Beyond llms.txt: AI Agents Need Maps, Not Tables of Contents¶
Earlier today I published a post about Synthesis and why knowledge infrastructure is the layer the AI agent ecosystem is missing. Several people responded with a version of the same question: "We use llms.txt — isn't that enough?"
It depends on what you are trying to do. And I think the answer is worth a dedicated post.
What llms.txt does well¶
Jeremy Howard designed llms.txt to be dead simple, and it is. Drop a file at a known location, list what your site contains, give agents something to find. For a personal site or a small project, this solves a real problem cleanly.
My own wiki has an llms.txt. It works. An agent querying wiki.totto.org can get a reasonable
picture of what is there and where to find it.
But I have been deploying AI agents against something much larger than a personal wiki, and llms.txt does not scale to what those agents actually need. The limitations are not bugs in the implementation — they are consequences of the design. Dead simple means you get the "hello world" version of knowledge representation. The production version is harder.
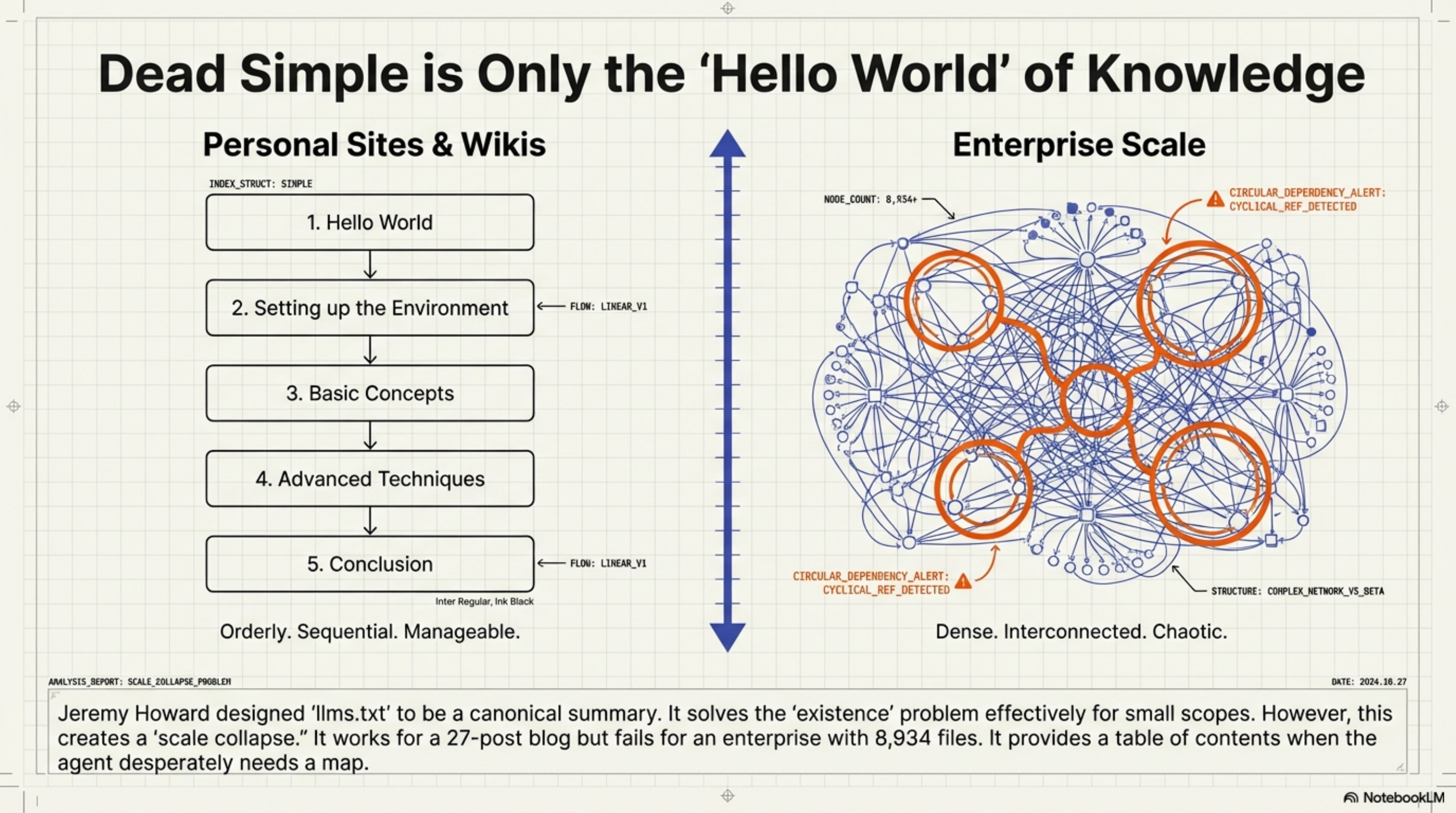
The six things llms.txt cannot express¶
Topology. llms.txt is a list. It tells an agent what exists. It cannot tell the agent that the authentication module depends on the token manager, that the deployment guide only makes sense after the installation guide, or that two pages contradict each other because one was written before a major refactoring. There are no relationships between knowledge units. An agent gets a table of contents. What it needs is a map.
