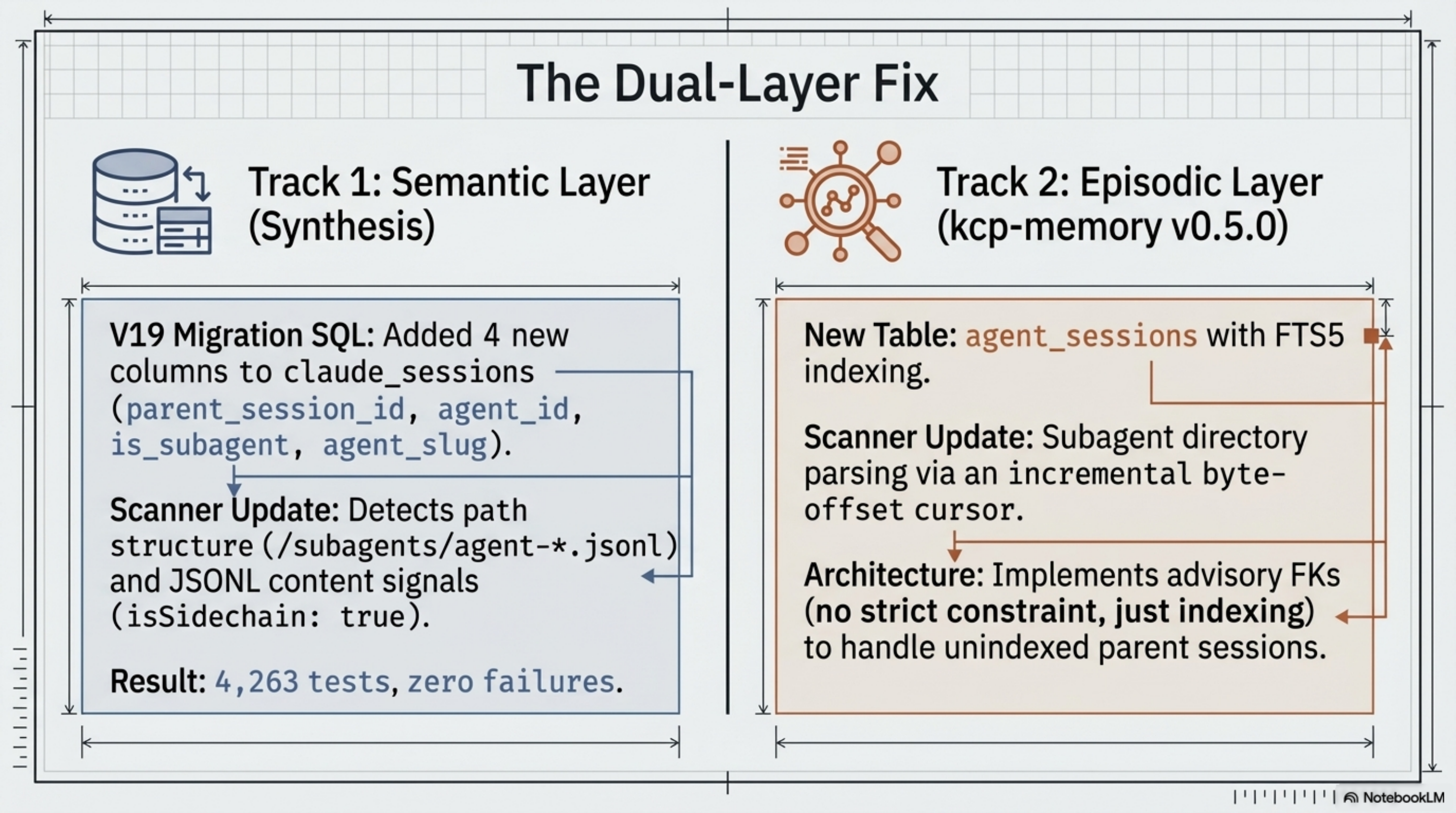
Synthesis (the semantic layer) was also ignoring subagent files. Opus added V19 migration SQL — four new columns to claude_sessions: parent_session_id, agent_id, is_subagent, agent_slug. The scanner now detects both path structure (/subagents/agent-*.jsonl) and content signals (isSidechain: true in the JSONL). Parent-child relationships are stored and queryable. 4,263 tests, zero failures.
