Skill-Driven Development vs Spec-Driven Development¶
Most teams using AI for development have settled on a workflow that looks roughly like this: write a detailed specification, feed it to the agent, review the output, iterate. It is disciplined. It is responsible. It works. And after six months of watching it in practice, I believe it has a structural limitation that becomes more expensive the longer you use it.
The limitation is not quality. Spec-driven development produces good output. The limitation is that every session starts from zero. The spec carries the knowledge. The agent carries nothing.
Why spec-driven development is rational¶
Before critiquing anything, I want to be clear: spec-driven development is a reasonable response to a real problem.
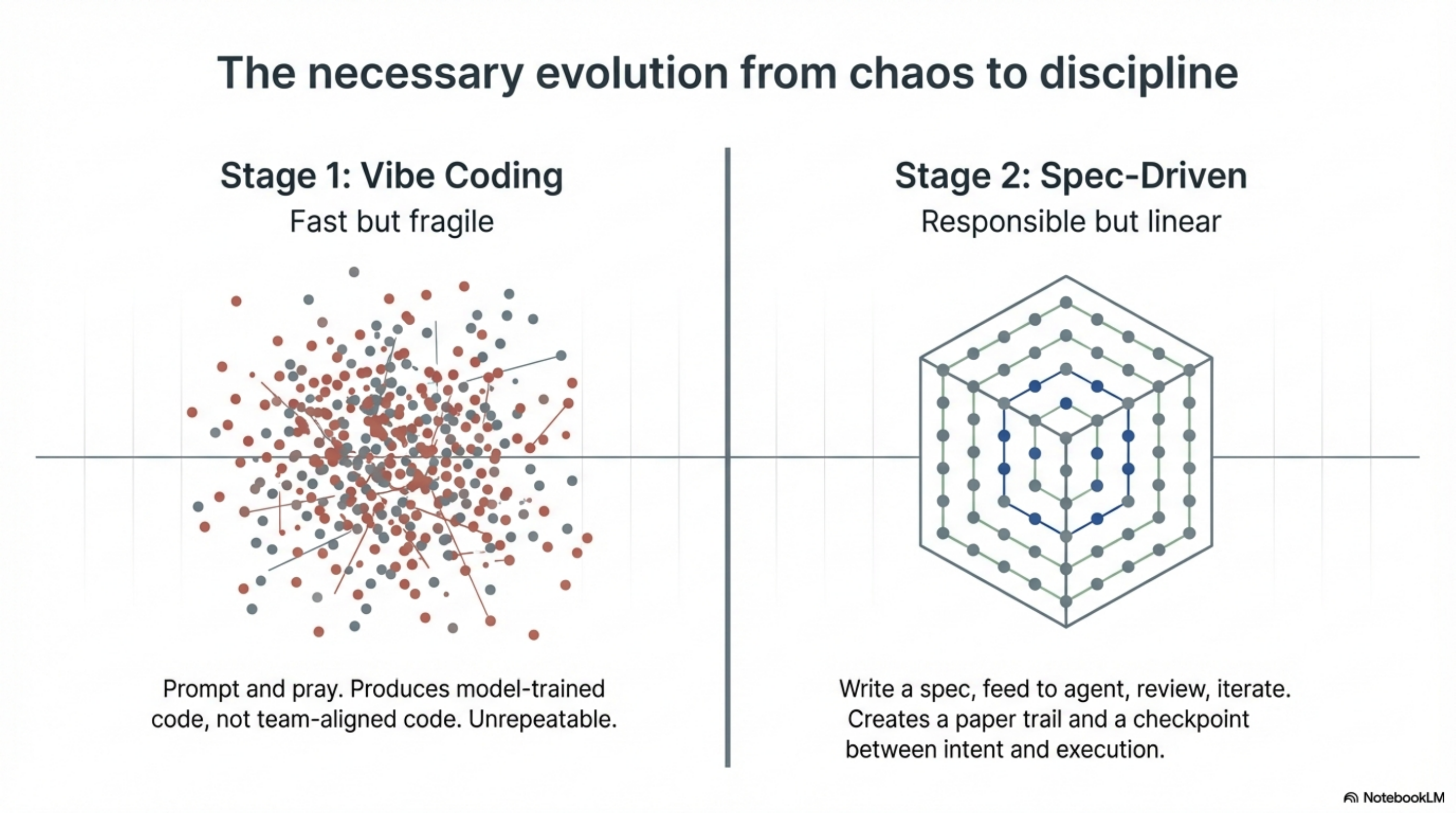
The alternative most teams tried first was vibe coding. Prompt the agent, see what comes out, fix the obvious problems, ship it. Fast for prototypes. Dangerous for anything that has to work in production. Vibe coding produces code that reflects the model's training data rather than your team's conventions. It generates confident output that may or may not match your architecture. It works until it doesn't, and when it doesn't, nobody can explain why.
Spec-driven development solved the obvious failure modes. You write what you want. The agent builds it. You review what was built. There is a paper trail. There is a checkpoint between intent and execution. It is the engineering response to the chaos of unstructured AI use, and for teams moving from vibe coding to something rigorous, it was the right step.
The problem is what happens after three months.
