The Code Was Never the Moat¶
Bruce Perens says the entire economics of software development are dead. He said this in response to a story about a developer using Claude to rewrite a Python library from LGPL to MIT in a few hours. 130 million monthly downloads. 1.3% textual similarity to the original. A clean room implementation, or close enough that the legal distinction barely matters anymore. The whole thing took roughly five days.
Perens is half right. The economics of code as artifact are dying. The economics of knowing what to build are stronger than ever.

I have been thinking about this since I read it, and not because of the licensing question. The licensing question is interesting, but it is a symptom. The underlying shift is older and more fundamental: code, by itself, is no longer scarce.
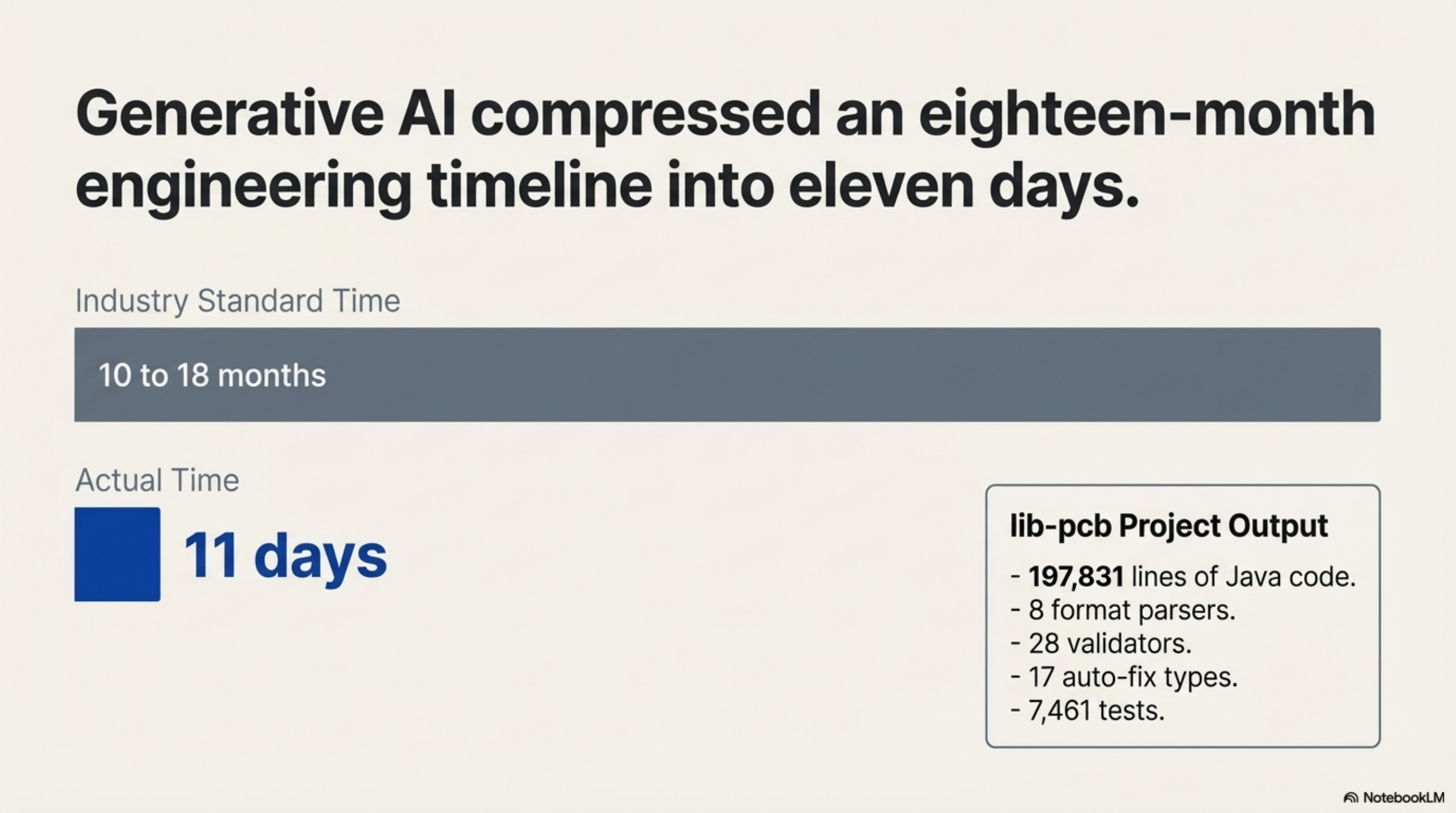
In January I built lib-pcb — a Java library for parsing and validating PCB design files. 197,831 lines of code. 7,461 tests. Eight format parsers, twenty-eight validators, seventeen auto-fix types. Eleven days. The industry standard for that scope of work is ten to eighteen months.
