The Prompt Cache as Infrastructure: Lessons from 3,007 Claude Code Sessions¶
I extracted the token usage from 55 days of Claude Code sessions. The number that stopped me:
12,198,713,224 cache read tokens.
Twelve billion. Against 9,965,286 input tokens. For every fresh token sent to the model, 1,224 were served from cache.
That ratio is not an accident. It is the result of treating the prompt cache as infrastructure -- something you invest in once and draw from continuously.
The raw numbers¶
Claude Code stores every session as a .jsonl file under ~/.claude/projects/. Each assistant
message includes a usage block with input tokens, output tokens, and cache statistics.
Across 3,007 sessions from January 9 to March 3, 2026:

| Metric | Tokens |
|---|---|
| Input | 9,965,286 |
| Output | 13,279,048 |
| Non-cached total | 23,244,334 |
| Cache write | 597,446,099 |
| Cache read | 12,198,713,224 |
| Grand total | 12,819,403,657 |
The cache read volume is 525x the fresh input. The average session consumed ~3,300 fresh input tokens while reading ~4M from cache.
Three phases¶
The 55 days did not behave uniformly. Tracking git commits, token usage, and cache hit rates together reveals three distinct phases -- the lifecycle of AI-augmented development from a cold start to a mature infrastructure.
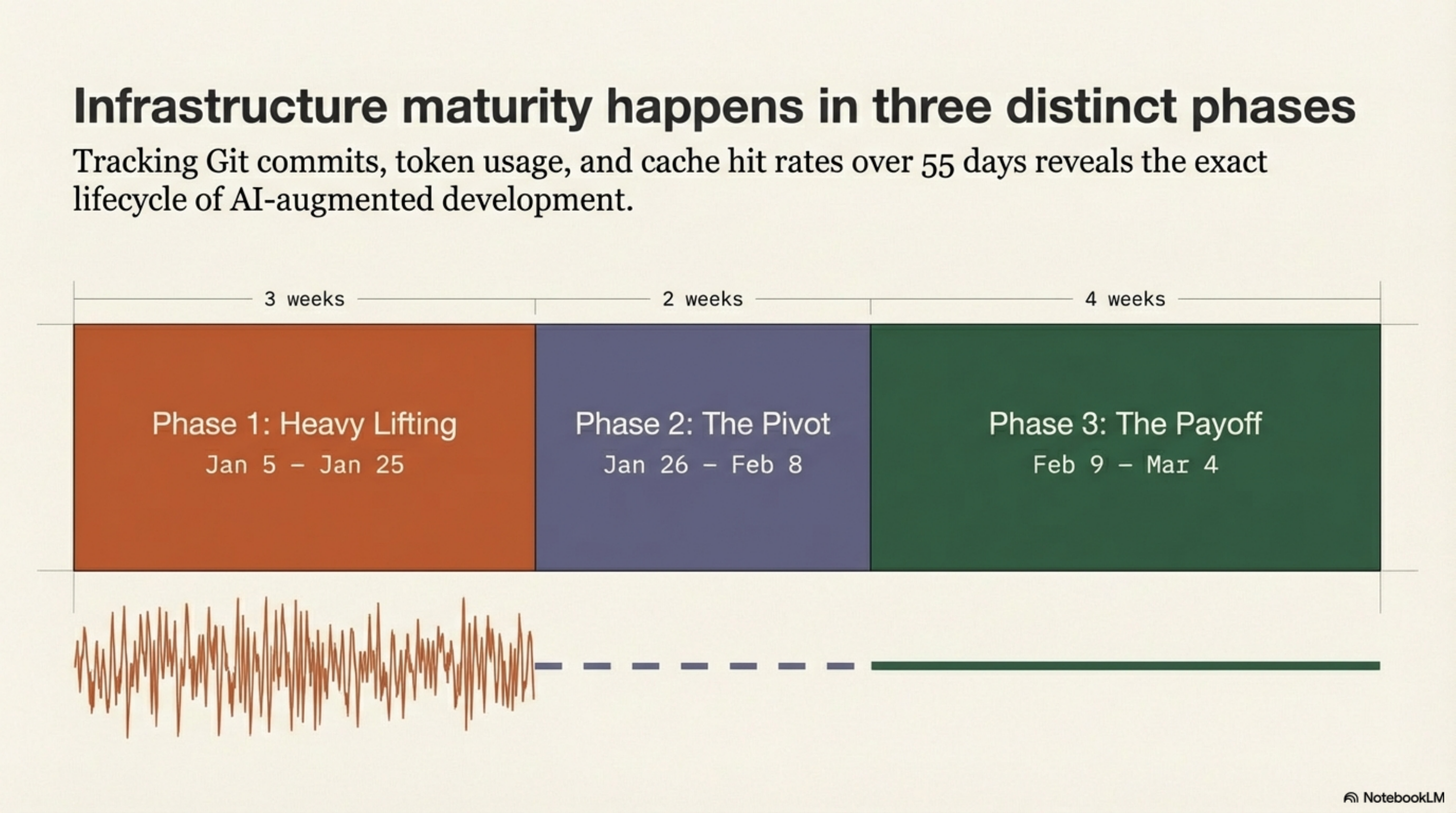
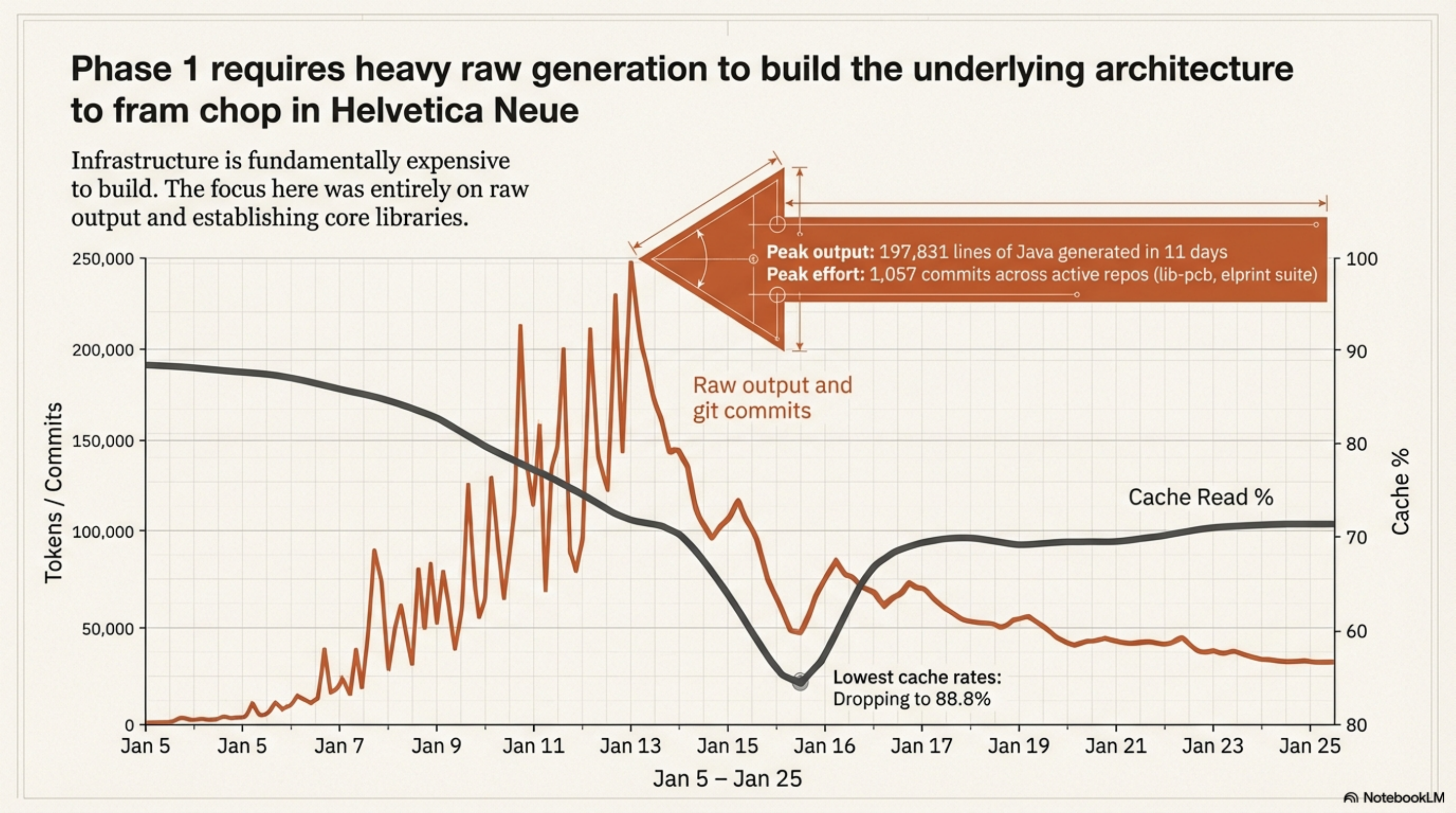
Phase 1: Heavy Lifting (Jan 5 -- Jan 25)¶
The first three weeks were raw generation. The lib-pcb build -- 197,831 lines of Java written in 11 days -- dominated this period. Peak sessions, peak fresh input, peak output. 1,057 commits across active repositories. The underlying infrastructure was being written, not yet stable.
