Same Engine, Different Transmission¶
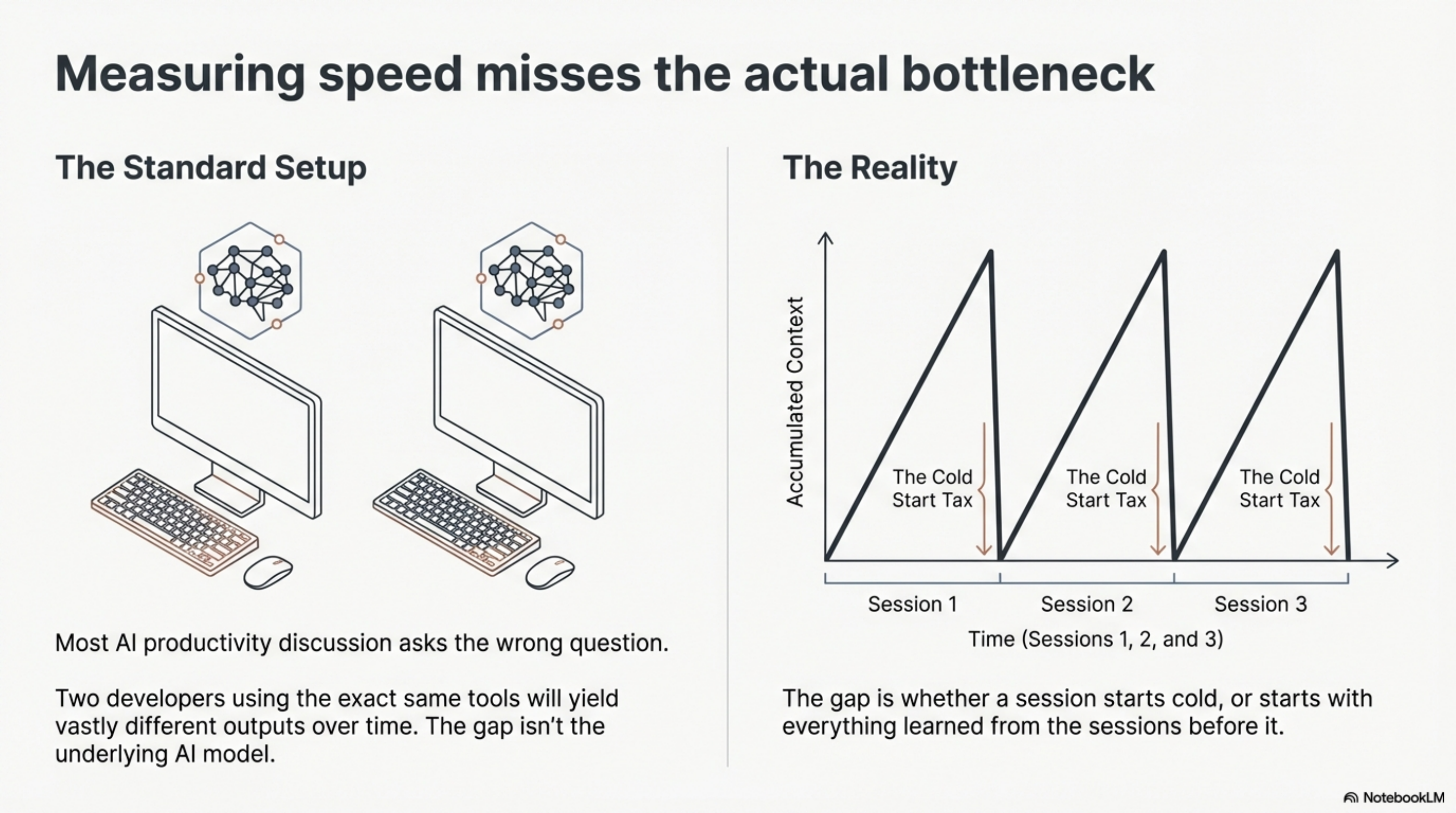
Most AI productivity discussion asks the wrong question. "How much faster?" assumes the difference is speed. It is not. Two developers using the same model, the same IDE integration, the same subscription tier -- one of them starts every session cold and the other does not. The gap between them is not the engine. It is the transmission. But the transmission alone is not the full story either. There is a third variable: how the driver was trained.