The session amnesia problem¶
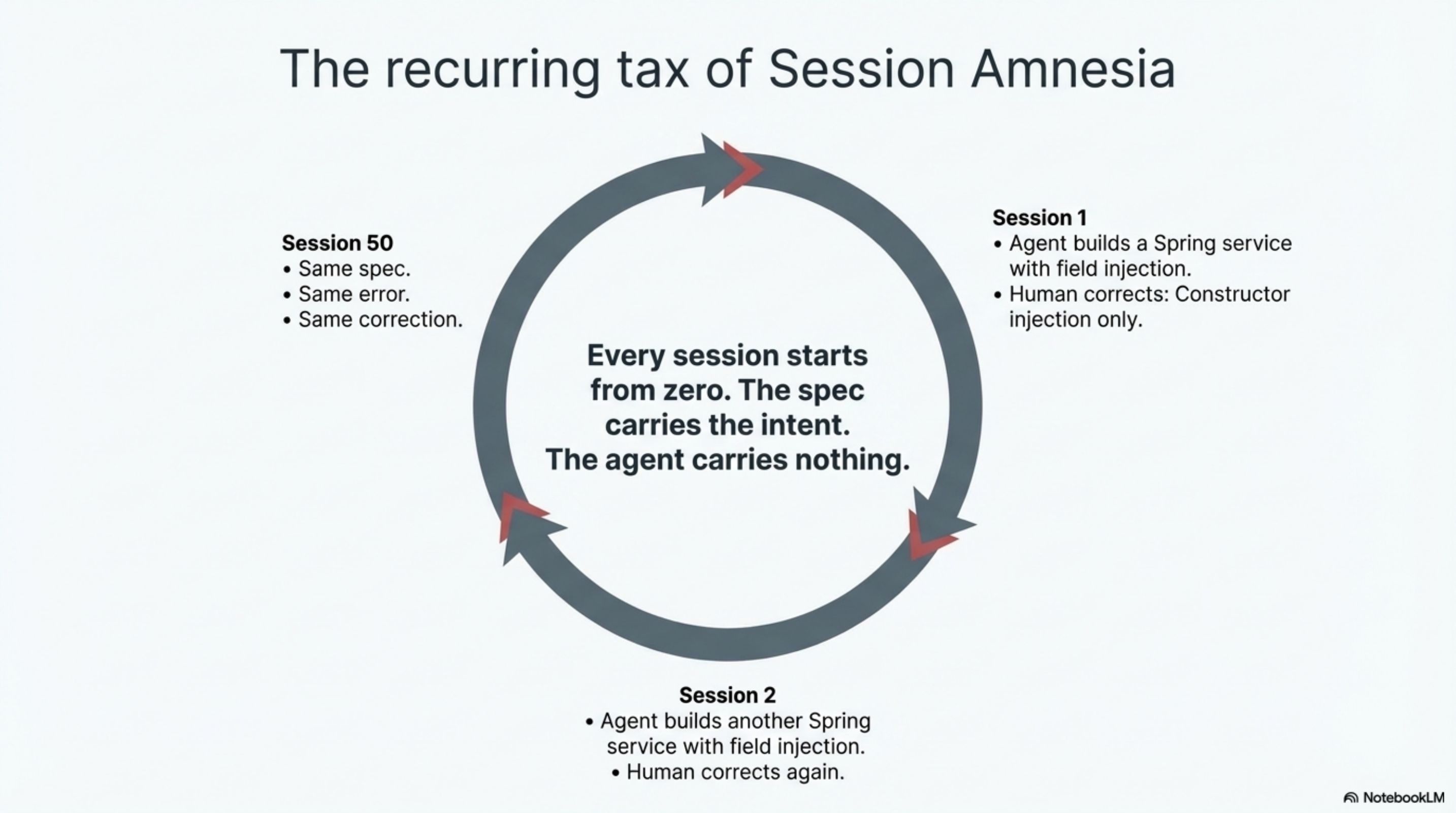
A spec is a document about what to build. It describes the desired outcome. It does not describe what the agent has learned while building.
Session one: the agent reads your spec and writes a Spring service. You correct it: "We use constructor injection exclusively, never field injection." The agent fixes it. Good.
Session two: the agent reads your spec again and writes another Spring service. With field injection. You correct it again. Same correction. Same fix.
Session fifty: same spec, same correction, same fix. The spec never changed because the spec does not encode how you build. It encodes what you build.
This is the session amnesia problem. Every session starts cold. The agent has no memory of previous corrections, previous architectural decisions, previous domain knowledge accumulated across dozens of interactions. The spec is a snapshot of intent. It is not a growing body of expertise.

Spec-driven teams compensate by making specs more detailed. Add a section on coding conventions. Add a section on testing patterns. Add a section on architectural constraints. The spec grows. Eventually it becomes a small book that the agent reads at the start of every session and promptly forgets by the next one.
The knowledge exists. It just doesn't persist where the agent can use it.