Selective loading. Two granularities: the index (tens of lines) or the full dump (thousands of lines). An agent building a feature does not need the project history, contributor guidelines, and changelog simultaneously. But llms.txt gives the agent no way to say "I am working on authentication — give me only what is relevant to authentication." The agent must read everything or guess from link titles.
Intent. Each entry is a URL with an optional description. There is no way to express what question a page answers, what task it is relevant to, or when to load it. An agent cannot distinguish a critical architectural decision record from a historical curiosity.
Freshness. llms.txt does not encode when content was last updated. An agent cannot distinguish a document written yesterday from one written three years ago. For technical documentation, where knowledge decays at the rate the code changes, this gap is critical.
Tooling connection. llms.txt is a static file. No query interface, no dependency graph, no way to ask "what else is related to this?" The file exists in isolation from the infrastructure that would make it powerful.
Scale. For a personal wiki with 27 blog posts, llms-full.txt at a few hundred lines works fine. For an enterprise with 8,934 files across multiple repositories, it does not. The standard's answer to scale is "make a bigger text file." That is not an architecture.

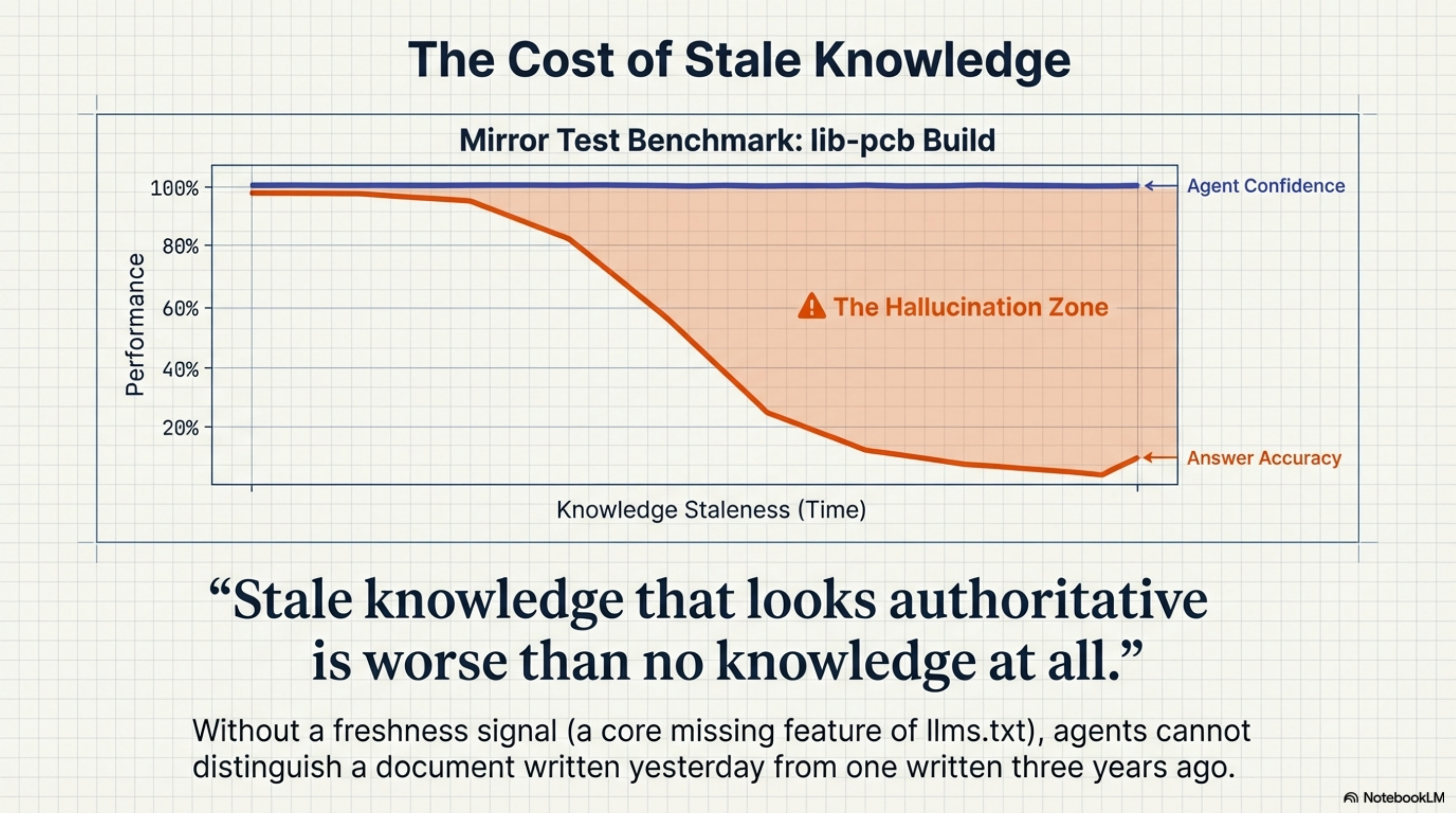
The Mirror Test¶
I ran what I called the Mirror Test during the lib-pcb build — a benchmark where an AI agent acts as researcher, instrument, and subject simultaneously, to measure how much its behaviour changes when given different context.