The advantage I have built since January has two dimensions, and neither works without the other. The first is infrastructure -- four memory layers where the standard setup has one. The second is methodology -- a set of six practices called Skill-Driven Development that determines how fast the infrastructure compounds. Infrastructure without methodology is tools without training. Methodology without infrastructure is discipline without leverage. Together, they are the systematic advantage.
Let me describe both, starting with why the methodology matters from the first session.
The methodology: six pillars¶
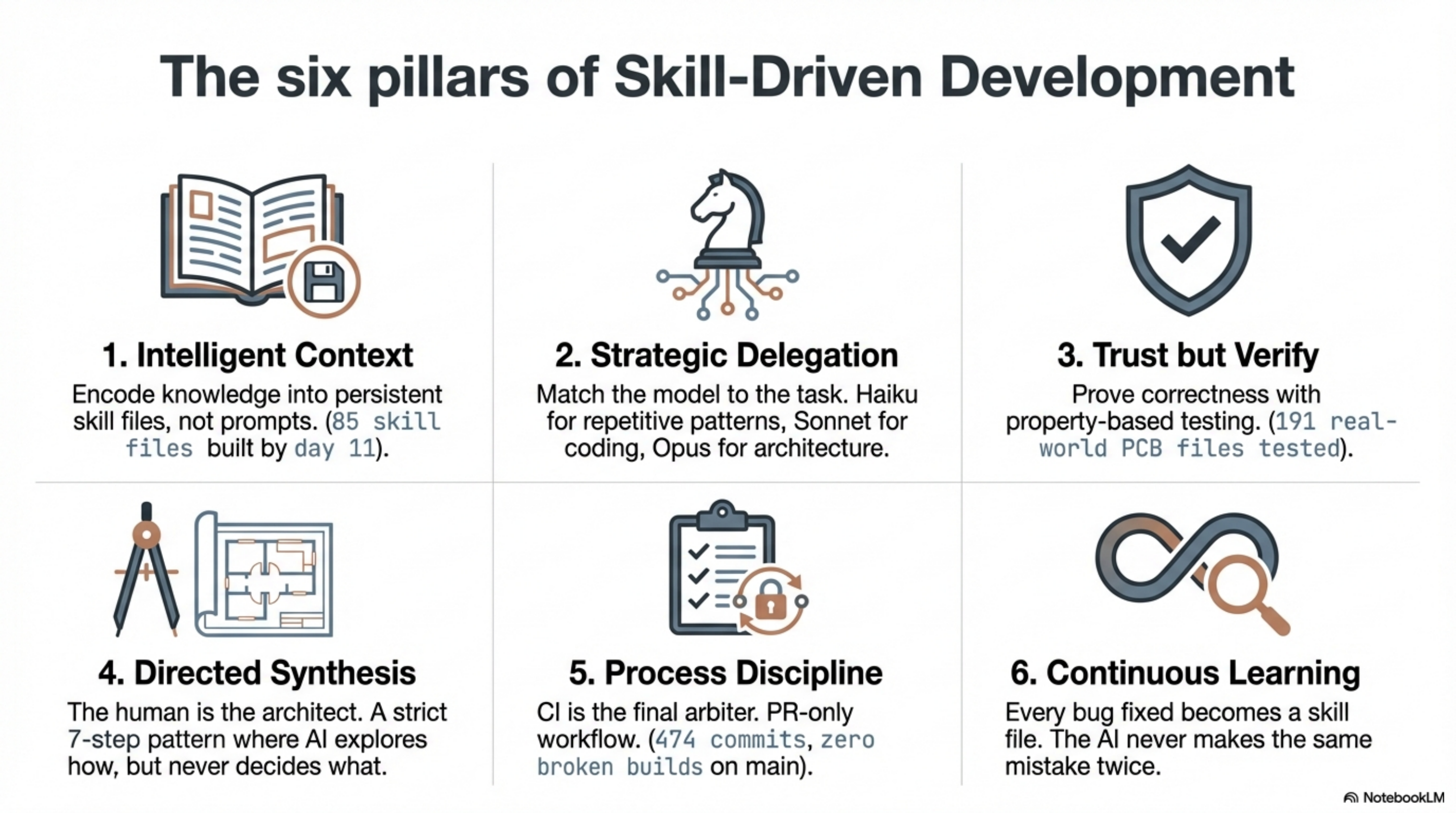
Skill-Driven Development came out of building a PCB design library -- 197,831 lines of Java in 11 days, 7,461 tests, 25-66x faster than industry standard. The six pillars are not abstract principles. They are the practices that made that result repeatable.