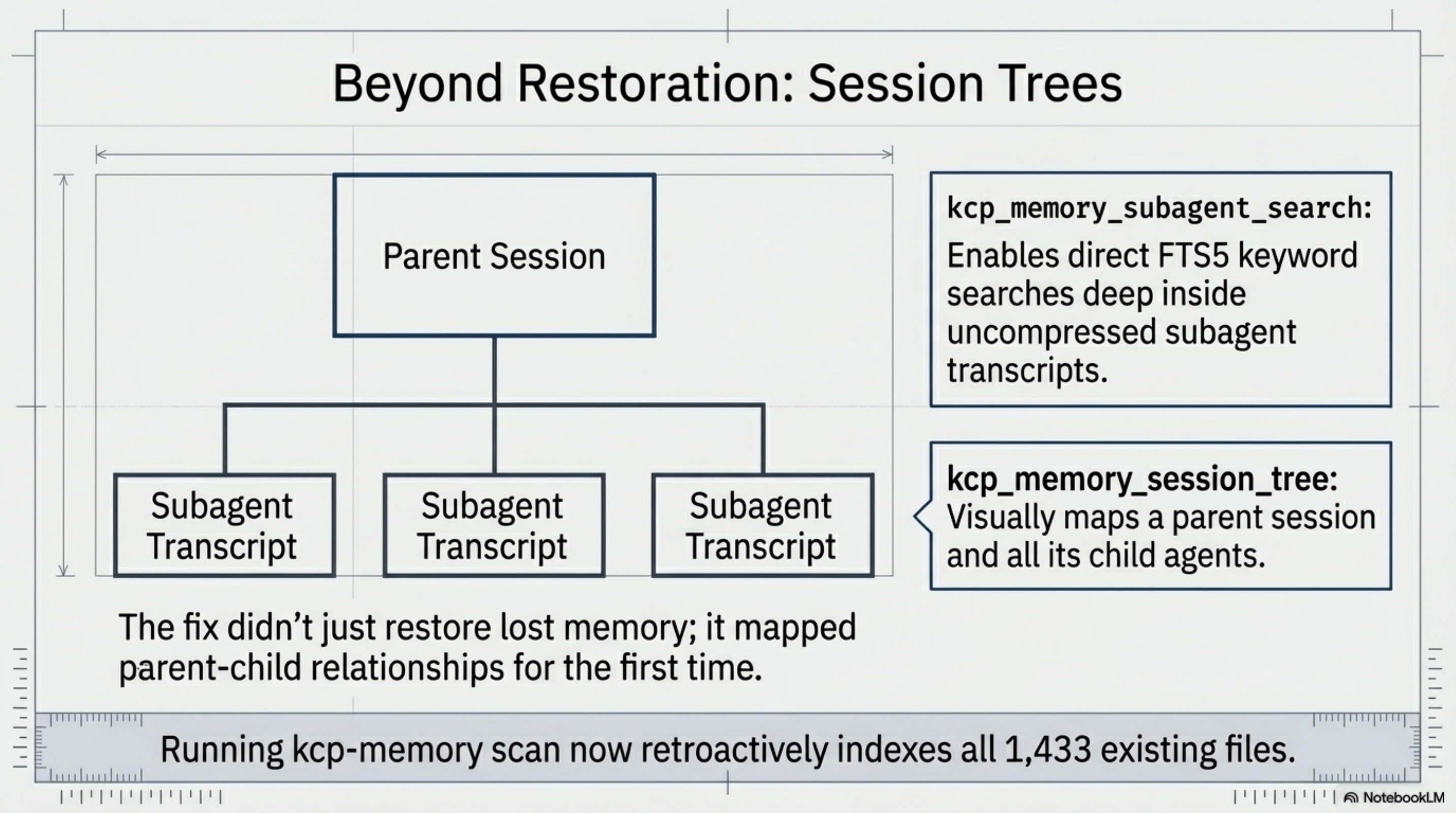
kcp-memory (the episodic layer) got a new agent memory layer — v0.5.0. A new agent_sessions table with FTS5 indexing, a scanner that walks the subagents/ directory tree, extracts the agent hash from the filename, detects isSidechain: true as the content-level signal, and indexes the full transcript text for search. Two new MCP tools:
kcp_memory_subagent_search— FTS5 full-text search within subagent transcriptskcp_memory_session_tree— show a parent session and all its child agents as a tree
The scanner is incremental (byte-offset cursor, like the events scanner) and handles the advisory FK correctly — parent sessions may not always be indexed first, so there's no foreign key constraint, just an index on the parent session ID column.
What changes now¶
Running kcp-memory scan retroactively indexes all 1,433 existing subagent files. That's 303 MB of previously invisible reasoning trails, searchable in milliseconds.
Concretely, this means:
- Search reaches into subagent work. Ask "what do we know about co-events?" and the search hits the subagent transcript where the full dependency chain was mapped — not just the one-paragraph summary the parent session received.
- Session tree view.
kcp_memory_session_treeshows a parent session with all its child agents — task, size, timestamp. Instead of a flat list of sessions, you see the actual structure of a complex investigation. Today's main session spawned ten agents. That's visible now. - Dead ends are searchable. "Did we already try reading co-event-simulator's API docs?" — yes, an agent found them stale three days ago. Don't repeat the work.
- Methodology compounds. The Maven multi-module investigation pattern that kept being rediscovered independently is now findable. The Whydah call-chain ordering (UIB, STS, UAS, Admin-SDK) is indexed once and available always.
The 303 MB was always being written to disk. The fix was just making it findable.
The meta-lesson¶
What made this possible was using the rig to debug itself. Opus had enough analytical capability to examine the transcript structure, count the files, measure the compression ratios, and identify the scanner gap — all in a single delegated task. The findings came back as a structured gap analysis. We implemented the fix the same day.
This is what a self-improving knowledge infrastructure looks like in practice. Not a grand architectural vision, but a specific gap identified through instrumentation and closed through targeted engineering.
The agents were forgetting everything they discovered. Now they don't.

kcp-memory v0.5.0 is available on GitHub. Run kcp-memory scan after upgrading to retroactively index existing subagent files.
KCP (Knowledge Context Protocol) — the open spec powering this ecosystem — is at github.com/Cantara/knowledge-context-protocol.