The finding that mattered: an agent consuming stale documentation about a module gave confident, fluent, wrong answers about that module's field count. The documentation said one thing; the code said another. The agent had no freshness signal, no way to know the documentation was out of date. High confidence, low accuracy.
Stale knowledge that looks authoritative is worse than no knowledge at all. The agent would have done better with no documentation than with documentation that confidently misrepresented the current state.
llms.txt has no answer for this. The file cannot tell an agent that its contents were last verified six months ago.
A proposal: Knowledge Context Protocol¶
I have been thinking about what a better standard would look like — one that sits between llms.txt (a static index file) and a full Synthesis deployment (a running MCP server). Something you can still drop on a website. Something a human can read. But something that actually expresses what agents need to navigate knowledge effectively.
Today I published a draft of that standard: the Knowledge Context Protocol (KCP).
KCP is a knowledge.yaml manifest. It adds the metadata layer that llms.txt cannot provide:
topology, intent, freshness, audience, and selective loading. You can start with three fields in
five minutes. The full field set handles enterprise knowledge graphs.
The positioning statement from the spec:
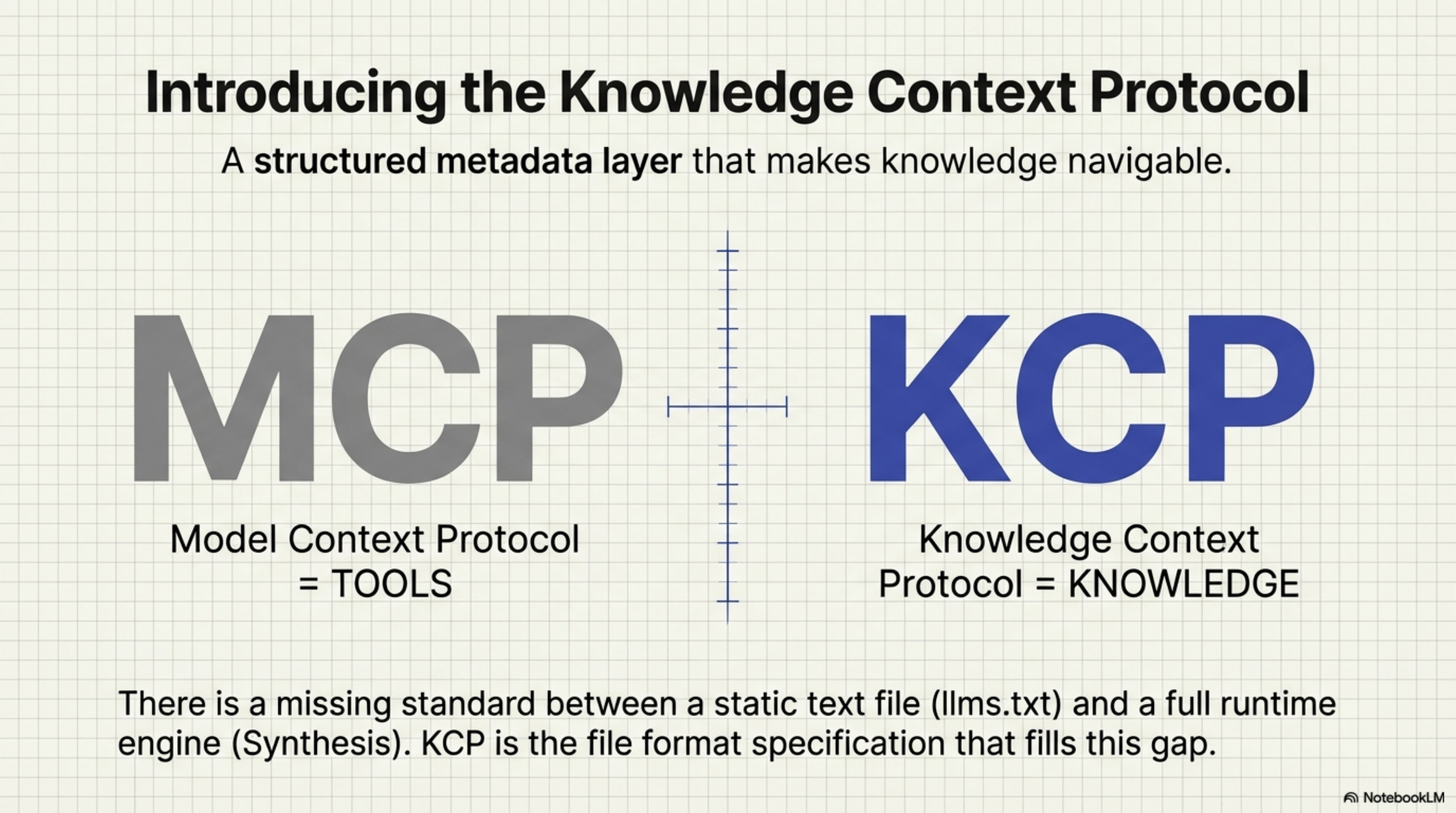
KCP is to knowledge what MCP is to tools.
MCP (Model Context Protocol) defines how agents connect to tools. KCP defines how knowledge is structured for those tools to serve. The parallel is intentional.
A minimal example:
project: my-project
version: 1.0.0
units:
- id: overview
path: README.md
intent: "What is this project and how do I get started?"
scope: global
audience: [human, agent]
validated: 2026-02-25
Add depends_on when one piece of knowledge requires another. Add triggers to declare what
task contexts make a unit relevant. Add supersedes when documentation replaces older
documentation. The structure grows with your need for it.
How this connects to Synthesis¶
Synthesis is the reference implementation of a KCP-native knowledge server. It indexes a workspace — code, documentation, configuration, PDFs — and serves it via MCP with sub-second retrieval.