Intelligent context. Encode what you know into persistent skill files, not prompts. Every session starts with the AI knowing what your most experienced developer knows. By day 11 of the lib-pcb build, we had 85 skill files. The AI did not need to rediscover the domain. It already understood PCB coordinate systems, layer stackups, the difference between metric and imperial units in Gerber files. That knowledge persisted between sessions because it was written down in a form the AI could load.
Strategic delegation. Right model for each task. Haiku for repetitive pattern-following. Sonnet for most coding. Opus for architecture decisions and complex reasoning. Not every task deserves the same compute budget, and matching model to task complexity is a skill in itself.
Trust but verify. Systems that prove correctness, not human eyeballing. Round-trip tests that parse a file, write it back, parse again, and compare. Property-based tests that generate random valid inputs. A battle suite of 191 real PCB files from the wild. The result: zero AI-induced production bugs. Not low. Zero.
Directed synthesis. The human stays in the architect's seat. A 7-step pattern: human identifies the problem, AI explores solution space, human reviews the approach, AI implements to spec, human reviews every change, AI tests, human makes the merge decision. The AI never decides what to build. It decides how to build what the human specified.
Process discipline. No shortcuts when tired, no exceptions. PR-only workflow. CI is the final arbiter. 474 commits across the lib-pcb build, zero broken builds on main. This pillar is the one that fails first when people try to move fast -- and the one whose absence costs the most.
Continuous learning. Every bug fixed is a skill to update. A bounding box calculation bug found on day 3 became a skill file entry. Claude never made that mistake again -- not in that session, not in any subsequent session. The knowledge did not decay between sessions because it was encoded in the skill corpus, not in a conversation that would be garbage-collected.
Two of these pillars -- intelligent context and continuous learning -- directly drive the compounding of the infrastructure layers. The infrastructure provides the mechanism: episodic memory, skills corpus, Synthesis index. SDD provides the discipline to systematically feed those mechanisms with accurate, current, high-signal knowledge. Without the methodology, the compounding flattens. Skills go stale. Sessions produce noise instead of retrievable decisions. The episodic memory fills with low-value content. The infrastructure is there but it is not getting fed.
The infrastructure: four gears¶
A well-equipped Claude Code user -- not a beginner, someone with a solid CLAUDE.md, maybe some MCP servers, uses it daily -- has one memory layer: the current session's context window. Whatever was loaded at session start, plus whatever accumulated during the session. When the session ends, it is gone. The next session starts from the same blank slate. That is a perfectly good car with one gear.