Cache rates dropped as low as 88.8% during the peak build week. Not bad in absolute terms, but low relative to what came later. The knowledge layer didn't exist yet -- no mature CLAUDE.md, no settled skills library, no memory files with accumulated context. Every session started closer to cold.
| Week | Sessions | Output (M) | Cache-R (B) | Cache% | Activity |
|---|---|---|---|---|---|
| Jan 5--11 | 124 | 1.25 | 0.55 | 96.1% | Elprint suite -- 176 commits |
| Jan 12--18 | 339 | 4.57 | 1.27 | 94.2% | lib-pcb begins -- 484 commits |
| Jan 19--25 | 134 | 0.02 | 0.26 | 88.8% | lib-pcb peak -- 573 commits |
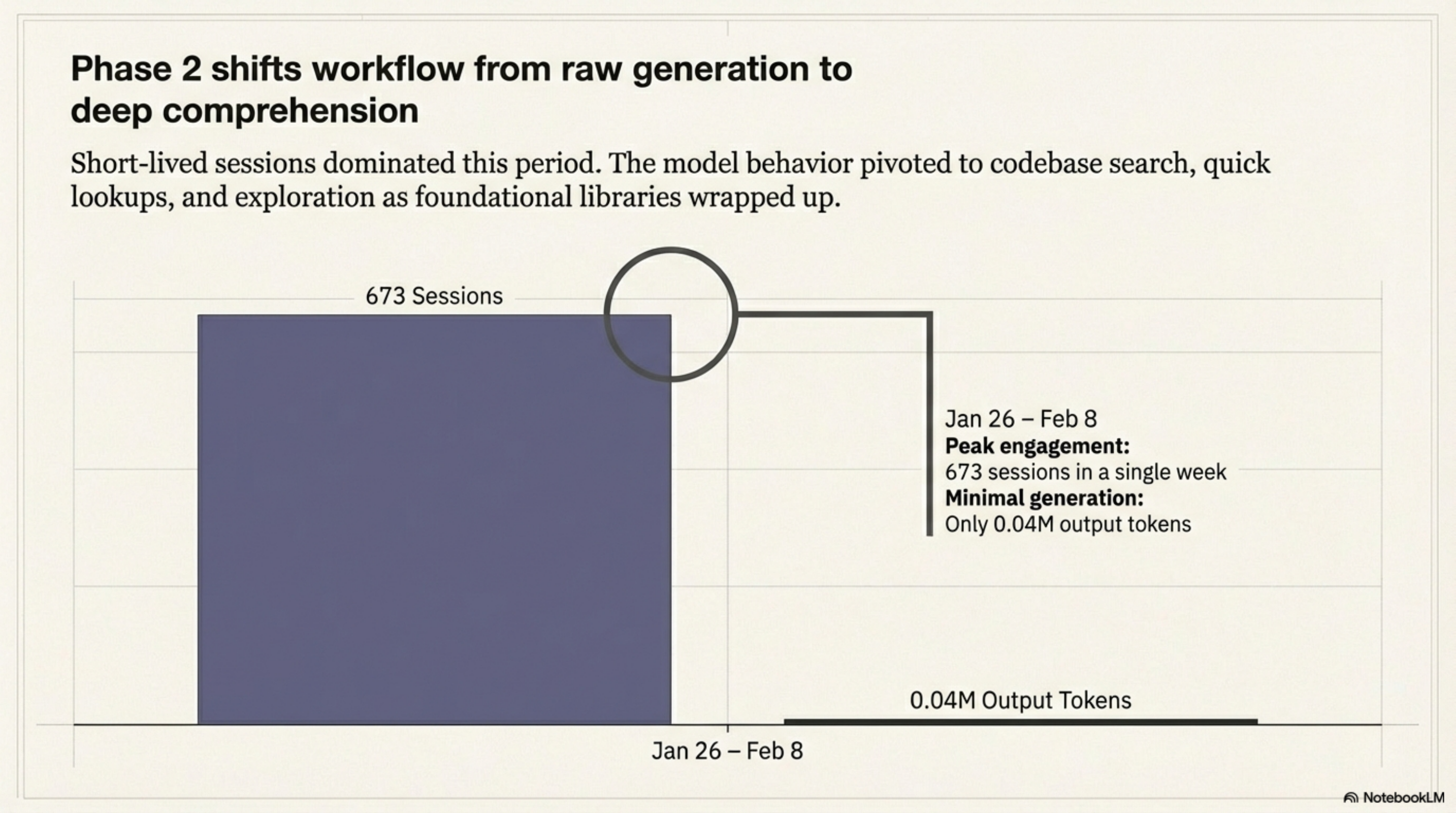
Phase 2: The Pivot (Jan 26 -- Feb 8)¶
lib-pcb wrapped up. The work pattern shifted from generation to comprehension -- exploring what had been built, integrating components, searching the codebase.
The signal: 673 sessions in a single week (Jan 26 -- Feb 1), but only 0.04M output tokens. Maximum engagement, minimal generation. The model was reading, not writing.