KCP is the format; Synthesis is the engine. But the format is open. Any tool can implement it.
The goal is that knowledge.yaml becomes the interchange format for structured knowledge the
way package.json is the interchange format for JavaScript project metadata — something every
tool in the ecosystem reads and writes.
synthesis export --format kcp is on the roadmap: one command to generate a knowledge.yaml
from an existing Synthesis index automatically.
Why now¶
The AI agent tooling market has invested heavily in model capability, agent frameworks, and tool connectivity. The knowledge structure layer — how knowledge is organized so agents can navigate it reliably — has been largely skipped.
llms.txt is the current best practice. It is good for what it is. But it was designed for a simpler problem than the one we are now trying to solve. The ecosystem needs a knowledge architecture standard, not just a better index file.
The spec is at github.com/cantara/knowledge-context-protocol. It is Apache v2 licensed, intentionally minimal, and open for feedback. KCP has been submitted to the Agentic AI Foundation (Linux Foundation) for neutral governance alongside MCP and AGENTS.md.
If you use OpenCode, the
opencode-kcp-plugin applies KCP directly
to your sessions: it injects the knowledge map into every system prompt and annotates glob/grep
results with intent strings. Two lines to enable — one to install, one in opencode.json.
If you have a use case that the current format does not cover, open an issue. If you add a
knowledge.yaml to a project and it works — or does not work — I want to know.
The agents are only as good as what they know. Give them something well-structured to know.
Projects already running KCP in production — including wiki.totto.org, wiki.cantara.no, and active PRs against crewAI, AutoGen, and smolagents — are listed in ADOPTERS.md.
This post is part of a series on knowledge infrastructure for AI agents. Previous: AI Agents Without Knowledge Infrastructure Are Interns With Amnesia Next: Add knowledge.yaml to Your Project in Five Minutes
Series: Knowledge Context Protocol
← Who Describes You to AI? · Part 2 of 24 · KCP and MCP: One Protocol for Structure, One for Retrieval →