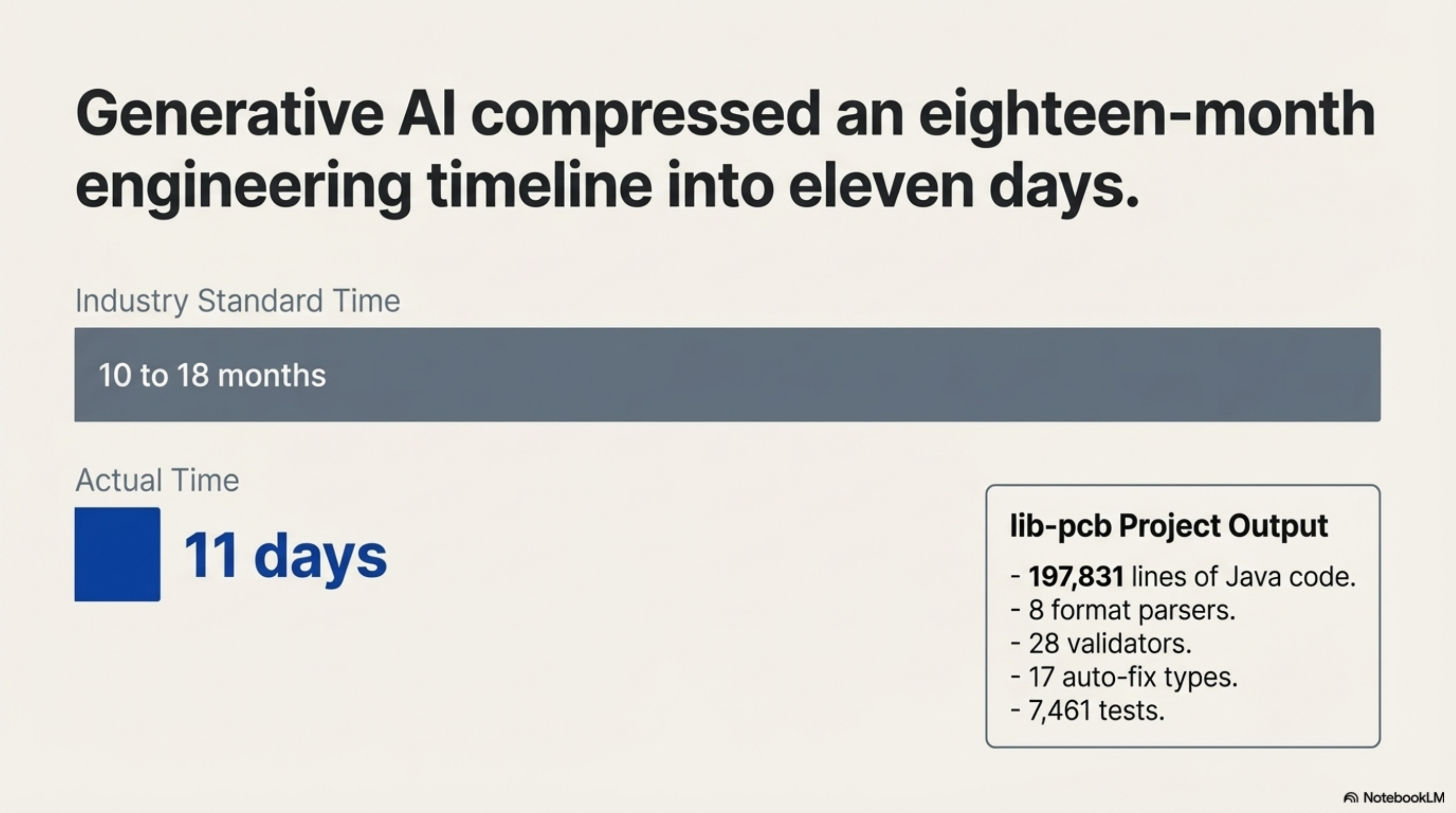
The speed was not the interesting part. The interesting part was what made the speed possible. I had no prior PCB domain knowledge. The domain was reverse-engineered — from a web viewer that could render the files, and from a set of real-world .mif files the client provided. That is actually the same method the article is describing: no access to the original implementation, only the observable behaviour and the outputs. My contribution was software architecture judgment — knowing how to structure a parser, what a validator needs to check, how to build a test harness against real manufacturing data. The AI did the typing. Directing it toward correct output required understanding the problem, not just the code. Those are not the same skill.