Cache rates recovered to 93--95% as the session pattern stabilised. But the knowledge infrastructure was still sparse. The high session count reflected workflow intensity, not infrastructure maturity.
| Week | Sessions | Output (M) | Cache-R (B) | Cache% | Activity |
|---|---|---|---|---|---|
| Jan 26--Feb 1 | 673 | 0.04 | 0.86 | 93.3% | lib-pcb wind-down -- 247 commits |
| Feb 2--8 | 495 | 0.78 | 2.02 | 94.8% | Integration -- 113 commits |
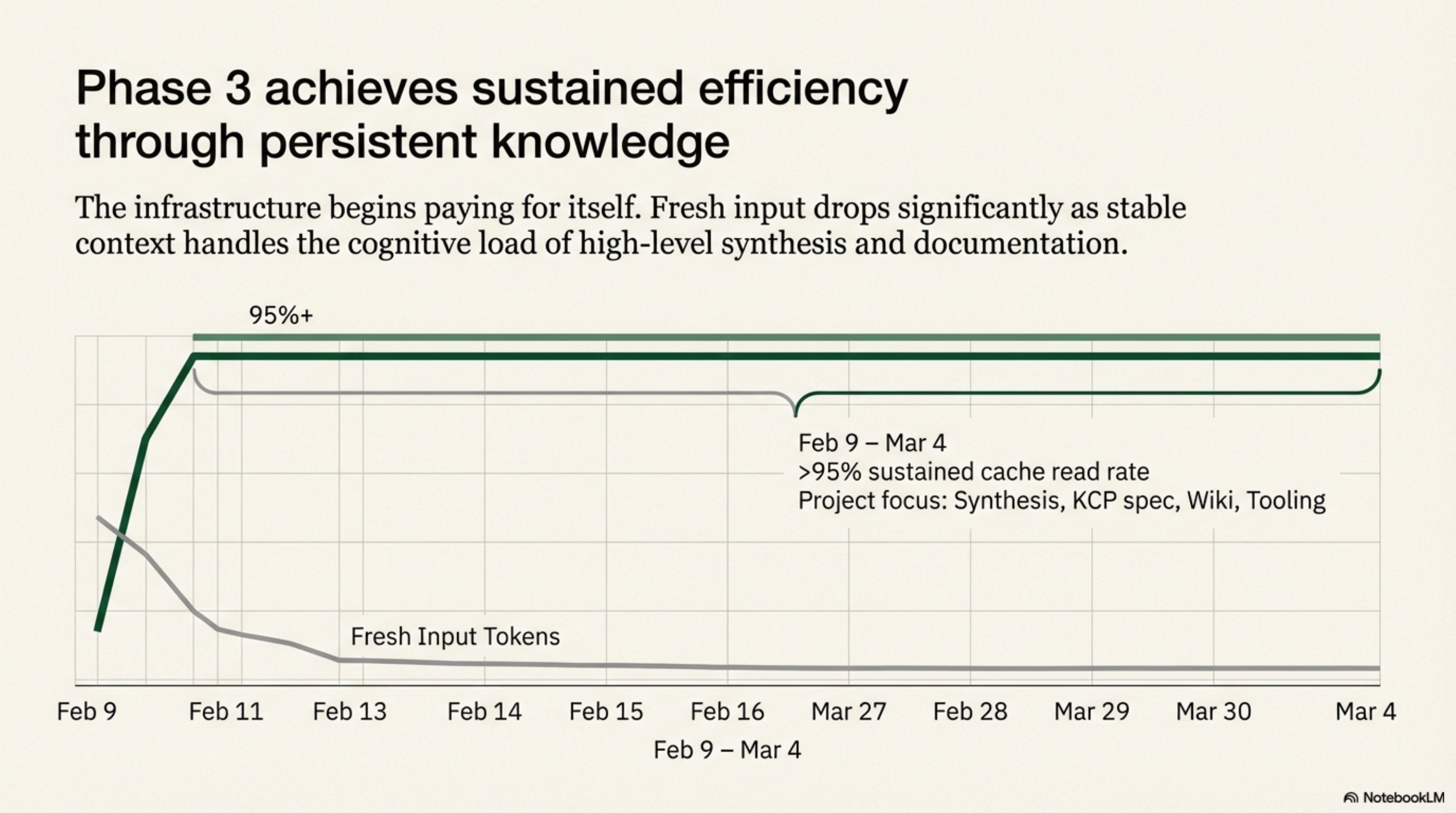
Phase 3: The Payoff (Feb 9 -- Mar 4)¶
From February 9, the project mix shifted entirely: Synthesis development, wiki restructure, KCP specification, kcp-commands, kcp-memory. Knowledge infrastructure tooling -- the work of building the knowledge layer itself.
Cache rates hit 95%+ and stayed there. Cache reads doubled. Fresh input dropped. The infrastructure was now paying for itself -- session after session, without additional investment.
| Week | Sessions | Output (M) | Cache-R (B) | Cache% | Activity |
|---|---|---|---|---|---|
| Feb 9--15 | 134 | 0.72 | 1.31 | 95.9% | Synthesis begins -- 82 commits |
| Feb 16--22 | 458 | 1.83 | 2.86 | 96.3% | Synthesis PR#18 -- 304 commits |
| Feb 23--Mar 1 | 388 | 2.73 | 2.20 | 95.4% | Wiki + KCP spec -- 270 commits |
| Mar 2--4 | 110 | 1.35 | 0.87 | 95.4% | kcp-commands + kcp-memory -- 163 commits |
What is actually being cached¶
Anthropic's prompt caching works on the stable prefix of the context window. The larger and more consistent that prefix, the higher the cache hit rate.