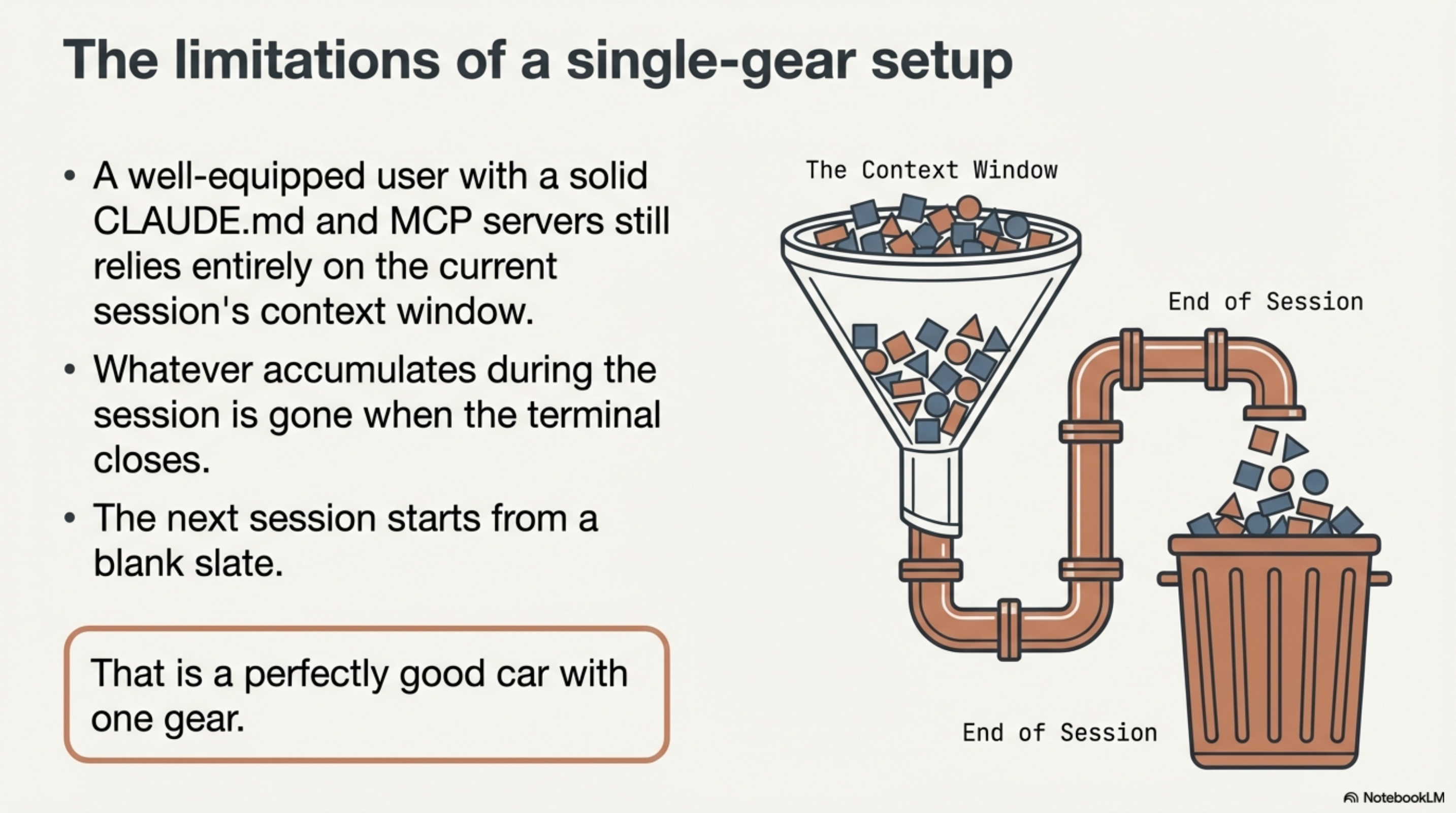
The setup I have been building since January has four.
Working memory management. The context window is not just capacity -- it is signal density. kcp-commands intercepts Bash tool calls in two phases: Phase A injects CLI flag guidance before execution so the agent asks for what it needs rather than dumping everything; Phase B strips noise from the output before it enters the context window. Validated result: 67,352 tokens saved per session, 33.7% of a 200K context window recovered. That is 33 more real tool results staying in scope per session -- 33 more facts about the actual project that remain available when later decisions reference earlier findings.
Episodic memory. Every Claude Code session I run gets indexed into a full-text SQLite store. synthesis sessions search "authentication architecture" retrieves past decisions in seconds -- including sub-agent sessions whose context I never directly held. Nothing is lost. Not the conclusions, and not the reasoning chains -- the dead ends, the failed approaches, the "we tried X and it failed because Y" that skill files never capture. This is where Pillar 6 (continuous learning) finds its source material. The episodic memory is the raw ore; the skill file is the refined output.
Semantic memory. Synthesis indexes 8,934 files across 3 workspaces. Sub-second search. Cross-repo dependency graphs covering 58 repositories and 429 dependencies, built in under 31 seconds. Bi-directional relationship tracking -- "what breaks if I change this?" answered in milliseconds. On top of that, 75+ domain-specific skills loaded on demand: regulatory frameworks, client engagement context, methodology patterns. Each skill is verified knowledge that grounds the model in sources rather than training-data approximations. And each skill exists because someone applied Pillar 1 (intelligent context) and wrote it down.