The alternative: investing in what the agent knows¶
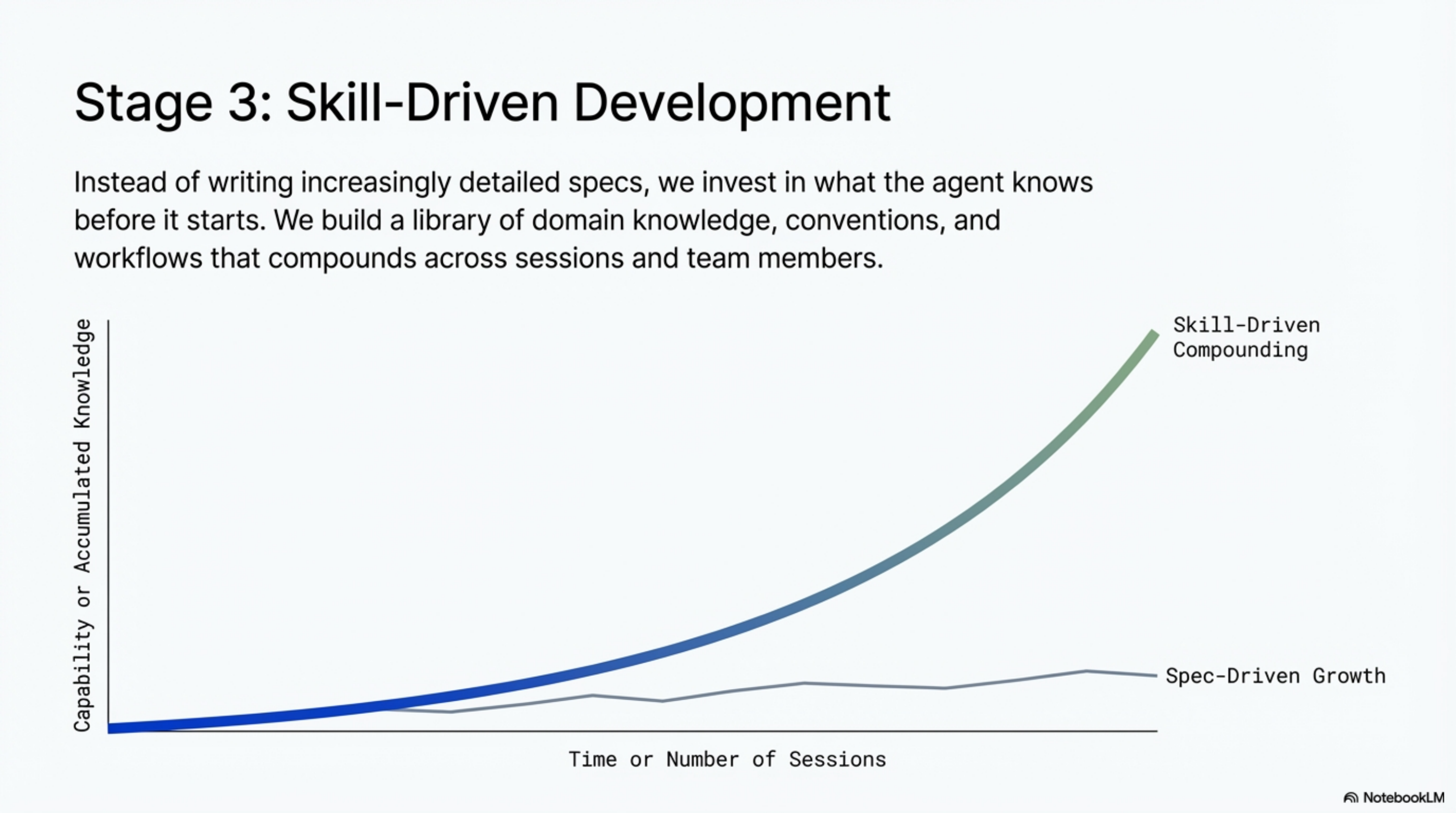
Skill-Driven Development takes a different approach. Instead of writing increasingly detailed specs about what to build, you invest in what the agent knows before it starts building.
A skill file is a YAML or Markdown file that encodes a specific piece of domain knowledge, convention, or workflow. It lives in the project's .claude/skills/ directory. It loads automatically when the agent works on that project. It persists across every session.
The Spring convention example becomes a skill:
name: spring-wiring-conventions
version: 1.0.0
instructions: |
- Constructor injection only. Never @Autowired on fields.
- @Transactional on service methods, never repositories.
- Integration tests use TestContainers, never H2.

Written once. Applied to every session, for every developer on the team, automatically. The agent does not need to be corrected. It already knows.
That is one skill. Over time, a project accumulates dozens of them. Each one captures something the team learned, a convention that was established, a mistake that was made and should not be repeated. The library grows. The agent's effective expertise grows with it.
This is the structural difference. Spec-driven development scales linearly: each new project requires a new spec. Skill-driven development compounds: each lesson learned makes every future session smarter.
Always explaining vs always accelerating¶
The daily experience of the two approaches feels different in a way that is hard to appreciate from a description. You have to live it.