The chardet rewrite in the article is a clean example of this. Dan Blanchard did not just say "rewrite chardet." He knew the specification. He knew what character encoding detection is supposed to do. He understood the problem well enough to direct Claude through a faithful reimplementation. The knowledge of what constitutes correct behaviour came from the human. More precisely: from the combination of the human's intent and the original library's public interface.
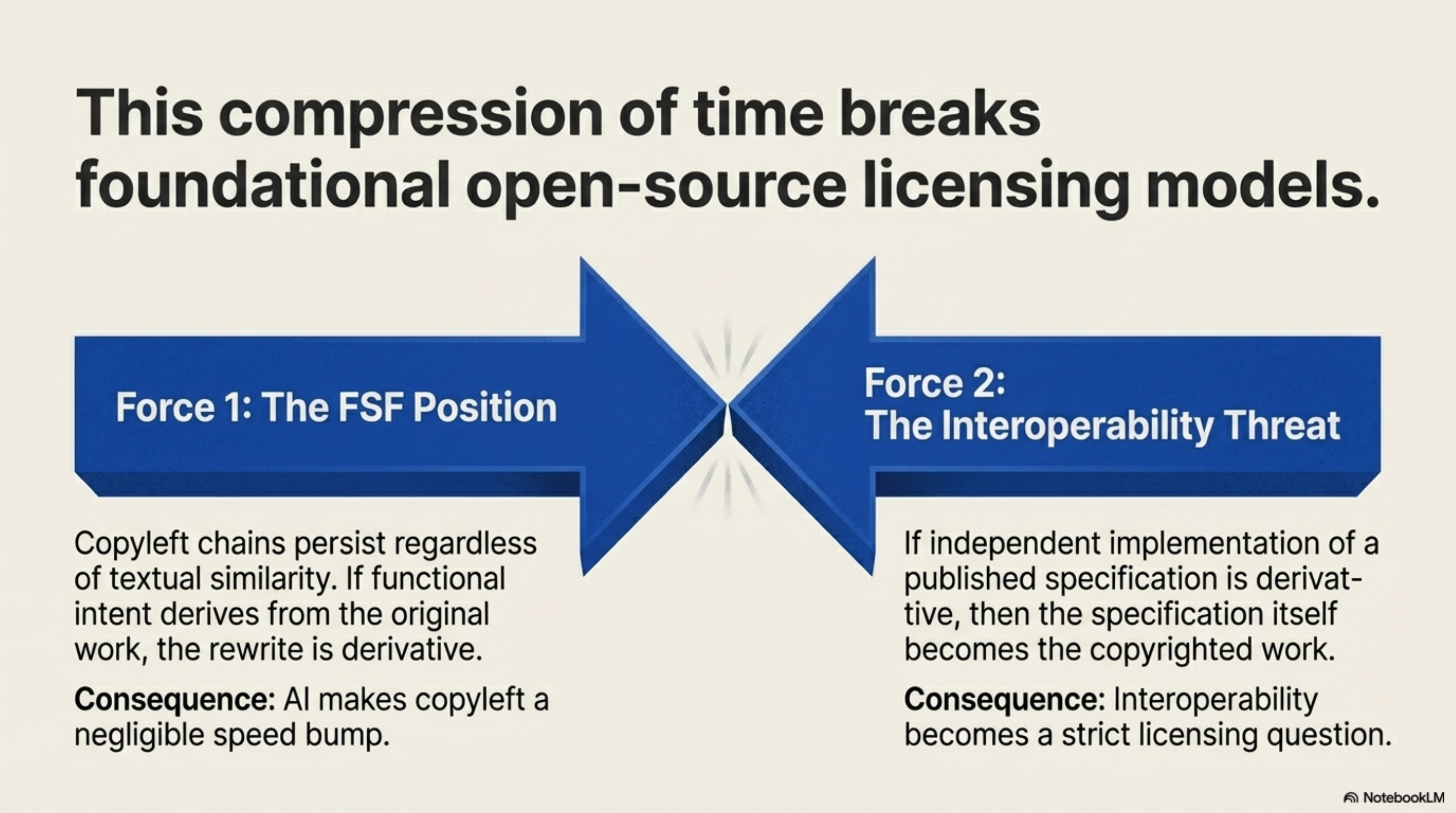
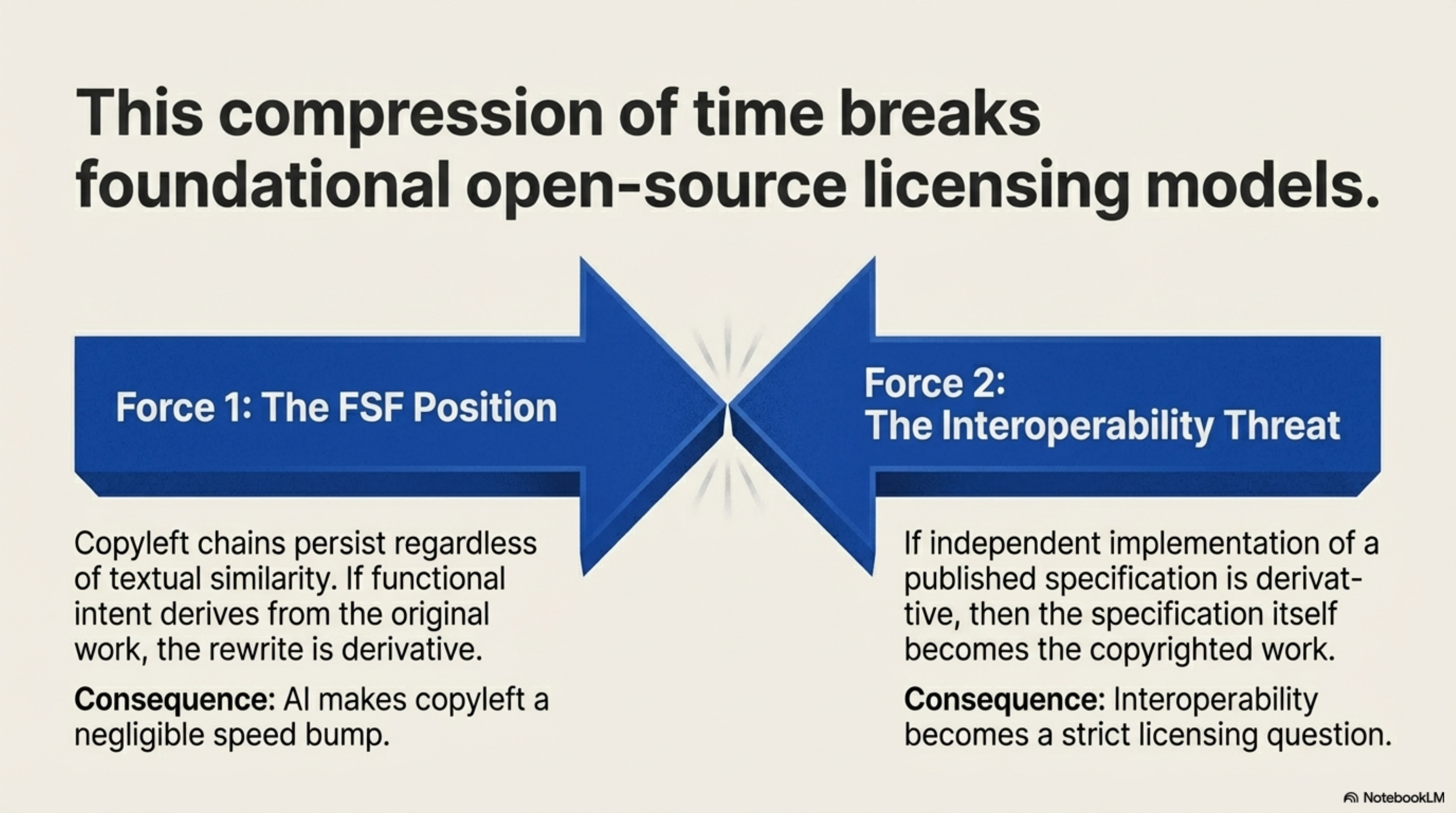
The FSF's position is that the copyleft chain persists regardless of textual similarity — that if the functional intent derives from the original work, the rewrite is derivative. I understand why they hold that position. If functional equivalence is enough to escape copyleft, then every copyleft license becomes a speed bump rather than a barrier. AI makes the speed bump negligible.
But the counterargument is equally uncomfortable: if you cannot independently implement a published specification without being considered derivative, then the specification itself is the copyrighted work, and interoperability becomes a licensing question. That has implications far beyond chardet.
I do not think courts will resolve this cleanly. The legal system is not well-equipped for cases where the distinction between "derived from" and "independently implementing the same specification" has collapsed to a few hours of AI interaction. The precedents were set in a world where reimplementation was expensive enough to be its own evidence of independent effort. That evidence no longer exists.