Autonomous processing. Two AI agents running 24/7 on EC2. Overnight: CVE scanning across 62 repositories, dependency patching, release management. A security briefing lands at 05:30 Oslo time. By 08:00, a morning briefing synthesises pipeline status, code health, and changelog into something I read over coffee in two minutes. The rig works while I sleep.
How they compound together¶
This is the part that matters most, and the part where the two dimensions reinforce each other.
Three of the four infrastructure layers grow over time. Episodic memory accumulates with every session. The skills corpus grows with every engagement. The Synthesis index gets richer with every maintenance cycle. But growth alone is not compounding. Compounding requires that each addition makes the next session more productive -- which only happens if the additions are high-signal.
That is where SDD earns its keep. Process discipline (Pillar 5) means every decision that deserves to persist gets persisted -- the skill files stay current, the ADRs reflect reality, the episodic memory has accurate signal rather than noise. Continuous learning (Pillar 6) means the corpus does not just grow, it gets smarter. Directed synthesis (Pillar 4) means sessions produce structured decisions and clear reasoning, not unstructured wandering -- which means the episodic memory layer has something worth retrieving later.
The lib-pcb evidence makes this concrete. The last 5 days of the 11-day build were more productive per session than the first 5. Not because the model changed. Because 85 skill files encoded everything learned in the first 6 days. That is SDD and infrastructure compounding together. The methodology fed the infrastructure. The infrastructure amplified the methodology.
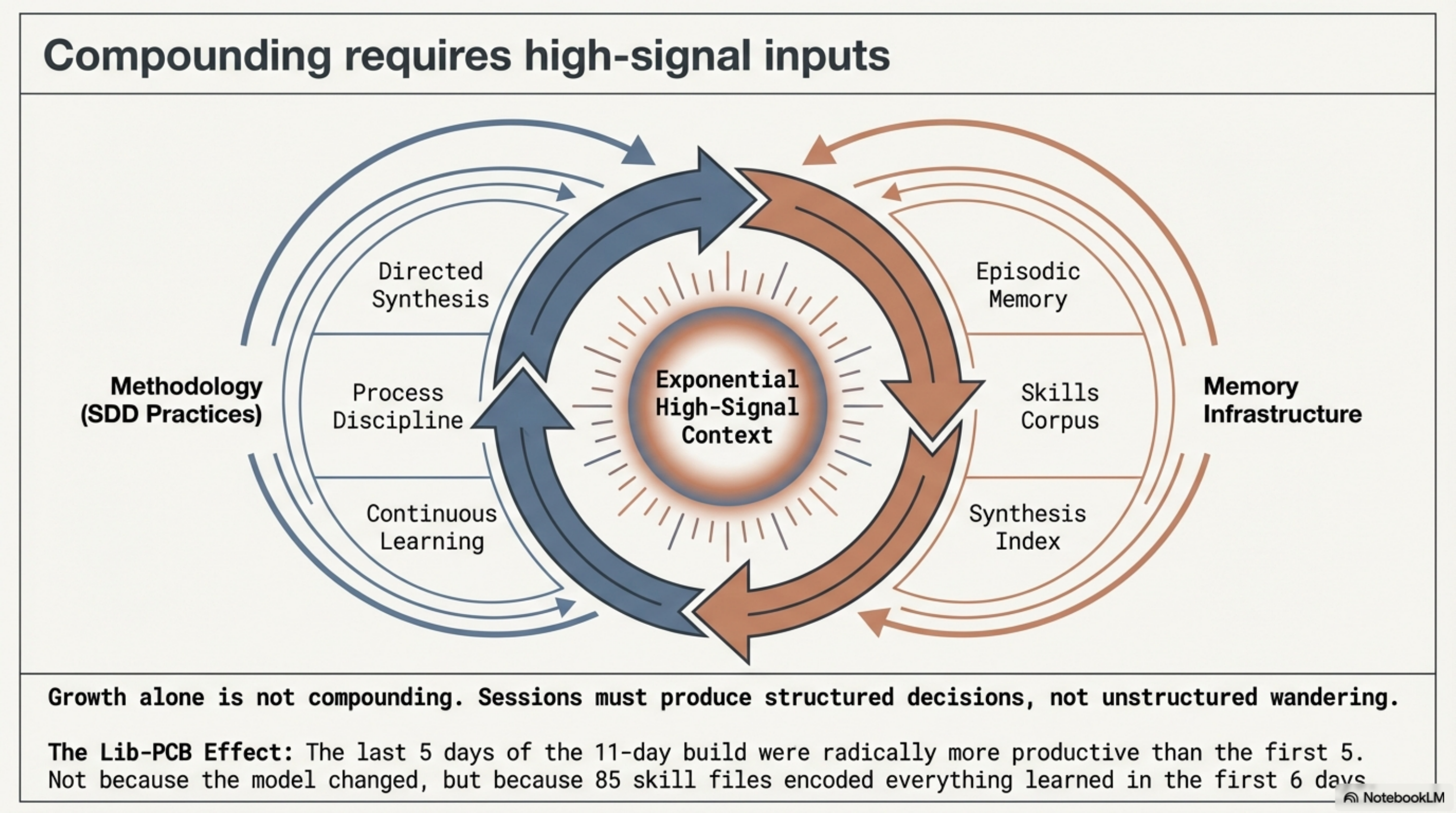