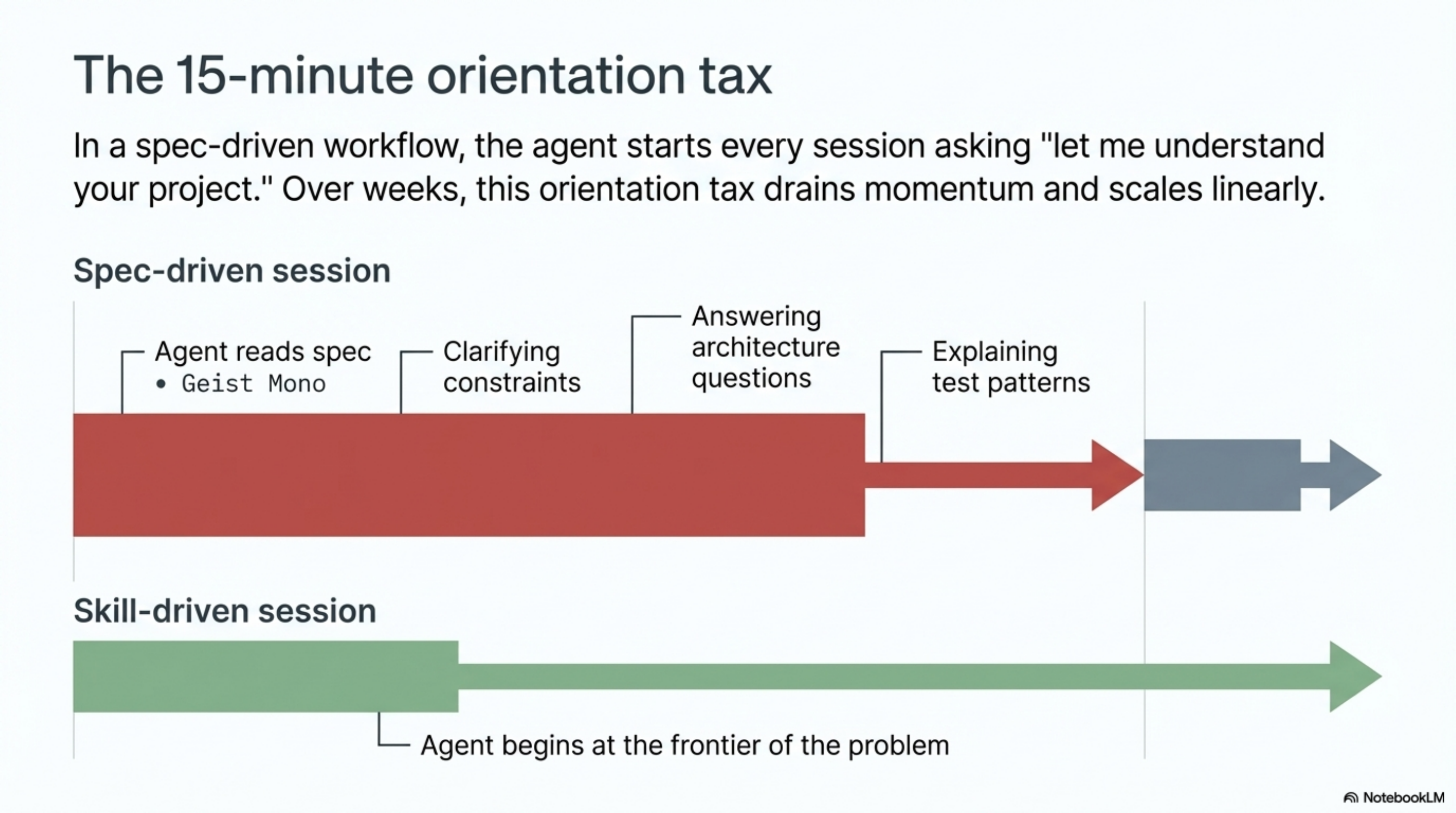
In a spec-driven workflow, the first fifteen minutes of every session are orientation. The agent reads the spec. You provide additional context. You answer questions about architecture. You clarify constraints. Then the building starts. The orientation tax is small on any given day. Over weeks, it adds up.
In a skill-driven workflow, the agent arrives knowing what it needs to know. Session start is not "let me understand your project." Session start is "the test for the coordinate parser is failing on files with non-standard origin offsets, and based on the coordinate-systems skill, the fix is to check for manufacturer-specific zero-point definitions." The conversation begins at the frontier of the problem, not at the baseline.
The gap is small in week one. By month three, the skill-driven team is working at a pace the spec-driven team cannot match, because every correction they made in the first month is encoded and active. The spec-driven team is still making the same corrections.
What compounding looks like in practice¶
During the lib-pcb build, we accumulated 75 skill files over eleven days. Not because we planned 75 skills on day one. Because each time we discovered something, we encoded it.
Day two: the agent transposes two fields in a binary parser. Stream misalignment cascades through the entire file. A skill is created: binary field order is sacred, never reorder without updating all downstream offset calculations. The agent never makes that mistake again.
Day five: a coordinate system edge case surfaces. A manufacturer uses a non-standard origin offset not in any published specification. Three lines are added to the coordinate-systems skill.
Day eight: a bounding box calculation includes a documentation layer with inflated coordinates. The bounding box skill is updated with the layer filtering rule.

By day eleven, the agent working on session fifty-five was measurably more capable than the agent working on session five. Not because the model improved. Because the skill library had grown. Each session inherited everything the previous sessions had learned.