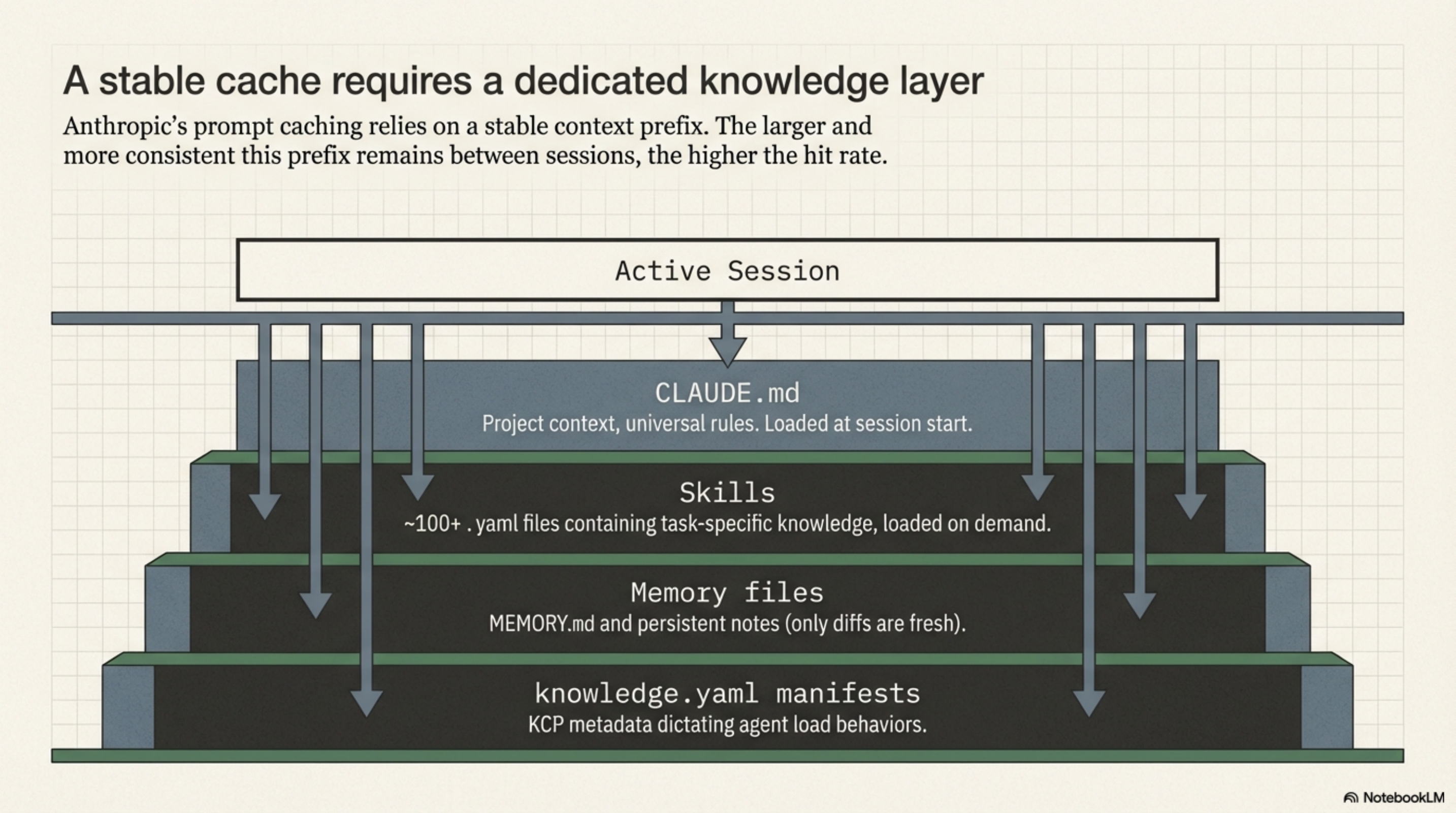
In practice, the cached content is:
CLAUDE.md-- project context, priorities, universal rules. Loaded at session start. Rarely changes.- Skills (~100+
.yamlfiles) -- task-specific knowledge loaded on demand. Stable content, high reuse. - Memory files --
MEMORY.md, topic files, persistent notes. The stable parts cache; only diffs are fresh. knowledge.yamlmanifests -- KCP metadata that tells the agent what to load and when.
Together these form a knowledge layer that sits in cache between sessions. The agent doesn't re-read it. The cache does.
The kcp-commands effect¶
kcp-commands saves 33% of the context window per session by injecting targeted syntax hints before Bash calls instead of letting the model guess. Less guessing means shorter tool-use chains, which means a more stable context prefix, which means better cache utilisation.