A well-equipped user who installed every tool in this post but applied no methodology would see the compounding flatten. A disciplined developer who applied every SDD principle but had no persistent memory layers would hit a ceiling -- the discipline would produce knowledge, but the knowledge would not accumulate across sessions.
The honest numbers¶
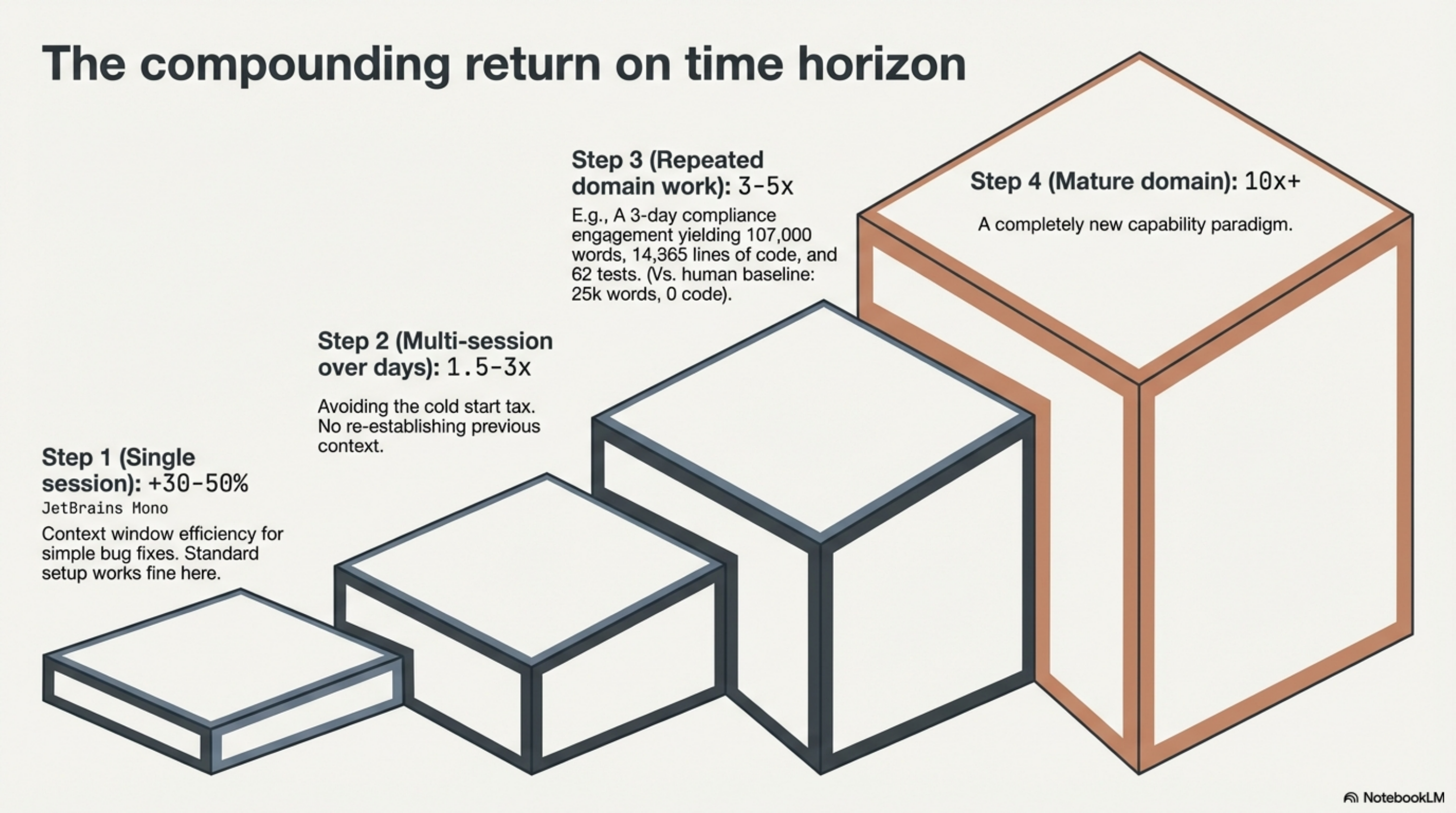
| Scenario | Advantage |
|---|---|
| Single session, simple task | 30--50% |
| Multi-session work spanning days | 1.5--3x |
| Repeated work in a domain (5th engagement vs 1st) | 3--5x |
| Mature domain, skills built up, tasks impossible any other way | 10x+ (capability gap, not speed) |
The advantage is smallest where it matters least. A single-session task -- write this function, fix this bug -- is where the standard setup already works well. The context window holds everything needed. My setup is maybe 30--50% better, mostly from context window efficiency.
The advantage grows with time horizon. Multi-session work is where cold starts compound. Every session that begins by re-establishing context that the previous session already held is paying a tax.
The advantage is largest in repeated domain work. A 3-day compliance engagement recently produced roughly 107,000 words of deliverables, 14,365 lines of code, 62 passing integration tests, and 25 simulation findings. A traditional senior consultant in 3 days: 15,000--25,000 words, no running code. The difference was not the model. It was the accumulated knowledge that the model could draw on.
With SDD applied consistently, the upper range of each bracket is more reliably reachable. The 3--5x is not a lucky outcome on a good week. It is the expected result when the methodology has been feeding the infrastructure for months.