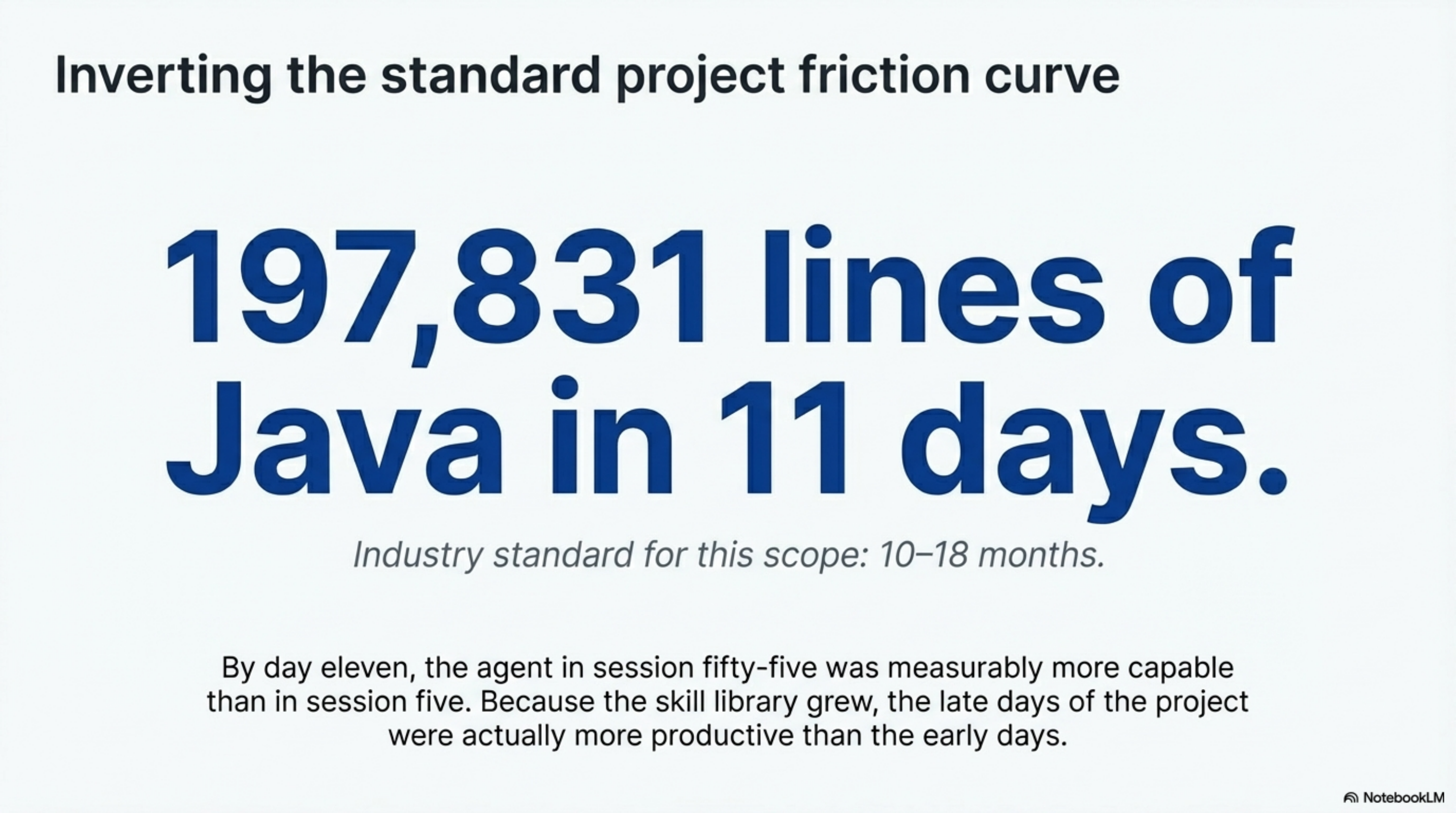
The result was 197,831 lines of Java in eleven days. Industry standard for a library of that scope is ten to eighteen months. I don't claim 75 skills are the only reason for that gap. Architecture, verification infrastructure, and focused delegation all played roles. But the compounding knowledge was the piece that made the late days more productive than the early ones. In most projects, the opposite happens.
The infrastructure that makes this work¶
Skills alone are one layer. The full picture includes infrastructure that most teams have not built yet.
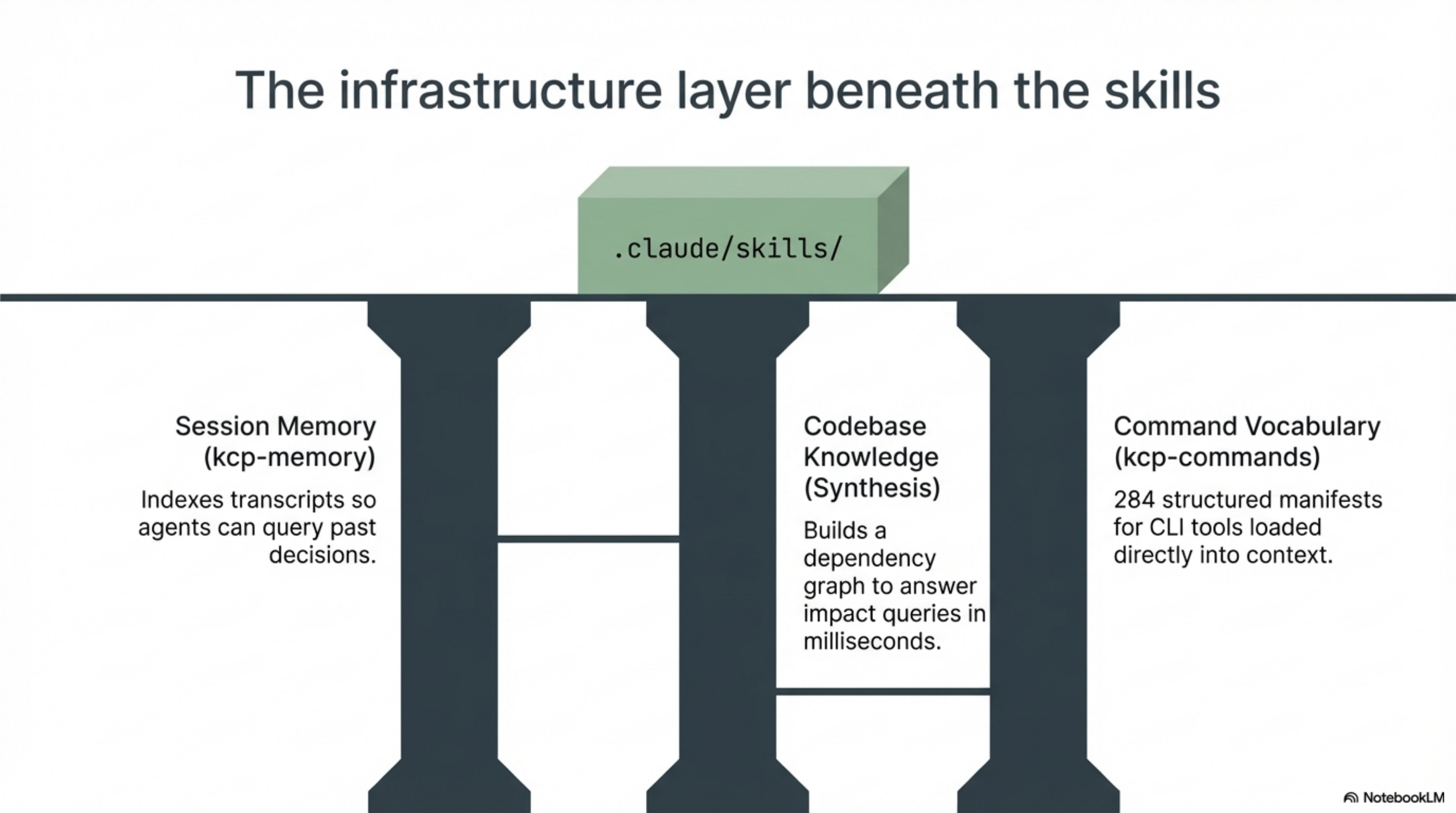
Session memory. The agent needs to remember what happened in previous sessions. Tools like kcp-memory index your session transcripts into a searchable store. "What did we decide about the authentication module last week?" becomes a query instead of a memory exercise. Without session memory, skills are the only bridge between sessions. With it, the agent can recall specific decisions, debugging approaches, and patterns from its own history.