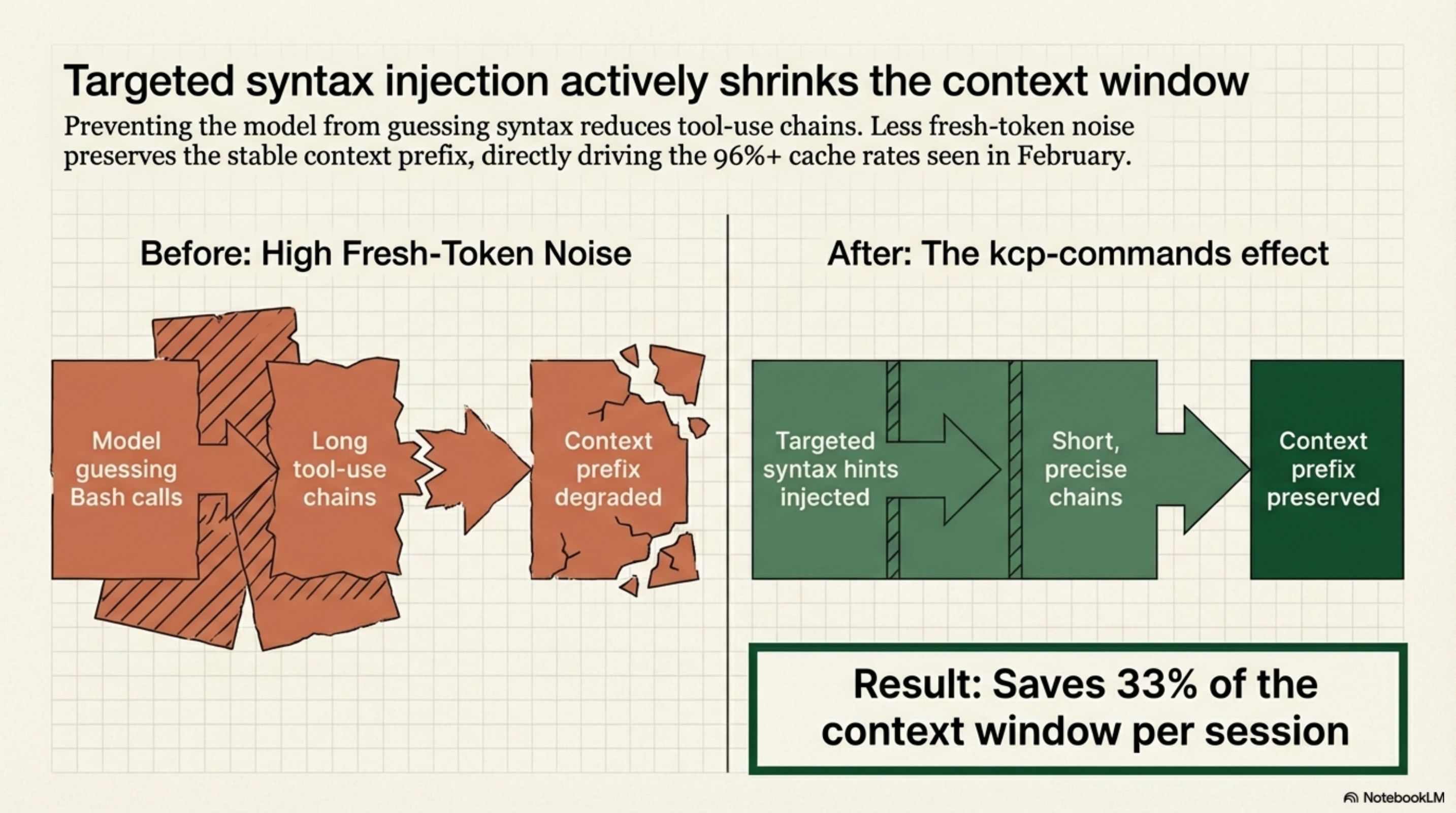
The 96%+ cache rates in February reflect both the mature knowledge infrastructure and the reduced fresh-token noise from kcp-commands. The effect is indirect but measurable.