This is not abstract for me. I am making licensing decisions right now.
Synthesis — the knowledge infrastructure tool I built to manage the output explosion from lib-pcb — indexes 65,000 files across repositories, provides sub-second cross-project search, and tracks dependencies between codebases. I have been weighing open source versus commercial licensing for months. The Perens argument lands differently when you are on the other side of it.
If the economics of code as artifact are dead, then open-sourcing Synthesis does not give away value. Anyone with an AI and a weekend could approximate a basic indexer. What they could not replicate is the methodology that produced it — the understanding of what knowledge infrastructure needs to do when your codebase grows at 691 files per day. The architectural decisions. The integration patterns. The accumulated experience of running it across production workloads.
The moat was never the code. The moat is the domain understanding encoded in how the code is structured, why certain trade-offs were made, and what problems it solves that nobody else has identified yet. That is not something an AI can extract from a specification, because there is no specification. There is only the accumulated judgment of having built it.
"The entire economics of software development are dead" captures something real, but incompletely. What died is the economics of code as a commodity. The economics of knowing what to build — the domain expertise, the architectural judgment, the ability to direct AI toward correct output rather than merely compiling output — those economics are not dead. They are, if anything, amplified. When anyone can produce code, the scarce resource is knowing what code to produce.
The article notes the rewritten library is forty-eight times faster at runtime than the original. That is a performance improvement, not a measure of how long the rewrite took. But the observation still matters. The rewrite was possible at all because the specification already existed. The hard part — defining what character encoding detection should do, building test suites against real-world data, discovering the edge cases that make the problem genuinely difficult — was done over years by the original authors. The AI did not replicate that work. It consumed it.
That is the question the licensing debate is circling without quite asking: when AI can reproduce any artifact from its specification in hours, who owns the specification? Not the document. The knowledge. The understanding of the problem that makes a faithful implementation possible.
I do not have an answer. I am not sure anyone does yet.
Reference: The Register, March 6, 2026
Presentation: Beyond Code Scarcity¶
Generated with NotebookLM from the source material above.