Codebase knowledge. The agent needs to understand how the codebase connects. Synthesis indexes your workspace and builds a knowledge graph: dependencies, relationships, change history. "What breaks if I change this file?" is answered in milliseconds, not through manual exploration. The agent navigates with a map instead of wandering.
Command vocabulary. The agent needs to know what tools are available. kcp-commands provides structured manifests for CLI tools, saving the agent from guessing at flags and syntax. 284 command manifests, covering everything from build tools to deployment scripts, loaded into context automatically.
These are not products I am pitching. They are infrastructure layers that solve specific problems. The point is that SDD is not just "write YAML files." It is a methodology supported by infrastructure that makes the compounding possible.
The honest cost¶
SDD requires upfront investment that spec-driven development does not. You need to write skills. You need to maintain them as the codebase evolves. You need infrastructure for session memory and codebase knowledge. None of this is free.
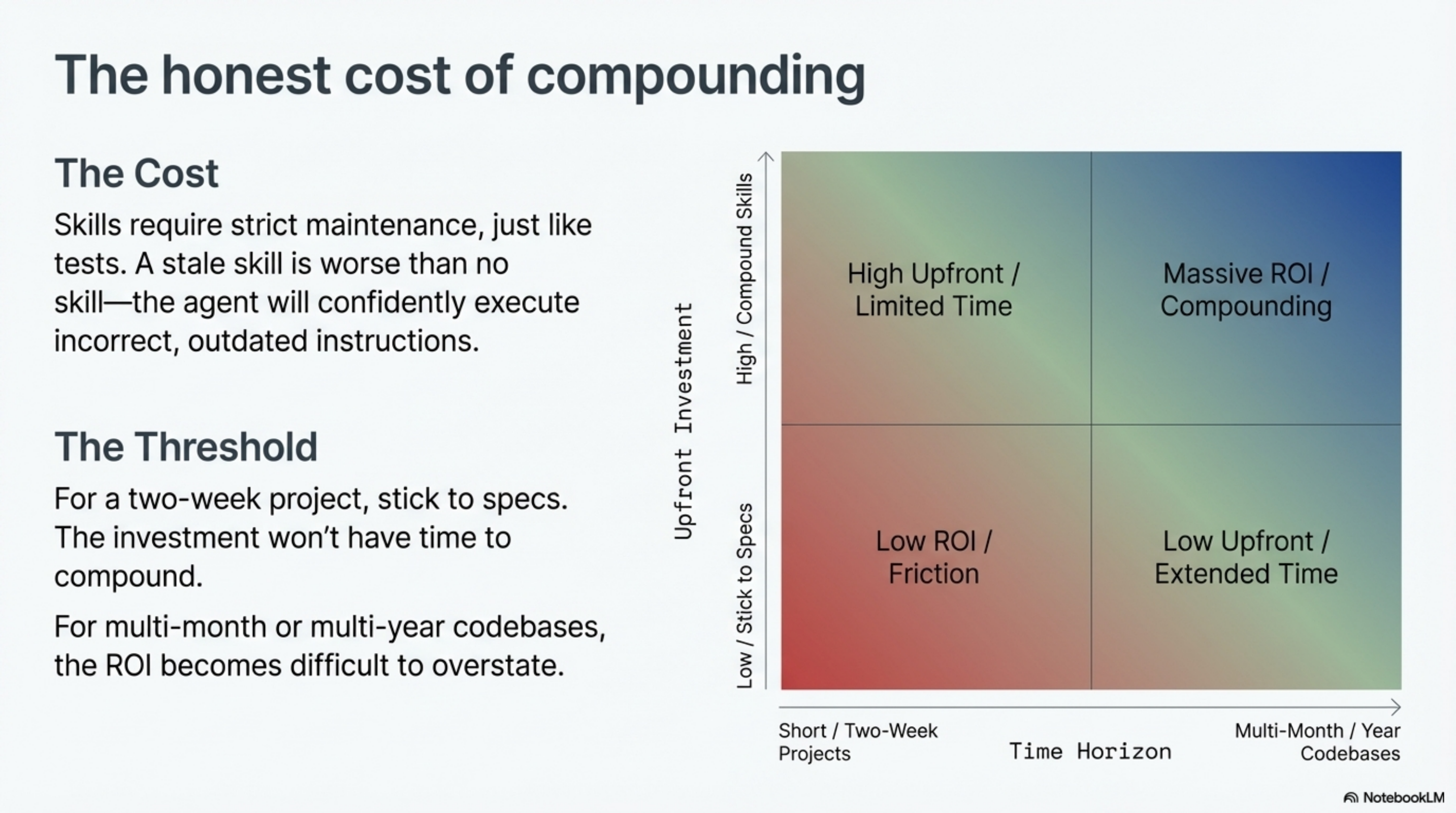
A stale skill is worse than no skill. If a skill claims three configuration fields and the code has six, the agent will confidently report three. It will be wrong. And it will be wrong with conviction, because the skill told it so. Skills require maintenance the same way tests do. If you are not willing to maintain them, you are better off without them.