Model usage breakdown¶
The 3,007 sessions span five model generations. Each settled into a distinct role:
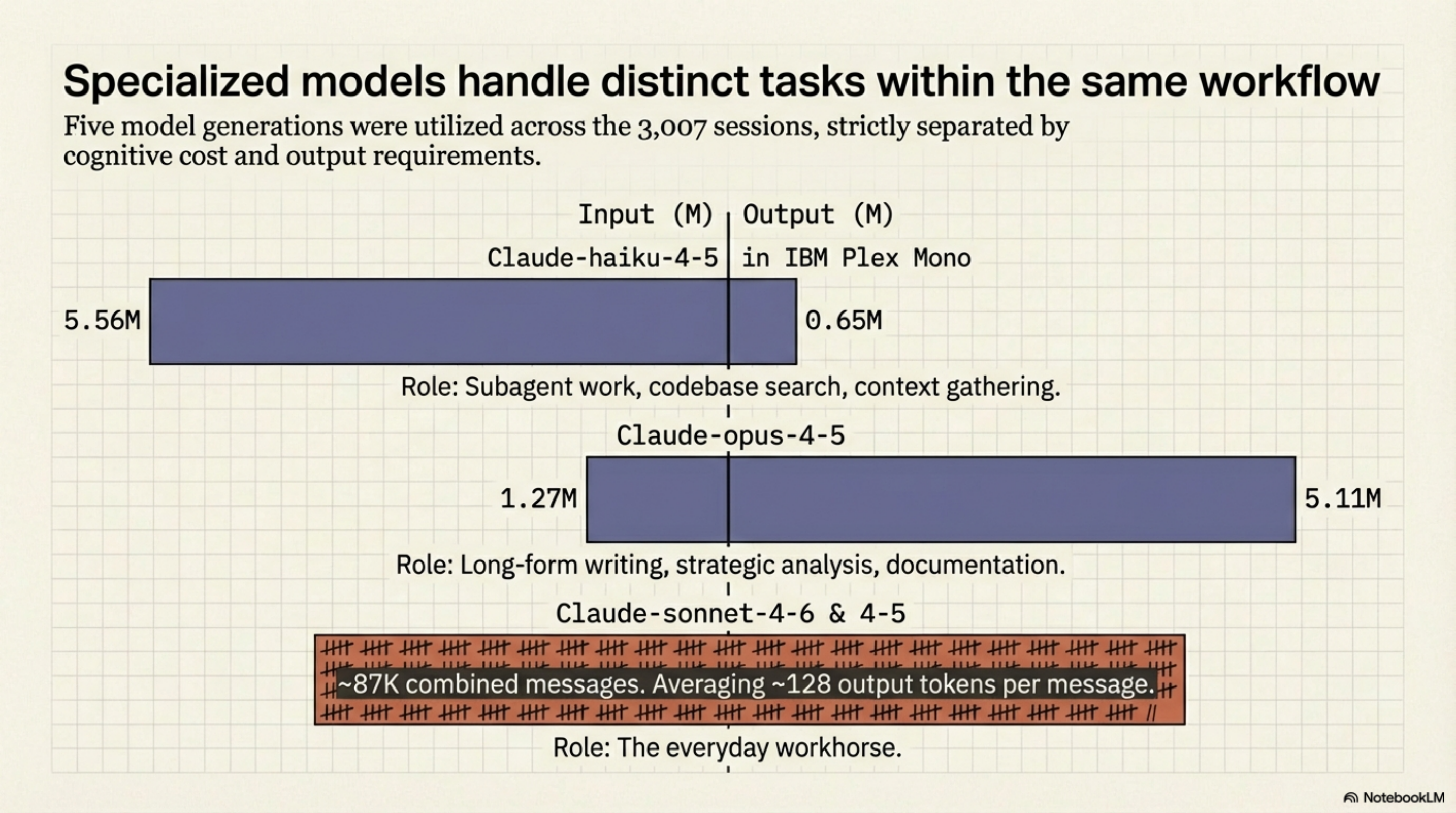
| Model | Messages | Input (M) | Output (M) | Cache-R (B) |
|---|---|---|---|---|
| claude-sonnet-4-5 | 44,790 | 1.77 | 1.88 | 4.22 |
| claude-sonnet-4-6 | 43,131 | 0.53 | 5.51 | 4.21 |
| claude-haiku-4-5 | 23,506 | 5.56 | 0.65 | 0.94 |
| claude-opus-4-6 | 19,270 | 0.84 | 0.14 | 1.43 |
| claude-opus-4-5 | 17,529 | 1.27 | 5.11 | 1.40 |
Haiku has 5.56M input against only 0.65M output -- the subagent workhorse: search, exploration, context gathering. High read volume, minimal generation.
Opus 4-5 has disproportionate output (5.11M) relative to its message count -- the long-form writing model: blog posts, documentation, strategic analysis.
Sonnet handles the everyday work at scale: ~87K combined messages averaging ~128 output tokens each.