The fourth row is different in kind. A 24-month simulation surfacing 25 architectural findings, cross-repo blast radius analysis across 58 repositories — these are not faster versions of tasks a well-equipped user could do. They are tasks a well-equipped user cannot do within the time envelope at all. When the capability gap is that large, the multiplier stops being a useful frame. The question becomes: what is achievable, and what is not?
March 3¶
Before March 3, the rig had three of the four layers but not episodic memory. Sessions were lost. Conclusions were captured in skills, but the reasoning chain -- the dead ends, the failed approaches, the context that led to a decision -- was gone. I would occasionally discover that a past session had solved a problem I was about to re-solve, but only by accident.
Synthesis v1.21.0 closed that gap. The sessions module indexes every Claude Code transcript into SQLite with FTS5 full-text search. The first scan processed 2,971 sessions in 109 seconds. Subsequent scans are near-instant.
With all four layers live and a methodology that systematically feeds them, the framing shifts. This is no longer "better tools." It is a fundamentally different memory architecture operated by a fundamentally different set of practices. The same model, the same API, the same subscription -- but the knowledge infrastructure surrounding it and the discipline applied to it determine whether each session starts from zero or starts from everything that came before.
Same engine. Different transmission. Trained driver.
Download: The Systematic AI Advantage (PDF)
The methodology: Six Pillars -- What We Learned Building 200,000 Lines in 11 Days. The infrastructure: Synthesis (knowledge infrastructure for AI agents) and kcp-commands (context window management for Claude Code).