The break-even point is not day one. For a project that lasts two weeks, spec-driven development is probably the right call. The investment in skills does not have time to compound. For a project that lasts two months or more, the compounding starts to show. For a team that works on the same codebase for years, the difference becomes difficult to overstate.
The question is not "which is easier to start?" Spec-driven wins that. The question is "which produces more value over time?" That depends on your time horizon.
Three stages, not two¶
Looking at how AI-assisted development has evolved in the past year, I see three stages:
Stage 1: Vibe coding. Just prompt it. No structure, no verification, no persistence. Fast and fun. Fragile and unrepeatable.
Stage 2: Spec-driven. Write detailed specifications. Feed them to the agent. Review output. Responsible and disciplined. But linear: each session starts cold, each project starts from scratch.
Stage 3: Skill-driven. Invest in what the agent knows. Build a library of domain knowledge, conventions, and workflows that compounds across sessions, across projects, across team members. The agent gets better over time because its knowledge base grows.
Most teams are at stage 2 and doing well there. Some are ready for stage 3. The shift is not about abandoning specs. You still need to describe what you want to build. The shift is about recognizing that the spec is not the only knowledge the agent needs. The how, the why, the constraints, the conventions, the lessons learned -- all of that is separate from the spec, and all of it can persist.
The shift: from writing specs to building knowledge¶
The practical move from spec-driven to skill-driven is smaller than it sounds.
Start with the corrections you keep making. Every time you correct the agent on the same thing twice, write a skill. Constructor injection. Test naming conventions. Module dependency rules. Error handling patterns. Each one is ten to thirty lines of YAML. Each one eliminates a category of repeated correction permanently.
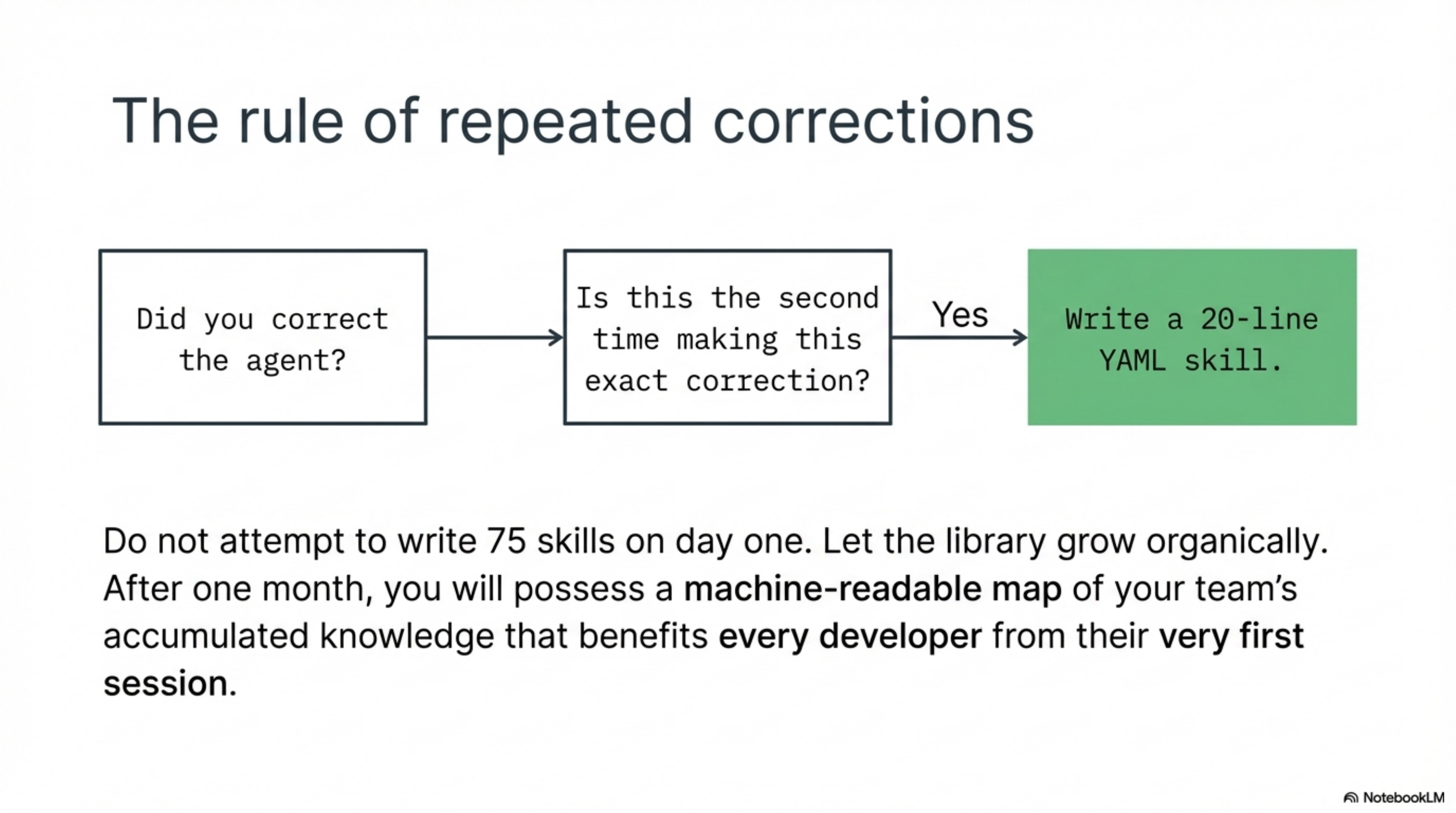
After a month, look at your skill library. It will be a map of your team's accumulated knowledge in machine-readable form. New team members get the benefit of it from their first session. The agent gets the benefit of it from every session. The knowledge does not walk out the door when someone leaves.