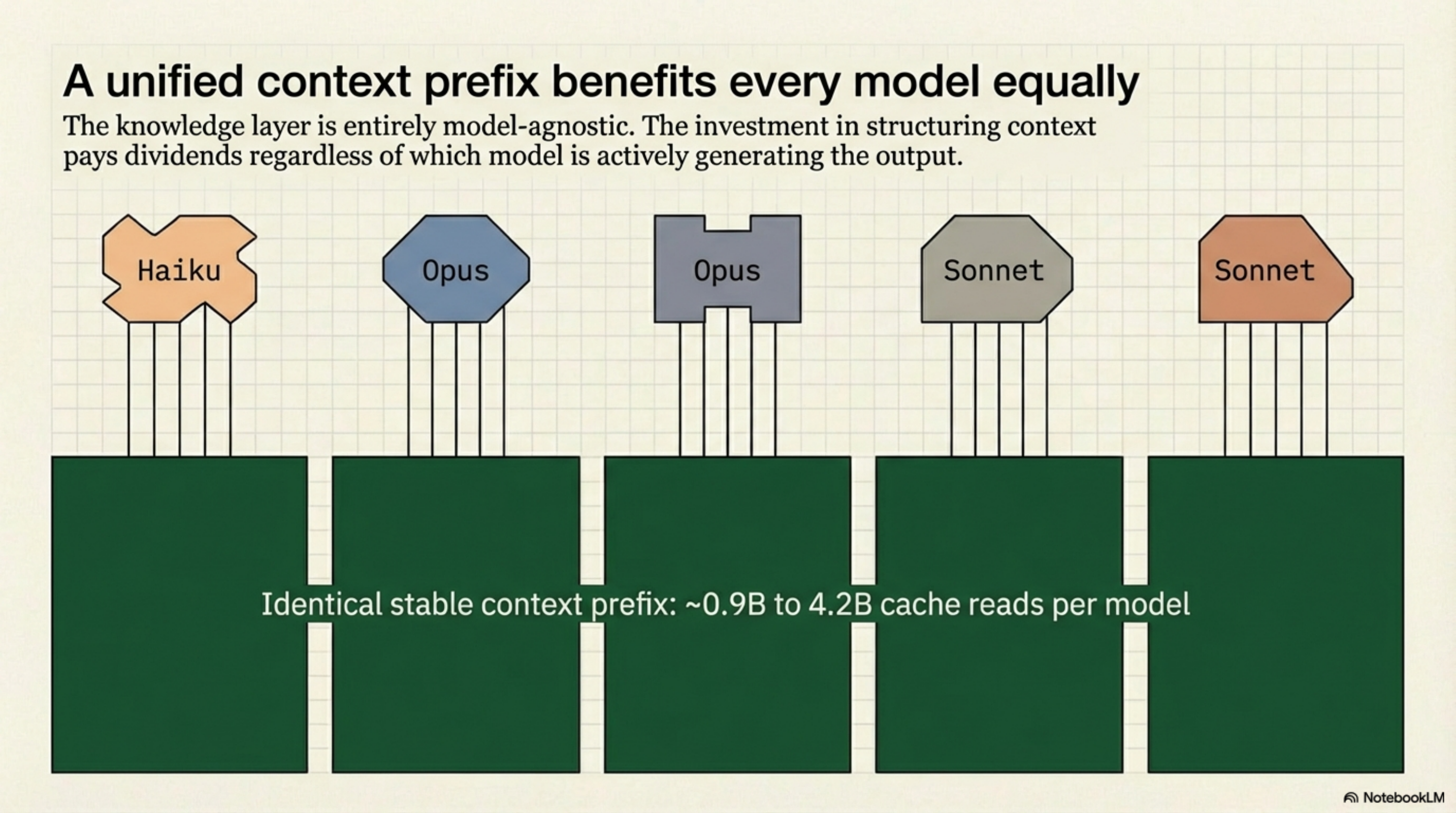
The most important observation: cache reads are uniform across all five models (~0.9--4.2B each). The same stable context prefix benefits every model equally. The knowledge infrastructure is model-agnostic.
What this would cost on the API¶
Without the caching infrastructure, this workflow breaks the economic model entirely.

At standard API rates, the 12.2B cache read tokens priced as fresh input would push the total past $40,000. With prompt caching, the same usage costs approximately $8,900. The infrastructure provides a 4.5x cost reduction on the API alone.
The Claude Max subscription for 55 days cost approximately $200--350.

| Scenario | Estimated cost (55 days) |
|---|---|
| Claude Max subscription | ~$200--350 |
| API with prompt caching | ~$8,900 |
| API without prompt caching | ~$40,000+ |
A workflow that would be economically ruinous per-token becomes standard operating procedure under a flat-rate model. This is the economic foundation of agentic labor.
What this means¶

The three phases tell a consistent story. Phase 1 was expensive because the infrastructure didn't exist yet. Phase 2 was the transition -- the work of building the knowledge layer. Phase 3 was the return on that investment: 95%+ cache rates sustained across 4 weeks, across five model generations, across 15+ repositories.
Every hour spent building a good CLAUDE.md, a well-structured skills library, or a
knowledge.yaml manifest
reduces the fresh token cost of every future session.
The investment amortises across thousands of interactions.
Treat your prompt context as infrastructure, not scaffolding. Write it once. Structure it well. Let the cache do the rest.
Token data extracted from ~/.claude/projects/**/*.jsonl using a 30-line Python script.
Git activity from git log across all active repositories. Sessions: 3,007. Period: 2026-01-09
to 2026-03-03. API cost estimates are approximations based on published Anthropic pricing as of
March 2026; actual costs vary with cache TTL, write frequency, and usage patterns.