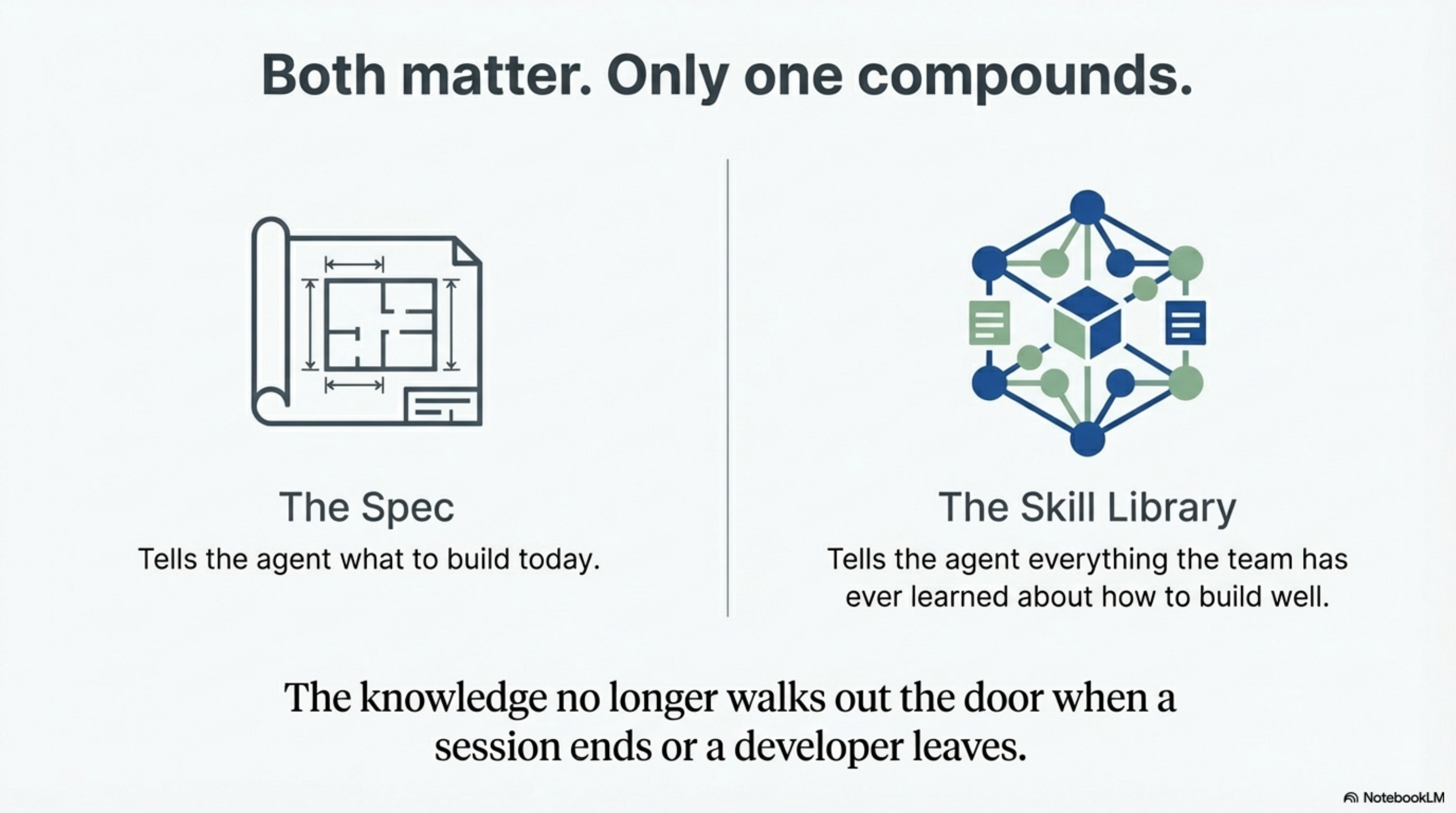
The spec tells the agent what to build today. The skill library tells the agent everything the team has ever learned about how to build well. Both matter. But only one of them compounds.
The methodology is described in detail in What a "Skill" Actually Is, Six Pillars, and Exploration Beats Specification. The infrastructure layers are covered in Three-Layer AI Memory and Four Layers. All examples from lib-pcb, built over 11 days (Jan 16-26, 2026).